жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
MysqlеӯҳеӮЁеј•ж“ҺдёҺж•°жҚ®еӯҳеӮЁзҡ„еҺҹзҗҶжҳҜд»Җд№ҲпјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
дҪңдёәдёҖеҗҚејҖеҸ‘дәәе‘ҳпјҢеңЁж—Ҙеёёзҡ„е·ҘдҪңдёӯдјҡйҡҫд»ҘйҒҝе…Қең°жҺҘи§ҰеҲ°ж•°жҚ®еә“пјҢж— и®әжҳҜеҹәдәҺж–Ү件зҡ„ sqlite иҝҳжҳҜе·ҘзЁӢдёҠдҪҝз”Ёйқһеёёе№ҝжіӣзҡ„ MySQLгҖҒPostgreSQLпјҢдҪҶжҳҜдёҖзӣҙд»ҘжқҘд№ҹжІЎжңүеҜ№ж•°жҚ®еә“жңүдёҖдёӘйқһеёёжё…жҷ°е№¶дё”жҲҗдҪ“зі»зҡ„и®ӨзҹҘпјҢжүҖд»ҘжңҖиҝ‘дёӨдёӘжңҲзҡ„ж—¶й—ҙзңӢдәҶеҮ жң¬ж•°жҚ®еә“зӣёе…ізҡ„д№ҰзұҚ并且йҳ…иҜ»дәҶ MySQL зҡ„е®ҳж–№ж–ҮжЎЈпјҢеёҢжңӣеҜ№еҗ„дҪҚдәҶи§Јж•°жҚ®еә“зҡ„гҖҒдёҚдәҶи§Јж•°жҚ®еә“зҡ„жңүжүҖеё®еҠ©гҖӮ
ж–ҮдёӯеҜ№дәҺж•°жҚ®еә“зҡ„д»Ӣз»Қд»ҘеҸҠз ”з©¶йғҪжҳҜеңЁ MySQL дёҠиҝӣиЎҢзҡ„пјҢеҰӮжһңж¶үеҸҠеҲ°дәҶе…¶д»–ж•°жҚ®еә“зҡ„еҶ…е®№жҲ–иҖ…е®һзҺ°дјҡеңЁж–ҮдёӯеҚ•зӢ¬жҢҮеҮәгҖӮ
еҫҲеӨҡејҖеҸ‘иҖ…еңЁжңҖејҖе§Ӣж—¶е…¶е®һйғҪеҜ№ж•°жҚ®еә“жңүдёҖдёӘжҜ”иҫғжЁЎзіҠзҡ„и®ӨиҜҶпјҢи§үеҫ—ж•°жҚ®еә“е°ұжҳҜдёҖе Ҷж•°жҚ®зҡ„йӣҶеҗҲпјҢдҪҶжҳҜе®һйҷ…еҚҙжҜ”иҝҷеӨҚжқӮзҡ„еӨҡпјҢж•°жҚ®еә“йўҶеҹҹдёӯжңүдёӨдёӘиҜҚйқһеёёе®№жҳ“ж··ж·ҶпјҢд№ҹе°ұжҳҜж•°жҚ®еә“е’Ңе®һдҫӢпјҡ
ж•°жҚ®еә“пјҡзү©зҗҶж“ҚдҪңж–Ү件系з»ҹжҲ–е…¶д»–еҪўејҸж–Ү件зұ»еһӢзҡ„йӣҶеҗҲпјӣ
е®һдҫӢпјҡMySQL ж•°жҚ®еә“з”ұеҗҺеҸ°зәҝзЁӢд»ҘеҸҠдёҖдёӘе…ұдә«еҶ…еӯҳеҢәз»„жҲҗпјӣ
еҜ№дәҺж•°жҚ®еә“е’Ңе®һдҫӢзҡ„е®ҡд№үйғҪжқҘиҮӘдәҺ MySQL жҠҖжңҜеҶ…幕пјҡInnoDB еӯҳеӮЁеј•ж“Һ дёҖд№ҰпјҢжғіиҰҒдәҶи§Ј InnoDB еӯҳеӮЁеј•ж“Һзҡ„иҜ»иҖ…еҸҜд»Ҙйҳ…иҜ»иҝҷжң¬д№ҰзұҚгҖӮ
еңЁ MySQL дёӯпјҢе®һдҫӢе’Ңж•°жҚ®еә“еҫҖеҫҖйғҪжҳҜдёҖдёҖеҜ№еә”зҡ„пјҢиҖҢжҲ‘们д№ҹж— жі•зӣҙжҺҘж“ҚдҪңж•°жҚ®еә“пјҢиҖҢжҳҜиҰҒйҖҡиҝҮж•°жҚ®еә“е®һдҫӢжқҘж“ҚдҪңж•°жҚ®еә“ж–Ү件пјҢеҸҜд»ҘзҗҶи§Јдёәж•°жҚ®еә“е®һдҫӢжҳҜж•°жҚ®еә“дёәдёҠеұӮжҸҗдҫӣзҡ„дёҖдёӘдё“й—Ёз”ЁдәҺж“ҚдҪңзҡ„жҺҘеҸЈгҖӮ
еңЁ Unix дёҠпјҢеҗҜеҠЁдёҖдёӘ MySQL е®һдҫӢеҫҖеҫҖдјҡдә§з”ҹдёӨдёӘиҝӣзЁӢпјҢmysqld е°ұжҳҜзңҹжӯЈзҡ„ж•°жҚ®еә“жңҚеҠЎе®ҲжҠӨиҝӣзЁӢпјҢиҖҢ
mysqld_safe жҳҜдёҖдёӘз”ЁдәҺжЈҖжҹҘе’Ңи®ҫзҪ®
mysqld еҗҜеҠЁзҡ„жҺ§еҲ¶зЁӢеәҸпјҢе®ғиҙҹиҙЈзӣ‘жҺ§ MySQL иҝӣзЁӢзҡ„жү§иЎҢпјҢеҪ“
mysqld еҸ‘з”ҹй”ҷиҜҜж—¶пјҢmysqld_safe дјҡеҜ№е…¶зҠ¶жҖҒиҝӣиЎҢжЈҖжҹҘ并еңЁеҗҲйҖӮзҡ„жқЎд»¶дёӢйҮҚеҗҜгҖӮ
MySQL д»Һ第дёҖдёӘзүҲжң¬еҸ‘еёғеҲ°зҺ°еңЁе·Із»ҸжңүдәҶ 20 еӨҡе№ҙзҡ„еҺҶеҸІпјҢеңЁиҝҷд№ҲеӨҡе№ҙзҡ„еҸ‘еұ•е’Ңжј”еҸҳдёӯпјҢж•ҙдёӘеә”з”Ёзҡ„дҪ“зі»з»“жһ„еҸҳеҫ—и¶ҠжқҘи¶ҠеӨҚжқӮпјҡ
жңҖдёҠеұӮз”ЁдәҺиҝһжҺҘгҖҒзәҝзЁӢеӨ„зҗҶзҡ„йғЁеҲҶ并дёҚжҳҜ MySQL гҖҺеҸ‘жҳҺгҖҸзҡ„пјҢеҫҲеӨҡжңҚеҠЎйғҪжңүзұ»дјјзҡ„з»„жҲҗйғЁеҲҶпјӣ第дәҢеұӮдёӯеҢ…еҗ«дәҶеӨ§еӨҡж•° MySQL зҡ„ж ёеҝғжңҚеҠЎпјҢеҢ…жӢ¬дәҶеҜ№ SQL зҡ„и§ЈжһҗгҖҒеҲҶжһҗгҖҒдјҳеҢ–е’Ңзј“еӯҳзӯүеҠҹиғҪпјҢеӯҳеӮЁиҝҮзЁӢгҖҒи§ҰеҸ‘еҷЁе’Ңи§ҶеӣҫйғҪжҳҜеңЁиҝҷйҮҢе®һзҺ°зҡ„пјӣиҖҢ第дёүеұӮе°ұжҳҜ MySQL дёӯзңҹжӯЈиҙҹиҙЈж•°жҚ®зҡ„еӯҳеӮЁе’ҢжҸҗеҸ–зҡ„еӯҳеӮЁеј•ж“ҺпјҢдҫӢеҰӮпјҡ InnoDBгҖҒ MyISAM зӯүпјҢж–ҮдёӯеҜ№еӯҳеӮЁеј•ж“Һзҡ„д»Ӣз»ҚйғҪжҳҜеҜ№ InnoDB е®һзҺ°зҡ„еҲҶжһҗгҖӮ
еңЁж•ҙдёӘж•°жҚ®еә“дҪ“зі»з»“жһ„дёӯпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁдёҚеҗҢзҡ„еӯҳеӮЁеј•ж“ҺжқҘеӯҳеӮЁж•°жҚ®пјҢиҖҢз»қеӨ§еӨҡж•°еӯҳеӮЁеј•ж“ҺйғҪд»ҘдәҢиҝӣеҲ¶зҡ„еҪўејҸеӯҳеӮЁж•°жҚ®пјӣиҝҷдёҖиҠӮдјҡд»Ӣз»Қ InnoDB дёӯеҜ№ж•°жҚ®жҳҜеҰӮдҪ•еӯҳеӮЁзҡ„гҖӮ
еңЁ InnoDB еӯҳеӮЁеј•ж“ҺдёӯпјҢжүҖжңүзҡ„ж•°жҚ®йғҪиў«йҖ»иҫ‘ең°еӯҳж”ҫеңЁиЎЁз©әй—ҙдёӯпјҢиЎЁз©әй—ҙпјҲtablespaceпјүжҳҜеӯҳеӮЁеј•ж“ҺдёӯжңҖй«ҳзҡ„еӯҳеӮЁйҖ»иҫ‘еҚ•дҪҚпјҢеңЁиЎЁз©әй—ҙзҡ„дёӢйқўеҸҲеҢ…жӢ¬ж®өпјҲsegmentпјүгҖҒеҢәпјҲextentпјүгҖҒйЎөпјҲpageпјүпјҡ
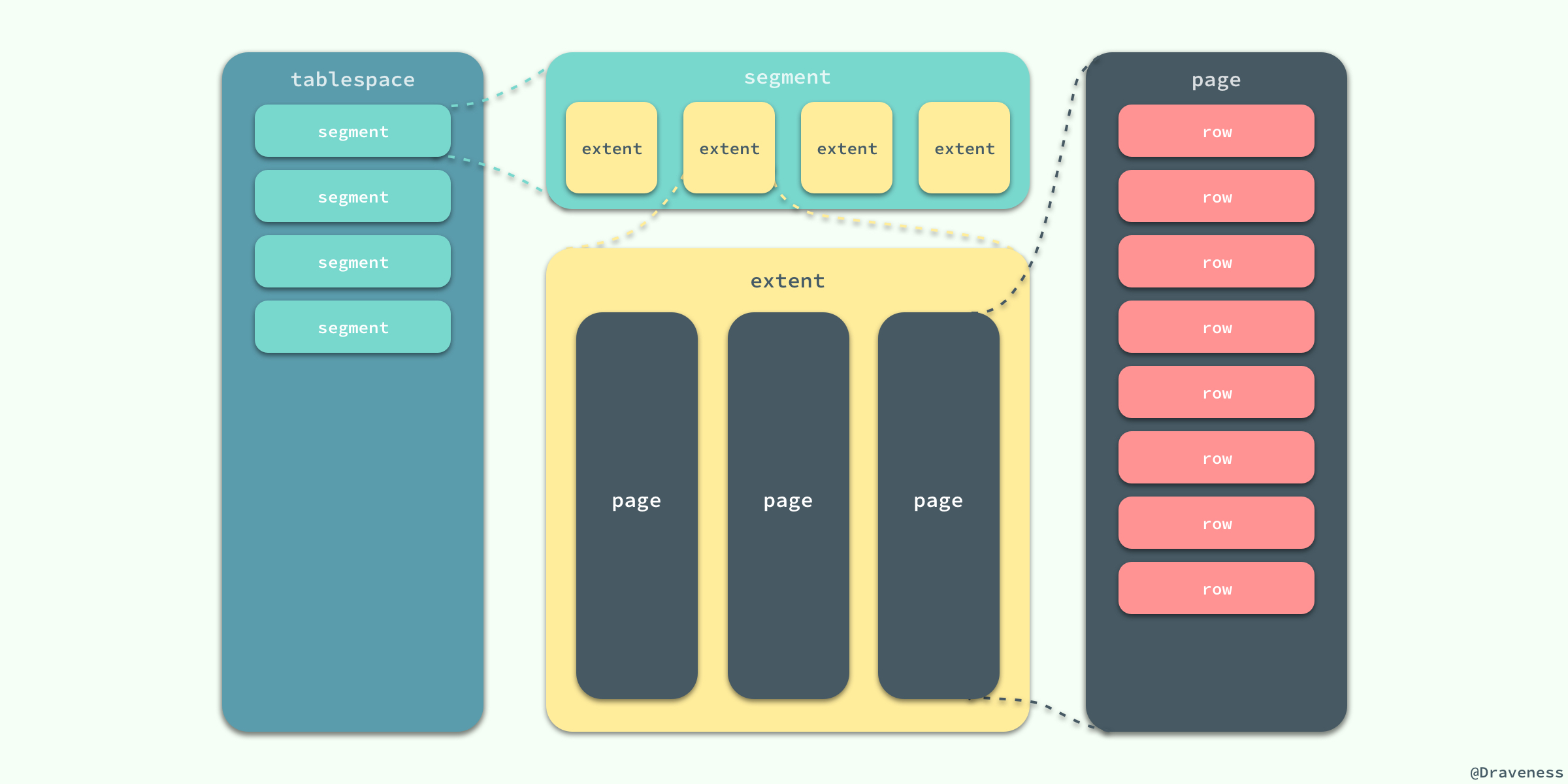
еҗҢдёҖдёӘж•°жҚ®еә“е®һдҫӢзҡ„жүҖжңүиЎЁз©әй—ҙйғҪжңүзӣёеҗҢзҡ„йЎөеӨ§е°Ҹпјӣй»ҳи®Өжғ…еҶөдёӢпјҢиЎЁз©әй—ҙдёӯзҡ„йЎөеӨ§е°ҸйғҪдёә 16KBпјҢеҪ“然д№ҹеҸҜд»ҘйҖҡиҝҮж”№еҸҳ
innodb_page_size йҖүйЎ№еҜ№й»ҳи®ӨеӨ§е°ҸиҝӣиЎҢдҝ®ж”№пјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜдёҚеҗҢзҡ„йЎөеӨ§е°ҸжңҖз»Ҳд№ҹдјҡеҜјиҮҙеҢәеӨ§е°Ҹзҡ„дёҚеҗҢпјҡ
еңЁ InnoDB еӯҳеӮЁеј•ж“ҺдёӯпјҢдёҖдёӘеҢәзҡ„еӨ§е°ҸжңҖе°Ҹдёә 1MBпјҢйЎөзҡ„ж•°йҮҸжңҖе°‘дёә 64 дёӘгҖӮ
MySQL дҪҝз”Ё InnoDB еӯҳеӮЁиЎЁж—¶пјҢдјҡе°ҶиЎЁзҡ„е®ҡд№үе’Ңж•°жҚ®зҙўеј•зӯүдҝЎжҒҜеҲҶејҖеӯҳеӮЁпјҢе…¶дёӯеүҚиҖ…еӯҳеӮЁеңЁ
.frm ж–Ү件дёӯпјҢеҗҺиҖ…еӯҳеӮЁеңЁ
.ibd ж–Ү件дёӯпјҢиҝҷдёҖиҠӮе°ұдјҡеҜ№иҝҷдёӨз§ҚдёҚеҗҢзҡ„ж–Ү件еҲҶеҲ«иҝӣиЎҢд»Ӣз»ҚгҖӮ
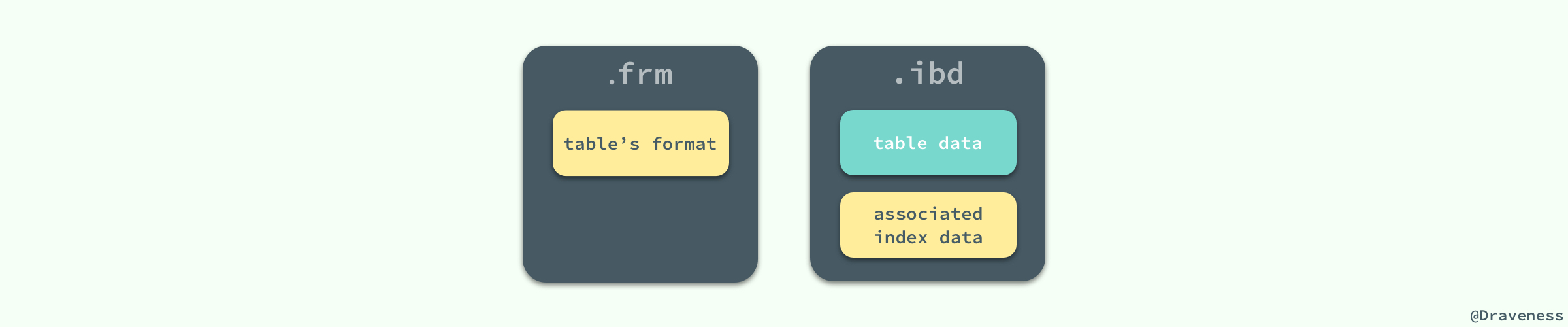
ж— и®әеңЁ MySQL дёӯйҖүжӢ©дәҶе“ӘдёӘеӯҳеӮЁеј•ж“ҺпјҢжүҖжңүзҡ„ MySQL иЎЁйғҪдјҡеңЁзЎ¬зӣҳдёҠеҲӣе»әдёҖдёӘ
.frm ж–Ү件用жқҘжҸҸиҝ°иЎЁзҡ„ж јејҸжҲ–иҖ…иҜҙе®ҡд№үпјӣ.frm ж–Ү件зҡ„ж јејҸеңЁдёҚеҗҢзҡ„е№іеҸ°дёҠйғҪжҳҜзӣёеҗҢзҡ„гҖӮ
CREATE TABLE test_frm( column1 CHAR(5), column2 INTEGER );
еҪ“жҲ‘们дҪҝз”ЁдёҠйқўзҡ„д»Јз ҒеҲӣе»әиЎЁж—¶пјҢдјҡеңЁзЈҒзӣҳдёҠзҡ„
datadir ж–Ү件еӨ№дёӯз”ҹжҲҗдёҖдёӘ
test_frm.frm зҡ„ж–Ү件пјҢиҝҷдёӘж–Ү件дёӯе°ұеҢ…еҗ«дәҶиЎЁз»“жһ„зӣёе…ізҡ„дҝЎжҒҜпјҡ
MySQL е®ҳж–№ж–ҮжЎЈдёӯзҡ„ 11.1 MySQL .frm File Format дёҖж–ҮеҜ№дәҺ
.frmж–Үд»¶ж јејҸдёӯзҡ„дәҢиҝӣеҲ¶зҡ„еҶ…е®№жңүзқҖйқһеёёиҜҰз»Ҷзҡ„иЎЁиҝ°пјҢеңЁиҝҷйҮҢе°ұдёҚеұ•ејҖд»Ӣз»ҚдәҶгҖӮ
InnoDB дёӯз”ЁдәҺеӯҳеӮЁж•°жҚ®зҡ„ж–Ү件жҖ»е…ұжңүдёӨдёӘйғЁеҲҶпјҢдёҖжҳҜзі»з»ҹиЎЁз©әй—ҙж–Ү件пјҢеҢ…жӢ¬
ibdata1гҖҒibdata2 зӯүж–Ү件пјҢе…¶дёӯеӯҳеӮЁдәҶ InnoDB зі»з»ҹдҝЎжҒҜе’Ңз”ЁжҲ·ж•°жҚ®еә“иЎЁж•°жҚ®е’Ңзҙўеј•пјҢжҳҜжүҖжңүиЎЁе…¬з”Ёзҡ„гҖӮ
еҪ“жү“ејҖ
innodb_file_per_table йҖүйЎ№ж—¶пјҢ.ibd ж–Ү件е°ұжҳҜжҜҸдёҖдёӘиЎЁзӢ¬жңүзҡ„иЎЁз©әй—ҙпјҢж–Ү件еӯҳеӮЁдәҶеҪ“еүҚиЎЁзҡ„ж•°жҚ®е’Ңзӣёе…ізҡ„зҙўеј•ж•°жҚ®гҖӮ
дёҺзҺ°жңүзҡ„еӨ§еӨҡж•°еӯҳеӮЁеј•ж“ҺдёҖж ·пјҢInnoDB дҪҝз”ЁйЎөдҪңдёәзЈҒзӣҳз®ЎзҗҶзҡ„жңҖе°ҸеҚ•дҪҚпјӣж•°жҚ®еңЁ InnoDB еӯҳеӮЁеј•ж“ҺдёӯйғҪжҳҜжҢүиЎҢеӯҳеӮЁзҡ„пјҢжҜҸдёӘ 16KB еӨ§е°Ҹзҡ„йЎөдёӯеҸҜд»Ҙеӯҳж”ҫ 2-200 иЎҢзҡ„и®°еҪ•гҖӮ
еҪ“ InnoDB еӯҳеӮЁж•°жҚ®ж—¶пјҢе®ғеҸҜд»ҘдҪҝз”ЁдёҚеҗҢзҡ„иЎҢж јејҸиҝӣиЎҢеӯҳеӮЁпјӣMySQL 5.7 зүҲжң¬ж”ҜжҢҒд»ҘдёӢж јејҸзҡ„иЎҢеӯҳеӮЁж–№ејҸпјҡ

Antelope жҳҜ InnoDB жңҖејҖе§Ӣж”ҜжҢҒзҡ„ж–Үд»¶ж јејҸпјҢе®ғеҢ…еҗ«дёӨз§ҚиЎҢж јејҸ Compact е’Ң RedundantпјҢе®ғжңҖејҖе§Ӣ并没жңүеҗҚеӯ—пјӣAntelope зҡ„еҗҚеӯ—жҳҜеңЁж–°зҡ„ж–Үд»¶ж јејҸ Barracuda еҮәзҺ°еҗҺжүҚиө·зҡ„пјҢBarracuda зҡ„еҮәзҺ°еј•е…ҘдәҶдёӨз§Қж–°зҡ„иЎҢж јејҸ Compressed е’Ң DynamicпјӣInnoDB еҜ№дәҺж–Үд»¶ж јејҸйғҪдјҡеҗ‘еүҚе…је®№пјҢиҖҢе®ҳж–№ж–ҮжЎЈдёӯд№ҹеҜ№д№ӢеҗҺдјҡеҮәзҺ°зҡ„ж–°ж–Үд»¶ж јејҸйў„е…Ҳе®ҡд№үеҘҪдәҶеҗҚеӯ—пјҡCheetahгҖҒDragonгҖҒElk зӯүзӯүгҖӮ
дёӨз§ҚиЎҢи®°еҪ•ж јејҸ Compact е’Ң Redundant еңЁзЈҒзӣҳдёҠжҢүз…§д»ҘдёӢж–№ејҸеӯҳеӮЁпјҡ
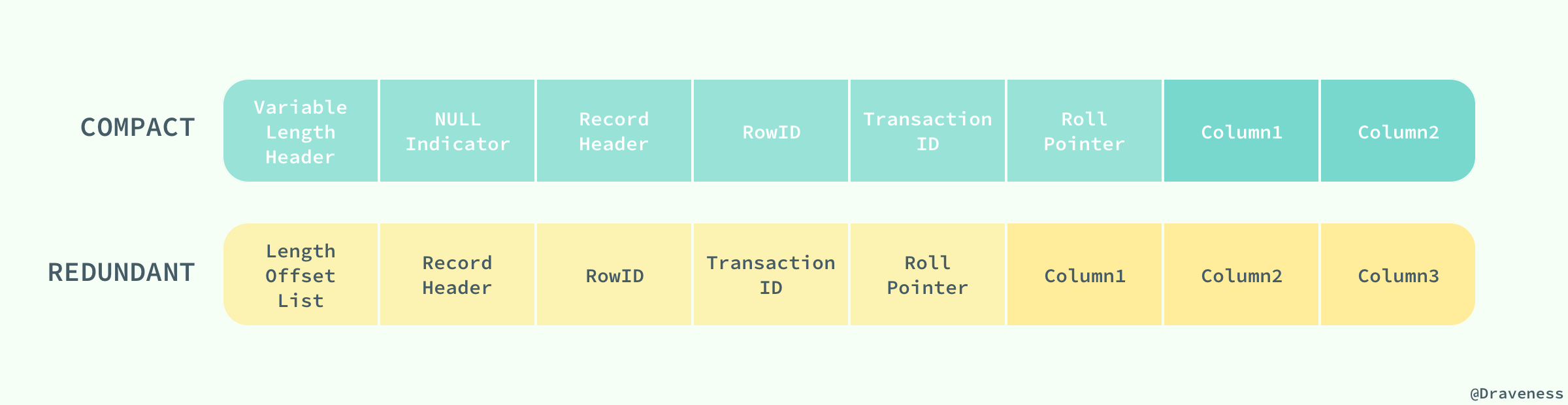
Compact е’Ң Redundant ж јејҸжңҖеӨ§зҡ„дёҚеҗҢе°ұжҳҜи®°еҪ•ж јејҸзҡ„第дёҖдёӘйғЁеҲҶпјӣеңЁ Compact дёӯпјҢиЎҢи®°еҪ•зҡ„第дёҖйғЁеҲҶеҖ’еәҸеӯҳж”ҫдәҶдёҖиЎҢж•°жҚ®дёӯеҲ—зҡ„й•ҝеәҰпјҲLengthпјүпјҢиҖҢ Redundant дёӯеӯҳзҡ„жҳҜжҜҸдёҖеҲ—зҡ„еҒҸ移йҮҸпјҲOffsetпјүпјҢд»ҺжҖ»дҪ“дёҠдёҠзңӢпјҢCompact иЎҢи®°еҪ•ж јејҸзӣёжҜ” Redundant ж јејҸиғҪеӨҹеҮҸе°‘ 20% зҡ„еӯҳеӮЁз©әй—ҙгҖӮ
еҪ“ InnoDB дҪҝз”Ё Compact жҲ–иҖ… Redundant ж јејҸеӯҳеӮЁжһҒй•ҝзҡ„ VARCHAR жҲ–иҖ… BLOB иҝҷзұ»еӨ§еҜ№иұЎж—¶пјҢжҲ‘们并дёҚдјҡзӣҙжҺҘе°ҶжүҖжңүзҡ„еҶ…е®№йғҪеӯҳж”ҫеңЁж•°жҚ®йЎөиҠӮзӮ№дёӯпјҢиҖҢжҳҜе°ҶиЎҢж•°жҚ®дёӯзҡ„еүҚ 768 дёӘеӯ—иҠӮеӯҳеӮЁеңЁж•°жҚ®йЎөдёӯпјҢеҗҺйқўдјҡйҖҡиҝҮеҒҸ移йҮҸжҢҮеҗ‘жәўеҮәйЎөгҖӮ

дҪҶжҳҜеҪ“жҲ‘们дҪҝз”Ёж–°зҡ„иЎҢи®°еҪ•ж јејҸ Compressed жҲ–иҖ… Dynamic ж—¶йғҪеҸӘдјҡеңЁиЎҢи®°еҪ•дёӯдҝқеӯҳ 20 дёӘеӯ—иҠӮзҡ„жҢҮй’ҲпјҢе®һйҷ…зҡ„ж•°жҚ®йғҪдјҡеӯҳж”ҫеңЁжәўеҮәйЎөйқўдёӯгҖӮ
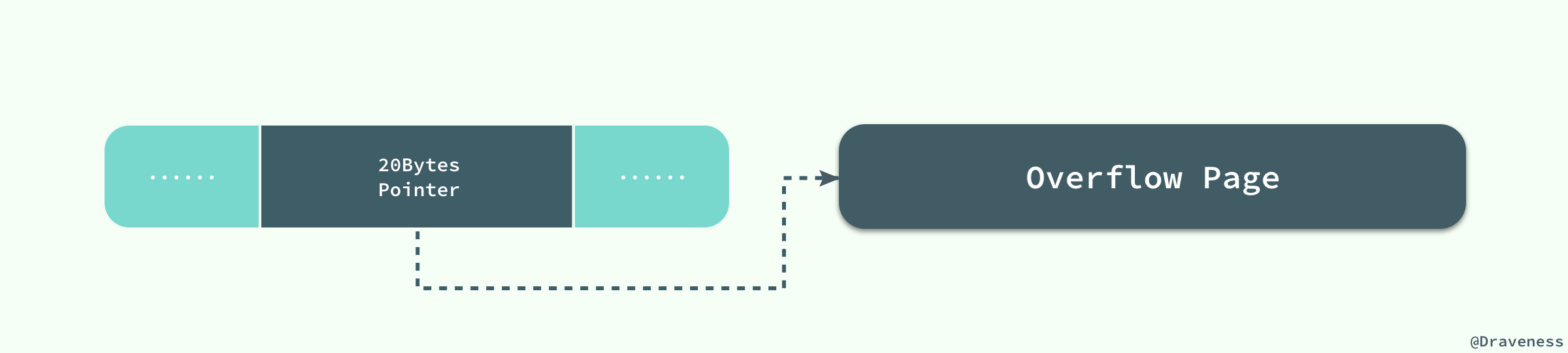
еҪ“然еңЁе®һйҷ…еӯҳеӮЁдёӯпјҢеҸҜиғҪдјҡеҜ№дёҚеҗҢй•ҝеәҰзҡ„ TEXT е’Ң BLOB еҲ—иҝӣиЎҢдјҳеҢ–пјҢдёҚиҝҮиҝҷе°ұдёҚжҳҜжң¬ж–Үе…іжіЁзҡ„йҮҚзӮ№дәҶгҖӮ
жғіиҰҒдәҶи§ЈжӣҙеӨҡдёҺ InnoDB еӯҳеӮЁеј•ж“Һдёӯи®°еҪ•зҡ„ж•°жҚ®ж јејҸзҡ„зӣёе…ідҝЎжҒҜпјҢеҸҜд»Ҙйҳ…иҜ» InnoDB Record Structure
йЎөжҳҜ InnoDB еӯҳеӮЁеј•ж“Һз®ЎзҗҶж•°жҚ®зҡ„жңҖе°ҸзЈҒзӣҳеҚ•дҪҚпјҢиҖҢ B-Tree иҠӮзӮ№е°ұжҳҜе®һйҷ…еӯҳж”ҫиЎЁдёӯж•°жҚ®зҡ„йЎөйқўпјҢжҲ‘们еңЁиҝҷйҮҢе°ҶиҰҒд»Ӣз»ҚйЎөжҳҜеҰӮдҪ•з»„з»Үе’ҢеӯҳеӮЁи®°еҪ•зҡ„пјӣйҰ–е…ҲпјҢдёҖдёӘ InnoDB йЎөжңүд»ҘдёӢдёғдёӘйғЁеҲҶпјҡ

жҜҸдёҖдёӘйЎөдёӯеҢ…еҗ«дәҶдёӨеҜ№ header/trailerпјҡеҶ…йғЁзҡ„ Page Header/Page Directory е…іеҝғзҡ„жҳҜйЎөзҡ„зҠ¶жҖҒдҝЎжҒҜпјҢиҖҢ Fil Header/Fil Trailer е…іеҝғзҡ„жҳҜи®°еҪ•йЎөзҡ„еӨҙдҝЎжҒҜгҖӮ
еңЁйЎөзҡ„еӨҙйғЁе’Ңе°ҫйғЁд№Ӣй—ҙе°ұжҳҜз”ЁжҲ·и®°еҪ•е’Ңз©әй—Із©әй—ҙдәҶпјҢжҜҸдёҖдёӘж•°жҚ®йЎөдёӯйғҪеҢ…еҗ« Infimum е’Ң Supremum иҝҷдёӨдёӘиҷҡжӢҹзҡ„и®°еҪ•пјҲеҸҜд»ҘзҗҶи§ЈдёәеҚ дҪҚз¬ҰпјүпјҢInfimum и®°еҪ•жҳҜжҜ”иҜҘйЎөдёӯд»»дҪ•дё»й”®еҖјйғҪиҰҒе°Ҹзҡ„еҖјпјҢSupremum жҳҜиҜҘйЎөдёӯзҡ„жңҖеӨ§еҖјпјҡ

User Records е°ұжҳҜж•ҙдёӘйЎөйқўдёӯзңҹжӯЈз”ЁдәҺеӯҳж”ҫиЎҢи®°еҪ•зҡ„йғЁеҲҶпјҢиҖҢ Free Space е°ұжҳҜз©әдҪҷз©әй—ҙдәҶпјҢе®ғжҳҜдёҖдёӘй“ҫиЎЁзҡ„ж•°жҚ®з»“жһ„пјҢдёәдәҶдҝқиҜҒжҸ’е…Ҙе’ҢеҲ йҷӨзҡ„ж•ҲзҺҮпјҢж•ҙдёӘйЎөйқўе№¶дёҚдјҡжҢүз…§дё»й”®йЎәеәҸеҜ№жүҖжңүи®°еҪ•иҝӣиЎҢжҺ’еәҸпјҢе®ғдјҡиҮӘеҠЁд»Һе·Ұдҫ§еҗ‘еҸіеҜ»жүҫз©әзҷҪиҠӮзӮ№иҝӣиЎҢжҸ’е…ҘпјҢиЎҢи®°еҪ•еңЁзү©зҗҶеӯҳеӮЁдёҠ并дёҚжҳҜжҢүз…§йЎәеәҸзҡ„пјҢе®ғ们д№Ӣй—ҙзҡ„йЎәеәҸжҳҜз”ұ
next_record иҝҷдёҖжҢҮй’ҲжҺ§еҲ¶зҡ„гҖӮ
B+ ж ‘еңЁжҹҘжүҫеҜ№еә”зҡ„и®°еҪ•ж—¶пјҢ并дёҚдјҡзӣҙжҺҘд»Һж ‘дёӯжүҫеҮәеҜ№еә”зҡ„иЎҢи®°еҪ•пјҢе®ғеҸӘиғҪиҺ·еҸ–и®°еҪ•жүҖеңЁзҡ„йЎөпјҢе°Ҷж•ҙдёӘйЎөеҠ иҪҪеҲ°еҶ…еӯҳдёӯпјҢеҶҚйҖҡиҝҮ Page Directory дёӯеӯҳеӮЁзҡ„зЁҖз–Ҹзҙўеј•е’Ң
n_ownedгҖҒnext_record еұһжҖ§еҸ–еҮәеҜ№еә”зҡ„и®°еҪ•пјҢдёҚиҝҮеӣ дёәиҝҷдёҖж“ҚдҪңжҳҜеңЁеҶ…еӯҳдёӯиҝӣиЎҢзҡ„пјҢжүҖд»ҘйҖҡеёёдјҡеҝҪз•ҘиҝҷйғЁеҲҶжҹҘжүҫзҡ„иҖ—ж—¶гҖӮ
InnoDB еӯҳеӮЁеј•ж“ҺдёӯеҜ№ж•°жҚ®зҡ„еӯҳеӮЁжҳҜдёҖдёӘйқһеёёеӨҚжқӮзҡ„иҜқйўҳпјҢиҝҷдёҖиҠӮдёӯд№ҹеҸӘжҳҜеҜ№иЎЁгҖҒиЎҢи®°еҪ•д»ҘеҸҠйЎөйқўзҡ„еӯҳеӮЁиҝӣиЎҢдёҖе®ҡзҡ„еҲҶжһҗе’Ңд»Ӣз»ҚпјҢиҷҪ然дҪңиҖ…зӣёдҝЎиҝҷйғЁеҲҶзҹҘиҜҶеҜ№дәҺеӨ§йғЁеҲҶејҖеҸ‘иҖ…е·Із»Ҹи¶іеӨҹдәҶпјҢдҪҶжҳҜжғіиҰҒзңҹжӯЈж¶ҲеҢ–иҝҷйғЁеҲҶеҶ…е®№иҝҳйңҖиҰҒеҫҲеӨҡзҡ„еҠӘеҠӣе’Ңе®һи·өгҖӮ
зҙўеј•жҳҜж•°жҚ®еә“дёӯйқһеёёйқһеёёйҮҚиҰҒзҡ„жҰӮеҝөпјҢе®ғжҳҜеӯҳеӮЁеј•ж“ҺиғҪеӨҹеҝ«йҖҹе®ҡдҪҚи®°еҪ•зҡ„з§ҳеҜҶжӯҰеҷЁпјҢеҜ№дәҺжҸҗеҚҮж•°жҚ®еә“зҡ„жҖ§иғҪгҖҒеҮҸиҪ»ж•°жҚ®еә“жңҚеҠЎеҷЁзҡ„иҙҹжӢ…жңүзқҖйқһеёёйҮҚиҰҒзҡ„дҪңз”Ёпјӣзҙўеј•дјҳеҢ–жҳҜеҜ№жҹҘиҜўжҖ§иғҪдјҳеҢ–зҡ„жңҖжңүж•ҲжүӢж®өпјҢе®ғиғҪеӨҹиҪ»жқҫең°е°ҶжҹҘиҜўзҡ„жҖ§иғҪжҸҗй«ҳеҮ дёӘж•°йҮҸзә§гҖӮ
еңЁдёҠдёҖиҠӮдёӯпјҢжҲ‘们и°ҲдәҶиЎҢи®°еҪ•зҡ„еӯҳеӮЁе’ҢйЎөзҡ„еӯҳеӮЁпјҢеңЁиҝҷйҮҢжҲ‘们е°ұиҰҒд»Һжӣҙй«ҳзҡ„еұӮйқўзңӢ InnoDB дёӯеҜ№дәҺж•°жҚ®жҳҜеҰӮдҪ•еӯҳеӮЁзҡ„пјӣInnoDB еӯҳеӮЁеј•ж“ҺеңЁз»қеӨ§еӨҡж•°жғ…еҶөдёӢдҪҝз”Ё B+ ж ‘е»әз«Ӣзҙўеј•пјҢиҝҷжҳҜе…ізі»еһӢж•°жҚ®еә“дёӯжҹҘжүҫжңҖдёәеёёз”Ёе’Ңжңүж•Ҳзҡ„зҙўеј•пјҢдҪҶжҳҜ B+ ж ‘зҙўеј•е№¶дёҚиғҪжүҫеҲ°дёҖдёӘз»ҷе®ҡй”®еҜ№еә”зҡ„е…·дҪ“еҖјпјҢе®ғеҸӘиғҪжүҫеҲ°ж•°жҚ®иЎҢеҜ№еә”зҡ„йЎөпјҢ然еҗҺжӯЈеҰӮдёҠдёҖиҠӮжүҖжҸҗеҲ°зҡ„пјҢж•°жҚ®еә“жҠҠж•ҙдёӘйЎөиҜ»е…ҘеҲ°еҶ…еӯҳдёӯпјҢ并еңЁеҶ…еӯҳдёӯжҹҘжүҫе…·дҪ“зҡ„ж•°жҚ®иЎҢгҖӮ
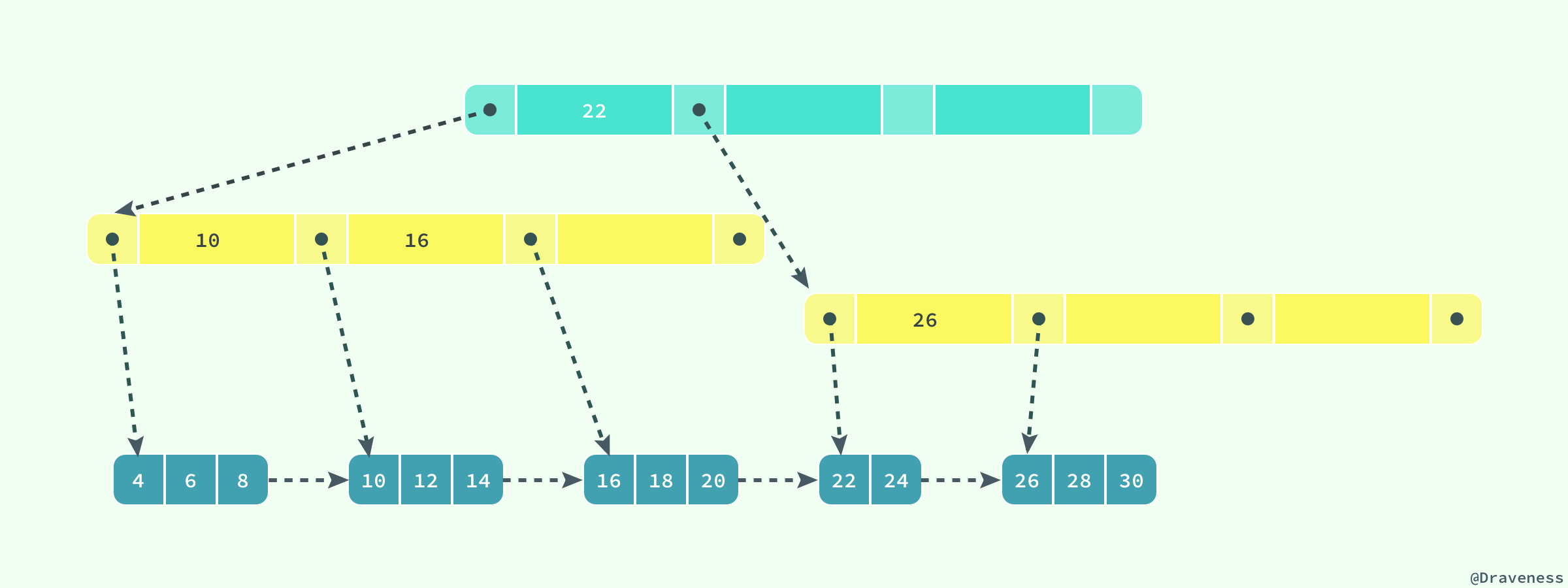
B+ ж ‘жҳҜе№іиЎЎж ‘пјҢе®ғжҹҘжүҫд»»ж„ҸиҠӮзӮ№жүҖиҖ—иҙ№зҡ„ж—¶й—ҙйғҪжҳҜе®Ңе…ЁзӣёеҗҢзҡ„пјҢжҜ”иҫғзҡ„ж¬Ўж•°е°ұжҳҜ B+ ж ‘зҡ„й«ҳеәҰпјӣеңЁиҝҷйҮҢпјҢжҲ‘们并дёҚдјҡж·ұе…ҘеҲҶжһҗжҲ–иҖ…еҠЁжүӢе®һзҺ°дёҖдёӘ B+ ж ‘пјҢеҸӘжҳҜеҜ№е®ғзҡ„зү№жҖ§иҝӣиЎҢз®ҖеҚ•зҡ„д»Ӣз»ҚгҖӮ
ж•°жҚ®еә“дёӯзҡ„ B+ ж ‘зҙўеј•еҸҜд»ҘеҲҶдёәиҒҡйӣҶзҙўеј•пјҲclustered indexпјүе’Ңиҫ…еҠ©зҙўеј•пјҲsecondary indexпјүпјҢе®ғ们д№Ӣй—ҙзҡ„жңҖеӨ§еҢәеҲ«е°ұжҳҜпјҢиҒҡйӣҶзҙўеј•дёӯеӯҳж”ҫзқҖдёҖжқЎиЎҢи®°еҪ•зҡ„е…ЁйғЁдҝЎжҒҜпјҢиҖҢиҫ…еҠ©зҙўеј•дёӯеҸӘеҢ…еҗ«зҙўеј•еҲ—е’ҢдёҖдёӘз”ЁдәҺжҹҘжүҫеҜ№еә”иЎҢи®°еҪ•зҡ„гҖҺд№ҰзӯҫгҖҸгҖӮ
InnoDB еӯҳеӮЁеј•ж“Һдёӯзҡ„иЎЁйғҪжҳҜдҪҝз”Ёзҙўеј•з»„з»Үзҡ„пјҢд№ҹе°ұжҳҜжҢүз…§й”®зҡ„йЎәеәҸеӯҳж”ҫпјӣиҒҡйӣҶзҙўеј•е°ұжҳҜжҢүз…§иЎЁдёӯдё»й”®зҡ„йЎәеәҸжһ„е»әдёҖйў— B+ ж ‘пјҢ并еңЁеҸ¶иҠӮзӮ№дёӯеӯҳж”ҫиЎЁдёӯзҡ„иЎҢи®°еҪ•ж•°жҚ®гҖӮ
CREATE TABLE users( id INT NOT NULL, first_name VARCHAR(20) NOT NULL, last_name VARCHAR(20) NOT NULL, age INT NOT NULL, PRIMARY KEY(id), KEY(last_name, first_name, age) KEY(first_name) );
еҰӮжһңдҪҝз”ЁдёҠйқўзҡ„ SQL еңЁж•°жҚ®еә“дёӯеҲӣе»әдёҖеј иЎЁпјҢB+ ж ‘е°ұдјҡдҪҝз”Ё
id дҪңдёәзҙўеј•зҡ„й”®пјҢ并еңЁеҸ¶еӯҗиҠӮзӮ№дёӯеӯҳеӮЁдёҖжқЎи®°еҪ•дёӯзҡ„жүҖжңүдҝЎжҒҜгҖӮ
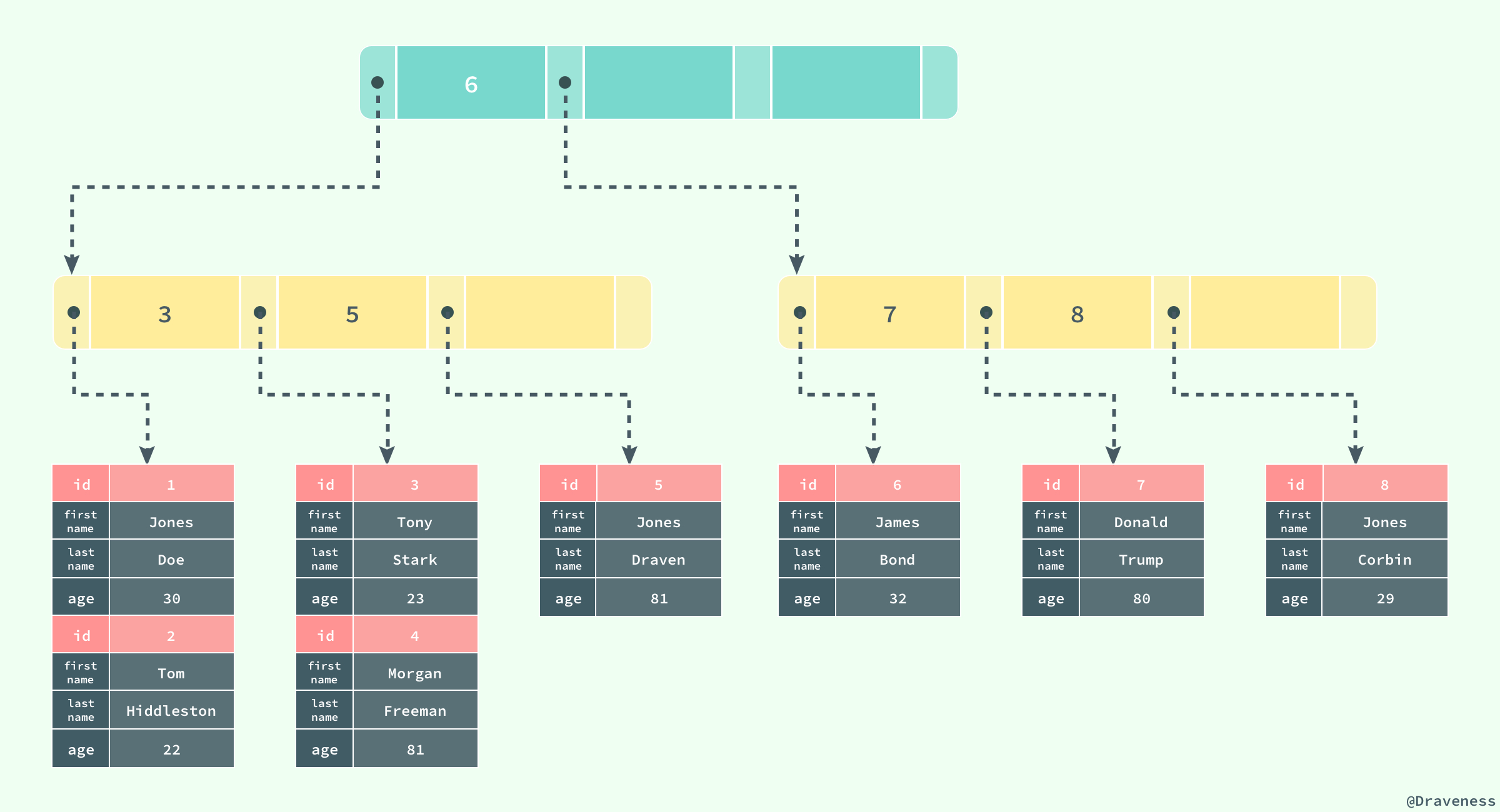
еӣҫдёӯеҜ№ B+ ж ‘зҡ„жҸҸиҝ°дёҺзңҹе®һжғ…еҶөдёӢ B+ ж ‘дёӯзҡ„ж•°жҚ®з»“жһ„жңүдёҖдәӣе·®еҲ«пјҢдёҚиҝҮиҝҷйҮҢжғіиҰҒиЎЁиҫҫзҡ„дё»иҰҒж„ҸжҖқжҳҜпјҡиҒҡйӣҶзҙўеј•еҸ¶иҠӮзӮ№дёӯдҝқеӯҳзҡ„жҳҜж•ҙжқЎиЎҢи®°еҪ•пјҢиҖҢдёҚжҳҜе…¶дёӯзҡ„дёҖйғЁеҲҶгҖӮ
иҒҡйӣҶзҙўеј•дёҺиЎЁзҡ„зү©зҗҶеӯҳеӮЁж–№ејҸжңүзқҖйқһеёёеҜҶеҲҮзҡ„е…ізі»пјҢжүҖжңүжӯЈеёёзҡ„иЎЁеә”иҜҘжңүдё”д»…жңүдёҖдёӘиҒҡйӣҶзҙўеј•пјҲз»қеӨ§еӨҡж•°жғ…еҶөдёӢйғҪжҳҜдё»й”®пјүпјҢиЎЁдёӯзҡ„жүҖжңүиЎҢи®°еҪ•ж•°жҚ®йғҪжҳҜжҢүз…§иҒҡйӣҶзҙўеј•зҡ„йЎәеәҸеӯҳж”ҫзҡ„гҖӮ
еҪ“жҲ‘们дҪҝз”ЁиҒҡйӣҶзҙўеј•еҜ№иЎЁдёӯзҡ„ж•°жҚ®иҝӣиЎҢжЈҖзҙўж—¶пјҢеҸҜд»ҘзӣҙжҺҘиҺ·еҫ—иҒҡйӣҶзҙўеј•жүҖеҜ№еә”зҡ„ж•ҙжқЎиЎҢи®°еҪ•ж•°жҚ®жүҖеңЁзҡ„йЎөпјҢдёҚйңҖиҰҒиҝӣиЎҢ第дәҢж¬Ўж“ҚдҪңгҖӮ
ж•°жҚ®еә“е°ҶжүҖжңүзҡ„йқһиҒҡйӣҶзҙўеј•йғҪеҲ’еҲҶдёәиҫ…еҠ©зҙўеј•пјҢдҪҶжҳҜиҝҷдёӘжҰӮеҝөеҜ№жҲ‘们зҗҶи§Јиҫ…еҠ©зҙўеј•е№¶жІЎжңүд»Җд№Ҳеё®еҠ©пјӣиҫ…еҠ©зҙўеј•д№ҹжҳҜйҖҡиҝҮ B+ ж ‘е®һзҺ°зҡ„пјҢдҪҶжҳҜе®ғзҡ„еҸ¶иҠӮзӮ№е№¶дёҚеҢ…еҗ«иЎҢи®°еҪ•зҡ„е…ЁйғЁж•°жҚ®пјҢд»…еҢ…еҗ«зҙўеј•дёӯзҡ„жүҖжңүй”®е’ҢдёҖдёӘз”ЁдәҺжҹҘжүҫеҜ№еә”иЎҢи®°еҪ•зҡ„гҖҺд№ҰзӯҫгҖҸпјҢеңЁ InnoDB дёӯиҝҷдёӘд№Ұзӯҫе°ұжҳҜеҪ“еүҚи®°еҪ•зҡ„дё»й”®гҖӮ
иҫ…еҠ©зҙўеј•зҡ„еӯҳеңЁе№¶дёҚдјҡеҪұе“ҚиҒҡйӣҶзҙўеј•пјҢеӣ дёәиҒҡйӣҶзҙўеј•жһ„жҲҗзҡ„ B+ ж ‘жҳҜж•°жҚ®е®һйҷ…еӯҳеӮЁзҡ„еҪўејҸпјҢиҖҢиҫ…еҠ©зҙўеј•еҸӘз”ЁдәҺеҠ йҖҹж•°жҚ®зҡ„жҹҘжүҫпјҢжүҖд»ҘдёҖеј иЎЁдёҠеҫҖеҫҖжңүеӨҡдёӘиҫ…еҠ©зҙўеј•д»ҘжӯӨжқҘжҸҗеҚҮж•°жҚ®еә“зҡ„жҖ§иғҪгҖӮ
дёҖеј иЎЁдёҖе®ҡеҢ…еҗ«дёҖдёӘиҒҡйӣҶзҙўеј•жһ„жҲҗзҡ„ B+ ж ‘д»ҘеҸҠиӢҘе№Іиҫ…еҠ©зҙўеј•зҡ„жһ„жҲҗзҡ„ B+ ж ‘гҖӮ
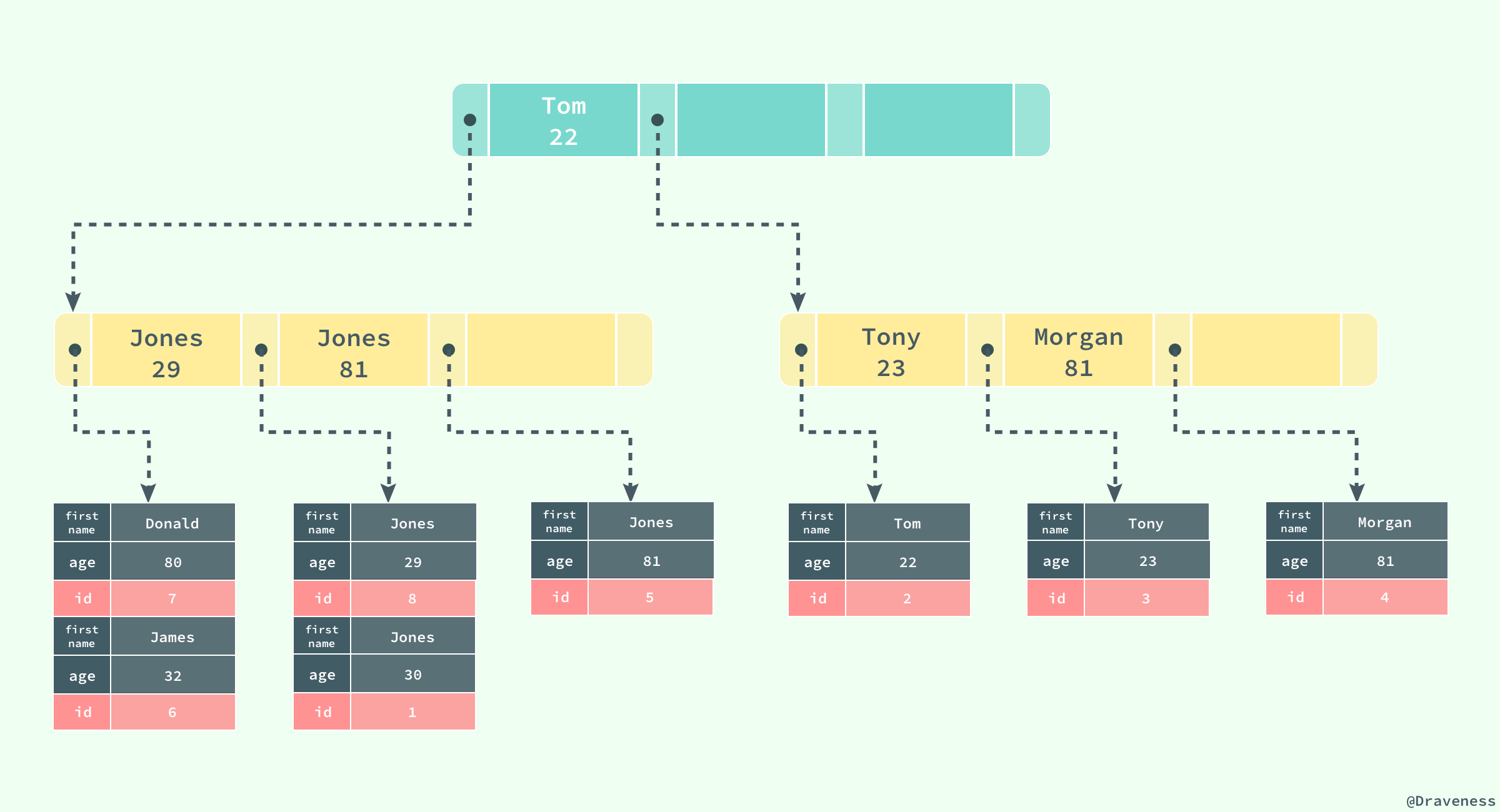
еҰӮжһңеңЁиЎЁ
users дёӯеӯҳеңЁдёҖдёӘиҫ…еҠ©зҙўеј•
(first_name, age)пјҢйӮЈд№Ҳе®ғжһ„жҲҗзҡ„ B+ ж ‘еӨ§иҮҙе°ұжҳҜдёҠеӣҫиҝҷж ·пјҢжҢүз…§
(first_name, age) зҡ„еӯ—жҜҚйЎәеәҸеҜ№иЎЁдёӯзҡ„ж•°жҚ®иҝӣиЎҢжҺ’еәҸпјҢеҪ“жҹҘжүҫеҲ°дё»й”®ж—¶пјҢеҶҚйҖҡиҝҮиҒҡйӣҶзҙўеј•иҺ·еҸ–еҲ°ж•ҙжқЎиЎҢи®°еҪ•гҖӮ

дёҠеӣҫеұ•зӨәдәҶдёҖдёӘдҪҝз”Ёиҫ…еҠ©зҙўеј•жҹҘжүҫдёҖжқЎиЎЁи®°еҪ•зҡ„иҝҮзЁӢпјҡйҖҡиҝҮиҫ…еҠ©зҙўеј•жҹҘжүҫеҲ°еҜ№еә”зҡ„дё»й”®пјҢжңҖеҗҺеңЁиҒҡйӣҶзҙўеј•дёӯдҪҝз”Ёдё»й”®иҺ·еҸ–еҜ№еә”зҡ„иЎҢи®°еҪ•пјҢиҝҷд№ҹжҳҜйҖҡеёёжғ…еҶөдёӢиЎҢи®°еҪ•зҡ„жҹҘжүҫж–№ејҸгҖӮ
зҙўеј•зҡ„и®ҫи®Ўе…¶е®һжҳҜдёҖдёӘйқһеёёйҮҚиҰҒзҡ„еҶ…е®№пјҢеҗҢж—¶д№ҹжҳҜдёҖдёӘйқһеёёеӨҚжқӮзҡ„еҶ…е®№пјӣзҙўеј•зҡ„и®ҫи®ЎдёҺеҲӣе»әеҜ№дәҺжҸҗеҚҮж•°жҚ®еә“зҡ„жҹҘиҜўжҖ§иғҪиҮіе…ійҮҚиҰҒпјҢдёҚиҝҮиҝҷдёҚжҳҜжң¬ж–ҮжғіиҰҒд»Ӣз»Қзҡ„еҶ…е®№пјҢжңүе…ізҙўеј•зҡ„и®ҫи®ЎдёҺдјҳеҢ–еҸҜд»Ҙйҳ…иҜ» ж•°жҚ®еә“зҙўеј•и®ҫи®ЎдёҺдјҳеҢ– дёҖд№ҰпјҢд№ҰдёӯжҸҗдҫӣдәҶдёҖз§Қйқһ常科еӯҰеҗҲзҗҶзҡ„ж–№жі•иғҪеӨҹеё®еҠ©жҲ‘们еңЁж•°жҚ®еә“дёӯе»әз«ӢжңҖйҖӮеҗҲзҡ„зҙўеј•пјҢеҪ“然дҪңиҖ…д№ҹеҸҜиғҪдјҡеңЁд№ӢеҗҺзҡ„ж–Үз« дёӯеҜ№зҙўеј•зҡ„и®ҫи®ЎиҝӣиЎҢз®ҖеҚ•зҡ„д»Ӣз»Қе’ҢеҲҶжһҗгҖӮ
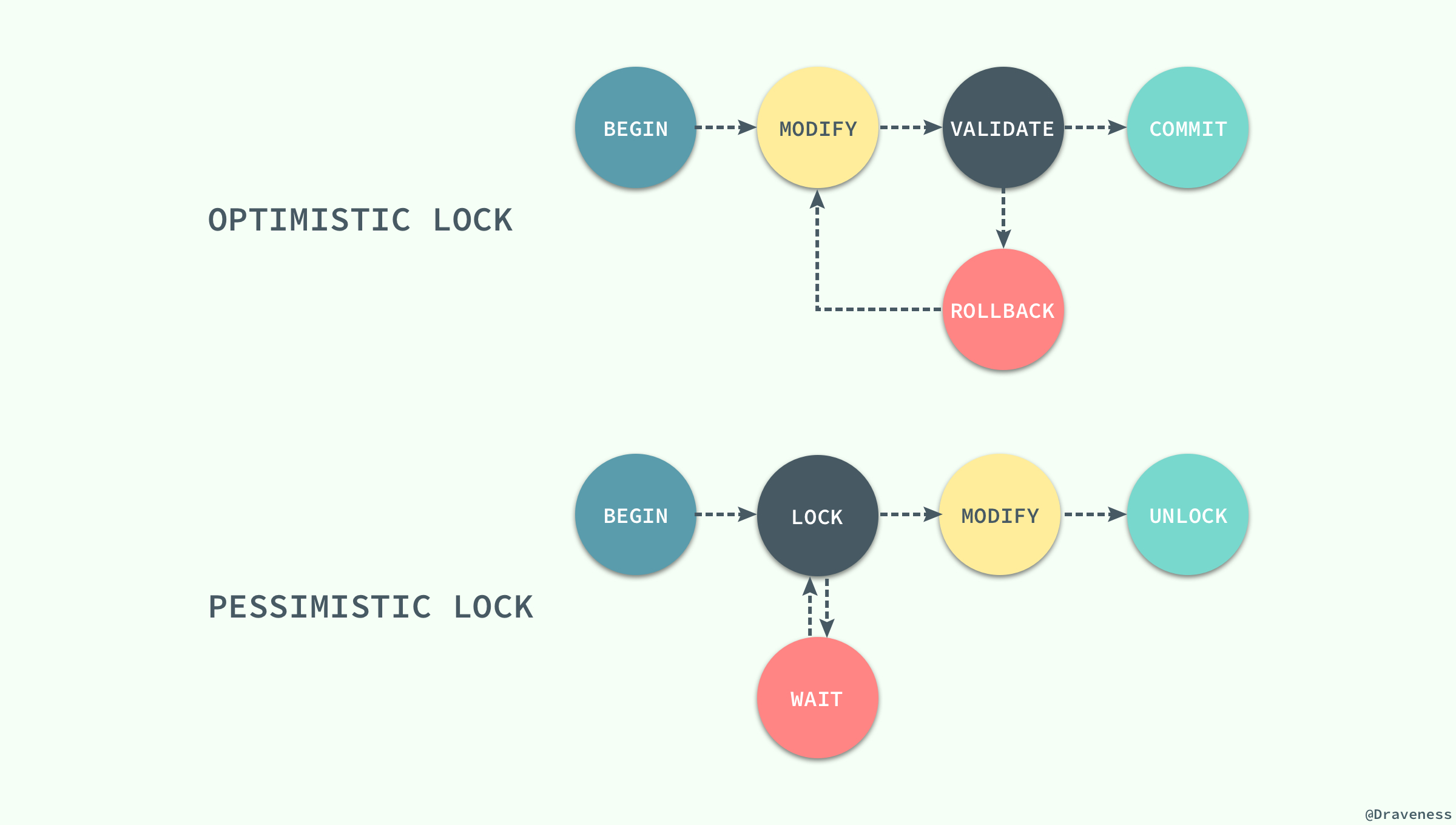
жҲ‘们йғҪзҹҘйҒ“й”Ғзҡ„з§Қзұ»дёҖиҲ¬еҲҶдёәд№җи§Ӯй”Ғе’ҢжӮІи§Ӯй”ҒдёӨз§ҚпјҢInnoDB еӯҳеӮЁеј•ж“ҺдёӯдҪҝз”Ёзҡ„е°ұжҳҜжӮІи§Ӯй”ҒпјҢиҖҢжҢүз…§й”Ғзҡ„зІ’еәҰеҲ’еҲҶпјҢд№ҹеҸҜд»ҘеҲҶжҲҗиЎҢй”Ғе’ҢиЎЁй”ҒгҖӮ
д№җи§Ӯй”Ғе’ҢжӮІи§Ӯй”Ғе…¶е®һйғҪжҳҜ并еҸ‘жҺ§еҲ¶зҡ„жңәеҲ¶пјҢеҗҢж—¶е®ғ们еңЁеҺҹзҗҶдёҠе°ұжңүзқҖжң¬иҙЁзҡ„е·®еҲ«пјӣ
д№җи§Ӯй”ҒжҳҜдёҖз§ҚжҖқжғіпјҢе®ғе…¶е®һ并дёҚжҳҜдёҖз§ҚзңҹжӯЈзҡ„гҖҺй”ҒгҖҸпјҢе®ғдјҡе…Ҳе°қиҜ•еҜ№иө„жәҗиҝӣиЎҢдҝ®ж”№пјҢеңЁеҶҷеӣһж—¶еҲӨж–ӯиө„жәҗжҳҜеҗҰиҝӣиЎҢдәҶж”№еҸҳпјҢеҰӮжһңжІЎжңүеҸ‘з”ҹж”№еҸҳе°ұдјҡеҶҷеӣһпјҢеҗҰеҲҷе°ұдјҡиҝӣиЎҢйҮҚиҜ•пјҢеңЁж•ҙдёӘзҡ„жү§иЎҢиҝҮзЁӢдёӯе…¶е®һйғҪжІЎжңүеҜ№ж•°жҚ®еә“иҝӣиЎҢеҠ й”Ғпјӣ
жӮІи§Ӯй”Ғе°ұжҳҜдёҖз§ҚзңҹжӯЈзҡ„й”ҒдәҶпјҢе®ғдјҡеңЁиҺ·еҸ–иө„жәҗеүҚеҜ№иө„жәҗиҝӣиЎҢеҠ й”ҒпјҢзЎ®дҝқеҗҢдёҖж—¶еҲ»еҸӘжңүжңүйҷҗзҡ„зәҝзЁӢиғҪеӨҹи®ҝй—®иҜҘиө„жәҗпјҢе…¶д»–жғіиҰҒе°қиҜ•иҺ·еҸ–иө„жәҗзҡ„ж“ҚдҪңйғҪдјҡиҝӣе…Ҙзӯүеҫ…зҠ¶жҖҒпјҢзӣҙеҲ°иҜҘзәҝзЁӢе®ҢжҲҗдәҶеҜ№иө„жәҗзҡ„ж“ҚдҪң并且йҮҠж”ҫдәҶй”ҒеҗҺпјҢе…¶д»–зәҝзЁӢжүҚиғҪйҮҚж–°ж“ҚдҪңиө„жәҗпјӣ
иҷҪ然д№җи§Ӯй”Ғе’ҢжӮІи§Ӯй”ҒеңЁжң¬иҙЁдёҠ并дёҚжҳҜеҗҢдёҖз§ҚдёңиҘҝпјҢдёҖдёӘжҳҜдёҖз§ҚжҖқжғіпјҢеҸҰдёҖдёӘжҳҜдёҖз§ҚзңҹжӯЈзҡ„й”ҒпјҢдҪҶжҳҜе®ғ们йғҪжҳҜдёҖз§Қ并еҸ‘жҺ§еҲ¶жңәеҲ¶гҖӮ
д№җи§Ӯй”ҒдёҚдјҡеӯҳеңЁжӯ»й”Ғзҡ„й—®йўҳпјҢдҪҶжҳҜз”ұдәҺжӣҙж–°еҗҺйӘҢиҜҒпјҢжүҖд»ҘеҪ“еҶІзӘҒйў‘зҺҮе’ҢйҮҚиҜ•жҲҗжң¬иҫғй«ҳж—¶жӣҙжҺЁиҚҗдҪҝз”ЁжӮІи§Ӯй”ҒпјҢиҖҢйңҖиҰҒйқһеёёй«ҳзҡ„е“Қеә”йҖҹеәҰ并且并еҸ‘йҮҸйқһеёёеӨ§зҡ„ж—¶еҖҷдҪҝз”Ёд№җи§Ӯй”Ғе°ұиғҪиҫғеҘҪзҡ„и§ЈеҶій—®йўҳпјҢеңЁиҝҷж—¶дҪҝз”ЁжӮІи§Ӯй”Ғе°ұеҸҜиғҪеҮәзҺ°дёҘйҮҚзҡ„жҖ§иғҪй—®йўҳпјӣеңЁйҖүжӢ©е№¶еҸ‘жҺ§еҲ¶жңәеҲ¶ж—¶пјҢйңҖиҰҒз»јеҗҲиҖғиҷ‘дёҠйқўзҡ„еӣӣдёӘж–№йқўпјҲеҶІзӘҒйў‘зҺҮгҖҒйҮҚиҜ•жҲҗжң¬гҖҒе“Қеә”йҖҹеәҰе’Ң并еҸ‘йҮҸпјүиҝӣиЎҢйҖүжӢ©гҖӮ
еҜ№ж•°жҚ®зҡ„ж“ҚдҪңе…¶е®һеҸӘжңүдёӨз§ҚпјҢд№ҹе°ұжҳҜиҜ»е’ҢеҶҷпјҢиҖҢж•°жҚ®еә“еңЁе®һзҺ°й”Ғж—¶пјҢд№ҹдјҡеҜ№иҝҷдёӨз§Қж“ҚдҪңдҪҝз”ЁдёҚеҗҢзҡ„й”ҒпјӣInnoDB е®һзҺ°дәҶж ҮеҮҶзҡ„иЎҢзә§й”ҒпјҢд№ҹе°ұжҳҜе…ұдә«й”ҒпјҲShared Lockпјүе’Ңдә’ж–Ҙй”ҒпјҲExclusive Lockпјүпјӣе…ұдә«й”Ғе’Ңдә’ж–Ҙй”Ғзҡ„дҪңз”Ёе…¶е®һйқһеёёеҘҪзҗҶи§Јпјҡ
е…ұдә«й”ҒпјҲиҜ»й”Ғпјүпјҡе…Ғи®ёдәӢеҠЎеҜ№дёҖжқЎиЎҢж•°жҚ®иҝӣиЎҢиҜ»еҸ–пјӣ
дә’ж–Ҙй”ҒпјҲеҶҷй”Ғпјүпјҡе…Ғи®ёдәӢеҠЎеҜ№дёҖжқЎиЎҢж•°жҚ®иҝӣиЎҢеҲ йҷӨжҲ–жӣҙж–°пјӣ
иҖҢе®ғ们зҡ„еҗҚеӯ—д№ҹжҡ—зӨәзқҖеҗ„иҮӘзҡ„еҸҰеӨ–дёҖдёӘзү№жҖ§пјҢе…ұдә«й”Ғд№Ӣй—ҙжҳҜе…је®№зҡ„пјҢиҖҢдә’ж–Ҙй”ҒдёҺе…¶д»–д»»ж„Ҹй”ҒйғҪдёҚе…је®№пјҡ
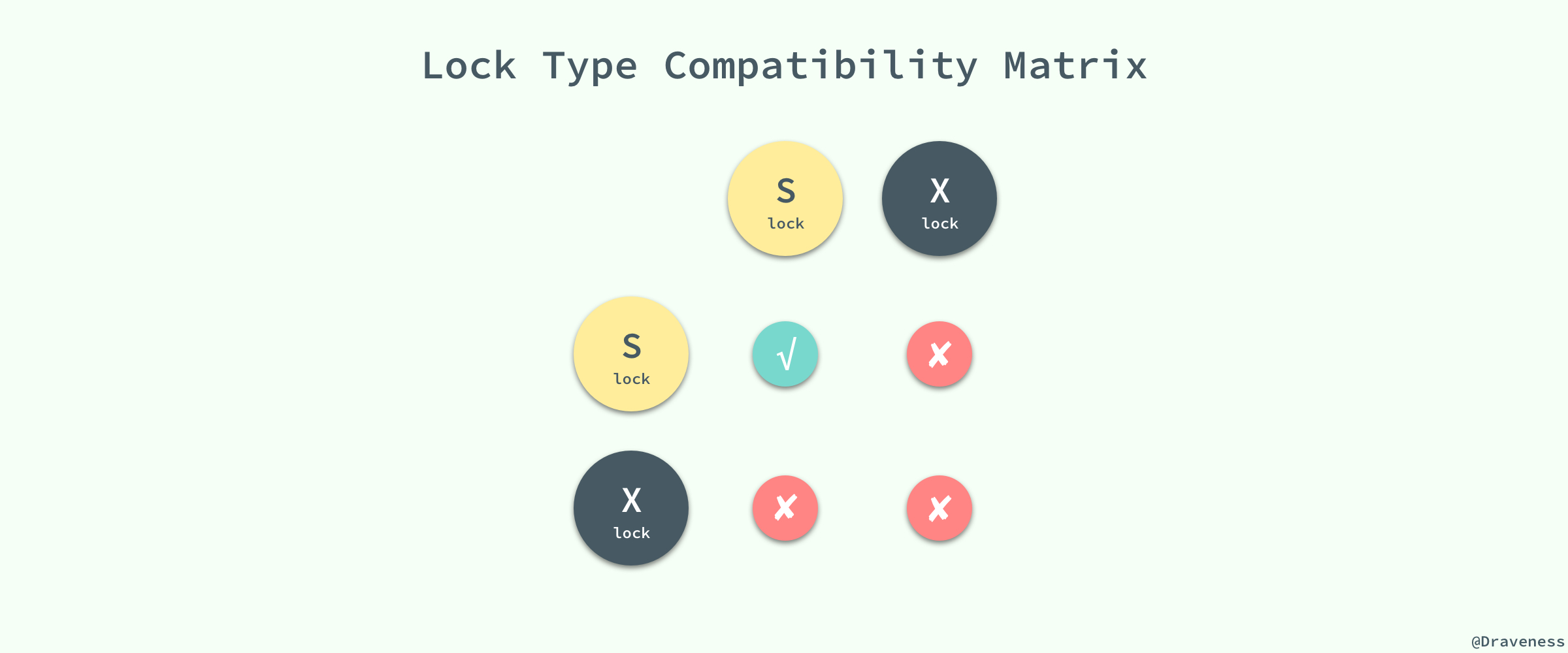
зЁҚеҫ®еҜ№е®ғ们зҡ„дҪҝз”ЁиҝӣиЎҢжҖқиҖғе°ұиғҪжғіжҳҺзҷҪе®ғ们дёәд»Җд№ҲиҰҒиҝҷд№Ҳи®ҫи®ЎпјҢеӣ дёәе…ұдә«й”Ғд»ЈиЎЁдәҶиҜ»ж“ҚдҪңгҖҒдә’ж–Ҙй”Ғд»ЈиЎЁдәҶеҶҷж“ҚдҪңпјҢжүҖд»ҘжҲ‘们еҸҜд»ҘеңЁж•°жҚ®еә“дёӯ并иЎҢиҜ»пјҢдҪҶжҳҜеҸӘиғҪдёІиЎҢеҶҷпјҢеҸӘжңүиҝҷж ·жүҚиғҪдҝқиҜҒдёҚдјҡеҸ‘з”ҹзәҝзЁӢз«һдәүпјҢе®һзҺ°зәҝзЁӢе®үе…ЁгҖӮ
ж— и®әжҳҜе…ұдә«й”ҒиҝҳжҳҜдә’ж–Ҙй”Ғе…¶е®һйғҪеҸӘжҳҜеҜ№жҹҗдёҖдёӘж•°жҚ®иЎҢиҝӣиЎҢеҠ й”ҒпјҢInnoDB ж”ҜжҢҒеӨҡз§ҚзІ’еәҰзҡ„й”ҒпјҢд№ҹе°ұжҳҜиЎҢй”Ғе’ҢиЎЁй”ҒпјӣдёәдәҶж”ҜжҢҒеӨҡзІ’еәҰй”Ғе®ҡпјҢInnoDB еӯҳеӮЁеј•ж“Һеј•е…ҘдәҶж„Ҹеҗ‘й”ҒпјҲIntention LockпјүпјҢж„Ҹеҗ‘й”Ғе°ұжҳҜдёҖз§ҚиЎЁзә§й”ҒгҖӮ
дёҺдёҠдёҖиҠӮдёӯжҸҗеҲ°зҡ„дёӨз§Қй”Ғзҡ„з§Қзұ»зӣёдјјзҡ„жҳҜпјҢж„Ҹеҗ‘й”Ғд№ҹеҲҶдёәдёӨз§Қпјҡ
ж„Ҹеҗ‘е…ұдә«й”ҒпјҡдәӢеҠЎжғіиҰҒеңЁиҺ·еҫ—иЎЁдёӯжҹҗдәӣи®°еҪ•зҡ„е…ұдә«й”ҒпјҢйңҖиҰҒеңЁиЎЁдёҠе…ҲеҠ ж„Ҹеҗ‘е…ұдә«й”Ғпјӣ
ж„Ҹеҗ‘дә’ж–Ҙй”ҒпјҡдәӢеҠЎжғіиҰҒеңЁиҺ·еҫ—иЎЁдёӯжҹҗдәӣи®°еҪ•зҡ„дә’ж–Ҙй”ҒпјҢйңҖиҰҒеңЁиЎЁдёҠе…ҲеҠ ж„Ҹеҗ‘дә’ж–Ҙй”Ғпјӣ
йҡҸзқҖж„Ҹеҗ‘й”Ғзҡ„еҠ е…ҘпјҢй”Ғзұ»еһӢд№Ӣй—ҙзҡ„е…је®№зҹ©йҳөд№ҹеҸҳеҫ—ж„ҲеҠ еӨҚжқӮпјҡ
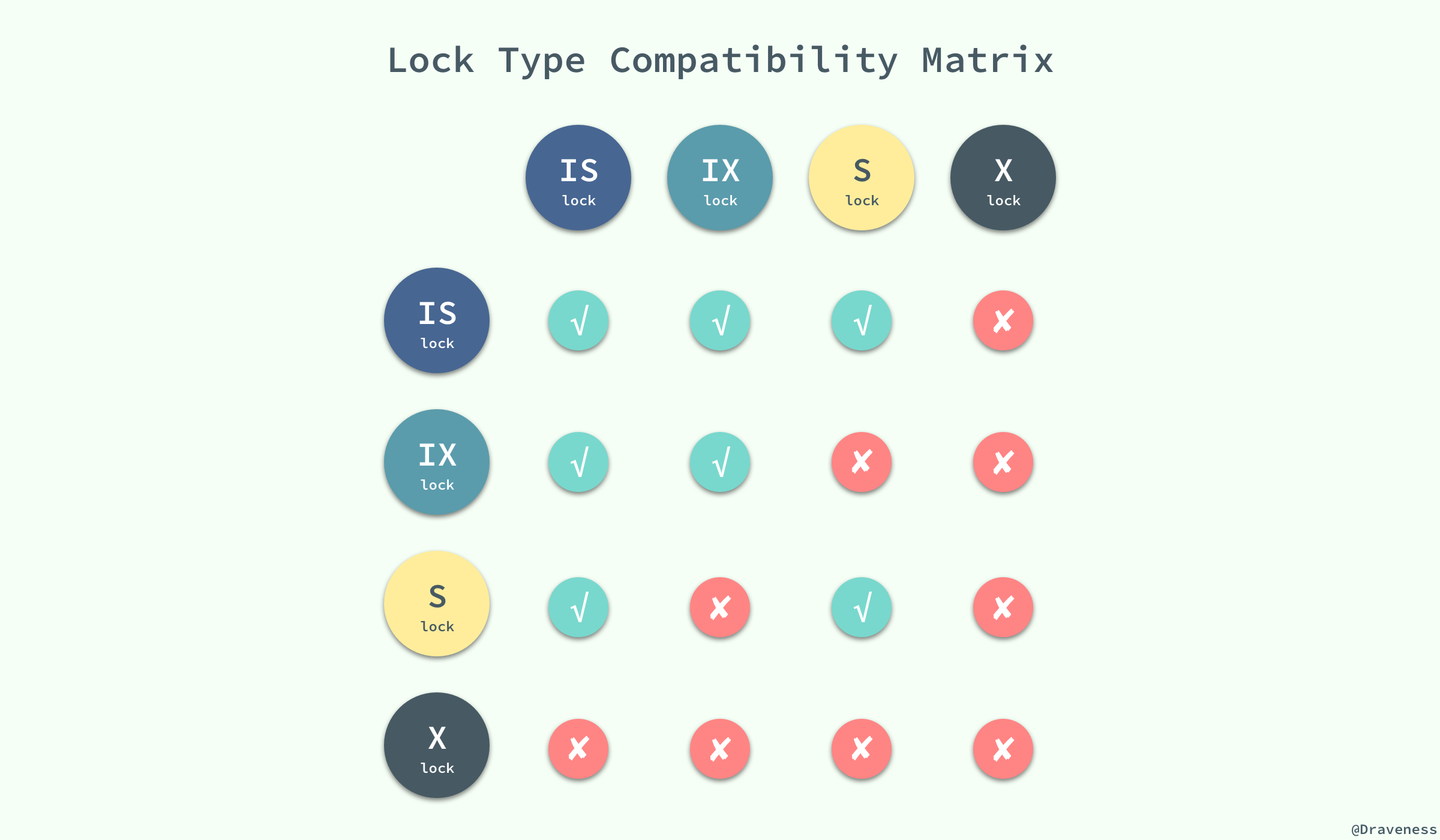
ж„Ҹеҗ‘й”Ғе…¶е®һдёҚдјҡйҳ»еЎһе…ЁиЎЁжү«жҸҸд№ӢеӨ–зҡ„д»»дҪ•иҜ·жұӮпјҢе®ғ们зҡ„дё»иҰҒзӣ®зҡ„жҳҜдёәдәҶиЎЁзӨәжҳҜеҗҰжңүдәәиҜ·жұӮй”Ғе®ҡиЎЁдёӯзҡ„жҹҗдёҖиЎҢж•°жҚ®гҖӮ
жңүзҡ„дәәеҸҜиғҪдјҡеҜ№ж„Ҹеҗ‘й”Ғзҡ„зӣ®зҡ„并дёҚжҳҜе®Ңе…Ёзҡ„зҗҶи§ЈпјҢжҲ‘们еңЁиҝҷйҮҢеҸҜд»ҘдёҫдёҖдёӘдҫӢеӯҗпјҡеҰӮжһңжІЎжңүж„Ҹеҗ‘й”ҒпјҢеҪ“е·Із»ҸжңүдәәдҪҝз”ЁиЎҢй”ҒеҜ№иЎЁдёӯзҡ„жҹҗдёҖиЎҢиҝӣиЎҢдҝ®ж”№ж—¶пјҢеҰӮжһңеҸҰеӨ–дёҖдёӘиҜ·жұӮиҰҒеҜ№е…ЁиЎЁиҝӣиЎҢдҝ®ж”№пјҢйӮЈд№Ҳе°ұйңҖиҰҒеҜ№жүҖжңүзҡ„иЎҢжҳҜеҗҰиў«й”Ғе®ҡиҝӣиЎҢжү«жҸҸпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢж•ҲзҺҮжҳҜйқһеёёдҪҺзҡ„пјӣдёҚиҝҮпјҢеңЁеј•е…Ҙж„Ҹеҗ‘й”Ғд№ӢеҗҺпјҢеҪ“жңүдәәдҪҝз”ЁиЎҢй”ҒеҜ№иЎЁдёӯзҡ„жҹҗдёҖиЎҢиҝӣиЎҢдҝ®ж”№д№ӢеүҚпјҢдјҡе…ҲдёәиЎЁж·»еҠ ж„Ҹеҗ‘дә’ж–Ҙй”ҒпјҲIXпјүпјҢеҶҚдёәиЎҢи®°еҪ•ж·»еҠ дә’ж–Ҙй”ҒпјҲXпјүпјҢеңЁиҝҷж—¶еҰӮжһңжңүдәәе°қиҜ•еҜ№е…ЁиЎЁиҝӣиЎҢдҝ®ж”№е°ұдёҚйңҖиҰҒеҲӨж–ӯиЎЁдёӯзҡ„жҜҸдёҖиЎҢж•°жҚ®жҳҜеҗҰиў«еҠ й”ҒдәҶпјҢеҸӘйңҖиҰҒйҖҡиҝҮзӯүеҫ…ж„Ҹеҗ‘дә’ж–Ҙй”Ғиў«йҮҠж”ҫе°ұеҸҜд»ҘдәҶгҖӮ
еҲ°зӣ®еүҚдёәжӯўе·Із»ҸеҜ№ InnoDB дёӯй”Ғзҡ„зІ’еәҰжңүдёҖе®ҡзҡ„дәҶи§ЈпјҢд№ҹжё…жҘҡдәҶеңЁеҜ№ж•°жҚ®еә“иҝӣиЎҢиҜ»еҶҷж—¶дјҡиҺ·еҸ–дёҚеҗҢзҡ„й”ҒпјҢеңЁиҝҷдёҖе°ҸиҠӮе°Ҷд»Ӣз»Қй”ҒжҳҜеҰӮдҪ•ж·»еҠ еҲ°еҜ№еә”зҡ„ж•°жҚ®иЎҢдёҠзҡ„пјҢжҲ‘们дјҡеҲҶеҲ«д»Ӣз»Қдёүз§Қй”Ғзҡ„з®—жі•пјҡRecord LockгҖҒGap Lock е’Ң Next-Key LockгҖӮ
и®°еҪ•й”ҒпјҲRecord LockпјүжҳҜеҠ еҲ°зҙўеј•и®°еҪ•дёҠзҡ„й”ҒпјҢеҒҮи®ҫжҲ‘们еӯҳеңЁдёӢйқўзҡ„дёҖеј иЎЁ
usersпјҡ
CREATE TABLE users( id INT NOT NULL AUTO_INCREMENT, last_name VARCHAR(255) NOT NULL, first_name VARCHAR(255), age INT, PRIMARY KEY(id), KEY(last_name), KEY(age) );
еҰӮжһңжҲ‘们дҪҝз”Ё
id жҲ–иҖ…
last_name дҪңдёә SQL дёӯ
WHERE иҜӯеҸҘзҡ„иҝҮж»ӨжқЎд»¶пјҢйӮЈд№Ҳ InnoDB е°ұеҸҜд»ҘйҖҡиҝҮзҙўеј•е»әз«Ӣзҡ„ B+ ж ‘жүҫеҲ°иЎҢи®°еҪ•е№¶ж·»еҠ зҙўеј•пјҢдҪҶжҳҜеҰӮжһңдҪҝз”Ё
first_name дҪңдёәиҝҮж»ӨжқЎд»¶ж—¶пјҢз”ұдәҺ InnoDB дёҚзҹҘйҒ“еҫ…дҝ®ж”№зҡ„и®°еҪ•е…·дҪ“еӯҳж”ҫзҡ„дҪҚзҪ®пјҢд№ҹж— жі•еҜ№е°ҶиҰҒдҝ®ж”№е“ӘжқЎи®°еҪ•жҸҗеүҚеҒҡеҮәеҲӨж–ӯе°ұдјҡй”Ғе®ҡж•ҙдёӘиЎЁгҖӮ
и®°еҪ•й”ҒжҳҜеңЁеӯҳеӮЁеј•ж“ҺдёӯжңҖдёәеёёи§Ғзҡ„й”ҒпјҢйҷӨдәҶи®°еҪ•й”Ғд№ӢеӨ–пјҢInnoDB дёӯиҝҳеӯҳеңЁй—ҙйҡҷй”ҒпјҲGap LockпјүпјҢй—ҙйҡҷй”ҒжҳҜеҜ№зҙўеј•и®°еҪ•дёӯзҡ„дёҖж®өиҝһз»ӯеҢәеҹҹзҡ„й”ҒпјӣеҪ“дҪҝз”Ёзұ»дјј
SELECT * FROM users WHERE id BETWEEN 10 AND 20 FOR UPDATE; зҡ„ SQL иҜӯеҸҘж—¶пјҢе°ұдјҡйҳ»жӯўе…¶д»–дәӢеҠЎеҗ‘иЎЁдёӯжҸ’е…Ҙ
id = 15 зҡ„и®°еҪ•пјҢеӣ дёәж•ҙдёӘиҢғеӣҙйғҪиў«й—ҙйҡҷй”Ғй”Ғе®ҡдәҶгҖӮ
й—ҙйҡҷй”ҒжҳҜеӯҳеӮЁеј•ж“ҺеҜ№дәҺжҖ§иғҪе’Ң并еҸ‘еҒҡеҮәзҡ„жқғиЎЎпјҢ并且еҸӘз”ЁдәҺжҹҗдәӣдәӢеҠЎйҡ”зҰ»зә§еҲ«гҖӮ
иҷҪ然й—ҙйҡҷй”Ғдёӯд№ҹеҲҶдёәе…ұдә«й”Ғе’Ңдә’ж–Ҙй”ҒпјҢдёҚиҝҮе®ғ们д№Ӣй—ҙ并дёҚжҳҜдә’ж–Ҙзҡ„пјҢд№ҹе°ұжҳҜдёҚеҗҢзҡ„дәӢеҠЎеҸҜд»ҘеҗҢж—¶жҢҒжңүдёҖж®өзӣёеҗҢиҢғеӣҙзҡ„е…ұдә«й”Ғе’Ңдә’ж–Ҙй”ҒпјҢе®ғе”ҜдёҖйҳ»жӯўзҡ„е°ұжҳҜе…¶д»–дәӢеҠЎеҗ‘иҝҷдёӘиҢғеӣҙдёӯж·»еҠ ж–°зҡ„и®°еҪ•гҖӮ
Next-Key й”ҒзӣёжҜ”еүҚдёӨиҖ…е°ұзЁҚеҫ®жңүдёҖдәӣеӨҚжқӮпјҢе®ғжҳҜи®°еҪ•й”Ғе’Ңи®°еҪ•еүҚзҡ„й—ҙйҡҷй”Ғзҡ„з»“еҗҲпјҢеңЁ
users иЎЁдёӯжңүд»ҘдёӢи®°еҪ•пјҡ
+------|-------------|--------------|-------+ | id | last_name | first_name | age | |------|-------------|--------------|-------| | 4 | stark | tony | 21 | | 1 | tom | hiddleston | 30 | | 3 | morgan | freeman | 40 | | 5 | jeff | dean | 50 | | 2 | donald | trump | 80 | +------|-------------|--------------|-------+
еҰӮжһңдҪҝз”Ё Next-Key й”ҒпјҢйӮЈд№Ҳ Next-Key й”Ғе°ұеҸҜд»ҘеңЁйңҖиҰҒзҡ„ж—¶еҖҷй”Ғе®ҡд»ҘдёӢзҡ„иҢғеӣҙпјҡ
(-вҲһ, 21] (21, 30] (30, 40] (40, 50] (50, 80] (80, вҲһ)
既然еҸ« Next-Key й”ҒпјҢй”Ғе®ҡзҡ„еә”иҜҘжҳҜеҪ“еүҚеҖје’ҢеҗҺйқўзҡ„иҢғеӣҙпјҢдҪҶжҳҜе®һйҷ…дёҠеҚҙдёҚжҳҜпјҢNext-Key й”Ғй”Ғе®ҡзҡ„жҳҜеҪ“еүҚеҖје’ҢеүҚйқўзҡ„иҢғеӣҙгҖӮ
еҪ“жҲ‘们жӣҙж–°дёҖжқЎи®°еҪ•пјҢжҜ”еҰӮ
SELECT * FROM users WHERE age = 30 FOR UPDATE;пјҢInnoDB дёҚд»…дјҡеңЁиҢғеӣҙ
(21, 30] дёҠеҠ Next-Key й”ҒпјҢиҝҳдјҡеңЁиҝҷжқЎи®°еҪ•еҗҺйқўзҡ„иҢғеӣҙ
(30, 40] еҠ й—ҙйҡҷй”ҒпјҢжүҖд»ҘжҸ’е…Ҙ
(21, 40] иҢғеӣҙеҶ…зҡ„и®°еҪ•йғҪдјҡиў«й”Ғе®ҡгҖӮ
Next-Key й”Ғзҡ„дҪңз”Ёе…¶е®һжҳҜдёәдәҶи§ЈеҶіе№»иҜ»зҡ„й—®йўҳпјҢжҲ‘们дјҡеңЁдёӢдёҖиҠӮи°ҲдәӢеҠЎзҡ„ж—¶еҖҷе…·дҪ“д»Ӣз»ҚгҖӮ
既然 InnoDB дёӯе®һзҺ°зҡ„й”ҒжҳҜжӮІи§Ӯзҡ„пјҢйӮЈд№ҲдёҚеҗҢдәӢеҠЎд№Ӣй—ҙе°ұеҸҜиғҪдјҡдә’зӣёзӯүеҫ…еҜ№ж–№йҮҠж”ҫй”ҒйҖ жҲҗжӯ»й”ҒпјҢжңҖз»ҲеҜјиҮҙдәӢеҠЎеҸ‘з”ҹй”ҷиҜҜпјӣжғіиҰҒеңЁ MySQL дёӯеҲ¶йҖ жӯ»й”Ғзҡ„й—®йўҳе…¶е®һйқһеёёе®№жҳ“пјҡ
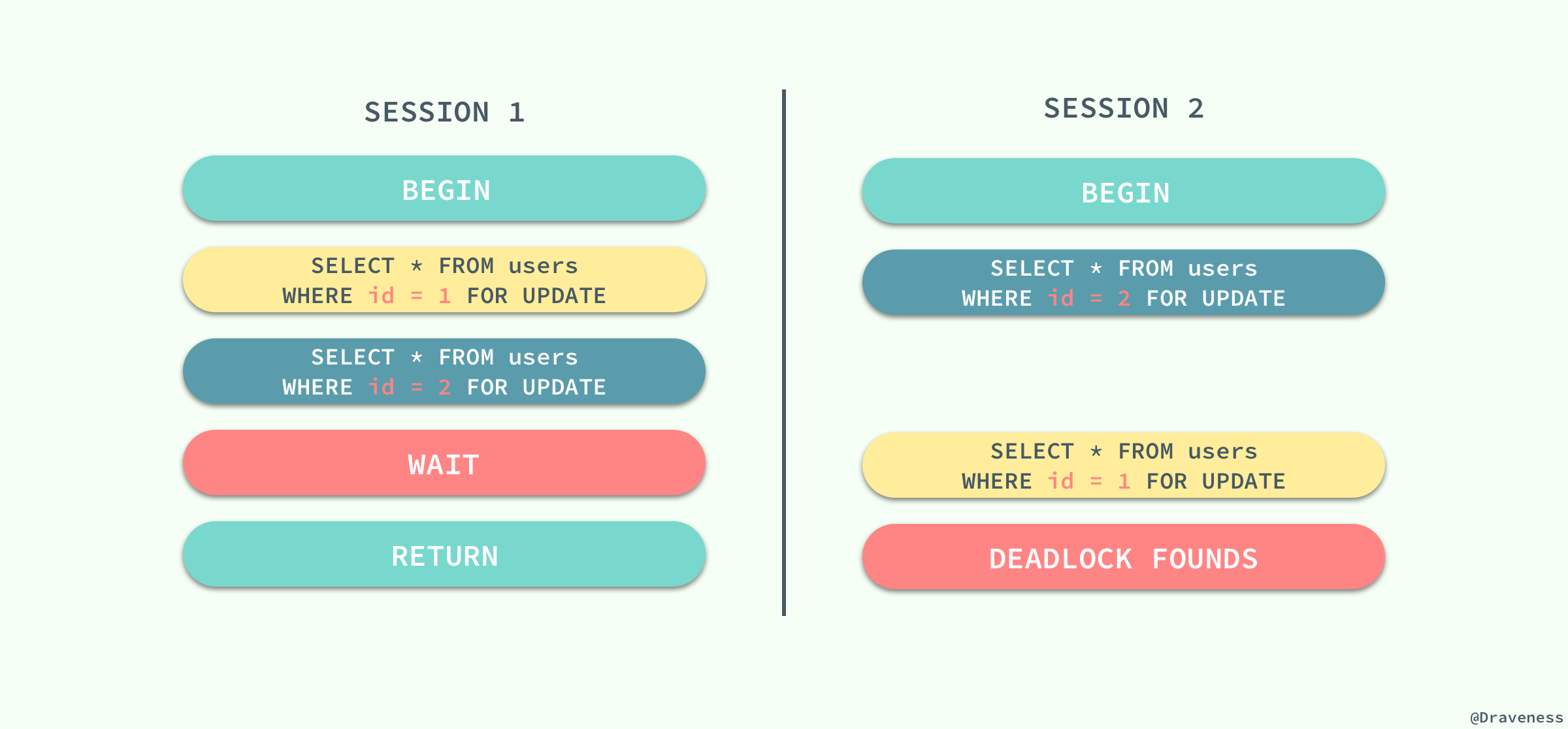
дёӨдёӘдјҡиҜқйғҪжҢҒжңүдёҖдёӘй”ҒпјҢ并且е°қиҜ•иҺ·еҸ–еҜ№ж–№зҡ„й”Ғж—¶е°ұдјҡеҸ‘з”ҹжӯ»й”ҒпјҢдёҚиҝҮ MySQL д№ҹиғҪеңЁеҸ‘з”ҹжӯ»й”Ғж—¶еҸҠж—¶еҸ‘зҺ°й—®йўҳпјҢ并дҝқиҜҒе…¶дёӯзҡ„дёҖдёӘдәӢеҠЎиғҪеӨҹжӯЈеёёе·ҘдҪңпјҢиҝҷеҜ№жҲ‘们жқҘиҜҙд№ҹжҳҜдёҖдёӘеҘҪж¶ҲжҒҜгҖӮ
еңЁд»Ӣз»ҚдәҶй”Ғд№ӢеҗҺпјҢжҲ‘们еҶҚжқҘи°Ҳи°Ҳж•°жҚ®еә“дёӯдёҖдёӘйқһеёёйҮҚиҰҒзҡ„жҰӮеҝө вҖ”вҖ” дәӢеҠЎпјӣзӣёдҝЎеҸӘиҰҒжҳҜдёҖдёӘеҗҲж јзҡ„иҪҜ件е·ҘзЁӢеёҲе°ұеҜ№дәӢеҠЎзҡ„зү№жҖ§жңүжүҖдәҶи§ЈпјҢе…¶дёӯиў«дәәз»ҸеёёжҸҗиө·зҡ„е°ұжҳҜдәӢеҠЎзҡ„еҺҹеӯҗжҖ§пјҢеңЁж•°жҚ®жҸҗдәӨе·ҘдҪңж—¶пјҢиҰҒд№ҲдҝқиҜҒжүҖжңүзҡ„дҝ®ж”№йғҪиғҪеӨҹжҸҗдәӨпјҢиҰҒд№Ҳе°ұжүҖжңүзҡ„дҝ®ж”№е…ЁйғЁеӣһж»ҡгҖӮ
дҪҶжҳҜдәӢеҠЎиҝҳйҒөеҫӘеҢ…жӢ¬еҺҹеӯҗжҖ§еңЁеҶ…зҡ„ ACID еӣӣеӨ§зү№жҖ§пјҡеҺҹеӯҗжҖ§пјҲAtomicityпјүгҖҒдёҖиҮҙжҖ§пјҲConsistencyпјүгҖҒйҡ”зҰ»жҖ§пјҲIsolationпјүе’ҢжҢҒд№…жҖ§пјҲDurabilityпјүпјӣж–Үз« дёҚдјҡеҜ№иҝҷеӣӣеӨ§зү№жҖ§е…ЁйғЁеұ•ејҖиҝӣиЎҢд»Ӣз»ҚпјҢзӣёдҝЎдҪ иғҪеӨҹйҖҡиҝҮ Google е’Ңж•°жҚ®еә“зӣёе…ізҡ„д№ҰзұҚиҪ»жқҫиҺ·еҫ—жңүе…іе®ғ们зҡ„жҰӮеҝөпјҢжң¬ж–ҮжңҖеҗҺиҰҒд»Ӣз»Қзҡ„е°ұжҳҜдәӢеҠЎзҡ„еӣӣз§Қйҡ”зҰ»зә§еҲ«гҖӮ
дәӢеҠЎзҡ„йҡ”зҰ»жҖ§жҳҜж•°жҚ®еә“еӨ„зҗҶж•°жҚ®зҡ„еҮ еӨ§еҹәзЎҖд№ӢдёҖпјҢиҖҢйҡ”зҰ»зә§еҲ«е…¶е®һе°ұжҳҜжҸҗдҫӣз»ҷз”ЁжҲ·з”ЁдәҺеңЁжҖ§иғҪе’ҢеҸҜйқ жҖ§еҒҡеҮәйҖүжӢ©е’ҢжқғиЎЎзҡ„й…ҚзҪ®йЎ№гҖӮ
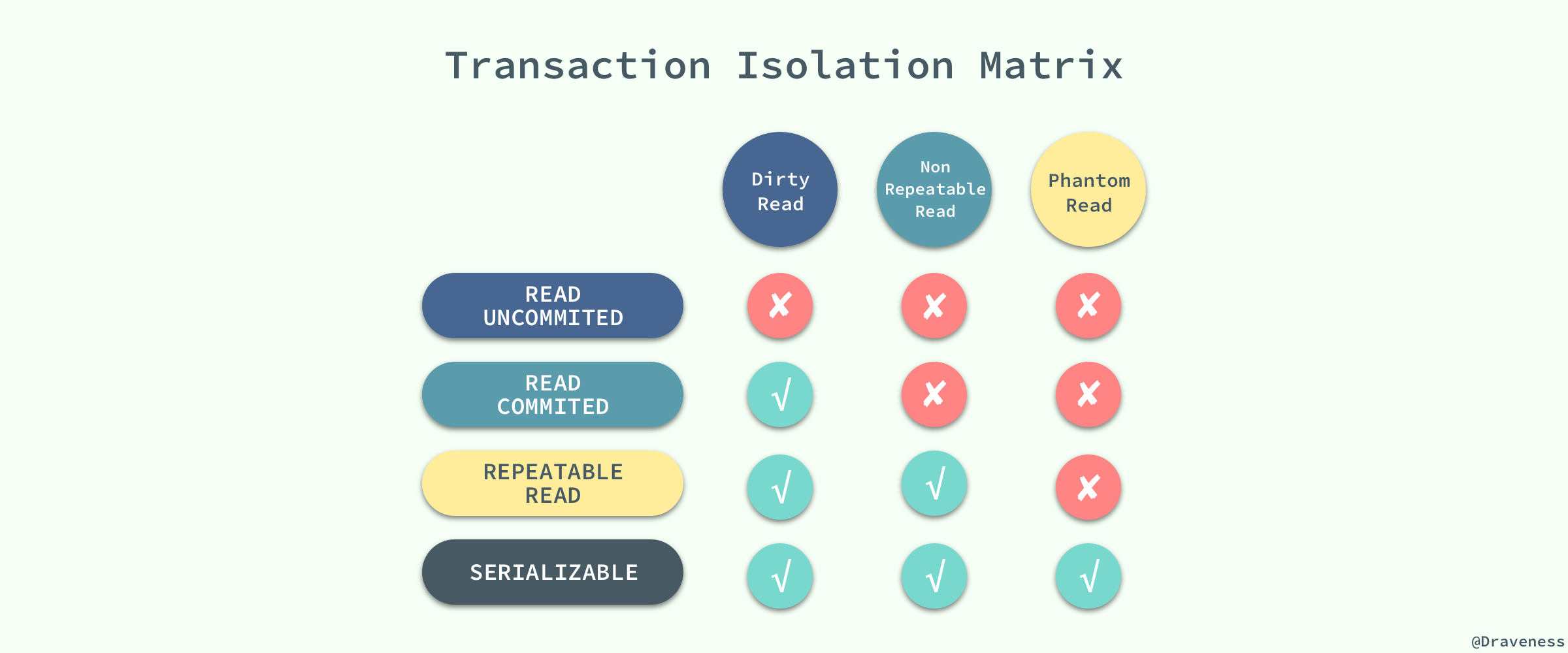
ISO е’Ң ANIS SQL ж ҮеҮҶеҲ¶е®ҡдәҶеӣӣз§ҚдәӢеҠЎйҡ”зҰ»зә§еҲ«пјҢиҖҢ InnoDB йҒөеҫӘдәҶ SQL:1992 ж ҮеҮҶдёӯзҡ„еӣӣз§Қйҡ”зҰ»зә§еҲ«пјҡREAD UNCOMMITEDгҖҒREAD COMMITEDгҖҒREPEATABLE READ е’Ң
SERIALIZABLEпјӣжҜҸдёӘдәӢеҠЎзҡ„йҡ”зҰ»зә§еҲ«е…¶е®һйғҪжҜ”дёҠдёҖзә§еӨҡи§ЈеҶідәҶдёҖдёӘй—®йўҳпјҡ
RAED UNCOMMITEDпјҡдҪҝз”ЁжҹҘиҜўиҜӯеҸҘдёҚдјҡеҠ й”ҒпјҢеҸҜиғҪдјҡиҜ»еҲ°жңӘжҸҗдәӨзҡ„иЎҢпјҲDirty Readпјүпјӣ
READ COMMITEDпјҡеҸӘеҜ№и®°еҪ•еҠ и®°еҪ•й”ҒпјҢиҖҢдёҚдјҡеңЁи®°еҪ•д№Ӣй—ҙеҠ й—ҙйҡҷй”ҒпјҢжүҖд»Ҙе…Ғи®ёж–°зҡ„и®°еҪ•жҸ’е…ҘеҲ°иў«й”Ғе®ҡи®°еҪ•зҡ„йҷ„иҝ‘пјҢжүҖд»ҘеҶҚеӨҡж¬ЎдҪҝз”ЁжҹҘиҜўиҜӯеҸҘж—¶пјҢеҸҜиғҪеҫ—еҲ°дёҚеҗҢзҡ„з»“жһңпјҲNon-Repeatable Readпјүпјӣ
REPEATABLE READпјҡеӨҡж¬ЎиҜ»еҸ–еҗҢдёҖиҢғеӣҙзҡ„ж•°жҚ®дјҡиҝ”еӣһ第дёҖж¬ЎжҹҘиҜўзҡ„еҝ«з…§пјҢдёҚдјҡиҝ”еӣһдёҚеҗҢзҡ„ж•°жҚ®иЎҢпјҢдҪҶжҳҜеҸҜиғҪеҸ‘з”ҹе№»иҜ»пјҲPhantom Readпјүпјӣ
SERIALIZABLEпјҡInnoDB йҡҗејҸең°е°Ҷе…ЁйғЁзҡ„жҹҘиҜўиҜӯеҸҘеҠ дёҠе…ұдә«й”ҒпјҢи§ЈеҶідәҶе№»иҜ»зҡ„й—®йўҳпјӣ
MySQL дёӯй»ҳи®Өзҡ„дәӢеҠЎйҡ”зҰ»зә§еҲ«е°ұжҳҜ
REPEATABLE READпјҢдҪҶжҳҜе®ғйҖҡиҝҮ Next-Key й”Ғд№ҹиғҪеӨҹеңЁжҹҗз§ҚзЁӢеәҰдёҠи§ЈеҶіе№»иҜ»зҡ„й—®йўҳгҖӮ
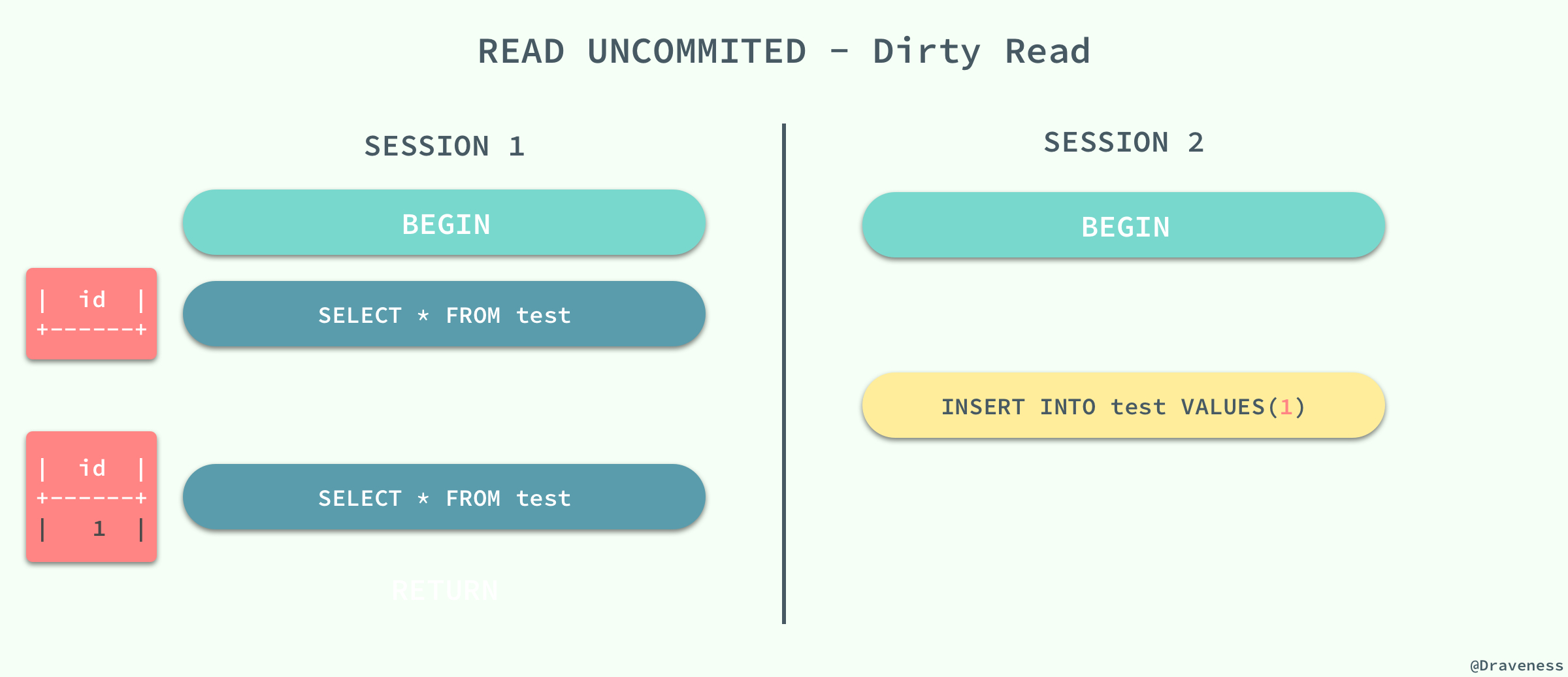
жҺҘдёӢжқҘпјҢжҲ‘们е°Ҷж•°жҚ®еә“дёӯеҲӣе»әеҰӮдёӢзҡ„表并йҖҡиҝҮдёӘдҫӢеӯҗжқҘеұ•зӨәеңЁдёҚеҗҢзҡ„дәӢеҠЎйҡ”зҰ»зә§еҲ«д№ӢдёӢпјҢдјҡеҸ‘з”ҹд»Җд№Ҳж ·зҡ„й—®йўҳпјҡ
CREATE TABLE test( id INT NOT NULL, UNIQUE(id) );
еңЁдёҖдёӘдәӢеҠЎдёӯпјҢиҜ»еҸ–дәҶе…¶д»–дәӢеҠЎжңӘжҸҗдәӨзҡ„ж•°жҚ®гҖӮ
еҪ“дәӢеҠЎзҡ„йҡ”зҰ»зә§еҲ«дёә
READ UNCOMMITED ж—¶пјҢжҲ‘们еңЁ
SESSION 2 дёӯжҸ’е…Ҙзҡ„жңӘжҸҗдәӨж•°жҚ®еңЁ
SESSION 1 дёӯжҳҜеҸҜд»Ҙи®ҝй—®зҡ„гҖӮ
еңЁдёҖдёӘдәӢеҠЎдёӯпјҢеҗҢдёҖиЎҢи®°еҪ•иў«и®ҝй—®дәҶдёӨж¬ЎеҚҙеҫ—еҲ°дәҶдёҚеҗҢзҡ„з»“жһңгҖӮ
еҪ“дәӢеҠЎзҡ„йҡ”зҰ»зә§еҲ«дёә
READ COMMITED ж—¶пјҢиҷҪ然解еҶідәҶи„ҸиҜ»зҡ„й—®йўҳпјҢдҪҶжҳҜеҰӮжһңеңЁ
SESSION 1 е…ҲжҹҘиҜўдәҶдёҖиЎҢж•°жҚ®пјҢеңЁиҝҷд№ӢеҗҺ
SESSION 2 дёӯдҝ®ж”№дәҶеҗҢдёҖиЎҢж•°жҚ®е№¶дё”жҸҗдәӨдәҶдҝ®ж”№пјҢеңЁиҝҷж—¶пјҢеҰӮжһң
SESSION 1 дёӯеҶҚж¬ЎдҪҝз”ЁзӣёеҗҢзҡ„жҹҘиҜўиҜӯеҸҘпјҢе°ұдјҡеҸ‘зҺ°дёӨж¬ЎжҹҘиҜўзҡ„з»“жһңдёҚдёҖж ·гҖӮ

дёҚеҸҜйҮҚеӨҚиҜ»зҡ„еҺҹеӣ е°ұжҳҜпјҢеңЁ
READ COMMITED зҡ„йҡ”зҰ»зә§еҲ«дёӢпјҢеӯҳеӮЁеј•ж“ҺдёҚдјҡеңЁжҹҘиҜўи®°еҪ•ж—¶ж·»еҠ иЎҢй”ҒпјҢй”Ғе®ҡ
id = 3 иҝҷжқЎи®°еҪ•гҖӮ
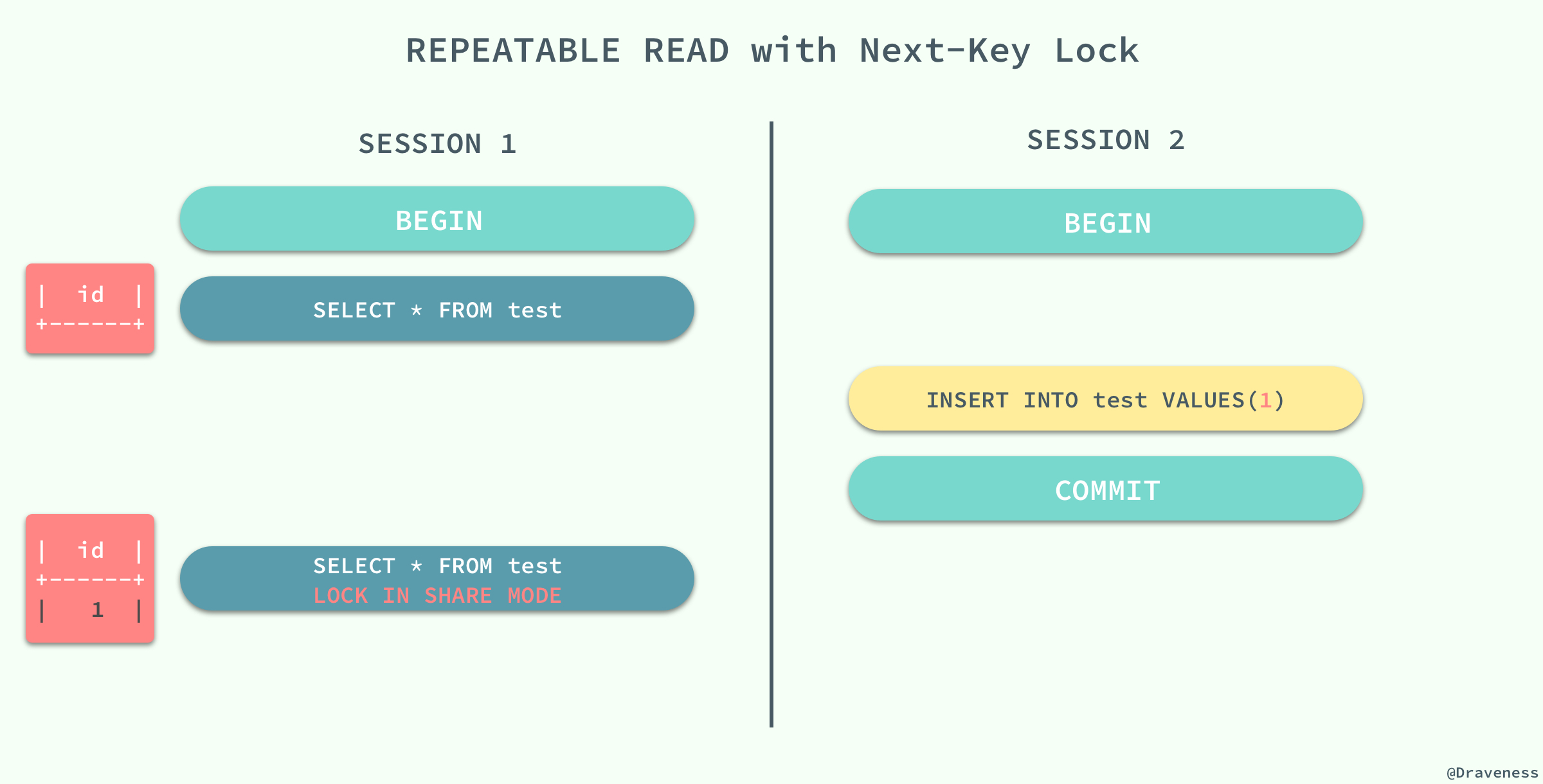
еңЁдёҖдёӘдәӢеҠЎдёӯпјҢеҗҢдёҖдёӘиҢғеӣҙеҶ…зҡ„и®°еҪ•иў«иҜ»еҸ–ж—¶пјҢе…¶д»–дәӢеҠЎеҗ‘иҝҷдёӘиҢғеӣҙж·»еҠ дәҶж–°зҡ„и®°еҪ•гҖӮ
йҮҚж–°ејҖеҗҜдәҶдёӨдёӘдјҡиҜқ
SESSION 1 е’Ң
SESSION 2пјҢеңЁ
SESSION 1 дёӯжҲ‘们жҹҘиҜўе…ЁиЎЁзҡ„дҝЎжҒҜпјҢжІЎжңүеҫ—еҲ°д»»дҪ•и®°еҪ•пјӣеңЁ
SESSION 2 дёӯеҗ‘иЎЁдёӯжҸ’е…ҘдёҖжқЎж•°жҚ®е№¶жҸҗдәӨпјӣз”ұдәҺ
REPEATABLE READ зҡ„еҺҹеӣ пјҢеҶҚж¬ЎжҹҘиҜўе…ЁиЎЁзҡ„ж•°жҚ®ж—¶пјҢжҲ‘们иҺ·еҫ—еҲ°зҡ„д»Қ然жҳҜз©әйӣҶпјҢдҪҶжҳҜеңЁеҗ‘иЎЁдёӯжҸ’е…ҘеҗҢж ·зҡ„ж•°жҚ®еҚҙеҮәзҺ°дәҶй”ҷиҜҜгҖӮ

иҝҷз§ҚзҺ°иұЎеңЁж•°жҚ®еә“дёӯе°ұиў«з§°дҪңе№»иҜ»пјҢиҷҪ然жҲ‘们дҪҝз”ЁжҹҘиҜўиҜӯеҸҘеҫ—еҲ°дәҶдёҖдёӘз©әзҡ„йӣҶеҗҲпјҢдҪҶжҳҜжҸ’е…Ҙж•°жҚ®ж—¶еҚҙеҫ—еҲ°дәҶй”ҷиҜҜпјҢеҘҪеғҸд№ӢеүҚзҡ„жҹҘиҜўжҳҜе№»и§үдёҖж ·гҖӮ
еңЁж ҮеҮҶзҡ„дәӢеҠЎйҡ”зҰ»зә§еҲ«дёӯпјҢе№»иҜ»жҳҜз”ұжӣҙй«ҳзҡ„йҡ”зҰ»зә§еҲ«
SERIALIZABLE и§ЈеҶізҡ„пјҢдҪҶжҳҜе®ғд№ҹеҸҜд»ҘйҖҡиҝҮ MySQL жҸҗдҫӣзҡ„ Next-Key й”Ғи§ЈеҶіпјҡ
REPEATABLE READ е’Ң
READ UNCOMMITED е…¶е®һжҳҜзҹӣзӣҫзҡ„пјҢеҰӮжһңдҝқиҜҒдәҶеүҚиҖ…е°ұзңӢдёҚеҲ°е·Із»ҸжҸҗдәӨзҡ„дәӢеҠЎпјҢеҰӮжһңдҝқиҜҒдәҶеҗҺиҖ…пјҢе°ұдјҡеҜјиҮҙдёӨж¬ЎжҹҘиҜўзҡ„з»“жһңдёҚеҗҢпјҢMySQL дёәжҲ‘们жҸҗдҫӣдәҶдёҖз§ҚжҠҳдёӯзҡ„ж–№ејҸпјҢиғҪеӨҹеңЁ
REPEATABLE READ жЁЎејҸдёӢеҠ й”Ғи®ҝй—®е·Із»ҸжҸҗдәӨзҡ„ж•°жҚ®гҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎMysqlеӯҳеӮЁеј•ж“ҺдёҺж•°жҚ®еӯҳеӮЁзҡ„еҺҹзҗҶжҳҜд»Җд№Ҳзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ