您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关Mysql5.7如何并行复制,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
MySQL 5.7的并行复制建立在组提交的基础上,所有在主库上能够完成 Prepared 的语句表示没有数据冲突,就可以在 Slave 节点并行复制。
关于 MySQL 5.7 的组提交,我们要看下以下的参数:
(test) > show global variables like '%group_commit%' -> ; +-----------------------------------------+-------+ | Variable_name | Value | +-----------------------------------------+-------+ | binlog_group_commit_sync_delay | 0 | | binlog_group_commit_sync_no_delay_count | 0 | +-----------------------------------------+-------+
要开启 MySQL 5.7 并行复制需要以下二步,首先在主库设置 binlog_group_commit_sync_delay 的值大于0 。
> set global binlog_group_commit_sync_no_delay_count=20; > set global binlog_group_commit_sync_delay =10;
这里简要说明下 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数的作用。
binlog_group_commit_sync_delay
全局动态变量,单位微妙,默认0,范围:0~1000000(1秒)。
表示
binlog提交后等待延迟多少时间再同步到磁盘,默认0 ,不延迟。当设置为 0 以上的时候,就允许多个事务的日志同时一起提交,也就是我们说的组提交。组提交是并行复制的基础,我们设置这个值的大于 0 就代表打开了组提交的功能。
binlog_group_commit_sync_no_delay_count
全局动态变量,单位个数,默认0,范围:0~1000000。
表示等待延迟提交的最大事务数,如果上面参数的时间没到,但事务数到了,则直接同步到磁盘。若
binlog_group_commit_sync_delay没有开启,则该参数也不会开启。
其次要在 Slave 主机上设置如下几个参数:
# 过多的线程会增加线程间同步的开销,建议4-8个Slave线程。 slave-parallel-type=LOGICAL_CLOCK slave-parallel-workers=4
或者直接在线启用也是可以的:
mysql> stop slave; Query OK, 0 rows affected (0.07 sec) mysql> set global slave_parallel_type='LOGICAL_CLOCK'; Query OK, 0 rows affected (0.00 sec) mysql> set global slave_parallel_workers=4; Query OK, 0 rows affected (0.00 sec) mysql> start slave; Query OK, 0 rows affected (0.06 sec) mysql> show variables like 'slave_parallel_%'; +------------------------+---------------+ | Variable_name | Value | +------------------------+---------------+ | slave_parallel_type | LOGICAL_CLOCK | | slave_parallel_workers | 4 | +------------------------+---------------+ 2 rows in set (0.00 sec)
当前的 Slave 的 SQL 线程为 Coordinator(协调器),执行 Relay log 日志的线程为 Worker(当前的 SQL 线程不仅起到协调器的作用,同时也可以重放 Relay log 中主库提交的事务)。
我们上面设置的线程数是 4 ,从库就能看到 4 个 Coordinator(协调器)进程。
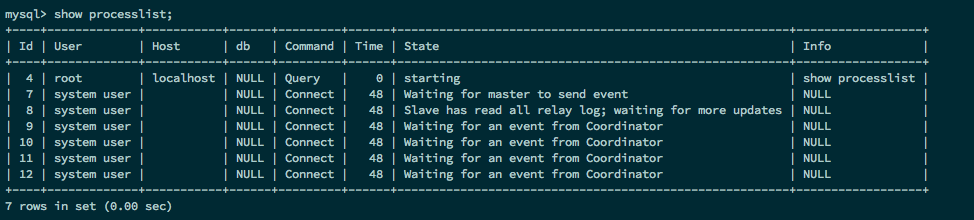
开启 MTS 功能后,务必将参数 master-info-repository 设置为 TABLE ,这样性能可以有 50%~80% 的提升。这是因为并行复制开启后对于 master.info 这个文件的更新将会大幅提升,资源的竞争也会变大。
在 MySQL 5.7 中,推荐将 master-info-repository 和 relay-log-info-repository 设置为 TABLE ,来减小这部分的开销。
master-info-repository = table relay-log-info-repository = table relay-log-recovery = ON
复制的监控依旧可以通过 SHOW SLAVE STATUS\G,但是 MySQL 5.7 在 performance_schema 架构下多了以下这些元数据表,用户可以更细力度的进行监控:
mysql> use performance_schema; mysql> show tables like 'replication%'; +---------------------------------------------+ | Tables_in_performance_schema (replication%) | +---------------------------------------------+ | replication_applier_configuration | | replication_applier_status | | replication_applier_status_by_coordinator | | replication_applier_status_by_worker | | replication_connection_configuration | | replication_connection_status | | replication_group_member_stats | | replication_group_members | +---------------------------------------------+ 8 rows in set (0.00 sec) 想办法统计出来每个同步线程使用的比率。统计方法如下: 1、将线上从机相关统计打开(出于性能考虑默认是关闭的),打开方法可以如下如下SQL: UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE 'events_transactions%'; UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'WHERE NAME = 'transaction'; 2、创建一个查看各个同步线程使用量的视图,代码如下: USE test; CREATE VIEW rep_thread_count AS SELECT a.THREAD_ID AS THREAD_ID,a.COUNT_STAR AS COUNT_STAR FROM performance_schema.events_transactions_summary_by_thread_by_event_name a WHERE a.THREAD_ID in (SELECT b.THREAD_ID FROM performance_schema.replication_applier_status_by_worker b); 3、一段时间后,统计各个同步线程的使用比率,SQL如下: SELECT SUM(COUNT_STAR) FROM rep_thread_count INTO @total; SELECT 100*(COUNT_STAR/@total) AS thread_usage FROM rep_thread_count;
关于“Mysql5.7如何并行复制”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。