您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Anton Els,Vít Špinka,Franck Pachot
Oracle Database 12c
Release 2 Multitenant
EISBN 978-1-25-983609-1
Copyright © 2017 by McGraw-Hill Education.
All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any
means, electronic or mechanical, including without limitation photocopying, recording, taping, or any
database, information or retrieval system, without the prior written permission of the publisher.
This authorized Chinese translation edition is jointly published by McGraw-Hill Education and Tsinghua
University Press Limited. This edition is authorized for sale in the People’s Republic of China only,
excluding Hong Kong, Macao SAR and Taiwan.
Translation copyright © 2018 by McGraw-Hill Education and Tsinghua University Press Limited.
版权所有。未经出版人事先书面许可,对本出版物的任何部分不得以任何方式或途径复制或传播,
包括但不限于复印、录制、录音,或通过任何数据库、信息或可检索的系统。
本授权中文简体字翻译版由麦格劳-希尔(亚洲)教育出版公司和清华大学出版社有限公司合作出版。
此版本经授权仅限在中国大陆区域销售,不能销往中国香港、澳门特别行政区和中国台湾地区。
版权©2018
由麦格劳-希尔(亚洲)教育出版公司与清华大学出版社有限公司所有。
北京市版权局著作权合同登记号 图字:
01-2017-3077
本书封面贴有
McGraw-Hill Education
公司防伪标签,无标签者不得销售。
版权所有,侵权必究。侵权举报电话:
010-62782989 13701121933
图书在版编目(CIP)数据
Oracle Database 12
R2
多租户权威指南
/ (新西兰)安东·艾尔斯(Anton Els),
(捷克)维特·斯
普林克(Vít Špinka),
(瑞士)弗兰克·帕丘特(Franck Pachot)
著;史跃东 译.
—北京:清华大学
出版社,
2018
书名原文:
Oracle Database 12
Release 2 Multitenant
ISBN 978-7-302-50251-7
Ⅰ.
①O… Ⅱ.
①安… ②维… ③弗… ④史… Ⅲ.
①关系数据库系统-指南
Ⅳ.
①TP311.138-62
中国版本图书馆
CIP
数据核字(2018)第
103253
号
号
责任编辑:
王 军 李维杰
封面设计:
牛艳敏
版式设计:
思创景点
责任校对:
曹 阳
责任印制:董 瑾
出版发行:
清华大学出版社
网 址:
http://www.tup.com.cn,
http://www.wqbook.com
地 址:北京清华大学学研大厦
A
座
邮 编:
100084
社 总 机:
010-62770175
邮 购:
010-62786544
投稿与读者服务:
010-62776969,
c-service@tup.tsinghua.edu.cn
质 量 反 馈:
010-62772015,
zhiliang@tup.tsinghua.edu.cn
印 刷 者:北京鑫丰华彩印有限公司
装 订 者:三河市溧源装订厂
经 销:
全国新华书店
开 本:
170mm×240mm
印 张:
23
字 数:
451
千字
版 次:
2018
年
6
月第
1
版
印 次:
2018
年
6
月第
1
次印刷
印 数:
1~3500
定 价:
79.80
元
———————————————————————————————————————————
产品编号:
074808-01
本打算趁着农历春节之前,利用调休的时间将这本
400
多页的书翻译完毕,
谁曾想诸事缠身,一顿忙活之后,也就到了年三十。于是这本书也就只能在春
节之后搞定了。
严格来说,这本书是去年
9
月时着手翻译的,到
2018
年
2
月,又是
6
个月
的时间。回想起去年翻译《云端存储
Oracle ASM
核心指南》时,也是断断续
续忙了
5
个月才完工。留意起来,才意识到翻译这个活儿,真心是一项费时费
心的工作。平时工作繁忙,也只能挤出晚上或周末,抑或调休的时间进行翻译。
并且书中很多词句都要斟酌再三、反复琢磨,才能够将原文的意思准确表达出
来。自己写书,是对自己会的知识进行梳理;而翻译,则是研究自己不会的东
西。因此,从某种程度上来说,翻译的过程,实质上也是学习新技术、新知识
的过程。
多租户与
IMO
一道,并称为
Oracle Database 12c
的两大关键特性。此番有
幸从清华大学出版社拿到这本书的翻译权,也是件值得高兴的事情。只不过与
IMO
相关的一本书, 则被
Oracle
原厂拿去翻译了。若是这两本书都由笔者翻译,
再加上前面的
ASM,岂不是完美?可惜。
多租户技术,是
Oracle
自
12.1
版本开始引入的一项全新特性。它从根本上
改变了
Oracle
数据库长久以来的体系结构,也是
Oracle
在这个风起云涌的时代,
全面迎合云计算的具体表现。对于传统的
Oracle DBA
来说,熟练掌握
12c
版本
中的这一新特性,已经是毋庸置疑的事情。
本书的封底,指出这本书由
OCM
专家团队编写,而实际上,翻阅了本书
前言的各位读者就会知道,本书的三位作者均是
Oracle ACE。他们不仅有着多
年的实践经验,也在各大技术社区和相关会议上进行技术分享。由这样的人撰
写本书, 本书内容的实战性可想而知。本书从多租户的基本概念入手, 涵盖
CDB
与
PDB
的创建和管理、网络与服务、安全、备份和恢复、数据移动以及多租户
的诸多高级特性,尤其是深入探讨了诸多技术在多租户环境下和此前版本中的
不同之处,这对于我们的实际工作来说,显然是极具价值的内容。
当然,依然要感谢所有在本书付梓出版的过程中给笔者提供帮助的各位人
士,正是你们一直以来的关心与帮助,笔者才能够笔耕不辍、日日向前。
由于笔者才疏学浅,因此在本书的翻译过程中注定会有些错误与不足之处,
各位读者见到后,望不吝赐教。
2018
年
2
月
22
日
Anton Els
是一位
Oracle ACE,目前是
Dbvisit
软件有限公司的高级副总裁。
Anton
在数据库技术领域已经有超过
15
年的工作经验,擅长
Oracle
数据库、备
份和恢复、数据库备库、
Oracle Linux、虚拟化以及
docker
技术。
Anton
是独立
Oracle
用户组(Independent Oracle Users Group,
IOUG)的活跃成员,同时也是新
西兰
Oracle
用户组(New Zealand Oracle Users Group,
NZOUG)的副主席。
Anton
拥有
Oracle Database 11g
OCM
证书,还拥有从
8i
到
12c
的全部
OCP
证书。同
时,他还拥有
Oracle Database 11g
RAC
与
GI
管理员方向的
OCE
证书、
Red Hat
5 RHSA
证书,以及
Oracle Solaris 10
的
SCSA
证书。
Anton
经常出席相关工业
及用户组会议,例如一些行业合作会议、在日本举行的
Oracle OpenWorld
数据
库技术专场会议、
NZOUG,以及亚太和拉美地区的
Oracle
技术网络(OTN)年
会等。可以访问他的
Twitter(@aelsnz)或博客(www.oraclekiwi.co.nz)。
Vít Špinka
是一位
Oracle ACE-A, 目前是
Dbvisit
软件有限公司的首席架构
师。
Vít
在数据库技术领域也有超过
15
年的工作经验,主要擅长
Oracle
数据库
技术。
Vít
也是
IOUG
的活跃成员,并经常出席
Oracle OpenWorld、行业合伙
会议、UKOUG、DOAG
以及
NZOUG
的相关活动。Vít
拥有
Oracle Database 10g、
11g
以及
12c
的
OCM
证书,还拥有从
9i
到
12c
的
OCP
证书、Oracle Database 10g
RAC
管理员专家认证,以及
LPIC-2 Linux
网络专业认证。可以访问他的
Twitter(@vitspinka)或博客(http://vitspinka.blogspot.com)。
Franck Pachot
是一位
Oracle ACE
总监,目前是
dbi
服务公司(瑞士)的首席
顾问、培训专家以及
Oracle
技术领导人。
Franck
在
Oracle
技术领域拥有超过
20
年的工作经验。
Franck
也经常参加
Oracle OpenWorld、
IOUG
合作会议、
DOAG、
SOUG
以及
UKOUG
的活动。他是
SOUG
和
DOAG
的活跃成员,同
时还是
OraWorld
团队的荣誉成员。
Franck
拥有
Oracle Database 11g
和
12c
的
OCM
证书, 还拥有从
8i
到
12c
的所有
OCP
证书, 同时拥有
Oracle Database 12c
性能管理与优化方向的
OCE
证书。另外,他还拥有
Oracle Exadata Database
Machine 2014
实施认证证书。可以访问他的
Twitter(@franckpachot)或博客
(http://blog.pachot.net)。
Deiby Gómez
是世界上最年轻的
Oracle ACE(23
岁)以及
ACE
总监(25
岁),
同时也是母国危地马拉的第一位
ACE
和
ACE
总监,还是拉美地区最年轻(24
岁,
2015.2)的
Oracle 11g
OCM
证书获得者。他是危地马拉第一位
OCM
证书获
得者,另外也是最年轻(26
岁,
2016.4)的
Oracle 12c
OCM
证书获得者,是中央
美洲第一位
Oracle 12c
OCM,是最近的
2016
年度编辑选择大奖的获得者(拉斯
维加斯,内华达州)。他经常在
Oracle
全球技术大会上发表演讲,包括
2013
年
至
2016
年的
Oracle
技术网络拉丁美洲年会、合作会议(美国)以及
Oracle
OpenWorld
等。
Deiby
也是
Oracle 12cR2 beta
版本在危地马拉的第一位测试者。
Deiby
分别用英文、西班牙文以及葡萄牙文发表过多篇技术文章,这些文章发
表在
Oracle
网站和
DELL’s Toad World
上。另外,在自己的博客上,他也发表
过数百篇技术文章。他曾以杰出专家的身份出现在
2014
年
11
月份和
12
月份
的
Oracle
杂志上。同时,
Deiby
也是危地马拉
Oracle
用户组(GOUG)的主席、
拉美
Oracle
用户组社区(LAOUC)的技术支持总监,他还是
OraWorld
团队的共
同发起人。目前,
Deiby
拥有自己的公司
NUVOLA,S.A,为拉美地区的客户提供
Oracle
技术服务。
Arup Nanda
以
DBA
的身份工作超过
20
年,工作经验几乎涉及
Oracle
技
术的所有方面,从建模到性能调整,再到
Exadata
均有涉猎。他已经发表过大
约
500
篇文章,是
5
本书的合著者,发表过
300
多场演讲。其博客网站为
arup.
blogspot.com,他也是新手技术导师,是一名经验丰富的
DBA。他曾于
2003
年
获得过
Oracle
年度
DBA
大奖,在
2012
年获得过年度企业架构师大奖。他也是
一位
ACE
总监,同时也是
Oak Table
网络的成员。
Mike Donovan
于
2007
年加入
Dbvisit,在该公司,
Mike
扮演了多个角色,
包括担任全球支持团队的领导人以及数字业务开发先驱。并且就在最近,他成
为该公司的
CTO。
Mike
对新技术有着狂热的激情,他与客户及合作伙伴一起
工作,努力搭建数据库技术与大数据等前沿技术之间的桥梁,从而创造出商业
价值。他喜欢接受挑战,会尝试探求更智能、更低成本的解决方案或替代方案。
Mike
具有技术、艺术以及客户支持和软件开发等多方面的复合背景。他对
Oracle
数据库技术极有热情,并为之工作超过
10
年的时间。他也在多个行业会
议上发表演讲,包括
OOW、
RMOUG、日本数据技术会议以及合作会议等。
Mike
作为产品
DBA
工作多年,获得了从
9i
到
12c
的多项认证。
在
Oracle Database 12cR1
版本(12.1)中, 开始引入名为“多租户”的新选项。
从那时起,新的术语“可插拔数据库”便传播开来。但是这个术语,往往意味
着对该特性或其影响并没有清晰的理解。从
12c
的第一个版本开始,多租户已
经是
Oracle
数据库中最为重大的架构变革之一,同时该选项在数据库软件中已
经被落地实施。多租户选项带来了很多新的特性,但也影响到了
Oracle DBA
进行日常管理的方式。从
12c
的第二个版本(12.2)开始,对多租户选项的可用特
性进行了更多的扩展。现在比较清楚的一点就是,旧的系统架构已经被抛弃,
多租户则已经开始生根发芽——不容忽视。
12cR2
中多租户的到来,需要
DBA
调整他们现有的思考方式,以及进行日
常管理的方式。无论是运行单租户数据库,还是运行包含大量租户的数据库,
都需要经历一个新的学习过程。所以,相比于单纯描述多租户这个新东西究竟
包含了什么内容,本书更倾向于描述与
DBA
相关的工作究竟发生了怎样的变
化,无论是核心的日常维护操作,还是一些相关的高级特性。可以将本书视为
Oracle Database 12c
的管理指南。此外,还可以学到关于这些新特性的一些实
战知识,包括语法上的改变,以及最佳实践等方面的内容。本书由三位具有丰
富
DBA
经验并具备相关认证的
DBA
撰写,并经由诸多技术精湛的审核人员进
行严格审查,从而使内容的价值得到进一步的提升。唯有如此,才能让你带着
洞察一切的激情来了解
Oracle
数据库的管理工作。
本书第Ⅰ部分介绍多租户的功能。其关键问题包括,
Oracle
公司为何要引
入这一选项,并以何种方式来模仿其他数据库产品,以及该选项是否能够真正
为我们设计并部署应用的方式所需要。第
1
章专注这些问题并解释多租户架构。
第
2
章讨论容器数据库(CDB)的创建流程,以及如何正确完成这一流程。因为
在
12c
版本中,创建
CDB
已经是默认的选项,不管信不信,我们真的遇到一些
人在对
CDB
毫不知情的情况下就创建了
CDB。在对多租户的各种特性进行详
细描述之前,第
3
章会为你提供信息,让你决定究竟是选择使用
CDB
还是非
CDB
数据库,并且第
3
章还提供不同可用版本和选项的概要信息。
第Ⅱ部分将会讲述当使用多租户特性时,你的日常工作将会发生怎样的改
变。这一部分从第
4
章开始,该章关注
PDB
的创建与管理,并且也会涉及将数
据库升级到
12c
版本的内容。第
5
章将会详细讨论数据库的网络与服务。接下
来的第
6
章,则会关注另一个重要议题——安全——我们将探讨
PDB
的隔离、
用户的公共性以及加密。
第Ⅲ部分将会讨论备份与复制操作等方面的巨大提升。当然,主要是在
PDB
级别。第
7
章将会详细研究作为每一个
DBA
都应该足够熟悉的领域——
备份和恢复——以及如果需要的话,如何将数据库恢复到过去的某个状态。第
8
章讨论如何使用数据库闪回技术实现归档,以及如何在
PDB
级别实现基于时
间点的恢复。本部分的最后一章,第
9
章将会研究如何插入/拔出
PDB,以及如
何对
PDB
进行克隆、传输或在线重定位(online relocation)。
在本书的第Ⅳ部分,你将会在一个新的层次或级别上学习多租户。当对多
个
PDB
进行集成时,将不得不意识到资源管理器(Resource Manager,
RM)的价
值。关于
RM,将在第
10
章进行讨论。在多租户环境中,
RM
将会发挥极为重
要的作用。第
11
章将会关注如何使用
DG
来对多租户数据库进行保护。第
12
章将会讨论
CDB
中的数据共享问题。与物理克隆或同步技术相比,基于云的
解决方案,则需要数据能够以一种更具灵活性的方式来提供。我们将在第
13
章讨论逻辑复制的相关内容。
第
1
章 多租户概述
······················3
1.1
历史课堂:
IT
技术的
新时代·································4
1.1.1
通往多租户之路············
5
1.1.2
方案集成
·······················
6
1.1.3
表集成
···························
9
1.1.4
服务器集成
···················
9
1.1.5
虚拟化
·························
10
1.1.6
一个实例管理多个
数据库
·························
10
1.1.7
集成策略总结··············
11
1.2
系统字典与多租户架构
··· 11
1.2.1
过去:非
CDB·············
11
1.2.2
多租户容器··················
14
1.2.3
多租户字典··················
16
1.2.4
使用容器
·····················
21
1.3
什么是
CDB
级别的
集成···································27
1.4
本章小结
··························33
第
2
章 创建数据库
····················35
2.1
创建容器数据库(CDB) ····36
2.1.1 OMF
概述····················
36
2.1.2 CDB
创建选项
············
37
2.2
创建可插拔数据库
(PDB) ································52
2.2.1
使用
PDB$SEDD
创建
新的
PDB ····················
53
2.2.2
使用本地克隆方式创建
新的
PDB ····················
56
2.2.3
使用
SQL Developer
创建
PDB ····················
57
2.2.4
使用
DBCA
创建
PDB···
60
2.2.5
使用
Cloud Control
创建
PDB ····················
61
2.3
使用
catcon.pl
脚本
··········62
2.4
本章小结
··························64
第
3
章 单租户、多租户以及应用
容器·······························65
3.1
多租户架构不是一个
选项
··································66
3.1.1
抛弃非
CDB ················
66
3.1.2
不兼容特性
·················
67
3.2
标准版中的单租户···········68
3.2.1
数据移动
·····················
68
3.2.2
安全
·····························
69
3.2.3
与
SE2
集成·················
69
3.3
企业版中的单租户···········70
3.3.1
闪回
PDB·····················
71
3.3.2 PDB
的最大数量
·········
71
3.4
使用多租户选项···············73
3.4.1
应用容器
·····················
73
3.4.2
与多租户选项集成
······
76
3.5
本章小结
··························77
第
4
章 日常管理
·······················79
4.1
选择要使用的容器···········81
4.2
管理
CDB ·························83
4.2.1
创建数据库··················
83
4.2.2
启动与关闭数据库
······
83
4.2.3
删除数据库··················
84
4.2.4
修改整个
CDB·············
84
4.2.5
修改根容器··················
85
4.3
管理
PDB··························86
4.3.1
创建新的
PDB ·············
86
4.3.2
打开和关闭
PDB ·········
86
4.3.3
查看
PDB
的状态
········
90
4.3.4
查看
PDB
的操作
历史
·····························
90
4.3.5
在多个
PDB
上运行
SQL······························
90
4.3.6
修改
PDB·····················
91
4.3.7
删除
PDB·····················
93
4.4
打补丁与升级···················93
4.4.1
升级
CDB ····················
94
4.4.2
插入
··························
103
4.4.3
打补丁
······················
105
4.5
使用
CDB
级别与
PDB
级别
的参数·····························106
4.5.1 CDB SPFILE·············
106
4.5.2 PDB SFPILE
的
等价性
······················
106
4.5.3 SCOPE=MEMORY ···
108
4.5.4 ALTER SYSTEM
RESET·······················
108
4.5.5 ISPDB_MODIFIABLE···
108
4.5.6 CONTAINER=ALL ···
109
4.5.7 DB_UNQIUE_
NAME ·······················
110
4.6
本章小结
························ 111
第
5
章 网络与服务
··················113
5.1 Oracle Net ······················· 114
5.2 Oracle
网络监听
············· 114
5.3 LREG
进程
····················· 115
5.4
网络:多线程与
多租户····························· 117
5.5
服务名称
························ 119
5.5.1
默认服务与连接到
PDB ···························
119
5.5.2
创建服务
···················
122
5.6
为
PDB
创建专用监听
···127
5.7
本章小结
························130
第
6
章 安全·····························131
6.1
用户、角色以及权限·····132
6.1.1
公共用户还是本地
用户?
·······················
132
6.1.2
何为用户?
···············
133
6.1.3 CONTAINER=
CURRENT·················
134
6.1.4 CONTAINER=
COMMON·················
135
6.1.5
本地授权
···················
138
6.1.6
公共授权
···················
139
6.1.7
冲突解决
···················
140
6.1.8
保持清晰与简单·······
143
6.1.9 CONTAINER_
DATA························
143
6.1.10
角色
························
145
6.1.11
代理用户·················
145
6.2
锁定概要文件
(lockdown profile)············147
6.2.1
禁用数据库选项·······
148
6.2.2
禁用
ALYTER
SYSTEM···················
148
6.2.3
禁用特性
··················
150
6.3 PDB
隔离························150
6.3.1 PDB_OS_
CREDENTIALS········
150
6.3.2 PATH_PREFIX ·········
151
6.3.3 CREATE_FILE_
DEST ························
151
6.4
透明数据加密(TDE) ······151
6.4.1
创建
TDE··················
152
6.4.2
带有
TDE
的插入与克隆
操作
··························
157
6.4.3 TDE
总结··················
157
6.5
本章小结
························157
第
7
章 备份和恢复··················161
7.1
回到基础知识·················162
7.1.1
热备份与冷备份·······
162
7.1.2 RMAN:默认配置
···
164
7.1.3 RMAN
冗余备份······
165
7.1.4 SYSBACKUP
权限···
166
7.2 CDB
备份与
PDB
备份
···166
7.2.1 CDB
备份
··················
167
7.2.2 PDB
备份···················
171
7.2.3
别忘了归档日志!
····
174
7.3
恢复场景
························174
7.3.1
实例恢复
···················
175
7.3.2
对
CDB
进行还原和
恢复···························
176
7.3.3
对
PDB
进行还原和
恢复···························
178
7.4 RMAN
优化方面的一些
考量·································180
7.5
数据恢复指导·················183
7.6
块损坏
····························184
7.7
使用
Cloud Control
进行
备份
································184
7.8
本章小结
························186
第
8
章 闪回与基于时间点的
恢复·····························189
8.1 PDB
的基于时间点的
恢复
································190
8.1.1
在指定时间恢复
PDB ···························
191
8.1.2 UNDO
在哪里?
·······
193
8.1.3
版本
12.1
中的
PDBPITR
总结
··········
195
8.2
版本
12.2
中的本地
UNDO ·····························196
8.2.1
数据库属性
···············
197
8.2.2
创建数据库
···············
197
8.2.3
修改
UNDO
表空间
··
198
8.2.4
修改
UNDO
管理
模式···························
199
8.2.5
共享
UNDO
还是本地
UNDO?
···················
200
8.3
版本
12.2
中
PDBPITR···201
8.3.1
共享
UNDO
模式下的
PDBPITR··················
201
8.3.2
本地
UNDO
模式下的
PDBPITR··················
202
8.4
闪回
PDB························202
8.4.1
闪回日志
··················
203
8.4.2
使用本地
UNDO
进行
闪回
··························
205
8.4.3
使用共享
UNDO
进行
闪回
··························
205
8.4.4 CDB
和
PDB
级别的
还原点
······················
206
8.4.5
干净还原点···············
209
8.5 resetlogs ·························· 210
8.6
闪回与
PITR···················212
8.6.1
何时需要
PITR
或
闪回?
······················
212
8.6.2
对备库的影响···········
212
8.6.3
辅助实例的清除·······
214
8.7
本章小结
························215
第
9
章 移动数据
·····················217
9.1
锚定
PDB
文件位置
·······218
9.2
插入与拔出
····················218
9.2.1 PDB
的拔出与插入
··
219
9.2.2
停留在源库中的已拔出
数据库
······················
220
9.2.3 XML
文件中究竟有
什么?
······················
222
9.2.4
为插入操作检查
兼容性
······················
225
9.2.5
像克隆一样插入········
226
9.2.6 PDB
的归档文件
·······
228
9.3
克隆
································229
9.3.1
克隆本地
PDB···········
229
9.3.2
克隆远程
PDB···········
231
9.4
应用容器的一些考量·····236
9.5
转换非
CDB
数据库·······236
9.5.1
插入非
CDB ··············
237
9.5.2
克隆非
CDB ··············
239
9.6
将
PDB
移动到云上
·······240
9.7
基于
PDB
操作的
触发器·····························241
9.8
全传输导出/导入············241
9.9
可传输表空间·················244
9.10
本章小
结
···························
245
第
10
章
Oracle
数据库资源
管理器························249
10.1
资源管理器基础···········250
10.1.1
资源管理器关键
术语
·······················
251
10.1.2
资源管理器的
需求
·······················
253
10.1.3
资源管理器的
级别
·······················
253
10.2 CDB
资源计划··············254
10.2.1
资源分配与使用
限制
·······················
254
10.2.2
默认与自动任务
指令
·······················
256
10.2.3
创建
CDB
资源
计划
·······················
257
10.3 PDB
资源计划··············265
10.3.1
创建
PDB
资源
计划
······················
266
10.3.2
启用或禁用
PDB
资源
计划
······················
268
10.3.3
移除
PDB
资源
计划
······················
269
10.4
使用初始化参数管理
PDB
的内存和
I/O ················269
10.4.1 PDB
的内存分配··
269
10.4.2
限制
PDB
的
I/O···
270
10.5
实例囚笼
(instance caging) ··········· 270
10.6
监控资源管理器···········272
10.6.1
查看资源计划与资源
计划指令···············
272
10.6.2
监控被资源管理器
管理的
PDB ··········
273
10.7
本章小结
······················274
第
11
章
Data Guard ···············275
11.1 ADG
选项·····················276
11.2
创建物理备库···············277
11.2.1
使用
RMAN
进行
复制
······················
277
11.2.2
使用
EMCC
创建
备库
······················
289
11.3
在多租户环境下管理
物理备库
······················292
11.3.1
在源端创建新的
PDB ······················
293
11.3.2
将
PDB
从源端
删除
······················
294
11.3.3
修改子集
··············
295
11.3.4 EMCC····················
298
11.4
云上的备库···················298
11.5
本章小结·······················301
第
12
章 在
PDB
之间共享
数据···························303
12.1
数据库链接···················304
12.2
共享公共只读数据·······305
12.2.1
可传输表空间········
306
12.2.2
存储快照与基于写的复
制(copy on wirte) ···
307
12.3
跨
PDB
视图·················308
12.3.1
简单用户表
···········
309
12.3.2
集成数据
···············
313
12.4
跨数据库复制···············327
12.5
本章小结
······················327
第
13
章 逻辑复制····················329
13.1 Oracle
日志挖掘器
(LogMiner)····················331
13.2
已过期的特性···············332
13.2.1 Oracle CDC···········
332
13.2.2 Oracle
流技术
·······
332
13.2.3 Oracle
高级复制
···
332
13.3 OGG(Oracle
GoldenGate)··················333
13.3.1 OGG
中的多租户
支持
······················
333
13.3.2
大数据适配器·······
343
13.4 Oracle XStream·············345
13.5
逻辑备库
······················346
13.6
其他第三方选项···········347
13.6.1 Dbvisit Replicate ···
347
13.6.2 Dell SharePlex·······
347
13.7
本章小结
······················347
多租户意味着什么
多租户概述
在
Oracle Database 12c
中,
Oracle
引入了一项发生于数据库体系结构上的
重大调整。在
Oracle Database 12c
以前,一个实例只能打开一个数据库。如果
想处理多个数据库,那么需要启动多个实例才行。因为它们都是完全隔离的架
构,即便这些数据库都安装在同一台服务器上也是如此。这一点与其他关系型
数据库颇为不同,其他很多的数据库,都是可以使用一个实例来管理多个数据
库的。
进入
Oracle Database 12c
之后,一个实例就可以打开多个可插拔数据库,
或者称之为
PDB(Pluggable DataBase)。
Oracle
将之称为新多租户架构,以前旧
的架构名称便被抛弃了。无论是否使用了多租户选项,将来所有的
Oracle
数据
库都会运行在多租户架构上。关于这点事实,所有的
DBA
都是不能忽视的。
1.1
历史课堂:
IT
技术的新时代
在介绍将来的架构之前,让我们先简要回顾一下使用数据库的历史。如你
在图
1-1
中所看到的,我们并不关注时间,而是关注数据库版本,通过它来回
顾
Oracle
数据库的演化历程。
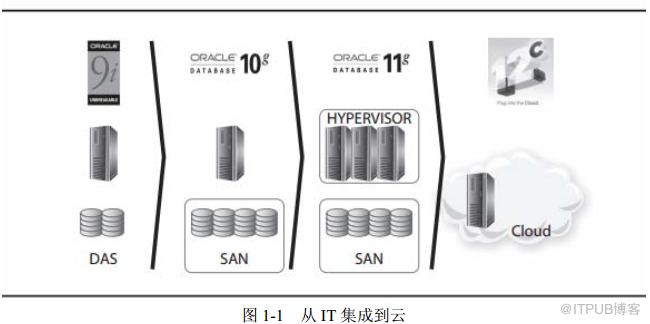
图
1-1
从
IT
集成到云
当
Oracle Database 8i
和
9i
出现在市场上时, 数据中心使用中型机逐渐变得
流行起来。我们从大型机时代开始步入客户端/服务器时代。而当时的
Oracle
数据库的体系结构,显然是非常适应这一趋势的。由于
Oracle
数据库是使用
C
语言编写的,因此它在多种平台上均能成功运转。并且,所有用户管理信息都
存储在数据库的数据字典中。
Oracle
数据库显然为客户端/服务器架构做好了准
备,它可以使用操作系统来监听
TCP/IP
端口并存储文件。此外,数据库的架构
在小型机上也是可扩展的,这多亏了一个被称为并行服务器的特性。当然,后
来它被称为
RAC(Real Application Cluster)。
随着服务器数量的增长,数据库的数量也随着增长。在那时,一家公司往
往会拥有很多台物理服务器,并且使用
DAS(Direct Attached Disks,直连存储)
作为存储,而在每台服务器上,则又运行着
1
个或
2
个
Oracle Database8i
或
9i
实例。
随着数据库数量的增长,管理所有的服务器和磁盘则又成为噩梦一般的存
在。面对着数据的指数级增长,还依然使用内部磁盘来管理这些数据的话,则
容量规划就变得极其困难。此时,
Oracle Database 10g
便应运而生。我们需要
对存储进行集成,这样我们就可以把数据库文件存放到一个存储阵列中,并通
过
SAN(Storage Area Network, 存储区域网络)让所有的服务器都可以共享访问。
这就是存储集成。
随着时间的流逝,
Oracle Database 11g
开始登场。早期,比较流行的想法
是,我们使用服务器,然后每台服务器上都带有磁盘。但是,相比于设置多台
服务器的容量并对其进行维护而言,虚拟化软件则为我们提供了一种新的可能:
我们可以将多台物理服务器放在一起,并在此基础之上提供虚拟机。在以前的
时代,我们就是使用这样的方法:应用服务器、
SAN
或
NAS,以及虚拟机。
现在,
Oracle Database 12c
为我们带来一种新的方法。很多拥有集成存储
和服务器的组织,目前已经意识到运营这样的架构其实并非他们的核心业务。
相反,他们将
IT
需求视作一个服务,它应该具有可扩展性和灵活性。小公司想
要使用公有云来提供他们所需的
IT,大一些的公司则打算建立自己的私有云。
在这样的情况下,虚拟化就可以提供
IaaS(Infrastructure as a Service,基础设施
即服务)。但是,我们也需要
AaaS(Application as a Service,应用即服务)和
DBaaS(DataBase as a Service,数据库即服务)。对于
IT
技术生态圈而言,这显
然是一个极为重大的变化。 这与当年从客户端/服务器架构进化到应用服务器时
代颇为相似,无论是扩展性方面还是重要性方面。当然,这一过程并非一蹴而
就——它需要时间。不过,现在就可以断言,在接下来的十年中,混合模型(按
需供应/云)将变得更强大,但是也终将会被云慢慢替代。
正如我们所期待的,新的时代有着不同的需求。数据库的未来也将与集成、
敏捷开发,以及快速就绪等联系在一起。对于
Oracle
而言,类似这样的一些特
性,其实从
9i
到
11g
一直都处于快速进化之中。比如简单数据传输、克隆,以
及精简指令配置(thin provisioning)等。但是数据库中的两个核心架构功能:一
数据库一实例,以及一数据库一数据字典,一直以来都是如此,尚未做好集成
的准备。为此,
Oracle Database 12c
提供了这两个问题的答案:多租户。在保
留原有可移植性架构的基础之上,
Oracle
对其架构进行了设计调整,从而使得
可以在同一个数据库上运行应用——无论程序是运行在小型服务器上,还是运
行在很大的云上。
1.1.1
通往多租户之路
新的时代是关于集成的时代。一些人会将其想象成一个集中式系统,并辅
以集中管理。但是这带来了新挑战:我们需要越来越高的敏捷性。让一个数
据库快速就绪在今天而言,本非一件容易之事。但至少,我们不能让它变得
更糟糕。
考虑这样一个例子。你是一个
Oracle DBA。然后一个开发人员来到你的办
公桌前,并表示她需要一个新的数据库。在她的意识里,可能会认为这是一个
很简单的需求,你只需要在一个管理界面上单击几下鼠标应该就能搞定。你看
着她,瞪大眼睛,然后告诉她需要去填一张需求申请单,上面需要指定存储、
内存、
CPU
以及可用性方面的内容。并且,你还得解释,这样的需求要上级领
导批准,需要花费数天甚至一周的时间才能建立一个数据库。显然,这里就是
开发人员与运维人员之间通常会产生误解的地方。
开发人员可能以前就没有使用过
Oracle
数据库, 所以她就闪过一些念头,
认为数据库不过就是用来装她的应用程序表的一个容器罢了,并且这个容器
还是一个很轻量级的玩意——在很多其他的非
Oracle
数据库中,这实际上就是
“数据库”。
但是在
Oracle
中,恰恰相反,我们是有一些轻量级的容器——逻辑级别上
的方案(scheme),以及物理级别上的表空间(tablespace)——但是数据库,则不仅
仅是这些内容的整个组合。
Oracle
数据库,是一组方案和表空间的集合,然后
再加上用于管理这些内容的元数据(数据字典),以及为数众多的用于实施各种
特性的
PL/SQL
代码(DBMS
包)。每一个数据库都必须拥有自己的实例,而实
例又由一组后台进程和一块共享内存构成。并且每一个数据库也都有相应的结
构来保护事务的完整性,比如
UNDO
表空间和
REDO
日志。
因此,基于上述这些理由,提供一个新的数据库并不是件很琐碎细微的事
情。要创建一个新的数据库,需要与系统管理员和存储团队进行沟通,因为需
要服务器和磁盘资源。你并不打算在一台服务器上部署太多实例,但是你也不
太可能在一台服务器上只部署一个数据库。正是因为这些,现在我们通常使用
虚拟化技术,然后为每个实例提供一台虚拟机(Virtual Machine,
VM)。当然,
这种方法并不适用于每一个应用或每一个环境,从敏捷的角度来看——因为这
样的话,需要的虚拟机就太多了。另外,当为每一个数据库都不得不分配服务
器、存储以及实例时,最终你就会发现,这样浪费太多资源了。
在
Oracle Database 12c
以前,这种场景下,对于开发人员来说,比较合适
的方法,就是在现有的数据库中为其创建新的方案。但是这种方法并不总是可
能的,或者说是可行的。让我们解释一下为什么。
1.1.2
方案集成
在
Oracle Database 12c
以前,方案就是可用的解决方法。每一个应用程序
都可以有自己的方案,或是一组方案,如果想将表和存储过程分开的话。这些
方案在逻辑上是隔离的,并使用权限管理来保证其安全性。
从物理上来讲,也可以为每个应用设置不同的表空间。这就意味着,一旦
数据文件丢失,在还原期间,可能就只有一个应用处于离线状态。如果想将表
空间重新分布到其他文件系统中,也是如此。但是,除此之外,为了优化资源
使用,其他的所有资源我们都是共享的:实例进程与内存、SYSTEM
与
SYSAUX
表空间、数据字典等。
备份策略和高可用(High Availability,
HA)策略也都是相同的。一个
DBA
管理一个数据库,然后在这个数据库上运行多个应用。在
Oracle
数据库的早期
版本中,数据库就是按照这样的方式来设计的。
1.
可传输表空间
在
Oracle
数据库中,很多操作都是发生在表空间级别的。尤其是可传输表
空间这一特性。通过这一特性,可以将应用的数据文件物理地拷贝到其他数据
库中,即便是拷贝到一个更高版本的数据库中也是可以的。可传输表空间这一
特性足够重要,因为它被认为是多租户技术的先驱,或者是始祖。1997
年,
Oracle
公司为可传输表空间技术申请专利,名为“数据库系统的可插拔表空间”。而现
在,多租户架构恰恰就是可插拔数据库的基础。
在这里,可插拔的意思,就是可以直接将一个物理结构(数据文件)插到一
个数据库中,并令其成为该数据库的一部分。可传输表空间这一特性,就能够
将用户表空间的数据文件插入到数据库中。 然后就只需要导入相应的元数据(数
据字典实体)即可。这样,在新的数据库中,这些逻辑对象的定义就与数据文件
中的物理内容相匹配了。
当然,在
Oracle Database 12c
中,也可以传输表空间,这样的操作也足够
简单。如果想传输所有的用户表空间,使用“FULL=Y”选项即可。但是相关
的元数据还是需要被逻辑传输。如果有数百张表的元数据需要传输,那么这个
时间可能就会比较长。即便这些表都是空表也是如此。例如,如果想迁移一个
PeopleSoft
数据库,它里面包含
20 000+张表。即便这些表都是空的,导入元数
据也需要几个小时的时间。
正如你将看到的,由于多租户更卓越的性能,传输一个可插拔数据库,实
际上就成为所有数据文件的传输,包括
SYSTEM
和
SYSAUX
中的数据文件。
显然,这里面就包含了数据字典,甚至还可能包含
UNDO
信息。这就意味着所
有的元数据也将会被物理导入。因此,相比传统的可传输表空间技术,这样的
操作就快了很多。
2.
方案名称冲突
在真实世界中,想实现方案集成,其实还是很有难度的。你可能想将很多
应用都集成到一个数据库中,甚至包括同一个应用的测试环境也想集成进来。
此时,就会面对一系列应用程序的约束问题。
如果应用中的方案所有者是硬编码的,不能修改,那么此时该怎么办?如
果我们需要建立一个电话清单系统,而该系统在数据库中对应的方案为
PB,然
后我们想将多个环境都集成到测试数据库中,那么这显然是被禁止的。原因是
该方案的名称已经硬编码到应用程序以及包中,当然还有其他地方。如果有应
用程序供应商派来的顾问,也许我们还能够比较好地理解这些奇怪的方案名称。
但是如果没有,可能就得去猜测这些方案名称最初究竟是什么意思。
当然,如果应用是在你的掌控之下进行设计的,那么你就可以避免这样的
问题。并且无须多言,你应该在自己的应用程序中从来都不要对方案名称进行
硬编码。可以使用某一用户连接到数据库,然后简单地使用
ALTER SESSION
SET CURRENT_SCHEMA
语句来设置当前应用程序的方案所有者,从而来访
问所有相关的对象。如果有多个方案?那么为应用程序使用多个方案倒也不算
是一个坏主意。
例如,可以使用代码(PL/SQL
包)来分离数据(表)。这能够让数据实现更好
的隔离与封装。但即便是在这种情况下,也不要将表所在的方案名硬编码到包
中。可以在包所在的方案中,为这些对象创建同义词即可。这样,就可以在
PL/SQL
代码中引用这些对象,而不用使用方案名(因为同义词与代码在同一个
方案中),而这些同义词会自动关联到相应的对象上。如果对象名称发生改变,
重新创建同义词就行了。这些动作都可以很简单地完成,也可以自动完成。
3.
公共同义词与数据库链接
对于上面提到的同义词,显然,我们讨论的是私有同义词。不要使用公共
同义词。因为它们会覆盖整个名称空间中的私有同义词。当一个应用程序创建
公共同义词时,无法让其绑定其他任何东西。这就是方案集成的一个限制:不
属于特定方案的对象,容易与其他应用程序,或是其他版本、其他环境中的同
一应用的对象产生冲突。
4.
角色、表空间名称与目录
一个应用程序可以定义或引用其他对象,只要这些对象均处于数据库的公
共名称空间即可——例如角色、目录以及表空间名称。如果一个应用程序在不
同环境中运行,则这些环境其实也可以被集成到同一个数据库中。只需要在执
行
DDL
脚本时,为不同的环境分别设置不同的参数,从而可以让这些数据库
对象分别适用不同的环境即可。如果不是这种情况的话,那么想实现方案集成
就有难度了。
另外一方面,这些不属于特定方案的对象,也会让数据移动的实现变得更
为复杂。例如,当想使用数据泵(Data Pump)来导入一个方案时,这些对象可能
需要在事先就完成创建。
5.
游标共享
即便一个应用程序是专门为方案集成而设计的,在将所有的东西都集成
到一个数据库里面时,也照样可能会遇到性能方面的问题。我们曾经处理过
一个包含
3000
个方案的数据库,它其实是一堆数据集市(data mart):结构相
同,数据不同。
另外,很显然,应用程序的代码也都是相同的。用户需要连接到其中一个
数据集市,然后执行查询,而这些查询已经在应用程序中进行了定义。这就意
味着同样的查询——甚至在
SQL
文本上也是完全相同的——将会运行在不同
的方案上。如果知道
Oracle
数据库中的游标共享是如何实现的,就立即能够看
到问题所在:一个游标会有上千个子游标。一个父游标会被所有的
SQL
文本共
享,当对象不同时,便会创建不同的子游标。当在多个方案中执行这些代码时,
问题就出来了。
SQL
解析时需要扫描一个相当长的子游标链表,而在扫描期间
需要持有
latch,这显然会导致很严重的库缓存竞争。
在多租户环境下,为满足集成的目的,父游标会被共享,但是在子游标搜
索方面需要进行一些性能方面的提升,从而缓解上述问题。
1.1.3
表集成
当想要对多个环境中的数据进行集成时,而这些环境又有着相同的应用程
序及代码版本,这就意味着要用到的表将会具有完全相同的结构,可以把所
有的东西都放到一张表中。通常情况下,我们是在每一个主键值中添加环境
ID(公司、国家、市场以及其他信息)来区别数据。这样做的好处,是可以一次
性管理所有的东西。例如,当想要添加索引时,可以为所有的环境添加。
基于性能和维护方面的原因考虑,可以基于环境
ID
来对表中的数据进行
物理分区,并将不同的分区数据存放在不同的表空间中。但是,这样做,其隔
离级别就会很低,并进而影响到性能、安全以及系统的可用性。
实际上,大部分应用程序都采用类似这样的设计,并且一般都把数据存储
在一个环境中。绝大部分情况下,添加到主键值前面的
ID
往往都只有一个值,
而这也是
Oracle
引入索引跳跃扫描的原因之一。可以使用虚拟私有数据库策略
来管理对这些环境的访问。可以使用分区交换技术,在物理上实现对这些分区
的独立管理。如果想找一个类似的例子,可以看一下
RMAN
的资料库(恢复目
录):所有已注册的数据库,其信息都存储在相同的表中。但是,在存储不同环
境(测试、开发以及生产环境)中的数据时,或是存储不同版本(数据模型也不尽
相同)的数据时,这样的隔离其实是不够的。
1.1.4
服务器集成
如果有多个独立的数据库,但是又不想为每个数据库都配置一台服务器,那
么可以将这些实例集成到一台服务器上。如果曾经登录过
Oracle
的
Ask Tom
网
站(astome.oracle.com/),并咨询过在一台服务器上推荐配置几个实例,
Tom Kate
的答案是这样的:“我们不建议在一台主机上部署多个实例——主机可以是虚拟
机或物理机,我们并不关注——但是你可以这样认为:一台主机
=
一个实例。”
但是在真实生活中,就像我们看到的那样,一台数据库服务器上往往运行着多个
实例。可以在一台主机上安装多个版本的数据库(ORACLE_HOME),也可以在一
台主机上运行多个实例——并且很多时候都是不得不如此。我们曾经见过一台
服务器上运行着多达
70
个实例。
这种情况下,在实例之间进行隔离的方法就比较少了。比如内存,可以通
过设置
SGA_MAX_SIZE
参数来在物理上对内存进行分割。也可以在
Oracle
Database 12c
中使用
PGA_AGGREGATE_LIMIT
来限制进程使用的内存。可以
使用实例囚笼策略,来设置每个实例在
CPU
上运行的最大进程数量。在最新的
Oracle Database 12cR2
中,不需要企业版就可以使用实例囚笼策略。我们将在
第
3
章中讨论这个主题。
但是,在一台服务器上运行大量的实例依然是个问题。例如,当要重启服
务器时,需要启动大量的进程,并完成内存分配。一次服务器停机,无论是计
划内的还是计划外的,都会对大量应用程序造成影响,并且需要消耗大量资源
来处理多个
SGA
以及数据字典表。
1.1.5
虚拟化
现今,虚拟化是一个非常好的方法,可以在不需要管理大量物理服务器的
前提下实现一个实例一台服务器。可以对环境进行极好的隔离设置,在限制范
围内分配
CPU、内存以及
I/O
带宽。甚至可以使用不同的网络来隔离这些数据
库。但是,即便这些服务器都是虚拟机器,也还是无法解决资源浪费,因为还
是要持有多个
OS、
Oracle
软件、内存以及数据字典。并且,还是得管理多个数
据库——备份恢复、实现高可用特性,比如
Data Guard
等。然后,还是有多个
OS
需要打补丁和监控。
此外,在虚拟化环境中,软件许可也是梦魇般的存在。当进行软件安装
时,
Oracle
软件是按照处理器数量进行授权的,
Oracle
会考虑这些因素,比
如与虚拟化技术相关的授权问题,以及在虚拟机上安装软件并运行,等等。
当然,这些也依赖供应商所提供的管理程序,以及这些管理程序的版本。
1.1.6
一个实例管理多个数据库
那么问题来了,如何找到一种方法,能够实现这样的一种隔离级别:能够
同时满足环境的隔离与资源集成两个目的。显然,这种隔离级别高于方案隔离,
但是又低于我们现在所知道的实例与数据库。也就是说,我们可以在一台服务
器上,使用一个实例来管理多个数据库。
在
12c
以前的
Oracle
数据库版本中,显然没有这样的功能。但是在现今
的多租户架构中,这种方法就颇为可行了。现在,一个集成的数据库可以管
理多个可插拔数据库。另外,也出现了一种新的隔离级别,即独立数据库——
可插拔数据库,这种架构在环境准备、移动以及系统升级等方面都提供了相
当高的敏捷性。
1.1.7
集成策略总结
表
1-1
简要总结了在多租户技术出现之前,几种可选的集成策略之间的不
同之处。
表
1-1
不同集成策略的优劣分析
| 集成策略 | 优势 | 劣势 |
| 表 | 将所有内容当成一个整体来进行管理 |
隔离级别受限较大,且不适用于不
同环境 |
| 方案 |
可以实现实例、数据字典以及
HA
级
别的共享 |
公共对象之间容易出现冲突,且隔
离级别受限 |
| 数据库 | 只需要管理一个数据库 |
需要多个
SGA
及多组后台进程,也
需要维护多个备份与 HA 配置 |
| 虚拟化 |
可以提供最佳的隔离级别,可以实现
职责分离,并提供 HA 以及 vMotion 方面的特性 |
授权许可问题,需要学习新的技术,
需要管理并运行多台主机 |
1.2
系统字典与多租户架构
在多租户架构中,系统字典是变化最大的部分之一。让我们来看看在以前
的版本中,系统字典是如何实现的,以及在
Oracle Database 12c
中,它又发生
了哪些变化。
1.2.1
过去:非
CDB
数据库中既存储数据,又存储元数据。例如,假设在
SCOTT
方案下有一
张表
EMP。该表的描述信息——名称、包含的列以及数据类型等——同样也存
储在数据库中。这些描述信息——也就是元数据——存储于系统表中,并且是
系统字典的一部分。
1.
字典
Codd
的规则(由
E.F.Codd
建立, 其提出了关系模型)定义了关系型数据库中
的元数据必须与数据有着同样的表现形式:可以使用
SQL
来查询元数据或数
据。作为数据库管理员,这样的事情几乎每天都在做。通过查询字典视图,例
如
DBA_TABLES,来获取数据库中对象的相关信息。
Codd
的规则虽然只用于
表述逻辑层面,并由字典视图提供这些信息;但是
Oracle
走得更远——通过在
关系型表中物理存储这些元数据信息——对于同样类型的表和应用程序表,这
些都为
SYS
方案所拥有,并存储在系统表空间(SYSTEM
和
SYSAUX)中。
其实,在处理数据及元数据信息存储时,并不需要使用
Oracle
字典的实际
名称和详细信息,如图
1-2
所示。表
SCOTT.DEPT
用于存储用户数据,该表的
定义则存储在字典表中, 即
SYS.COLUMNS。该字典表用于存储列的相关信息,
并且由于这个字典本身也是表,因此它的定义信息也采用同样的方式存储下来。
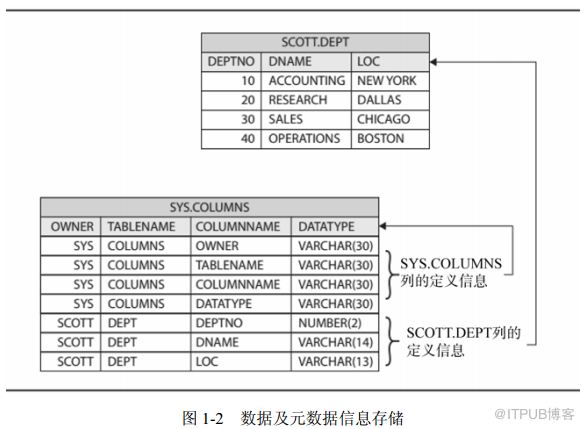
图
1-2
数据及元数据信息存储
当然,系统字典表中不仅仅存储了表的定义信息。一直到
8i
版本,数据存
储(表的
extent
信息)的物理描述信息也都是存储在字典表中的。但是,为了适
应可插拔的需求,表空间已经变得越来越自包含了。因此,数据存储的处理方
式,随着本地管理表空间的出现而发生了变化。另一方面,在每一个新的数据
库版本中,都会有很多新的信息会被添加到系统字典中。在当前的数据库版本
中,
Oracle
数据库软件的很大一部分功能,都是用
PL/SQL
包来实现的,而这
些内容,也是存储在系统字典中的。
2. Oracle
管理的对象
对于
Oracle
数据库而言, 其系统字典的实现方式, 就是我们前面所讨论的:
字典存储在数据库中。每一个数据库都有其自己的系统字典。并且当使用逻辑
导入/导出工具(EXP/IMP
或数据泵)来移动数据库时,可能就会发现,有些字典
对象属于系统,有些用户对象属于应用程序,而如何将这些对象区分开来,则
是一件很棘手的事情。当将一个数据库完整地导入(在
IMPDP
中使用
FULL=Y
选项, 这将在第
8
章进行讨论)新建的数据库中时, 你不会想把字典信息也导入,
因为在目标数据库中,这些内容已经存在了。
当然,
SYS
方案中的对象就是字典对象,并且它们会被数据泵忽略。但是
如果有人在
sys
下创建了用户对象,那么这些对象就会丢失,基于
sys
对象的
授权也会丢失。并且在其他地方也可以找到一些系统对象,例如在
OUTLN、
MDSYS
以及
XDB
等方案中。另外,系统中也有很多角色,也可以创建自己的
角色。想把它们区分开也不是那么容易。
幸运的是, 在
12c
版本中,
DBA_OBJECTS、
DBA_USERS
以及
DBA_ROLES
视图中都包含了一个标记,用来指明哪些是数据库维护的对象,是由数据库创建
的,并且不属于你的应用程序。我们可以在
12c
版本中查询出这些
Oracle
维护的
方案列表:
在
12c
版本中,这显然是一个非常大的提升。可以很简单地确认哪些方案
属于你的应用程序,而哪些又属于数据库系统。
ORACLE_MAINTAINED
标记
列在
DBA_OBJECTS、
DBA_USERS
以及
DBA_ROLES
视图中存在,因此现在
就可以很容易地区分哪些对象是由数据库创建的,以及哪些对象是由应用程序
创建的。
注意:
12c
Oracle
EXP/IMP
EXU8USR
KU_NOEXP_TAB
Data Guard
LOGSTDBY_SKIP_SUPPORT
DEFAULT_PWD$
V$SYSAUX_OCCUPANTS
DBA_REGISTRY
3.
系统元数据与应用程序元数据
我们已经描述了如下元数据结构: 方案、 对象以及角色。 让我们再深入一点,
深入数据去看一看。你已经知道表的定义信息存储在字典表中, 例如在图
1-2
中,
我们简要提了一下
SYS.COLUMN
表。但是,字典数据模型其实是很复杂的。
实际上,对象名称存储在
SYS.OBJ$中,表的信息存储在
SYS.TAB$中,列的
信息则存储在
SYS.COL$中,等等。这些都是表,并且每一个都有自己的定义
信息——元数据——存储在字典表
SYS.TAB$中。例如,它里面存储了你自己
创建的表的信息,但是也存储了所有字典表的相关信息。
在
SYS.TAB$中,有一行数据是用于存储自身的定义信息。你可能会问,
在创建表时(当然也是创建数据库时),这一行是怎样插入到表中的,因为当时
这张表应该还不存在。在
ORACLE_HOME
中,Oracle
有一段特殊的引导代码(关
于这部分内容,已经超出了本书的范围。不过可以查看
ORACLE_HOME/
rdbms/admin
目录下的
dcore.bsq
文件。也可以查询
BOOTSTRAP$表,看看在启
动阶段,数据库是如何在字典缓冲区中创建这些表的。此时这些基础的元数据
都是立即可用的,从而允许对余下的元数据进行访问)。
所有的元数据都存储在这些表中,但是在非多租户环境下有一个问题:系统
信息(属于数据库的信息)与用户信息(属于应用程序的信息)是混杂在一起的。这
些元数据都存储在同样的表中,并且所有这些东西都存储在同一个容器——数
据库中。
这就是多租户架构中与之前不同的地方:我们现在可以使用多个容器,从
而将系统信息与应用程序信息分离开来。
1.2.2
多租户容器
在多租户数据库中,最重要的结构就是容器。一个容器包含数据和元数据。
多租户中的不同之处在于:一个容器可以包含多个容器,从而分离对象,无论
是物理上还是逻辑上。一个容器数据库可以包含多个可插拔数据库,以及一个
根容器,用来存储公共对象。
多租户数据库是容器数据库(Container DataBase,
CDB)。在原有的架构中,
一个数据库就是一个单一的容器,并且无法再分,这被称为非
CDB。在
12c
版本
中,可以选择是创建
CDB
还是非
CDB。可以创建一个
CDB,也就是多租户数据
库,通过在实例参数中设置
ENABLE_PLUGGABLE=true,并且在
CREATE
DATABASE语句中添加
ENBALE PLUGGABLE
选项来完成(更多细节请参阅第
2
章)。
这样就会创建出一个
CDB, 其中可以包含其他容器。这些容器可使用数字、
容器
ID
或名称进行标识。一个
CDB
中至少包含一个根容器和一个种子容器,
也可以添加自己的容器,在
12.1
版本中,最多可以添加
252
个容器;在
12.2
版本中,则可以多达上千个容器。
1.
可插拔数据库
多租户的目的是集成。相比于在一台服务器上部署多个数据库,现在我们
只需要创建一个集成的数据库即可,也就是
CDB。它里面可以包含多个可插拔
数据库(PDB)。并且每一个
PDB
对于它的用户来说,都是一个完整的数据库。
它有多个方案、公共对象,有系统表空间、字典视图等。
多租户架构可以用来在私有云或公有云上进行集成。可以实现数百个甚至
上千个
PDB
的集成。其目的是,可以提供多个
PDB
的快速就绪服务,但呈现
出来的状态却像是一个数据库。根据这种设计方式,任意连接到一个
PDB
的用
户都无法区分自己是连接到了一个
PDB
还是一个独立的数据库。
另外, 所有以前版本中使用的命令现在照样可用。例如, 当连接到一个
PDB
时,可以执行
shutdown
来关闭这个
PDB。当然,它实际上并不会关闭实例。
因为该实例还管理着其他
PDB。但是对于用户来说,他所看到的,与关闭一台
独立数据库并无二致。
考虑另外一个例子。我们正连接到一个
PDB,并且我们没有自己的
UNDO
表空间,因为该表空间是
CDB
级别的(在
12.2
版本中,我们可以改变这一点,
但是到第
8
章才能看到相关内容)。让我们试着创建一个
UNDO
表空间:
这里并没有报错。但是
UNDO
表空间显然没有创建出来。毕竟,要创建一
个
100TB
的数据文件是不可能的。我们所提交的语句只是被忽略了。其想法是,
既然在一个数据库中提交的脚本可以创建一个
UNDO
表空间, 那么这样的语法
在一个
PDB
中显然也是应该被接受的。被接受的原因是,所有在非
CDB
中可
以做的事情,在
PDB
中必须也是可以进行的。但是它被忽略了,因为
UNDO
表空间是
CDB
级别的对象。
在多租户环境中,也会有一些新的命令可用,并且你所知道的所有命令也
都被
PDB
所接受。可以为一个
PDB
用户授予
DBA
角色,这样该用户就可以做
一个
DBA
能够做的所有事情。并且该
PDB
用户会被从其他
PDB
中隔离出来,
并将也将无法看到
CDB
级别的信息。
2. CDB$ROOT
你的
SYSTEM
表空间有多大?在数据库刚刚创建时,它差不就有几个
GB
那么大了。对于数据库创建,我们这里并不是指
CREATE DATABASE
语句,而
是指运行
catalog.sql
以及
catproc.sql(当然,在多租户环境中,我们就不这样称呼
它们了,我们称之为
catcdb.sql。实际运行的脚本还是一样)。一个空数据库的字
典表,也将会占用数
GB的空间,用来存储字典结构以及系统包,它们都是
Oracle
软件的一部分——ORACLE_HOME
下的二进制文件——但它们是以存储过程
和包的形式部署在数据库中的。如果在一台服务器上部署
50
个数据库,那么就有
50
个
SYSTEM
表空间并存储同样的内容(假设它们的版本和补丁号都一样)。如果
想对数百个或数千个数据库进行集成, 正如对
PDB
所做的那样, 你可能不想对每
一个数据库都存储同样的内容。可以将所有的公共数据只存储在一个容器中,
并让其他容器共享这些内容。这就是
CDB$ROOT:它是一个
CDB
中唯一的非
PDB
容器,用来存储
PDB
之间的所有公共信息。
基本上,
CDB$ROOT
将会存储所有的字典表、 字典视图、 系统包(以
dbms_
开头)以及系统用户(SYS、
SYSTEM
等)——并且不再存储其他内容。不要在
CDB$ROOT
中存储用户数据。如果需要,可以在所有的
PDB
中创建自己的用
户。关于公共用户,可以在第
6
章中了解更多信息。
也可将
CDB$ROOT
视为
ORACLE_HOME
的扩展。它是数据库软件的一
部分,并存储于数据库中。它与
ORACLE_HOME
的版本相关,只要版本相同,
那么所有
CDB
中的
CDB$ROOT
都是一样的。
12.2.0.1
版本中的
CDB$ROOT
与你的数据库基本也是一样的。
3. PDB$SEED
多租户数据库
CDB
的目的是创建多个
PDB。不仅如此,还应该能够根据
需要,简单快速地创建
PDB。这也是
DBaaS(DataBase as a Service,数据库即服
务)架构所关注的。如何通过
DBCA
来快速创建一个数据库?可以通过一个包
含所有文件的模板来创建数据库。如果能够克隆一个现成的空数据库,那么就
不再需要去重新创建所有的东西了(正如
catalog.sql
和
catproc.sql
所做的)。 这就
是
PDB$SEED: 它是一个空的
PDB, 可以对它进行克隆, 从而创建另外的
PDB。
不能对它进行修改,因为它是只读的,只能将它作为一个新
PDB
的源头。
一个
CDB
最少包含一个
CDB$ROOT
容器和一个
PDB$SEED
容器。不能
对它们进行修改,只能使用它们。只有在对
CDB
进行升级或打补丁时,它们
的结构才会发生变化。
1.2.3
多租户字典
多租户架构的目的之一,就是将系统元数据从应用程序元数据中分离出来。
系统元数据,
PDB
之间所有的公共信息,都存储在
CDB$ROOT
中,称为系统
对象。例如,包的定义,存储在字典表
SOURCE$中,我们可以通过查询
DBA_SOURCE
视图来获取这些内容。在一个非
CDB
中,该表则存储了系统包
和你自己创建的包——有的包由
SYS
拥有,有的则由应用程序方案拥有;就让
我们叫它
ERP
吧。在多租户环境中,
CDB$ROOT
只包含系统元数据,因此在
前面的例子中,这也就意味着这些都是
SYS
包。
在我们指向应用程序的
PDB
中,我们称其为
PDBERP,
SOURCE$中将会
只包含我们应用程序的包,也就是
ERP
的包。让我们看一个例子。我们使用
CDB$ROOT
并统计
SOURCE$中的行数。我们将其与
DBA_OBJECTS
进行关
联,从而显示出哪些是
Oracle
管理的对象(系统对象):
SOURCE$中所有的行都是
Oracle
管理的对象,也就是系统包。
现在我们在
PDB
中看一眼:
| 这里的结果就不是系统包了,而是应用程序创建的包。当然,在你的环境 |
|
| 中,可能查询结果会有所不同。但是这个例子,基本上已经显示出了多租户环 |
|
| 境下,字典信息是如何分离的:在非 CDB 中,元数据存储于同样的字典表中, |
|
| 但是现在存储到了不同的容器中,从而让 Oracle 元数据与应用程序元数据分离 |
|
| 开来。注意,这与分区不同,对于字典表来说,它们倒更像是不同的数据库。 |
|
| 1. 字典视图 |
|
| 你知道我们为什么查询 SOURCE$而不是 DBA_SOURCE,假设它们能够提 |
|
| 供同样的结果吗?检查如下内容: |
|
|
|
在
CDB$ROOT
中,这与上面查询得到的行数相同。但是在
PDB
中:
这里,我们看到有更多的行数。实际上,我们是从
CDB$ROOT
中看到的
这些行。这里有两个原因。首先,我们说存储在
CDB$ROOT
中的是公共信息,
因此在
PDB
中显然也能够看到这些信息。其次,我们说当一个用户连接到一个
PDB
时,该用户在一个独立的数据库中能看到什么,在一个
PDB
中就也应该
能看到什么。而在一个独立的数据库中,基于
DBA_SOURCE
的查询应该显示
所有的内容,包含系统的以及应用程序的。但是在查询
SOURCE$时则不是这
样。当然你也不希望这样。只有视图记录下了这些信息,并且你会期望去查询
这些视图。
PDB
中的字典视图,提供了
PDB
的信息,以及来自
CDB$ROOT
的信息。
它不是分区,也不是一个数据库链接。我们将在接下来的部分看看
Oracle
是如
何进行处理的。
当连接到
CDB$ROOT
时,
DBA_SOURCE
视图将会只显示容器中的信息。
但是新的以
CDB_开头的视图,则会显示所有容器中的内容,你将在本节后面
1.2.4
节的“5.
容器中的字典视图”部分看到这一点。
因此,从物理上来说,这些字典信息是分离的。每一个容器都存储各自用
户对象的元数据,根容器则存储公共部分——主要是系统元数据。从逻辑上来
说,从这些视图中,我们可以看到所有的信息,因为我们在非
CDB
中就可以
看到,
PDB
显然应该兼容这一点。
2.
元数据链接
Oracle
引入了一种新的方式,来将一个容器中的对象链接到其他容器:元
数据链接。每一个容器都拥有所有的字典对象(存储在
OBJ$中并且可以通过
DBA_OBJECTS
访问到),例如前面的例子中用到的系统包名称。但是更多的对
象定义信息(例如包的代码文本)并非存储在所有的容器中,而是只存储在
CDB$ROOT
中。在
OBJ$中,每一个容器都有一个标识,这可以通过
DBA_
OBJECTS
中的
SHARING
列得到。当需要获取某个对象的定义信息时,该标志
就会告诉
Oracle,这些信息需要切换到
CDB$ROOT
容器去获取。
如下是一些关于这些包中的某个包的信息,所有的容器都包含相同的定义
信息,查询
CDB$ROOT
的
DBA_OBJECTS:
如下信息则是从
PDB
中查询得到:
可以看到,这些对象都具有相同的名称和类型,并且都定义为
Oracle
管理的,
SHARING
列也都为
METADATA LINK。它们有不同的对象
ID。在对它们进行
链接时,只需要使用名称和内部标签。根据这些内容,我们就可以知道,这些
对象都是系统对象(Oracle
管理的),因此当我们在
PDB
中查询这些对象时,
Oracle
就会知道需要切换到根容器来获取它们的信息。这就是元数据链接的具
体处理行为。字典对象往往都比较大,因此只会存储在
CDB$ROOT
中。但是
它们可以通过字典视图,从而在任意位置都可以访问到。
这与元数据有关。对于应用程序而言,相关的元数据则会存储在对应的
PDB
中。
Oracle
管理的对象则存储在
CDB$ROOT
中。后者是静态信息:它们
只有在对数据库进行升级或打补丁时才会更新。可以看到,这样做的好处,一
是可以降低信息的重复程度,二是能够加快
PDB
升级的速度,因为
PDB
中只
是一些链接罢了。
图
1-3
显示了字典信息是如何分离的,当然也是对前面图
1-2
的简单扩展。
3.
数据链接(在版本
12.1中称为对象链接)
当然,在字典中不仅仅只有元数据。在
CDB
级别,多租户数据库也会存
储一些数据。这里是一个简单的例子。假设
CDB
需要维护一个容器列表,并
将其存储在系统表
CONTAINER$中然后可以通过字典视图
DBA_PDBS
进行访
问。这些数据可以更新,从而用来存储容器的状态信息。但是,这些数据虽然
只在
CDB
级别才有意义,不过所有的
PDB
都可以访问得到。下面我们就来看
看是如何共享这些信息的。
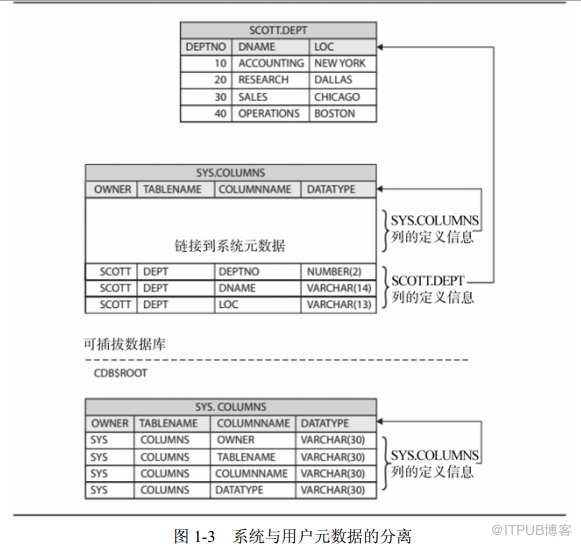
图
1-3
系统与用户元数据的分离
先查询
CDB$ROOT:
然后查询
PDB:
可以看到,访问
CONTAINER$的视图,实质上是一个数据链接。这就意味
着,当有会话来执行这些查询时,其实信息是从
CDB$ROOT
获取到的。实际
上,
CONTAINER$表在所有的容器中都存在,但是只有在根容器中是真正存储
数据的,其他都是空的。
1.2.4
使用容器
既然有了这么多的
PDB,那么如何使用它们?可以从识别它们开始。
1.
通过名称和
ID
来识别容器
一个集成的
CDB
中,可以包含多个容器,它们可以通过名称和数字,也
就是
CON_ID
来进行识别。在
12c
版本中,所有用来显示一个实例中包含哪些
对象的
V$视图,都额外添加了一列,用来显示
CON_ID,以便标记对象属于哪
一个容器。
CDB
本身就是一个容器,其容器
ID
为
CON_ID=0。被标记为
CON_ID=0
的对象,都是
CDB
级别的对象,并且不会关联到其他容器。
例如,如下是我们在根容器中查询
V$DATABASE
后得到的信息:
下面则是在
PDB
中执行查询:
如果在不同的容器中执行上述查询,结果可能也会有所不同。但是无论哪
种情况,所获取到的数据库信息,都只是
CBD
级别的。该视图中包含的信息
来自于控制文件,你将看到这些其实就是公共信息,因此
CON_ID
被设置为
。
如果是非
CDB,那么对于所有的对象而言,
CON_ID
都为
。但是如果是在一
个多租户架构中,那么大部分对象都属于特定容器。
任一
CDB
环境中,第一个容器都是根容器,名为
CDB$ROOT,并且
CON_ID=1。其他所有的容器都是
PDB。
任一
CDB
中的第一个
PDB,都是种子容器,名为
PDB$SEED。因为它是
CDB
中的第二个容器,所以
CON_ID=2。
CON_ID>2
的容器,就是用户
PDB。在版本
12.1
中,可以创建额外的
252
个
PDB。在版本
12.2
中,则为
4096
个
PDB。
2.
容器列表
字典视图
DBA_PDBS列出了所有的
PDB(所有的容器,除了根容器)及其状态:
对于
PDB
而言,当刚刚创建时,其状态为
NEW,并且在第一次将其以读/
写方式打开时,其状态调整为
NORMAL,因为在第一次打开
PDB
时,需要进
行一些相关操作。状态为
UNUSABLE
表明该
PDB
创建失败,并且唯一允许的
操作是将其删除。状态为
UNPLUGGED,则表明该
PDB
将会被传输到其他
CDB,而在源
CDB
上,唯一能做的操作,就是将该
PDB
删除。
在版本
12.1
中,可以看到
NEW
这样的状态,此外还有其他一些状态:NEED
UPGRADE,表明该
PDB
来源于其他版本的数据库;
CONVERTING,表明其
来自于一个非
CDB。当然,还有其他三种状态:
RELOCATING、
REFRESHING
以及
RELOCATED。我们将在第
9
章讨论这些内容。
如下信息是从数据库字典中查到的。我们可以通过实例来列出容器的信息,
这里显示了其打开的状态:
在非
CDB
中,
MOUNTED
状态表明当前控制文件已经被读取,但是数据
文件还没有被实例进程打开。这里查询到的结果与之颇为类似:一个处于关闭
状态的
PDB,其数据文件为未打开状态。
PDB
没有
NOMOUNT
状态,因为控
制文件是公用的。
要注意,无论是
SQL*Plus
还是
SQL Developer,都有一种快捷方式,可以
用来显示当前的
PDB。如果正处于根容器中,还可以显示所有的
PDB:
3.
通过
CON_UID
和
DBID
来识别容器
可以看到,除了容器的名称,还可以通过
ID
或
CDB
中的
CON_ID
来识别
容器。但是,当移动
PDB
时,其
CON_ID
将会发生变化。基于这个原因,还需要
一个唯一的标识符
CON_UID。该号码在
PDB
发生移动时也依然可以用来标识
PDB。
CDB$ROOT
是一个容器但不是
PDB,并且它也不会移动,因此其
CON_UID
为
1。
基于数据库的兼容性考虑,每个容器都有一个
DBID。
CDB
的
DBID
就是
CDB$ROOT,
PDB
的
DBID
则为
CON_UID。
另外,每一个容器都还有一个
GUID:一个包含
16
个字节的
RAW
值。它
在
PDB
创建时生成,并且永远都不会再改变。当使用
OMF(Oracle Managed
Files,
Oracle
管理的文件)时,
GUID
被用于目录结构,并作为
PDB
的唯一标识
符。
所有这些标识符都存储于
V$CONTAINER
中,当然也可以使用这些函数来获
取一个容器的
ID:
CON_NAME_TO_ID、
CON_DBID_TO_ID、
CON_UID_TO_ID
以及
CON_GUID_TO_ID。如果容器不存在,就返回
null
值,如下是一些例子:
4.
连接到容器
前面我们对多租户的分析, 是将其作为突破方案集成限制的一种方法来进行
讨论的。那么问题来了,如何在多个方案之间进行切换?而不是使用方案用户进
行直接连接?这里,可以使用
ALTER SESSION SET CURRENT_SCHEMA。
当然,也可以直接连接到一个
PDB,但是这部分内容我们将在第
5
章进行
讨论。这些内容与服务有关,并且这是从用户或应用程序连接到
PDB
的正确做
法。但是现在,你已经连接到了
CDB,可以使用
ALTER SESSION SET
CONTAINER
命令,从而简单地将会话切换到一个新的容器。
现在,我们已经连接到了
CDB$ROOT:
我们来改变一下当前容器:
现在我们就在
PDB
中了:
事务 如果在一个容器中开启了一个事务,那么将无法在其他容器中开启
另外的事务。
可以离开当前事务,并切换容器:
但是现在无法执行
DML
语句,因为它需要一个新的事务:
首先,需要回到原来的容器并结束事务:
然后可以在另外的容器中开启一个新的事务:
游标 如果在一个容器中打开了一个游标,将无法在另一个容器中对该游
标进行获取操作。需要回到游标所在的容器并进行获取:
基本上,从一个容器切换到另外一个容器往往是很容易的。但是在不同的
容器中进行的操作,则是相互隔离的,并且以前容器中的状态是无法共享的。
例如,我们连接到
PDB1,设置
serveroutput
为
on,然后使用
dbms_output
命令:
dbms_output
产生了输出,可以看到
USERENV
显示了当前的容器名称。
现在我们切换到
PDB2:
这里就没有任何输出结果了。
serveroutput
只是在
PDB1
中进行了设置,我
们需要在
PDB2
中也进行设置:
现在我们回到
PDB1:
这里就不需要再次设置
serveroutput
了。当我们切换回来时,我们重新获取
了原来
PDB
中的状态。
使用
JDBC
或
OCI
我们的例子是在
SQL*Plus
中运行的,但是其他客户
端就不能这么做了。当使用一个在根容器中进行定义的用户(公共用户),并且
该用户也被授予
PDB
的
SET CONTAINER
系统权限时,就可以切换到这个
PDB。可以使用
JDBC(Java DataBase Connectivity )或
OCI(Oracle Call Interface)
来完成这个操作。例如,可以在应用服务器上配置一个连接池,这样在拿到连
接时,就可以将连接切换到所需的容器。当为数据库多租户创建公共应用服务
器时,这种方法是值得考虑的。
注意:
12.2
PDB
12.2
ORA-24964:ALTER SESSION SET CONTAINER
设置容器触发器 基于某些理由,如果想在一个会话进行容器切换时执行某
些动作,例如设置不同的优化器参数,那么可以创建
BEFORE SET CONTAINER
和
AFTER SET CONTAINER
触发器。
如下是这些触发器的工作机制:
●
在
PDB1
中创建
BEFORE SET CONTAINER
触发器, 当处于
PDB1
中,
然后执行
ALTER SESSION SET CONTAINER
时就会触发。如果触发
器读取到了容器的名称,那就是
PDB1。
●
在
PDB2
中创建
AFTER SET CONTAINER
触发器,当执行
ALTER
SESSION SET CONTAINER=PDB2
时就会触发。
这就意味着,如果在
PDB1
和
PDB2
中分别创建
before
和
after
触发器,那
么当从
PDB1
切换到
PDB2
时,这两个触发器都会分别触发。
这是
PDB
中两种不同的工作方式。也可以通过服务来连接到容器,我们将
在第
5
章讨论这些内容。此时,在会话开始时,就可以使用
AFTER LOGON ON
PLUGGABLE DATABASE
触发器执行某些代码。或者,也可以使用
SET
CONTAINER,然后使用
AFTER SET CONTAINER ON PLUGGABLE DATBASE
触发器。当一个用户在
PDB
中工作时,如果想对这些会话进行某些确定的设置,
那么前面说的这两项操作就都需要进行定义。要注意这里的
PLUGGABLE
单词
并不是必需的,因为这里的语法与数据库的行为是兼容的。
5.
容器中的字典视图
PDB中包含了所有你想从一个数据库中看到的内容。这就意味着对一个PDB
中的字典视图进行查询,其结果应该与对一个数据库进行查询所返回的结果一
致。你同样也拥有
DBA_/ALL_/USER_视图,用来获取
PDB
中对象的元数据。
那些对象,要么有权限去访问,要么是你自己创建的。事实是,系统对象存储在
什么地方是透明的:可以在
DBA_OBJECTS
中看到系统对象,在
DBA_TABLES
中看到系统表,以及在
V$视图中看到实例信息。但是你所看到的行,都跟你当
前所在的
PDB
相关。
当处于
CDB$ROOT
中时,就可以看到
CDB_视图。这些视图就像是所有
打开容器中
DBA_视图的
UNION ALL
结果。 这是一个
CDB
数据库管理员可以
使用的方法,从而查看所有的对象。对于
CDB$ROOT
的用户,
V$视图将会显
示所有容器内的信息。
最后,你可能想知道,你是在非
CDB
环境中还是在多租户环境中。
V$DATABASE
中的
CDB
列为你提供了答案:
1.3
什么是
CDB
级别的集成
对于集成而言,实现共享资源的公共性是其主要目标。在实例与字典之上,
很多数据库结构都是在
CDB
层面进行管理的。我们这里并不讨论数据文件,
因为它们被指定到每一个容器上。并且它们之间唯一的共同之处就是必须拥有
相同的字符集(除了在将一个容器从另外一个
CDB
中传输过来时, 当然这一点我
们要到第
9
章才进行讨论)。在一个容器数据库中,其他类型的文件都是公共的。
SPFILE
对于所有容器而言,数据库实例是公用的,
SPFILE持有该实例的相关参
数,并为整个
CDB
进行属性设置。
SPFILE
包含的设置,无法存储在数据库或控
制文件中,因为这些设置必须在数据库处于
mount
状态之前就可用才行。
有些参数可以在
PDB
级别进行设置(在
V$PARAMETER
中,这些参数的
ISPDB_MODIFIABLE
列为
TRUE)。对这类参数的修改当然也可以持久保存下
来。但是在修改这些参数时,即便在语法上设置
SCOPE=SPFILE,这些
PDB
级别的参数实际也会存储在
CDB
的字典表(即
PDB_SPFILE$)中。它们不会存
储在自身的
PDB
中,因为这些参数必须在打开
PDB
之前就能够访问。在稍后
我们将会看到,当移动一个
PDB(插入/拔出)时,这些参数将会被抽取出来存放
到一个
XML
文件中,并随着
PDB
的数据文件一起被传输。
控制文件
控制文件与数据库中的所有其他结构都有关系。例如,控制文件是唯一真
正存储数据文件名称的地方,在字典表中为
FILE_ID
列,只是对具体位置的引
用而已。在多租户环境中,控制文件位于
CDB
级别,并持有所有
PDB
的数据
文件信息。可以在第
9
章中看到这些与
PDB
相关的内容,即当一个
PDB
被拔
出/插入时,所有与该
PDB
相关的数据文件信息,也会被从控制文件中导出,
然后存储到一个
XML
文件中。
注意:
(control files)
当讨论数据文件时,有一个初始化参数可以用来控制一个实例可以打开的
最大文件数量。就是
DB_FILES,其默认值为
200。要注意,如果想创建数百
个
PDB,那么很快就会达到这一限制。到时候就无法再创建新的表空间或
PDB
了,除非重启实例。在多租户环境中,重启实例意味着会引起很多应用的停机
操作。因此应该避免这一点。故而,当打算在容器中管理多个
PDB
时,不要忘
记对
DB_FILES
参数进行正确设置。
UNDO
在版本
12.1
中,即第一个带有多租户架构的
Oracle
数据库版本中,
UNDO
表空间是公共的,并且处于
CDB
级别。但是在版本
12.2
中,我们有了新的选
项,可以在本地
UNDO
模式下运行
CDB。如果
LOCAL UNDO
被设置为
on,
则每一个
PDB
都拥有自身的
UNDO
表空间, 并且当所有会话往
PDB
的数据块
中写数据时,其
UNDO
信息都会被存储到该
PDB
本地的
UNDO
表空间中。只
有在
CDB$ROOT
中执行的修改操作, 才会将
UNDO
信息记录到
root
的
UNDO
表空间中。
简单点说,如果可能的话,将
CDB
运行在本地
UNDO
模式下比较好。UNDO
中包含了应用数据,并且如果我们将这些数据存放到公共的
UNDO
文件中的
话,我们就无法实现
PDB
的隔离了。一个需要使用本地
UNDO
模式的原因,
就是当我们打算进行
PDB
的快速闪回或是基于时间点的恢复时。我们将在第
8
章解释这些内容。
临时表空间
临时表空间可以在
CDB
或
PDB
级别创建。如果某个
PDB
中的用户在运行
会话时没有指定临时表空间,并且该
PDB
也没有默认的临时表空间,该会话将
会使用
CDB
的临时表空间。但这不是推荐的做法。我们可以为
root
的临时表
空间设置限额(MAX_SHARED_TEMP_SIZE),从而控制
PDB
对它的使用。
当需要分配工作区,从而完成对对象链接视图的递归查询时,
CDB$ROOT
的临时表空间一般都由连接到根容器的会话使用, 或者由来自一个
PDB
的会话
使用。
当将一个临时表空间设置为默认的临时表空间时,如果是你创建了该
PDB,那么你也可以指定其他的临时表空间为默认的临时表空间。但是在此之
后,你就无法将
CBD
的临时表空间设置为该
PDB
的默认临时表空间了。
重做日志
重做日志是用来保护实例的,因此,它们也是公共的。重做日志的主要用
途,是对
buffer cache
中所有的修改进行记录,并确保这些所有已提交事务的更
改能够持久保存下去。
多租户环境下的
REDO
数据流与之前版本中的类似,除了在每一条
REDO
记录中都要添加额外的信息用来标记容器之外。并且对于恢复操作而言,
REDO
数据的格式也极为关键,基于此,
Oracle
很少去改变这些东西。
使用统一的
REDO
线程来处理所有的
PDB,对于
DBA
管理
CDB
而言,
也是颇有益处的。在非
CDB
环境中,当打算准备一个新的数据库时,将会花
费很多时间和精力去设置恢复区大小、建立备份,以及创建并配置
Data Guard
物理备库,如果使用了的话。但是在多租户环境下,类似的工作,只需要做一
次就够了,也就是
CDB。因为这就是与数据库可用性相关的功能汇聚的地方:你
的备份、
Data Guard
以及
RAC
配置。可以简单地创建一个新的
PDB,并从这个
已经配置好可用性的环境中受益:它会随着
CDB
进行自动备份,自动在物理
备库中创建(当然这里需要使用
Active Data Guard), 以及能够自动被所有
RAC
实例访问。再强调一次,这就是因为用来实现数据库可用性的关键架构——
REDO
数据流,都是在
CDB
级别进行运作的。
但是,如果只使用一个
REDO
数据流,有时候也会导致性能问题。如果曾
经遇到过与日志写相关的性能问题,例如基于“log file sync”事件的长等待,
那么就可以想象出,当
LGWR
进程需要进行所有
PDB
的
REDO
写操作时,会
发生什么事情。其结果就是,如果
LGWR
无法跟上
REDO
的生成速度,那么
当用户执行提交操作时,就不得不进入等待状态。
因此,基于
LGWR
的可扩展性考虑,
Oracle
在
12c
版本中引入了多线程
LGWR
结构。这里,
LGWR
是一个协调进程, 然后有多个从属进程(LG00、
LG01
等)与之相关联。这样,实例的
REDO
数据流就可以采用并行方式进行数据写
操作。当然,
RAC
仍然是另一种实现
REDO
并行处理的方式。需要牢记在脑
海中的是,在多租户环境中,调整
LGWR
以及
REDO
写的数量是至关重要的。
当进行集成时,需要对存放
REDO
日志的磁盘性能加以特别关注。
数据文件
存储在表空间数据块中的数据文件,属于各自的容器,但它们也同样为
CDB
所管理。对于
CDB
而言,这些数据文件都有唯一的标识符,也就是
FILE_ID:
relative file number,中文为相对文件编号,是随着可传输表空间被引入进
来的。因此在
12c
以前的版本中,这个特性已经存在相当一段时间了。多租户
环境下,在
PDB
中,数据文件是通过表空间编号和该文件在表空间中的相对文
件编号(RELATIVE_FNO)进行标识的。此外,当进行文件的移动、克隆或插入
到
PDB
中时,文件编号的修改都不是必需的。只有绝对文件编号(FILE_ID)会
被重新编号,从而确保其在
CDB
中的唯一性——但是在控制文件和数据文件
头中,这个重新编号的动作,是极其快速的。
CDB
级别的数据与元数据
至此,我们已经解释了与系统对象相关的字典,它们存储在
CDB$ROOT
的
SYSTEM
和
SYSAUX
表空间中。它们是公共的,并且可以被
PDB
访问。但
是除了这些基础的数据库对象(由
catalog.sql
和
catproc.sql
创建)外, 还有更多的
公共信息也都存储在根容器中。
1. APEX
默认情况下,一旦安装了
APEX(在版本
12.2
中,可以选择该组件),它就
处于
CDB
级别。
APEX
与系统字典类似,它们都用来存储元数据,并且不需要
安装在
PDB$SEED
或其他
PDB
中。但是,这种方式有一个非常大的缺点:在
你的
CDB
中,只有一个
APEX
版本。并且当想在该
CDB
中插入一个运行
APEX
5.0
版本的非
CDB
时,将会遇到问题。例如,在
Oracle
云服务中,当前的
CDB
上安装的是
APEX 4.2
版本。
注意:
Mike Dietrich
blogs.oracle.
com/UPGRADE/entry/apex_in_pdb_dose_not
APEX 5.0
Oracle
APEX
PDB
Oracle Application
Express(APEX)
2. AWR
AWR(Automatic Workload Repository,自动工作量资料档案库)从实例的动
态视图中收集大量的信息(统计信息、等待事件等)。在多租户环境下,这些是
在
CDB
级别完成的。只有一个
job
用来收集所有容器的所有统计信息,并存储
在
CDB$ROOT
中。这就是对象链接视图——AWR
视图(以
DBA_HIST
开头)
主要的应用案例。它们可以由每一个
PDB
进行查询,但是读取的数据实际上是
存储在根容器中的。
因此,这里有两个重要的结论。其一,如果移动了一个
PDB,那么
AWR
历史数据将不会随之移动;相反,它将仍然保留在原始的
CDB
中。可以使用
原来的数据库读取这些视图,或者在他处将其导出。但是存储在
AWR
中的
CON_ID,应该是生成快照时的容器
ID,因此需要你去检查
CON_DBID,从而
确认某一指定的
PDB。在每一个以
DBA_HIST
开头的视图中,实际上有三个
不同的标识符:
● DBID是
CDB的
DBID,这与非
CDB环境中的一样。该标识符与
SNAP_ID
和
INSTANCE_NUMBER
一起,可以用来确定唯一的快照。
● CON_ID
是容器
ID,是生成快照时所查询的
V$视图所在的容器
ID。
视图中有些行可能不与任意容器相关联,此时
CON_ID=0。其他行则
记录了某个容器对象的统计信息,因此在生成快照时,就记录下了相
应的
CON_ID。
● CON_DBID
用来唯一标识一个
PDB,它和
DBID
用来唯一标识一个数
据库一样。
对于在
CDB
级别收集统计信息的
AWR
而言,第二个结论是:当在
PDB
级别运行
AWR
报告时,它只会过滤出与你的容器相关的统计信息,并且与查
询
PDB
中
V$视图得到的信息一样。但是你仍然需要知道,在同一份
AWR
报
告中,还是可以看到一些在
CDB
级别收集的统计信息(这些行的
CON_ID=0)。
这就意味着,例如,可以在
AWR
的实例统计信息部分,看到实例所完成的逻
辑读的数量,但是在展示具体的细节(在
SQL
部分或段部分)时,只会显示与你
的
PDB
相关的信息。让我们看一个例子。
在阅读
AWR
报告的细节之前,我们通常会检查一下大部分被捕获的
SQL
语句,因为如果我们不打算去研究
SQL
语句的细节的话,这样的动作就没有必
要继续了。如下是一份
AWR
报告中的
SQL ordered by Gets
部分:
这里显示捕获了
89%的
SQL
语句,并且我们知道,当我们想去研究高逻辑
读问题时,我们有了所需的细节。如果该比例比较低,那么通常意味着我们生
成的报告,覆盖了一个太大的时间窗口。因此大部分
SQL
语句在
end snapshot
之前都已经由于超时而被移出共享池了。但是,当在一个
PDB
上运行
AWR
报
告时,也可以看到另外一个原因:
| 这里看不到任何区别,除了只捕获了 21%的 SQL 语句。需要检查 AWR 报 |
|
| 告的头部,来看看它是否只覆盖了一个 PDB。事实上我们有两个 PDB 在此时 |
|
| 处于活动状态,如下是另外一个 PDB: |
|
|
从一个
PDB
中,没有办法确认该
PDB
所有的
SQL
语句是否都已被捕获。
对于该 PDB 而言,没有类似总的逻辑读这样的统计信息。 注意: 12.1 PDB V$CON_ SYSSTAT ARW 12.2 DBA_HIST_CON_SYSSTAT (DBA_HIST_CON_SYS_TIME_MODEL) (DBA_HIST_CON_ SYSTEM_ EVENT) 12.2 AWR statspack 如果没有诊断包,那就无法使用 AWR,可以安装 statspack。通 过查阅相关文档(spdoc.txt),可以知道 statspack 只能在 PDB 级别进行安装。当 然,我们认为在 CDB 级别安装也是有用处的,因为你会想去分析一下 CDB$ROOT 的活动情况。每一个想要收集快照的 PDB 都将存储其自身的统计 信息。因为现在统计信息是在 PDB 级别被收集的,所以相关的行为就与 AWR 不同。我们在与前面例子中相同的时间点获取 statspack 的快照,此时,从 spreport.sql 中读到的信息如下:当报告运行在 CDB$ROOT 上时,会话逻辑读 的数值为 24 956 570;在其中一个 PDB 上运行时,数值为 5 709 168(22%);在 另外一个 PDB 上数值为 17 138 586(68%)。当在根容器上运行时, statspack 收 集与该 CDB 相关的统计信息,而在 PDB 上运行时,则收集该容器的统计信息。 1.4 本章小结 在前面长长的介绍中,我们已经解释了在 2013 年, Oracle 为何要在版本 12c 中引入多租户特性。我们已经看到了不同的集成选项,当然你也可能认为 并不需要在多租户环境下运行应用。但是,这种新的架构将来会成为 Oracle 唯 一支持的数据库架构,原有的非 CDB 架构正在被抛弃。因此,即便现在不想 在一个实例上运行多个 PDB,也得运行我们称之为“单租户”的数据库(我们 将在第 3 章讨论这一点),并且也不得不管理容器数据库。 除了集成,新的架构也将应用数据与元数据从系统字典中分离开来,从而 为数据移动和位置透明提供更强大的敏捷性。这些我们将在第 9 章进行探讨。 下一章,将从创建一个集成数据库开始。 购买地址: https://item.jd.com/12393662.html
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。 相关阅读 |