您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“MySQL8.0 redo log优化概述和线程模型介绍”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
1 MySQL redo_log简要回顾
在MySQL 5.7中写性能将受限于redo_log的同步操作,特别是在多cpu,存储设备很快的情况下,MySQL 5.7 redo_log的设计无法有效利用存储设备性能,因此需要重新设计。MySQL 5.7瓶颈在于mtr将在把log写到log buffer时加log_sys_t::mutex锁,之后该mtr把dirty page加入flush list中时,为了保证全局有序,会加 log_sys_t::flush_order_mutex锁。如果其他用户线程的mtr要把log写到log buffer,需要等待log_sys_t::mutex,同时为了保证全局lsn有序,其他用户线程的mtr即使要往其他flush list中加数据也需要等待log_sys_t::flush_order_mutex锁,这两把锁是MySQL 5.7中redo_log的主要性能瓶颈。
2 redo log优化概述
目前,redo log是无锁全异步设计,其流程架构图如下所示:
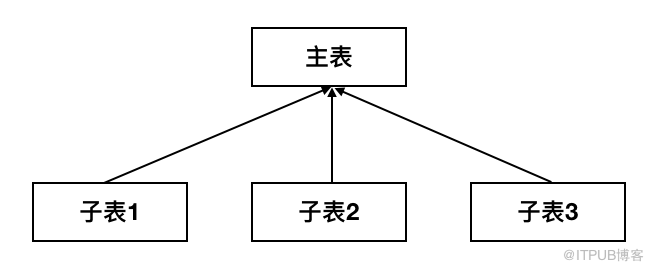
如上图所示,redo log的异步工作线程为4个,另2个异步辅助线程:分别是:log_writer, log_flusher, log_flush_notifier, log_write_notifier, log_checkpointer,log_close,log_flush_notifier /log_write_notifier为图中log notifier线程组,辅助线程为log_checkpointer, log_closer。
log_writer:负责将日志从log buffer写入磁盘,并推进write_lsn(原子数据)
log_flusher:负责fsync,并推进flushed_to_disk_lsn(原子数据)
log_write_notifier:监听write_lsn,唤醒等待log落盘的用户线程(根据flush_log_at_trx_commit设置,用户commit操作会等待write_lsn推进)
log_flush_notifier:监听flushed_to_disk_lsn,唤醒等待log fsync的用户线程。log_closer:1、在正常退出时清理所有redo_log相关lsn\log buffer相关数据结构;2、定期清理recent_closer的过老数据(recent_closer所用之后详述)
log_checkpointer:定期做checkpoint检查,根据flush list刷dirty page情况推进check point,释放log buffer等
1 线程同步数据结构
异步线程之间通过2种数据结构进行数据同步:原子读写(atomic )和Link_buf。原子读写是c++11针对多核cpu的一个新特性,在不加锁的情况下,对一个64位数据的原子读写。
Link_buf是MySQL新实现的数据结构,逻辑上是循环数组,数组下标表示start lsn,数据内容是lsn长度,数据类型为原子类型,如果数据内容(lsn 长度)为0表示这个slot为空 。每个通过合理的std::atomic_thread_fence(std::memory_order_release) / std::atomic_thread_fence(std::memory_order_acquire)操作,保证对里面不同slot的lsn读写的无锁并发。
3 mtr流程
3.1 流程
为了解决多个用户线程的mtr对redo log的争抢,MySQL引入了Link_buf的两个实例:recent_write / recent_close. 这两个实例的数据类型是上文介绍的Link_buf,不同mtr线程和log_writer线程可以无锁对recent_write / recent_close不同slot进行读写,recent_write / recent_close链表长度固定,由innodb_log_recent_closed_size 和innodb_log_recent_written_size制定。mtr的流程如下所示:
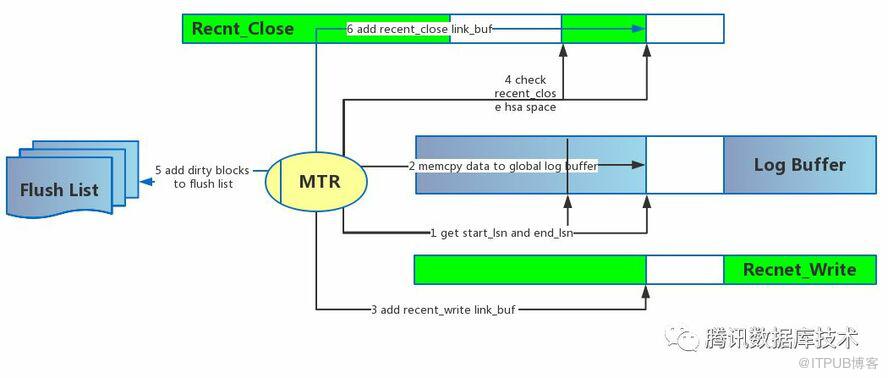
mtr通过sn和log_len获得写入的
start_lsn/end_lsn,
log_buffer_reserve(*log_sys, len);
将mtr的每个block都memcpy到log_buffer
推进recent_write的lsn位置到end_lsn
m_impl->m_log.for_each_block(write_log);
查看recent_close是否有空间,如果recent_close由于最早lsn对应的slot为空(表示该slot等待数据填充),而没有空间存储目前mtr对应的lsn,那么,当前mtr需要等待,直到recent_close最早的slot推进
log_wait_for_space_in_log_recent_closed(*log_sys, handle.start_lsn);
将dirty block添加到flush list
add_dirty_blocks_to_flush_list(handle.start_lsn, handle.end_lsn);
将当前lsn写入到recent_close
log_buffer_close(*log_sys, handle);
3.2 分析
各用户线程的mtr之间对log buffer、flush list的争抢冲突,通过recent_write / recent_close的读写而化解。
1、多个mtr根据步骤1中分配的lsn,可以并发的写入log_buffer而不产生冲突。但由于并发写入,获得较小lsn的mtr(较早申请lsn的mtr)不一定可以较早的进行memcpy,因此在某些时间点log_buffer会出现空洞(hole)。对于空洞的解决后面详述。
2、各mtr作为生产者将数据写入log_buffer, log_writer作为消费者将数据将数据取出,log_writer对数据log_buffer读取位置的获取通过recent_write获得,由于recent_write的无锁设计,mtr与log_writer之间也不会有上锁等待过程。
log_writer必须保证连续日志写入,但在1中分析,并发mtr或导致log_buffer空洞。因此recent_write提供方法advance_tail_until,该方法使得推进数组到第一个slot存储值为0的地方,该slot的下标对应lsn就是第一个空洞出现的位置。log_writer将write_lsn(上次写盘位置)到该slot对应的lsn之间的日志都从log_buffer写入磁盘。这套机制保证log_writer连续日志写入,取代MySQL 5.7中log_sys_t::mutex锁。
3、由于多个mtr并发写入,加入各flush list中的数据不在全局有序仅仅每个flush局部有序,因此需要确定一个lsn可以保证该lsn之前的所有dirty page都flush结束。针对这个限制,各mtr线程之间通过recent_close同步。由于recent_close长度固定,如果recent_close中最小的lsn与当前申请的lsn间距大于len(recent_close),则需要等待,recent_close最小lsn的推进有log_closer进行(后面详述)。因此,可以保证最大可能乱序长度为len(recent_close),一旦block进入flush list其对应的lsn减去len(recent_close)位置的lsn一定已经刷盘,可以在该点进行checkpoint。这套机制保证可以找到一个较新lsn(较大lsn),同时保证checkpoint点的新鲜程度,此机制用来取代MySQL 5.7中log_sys_t::flush_order_mutex锁。
4 redo log线程模型
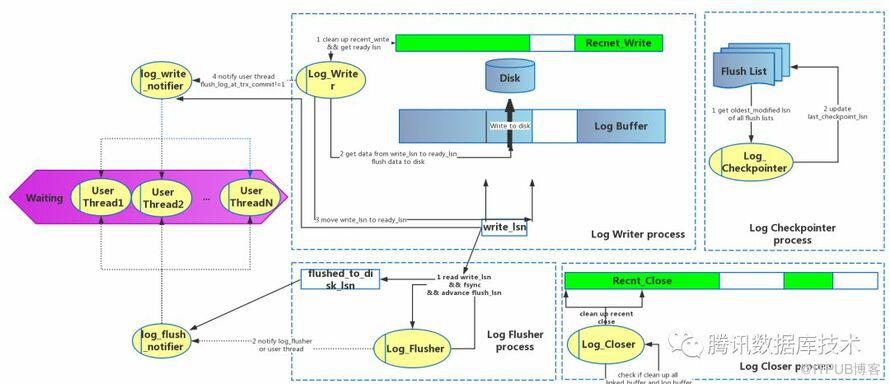
redo log线程模型如下图所示:
4.1 log_writer
log_writer负责将数据从log_buffer刷入disk,流程如下:
推进recent_write的tail至最大的连续lsn,并获取lsn的值(ready_lsn)
/* Advance lsn up to which data is ready in log buffer. */
(void)log_advance_ready_for_write_lsn(log);
ready_lsn = log_buffer_ready_for_write_lsn(log);
数据落盘,将write_lsn至ready_lsn之间的日志从log_buffer刷入FS cache中
write_blocks(log, write_buf, write_size, real_offset);
推进write_lsn,将write_lsn推进到ready_lsn
const lsn_t new_write_lsn = start_lsn + lsn_advance;
ut_a(new_write_lsn > log.write_lsn.load());
log.write_lsn.store(new_write_lsn);
log_writer整个流程仅通过recent_write同步log_buffer的连续日志位置,采取spin lock + pthread_cond_timedwait方式轮询recent_write。之前MySQL(5.7)的设计写盘操作是mtr中同步进行的,写策略比较单一,mtr写入长度(对于文件系统过大或者过小)不合适也必须进行写入,如果连续写入小数据,会造成严重的IO浪费。修改后的写入策略可以进一步优化,写入块大小、需不需要做batch都可以在log_writer中优化。
4.2 log_flusher
log_flusher负责将数据fsync到磁盘,推进flush_up_to_lsn。log_flusher与log_writer之间仅通过write_lsn同步刷盘位置,两个线程按照各自速度进行刷盘与fsnyc,他们之间的刷盘数据同步在OS/FS层进行,没有用户态的锁。
4.3 log_notifier
log_notifier包括log_write_notifier和log_flush_notifier,这两个线程定期轮询(为了加速也会被唤醒)各自关心的lsn位置:log_write_notifier关心write_lsn,log_flush_notifier关心flush_up_to_lsn。并将根据最新的lsn值唤醒等待的用户线程。用户线程commit等操作时会等在log_write_up_to函数上,当flush_up_to_lsn/write_lsn推进到等待位置时,log_write_up_to返回。
4.4 log_closer
log_closer作用有两个:
定期推进recent_close,清除recent_close中已经放入flush list的连续lsn片段,保证mtr不会因为第4步recent_close没空间而持续等待;
当数据库正常退出时,做收尾工作,将redo_log中的日志放到flush list中。
4.5 新增参数
与innodb_log_writer_spin_delay/innodb_log_writer_timeout作用相同,closer线程对应inno_log_closer_spin_delay/innodb_log_closer_timeout两个参数调节轮询速度。
4.6 log_checkpointer
log_checkpointer监控所有flush list,选择所有flush lists中刷盘的最小(最老)的lsn,将此lsn与flushed_to_disk_lsn等进行比较之后,设置新的last_checkpoint_lsn。这样做节省在主进程中进行checkpoint,将原来在主进程7秒做一次checkpoint改变成在log_checkpointer1秒做一次,一定程度节省数据库崩溃恢复的时间。
4.7 参数
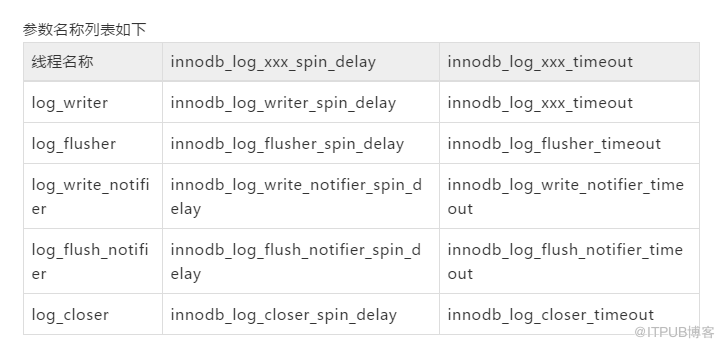
1. innodb_log_xxx_spin_delay && innodb_log_xxx_timeout
对于除log_checkpointer以外的log线程,每个线程都设置了自己的轮询参数:innodb_log_xxx_spin_delay和innodb_log_xxx_timeout
控制log线程轮询频率的函数为:
template <typename Condition>
inline static Wait_stats os_event_wait_for(os_event_t &event,
uint64_t spins_limit,
uint64_t timeout,
Condition condition = {})
log线程先等待innodb_log_xxx_spin_delay(spins_limit参数)个cpu pause指令,如果事件没有到来(condition函数返回false),开始等待特定信号量event,睡眠k个innodb_log_xxx_timeout(timeout参数)us,k随着连续等待次数的增加按照2的指数上升,总体睡眠时间以100ms为上限。
参数名称列表如下
2. innodb_log_spin_cpu_abs_lwm && innodb_log_spin_cpu_pct_hwm
用innodb_log_spin_cpu_abs_lwm和innodb_log_spin_cpu_pct_hwm进行两个参数控制os_event_wait_for中自旋锁的使用。innodb_log_spin_cpu_abs_lwm表示使用自旋锁的下门限,cpu低于这个门限,表示系统空闲,不需要使用自旋锁,cpu高于innodb_log_spin_cpu_pct_hwm表示系统特别繁忙,也不许使用自旋锁。innodb_log_spin_cpu_abs_lwm表示一个cpu的使用率,比如40core cpu,innodb_log_spin_cpu_abs_lwm为80,在MySQLd上cpu总使用率小于80%,不进行自旋。innodb_log_spin_cpu_pct_hwm表示所有cpu的总使用率,比如40core cpu,innodb_log_spin_cpu_pct_hwm为50,在cpu使用率大于2000%时,不进行自旋。
5 结语
redo_log的优化将之前锁冲突化解,用户线程的“等锁-写”机制转化为“写缓冲-查看写盘”机制。用户线程不进行刷盘操作,由后台线程统一刷盘,用户线程在写缓冲后就可以做其他操作,达到日志写盘和mtr做其他事情的并行,提升效率。
“MySQL8.0 redo log优化概述和线程模型介绍”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。