您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
【恩墨学院】深入解析:一主多备DG环境,failover的实现过程详解
作者介绍
现任云和恩墨数据库技术顾问,擅长Oracle数据库的安装配置、故障诊断、性能诊断、性能优化、备份容灾解决方案的设计与实施。
个人技术博客:https://www.cnblogs.com/jyzhao
在DG中,switchover和failover是两个重要的概念,也是DG实现的核心。根据不同的DG配置,switchover和failover也是有差异的。当主库被crash之后,如何进行DG foilover的操作?
本文是针对在DG灾备环境进行failover操作以及后续恢复的报告。
数据库版本:Oracle 11.2.0.4
Site A:主库 db_unique_name=jyzhao
Site B:备库(实时应用)db_unique_name=mynas
Site C:备库(延迟1小时应用)db_unique_name=jyzhao_s
A库 => Site A:主库
B库 => Site B:备库(实时应用)
C库 => Site C:备库(延迟1小时应用)
当A库crash后,在B库进行failover将B切换为新的主库,确认failover之后,A库和C库应该如何处理才可以成为新的备库继续使用?是否需要重建?重建的话,是否需要重新备份来恢复,以前的备份是否可以用来创建备库?
问题
验证过程
1、A库异常关闭
A库:
SQL>shutdown abort
2、B库进行failover切换为新主库
failover 标准步骤如下:
#取消DG应用
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
#重启下数据库(建议)
shutdown immediate;
startup
#操作不可逆,确定实际情况需要failover
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE FINISH force;
SELECT OPEN_MODE, DATABASE_ROLE, SWITCHOVER_STATUS, FORCE_LOGGING, DATAGUARD_BROKER, GUARD_STATUS FROM V$DATABASE;
#尝试常规切换为主库
ALTER DATABASE COMMIT TO SWITCHOVER TO PRIMARY WITH SESSION SHUTDOWN;
如果这一步的常规切换失败,提示需要介质恢复,那么:
1)恢复备库 recover standby database until cancel;
2)激活备库 alterdatabaseactivatestandbydatabase;
#最后重新启动数据库
shutdownimmediate;
startup
查看此时B库的信息:
SQL>selectname, database_role, open_mode fromgv$database;
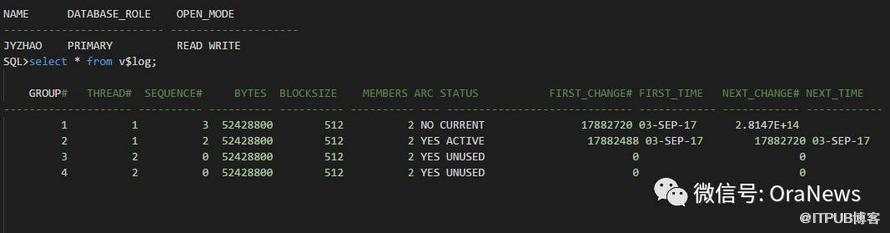
可以看到,目前B库已成为新的主库,redo日志的sequence重新开始。
3、要求C库成为新主库的备库
现在要求C库成为新主库的备库。是否需要重建C库呢?答案是不需要。下面具体来看下验证过程。
C库的alert日志:
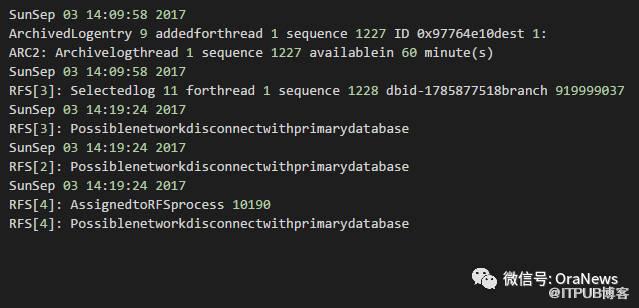
可以看到,在A库crash之后,C库收到网络无法连接到A库的告警,说明C库目前没有新的操作。
接下来想要C库成为B库(新主库)的备库,就需要尝试在B库上配置DG参数,使得B库的归档可以传输到C库。

同时在B库的tnsnames.ora文件中增加到C库的连接:
#StandbySingle Instance
JYZHAO_S=
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.111)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = jyzhao_s)) )
在B库设置完成后,观察B库的告警:
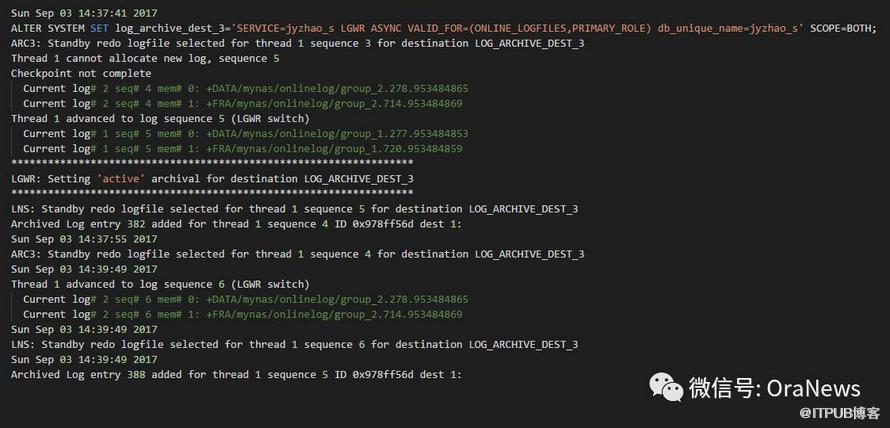
然后返回C库操作,将C库开启实时日志应用:
SQL>alter database recover managed standby database cancel;
Databasealtered.
SQL>alter database recover managed standby database using current logfile disconnect from session;
Databasealtered.
此时再观察C库的告警日志:
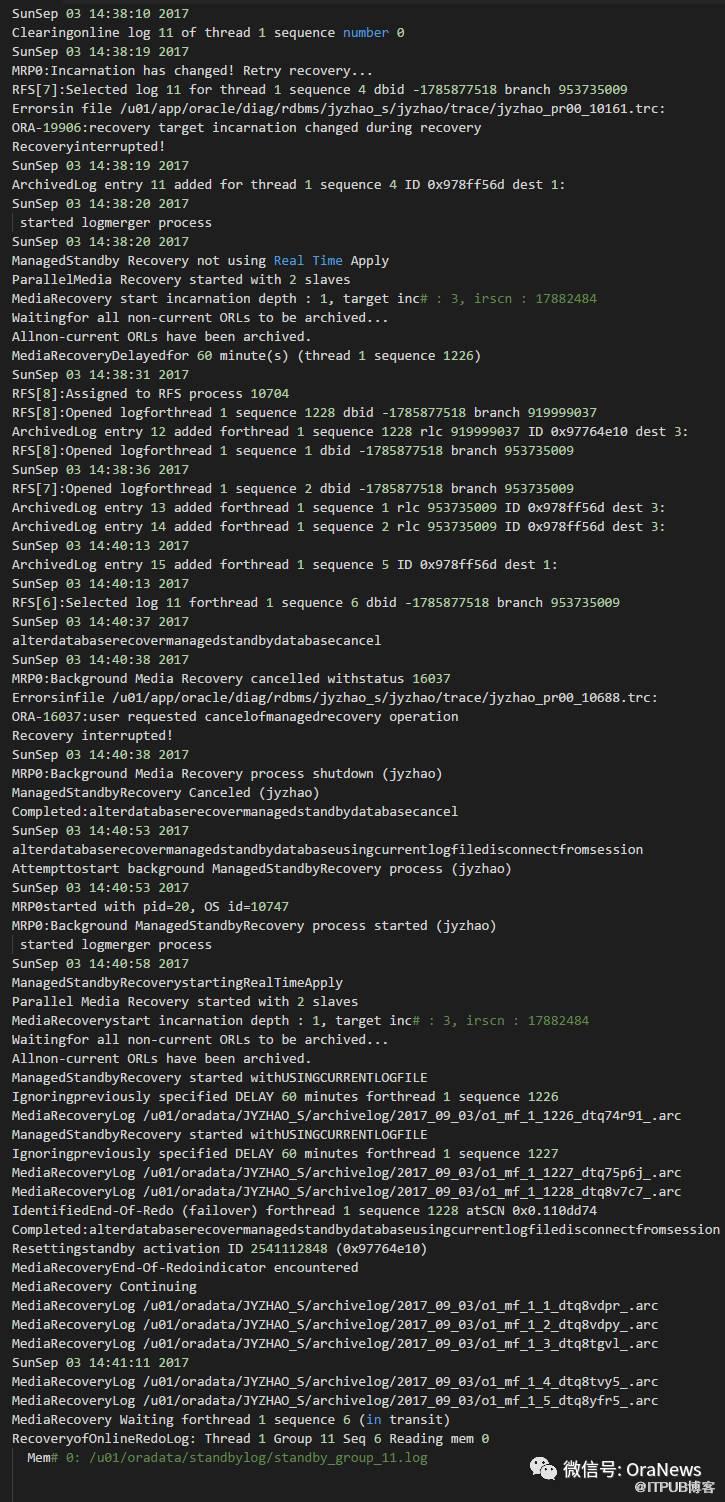
实际看到,C库已经可以正常应用日志。说明C库不需要重建即可通过简单配置成为新主库B库的新备库。
4、要求A库成为新主库的备库
此时A库启动的话,是一个独立运行的数据库,如果想将A库也设置为主库的话,那么,通过新主库的最新备份肯定是可行的,但是如果数据量很大,之前A库自己本身有历史的备份,能否不再耗时备份新主库,直接通过历史的备份恢复呢?其实这个从上面的C库不再需要重建直接成为新主库的备库,也可以推断出,是可以的。只需要确认这个备份是在failover之前完成的。下面我们来具体实验验证下可行性。
在B库创建新的备库控制文件,并传输到A库相同路径下:
backupcurrentcontrolfileforstandbyformat'/tmp/std_control02.ctl';
在A库启动到nomount,恢复新的备库控制文件
restorestandbycontrolfilefrom'/tmp/std_control02.ctl';
在A库查看数据文件头的检查点,确认是在failover之前:
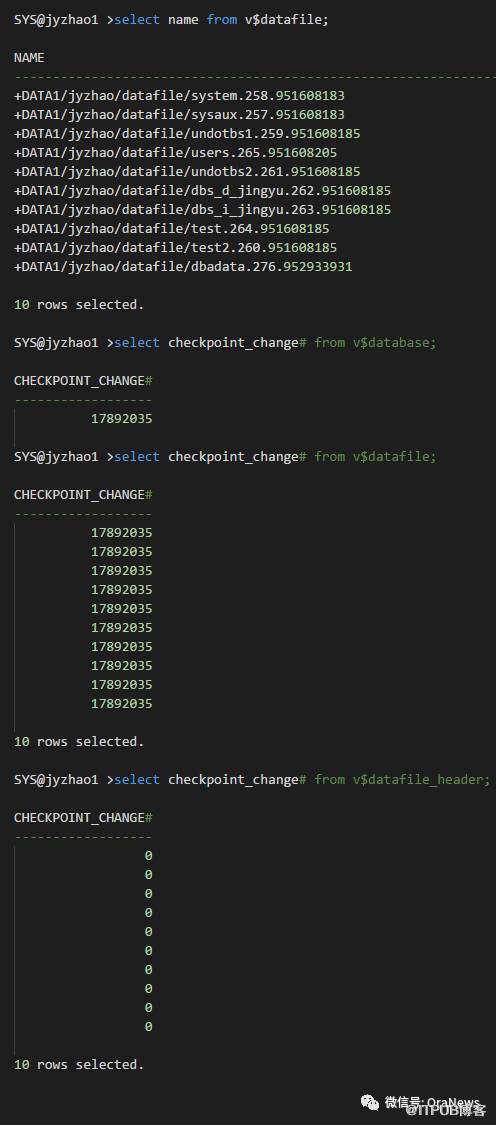
上面这个数据文件头的检查点是0,说明数据文件没有正确获取到,实际上是由于OMF的名字有变化,直接将数据文件路径catalog到备份集中,再switch即可。
catalogstartwith'+DATA1/jyzhao/datafile/';
switchdatabase to copy;
再次查询:
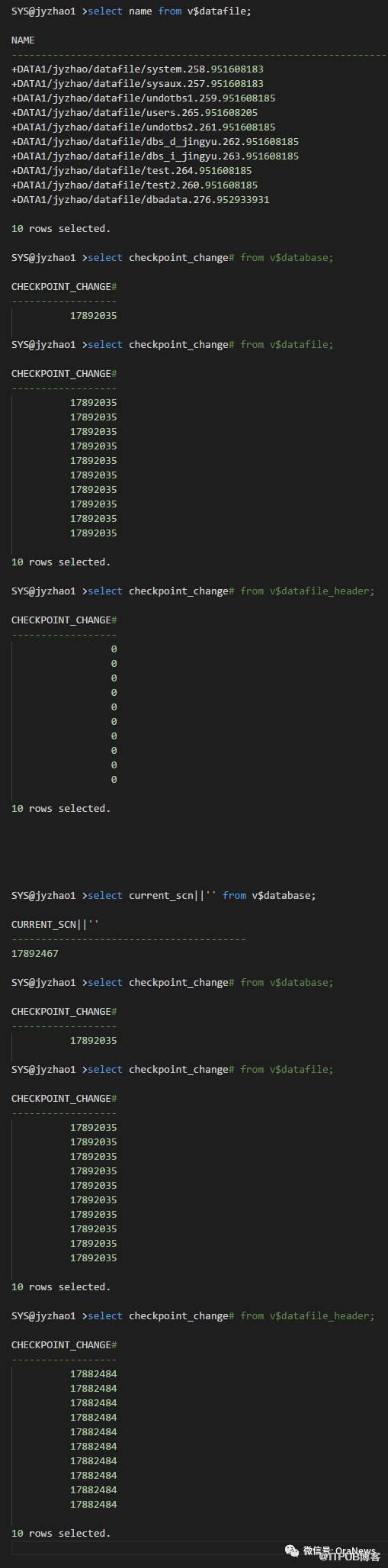
此时在mount状态下开启日志应用:
alter database recover managed standby database disconnect from session;
从告警日志观察,确认应用到最新时,取消日志应用:
alter database recover managed standby database cancel;
打开数据库,开启实时应用:
alter database recover managed standby database USING CURRENT LOGFILE disconnect from session;
最终查询可以正常实时应用。
结论
一般来说,在A库crash之后,B库failover成为新的主库,那么原来设置为延迟1小时应用的C 库是可以直接配置成为新主库的备库。A库修复后,也可以通过failover之前的现有备份集来恢复到failover之前的状态,而不需要在新主库重新去备份。
恩墨学院隶属于云和恩墨(北京)信息技术有限公司,致力于提供专业高水准的oracle数据库与大数据培训服务,挖掘培养大数据与数据库人才。恩墨学院提供包括个人实战技能培训、个人认证培训、企业内训在内的全方位大数据和数据库技术培训。ACE级别超强师资,配备专业实验室,沉浸式学习与训练,专业实验室、配备专业助教指导训练。能迅速融入专家圈子,业内资源丰富,迅速积累职场人脉。oracle数据库课程包括:Oracle DBA实战班、Oracle OCM考试、Oracle OCP考试等。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。