您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“怎么理解并掌握mysql的表”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
一.索引组织表
如果在创建表时没有定义主键,则innodb存储引擎会按如下方式选择或创建主键
-首先判断表中是否有非空的唯一索引,如果有则该列即为主键,当表中有多个非空唯一索引时,innodb存储引擎将选择建表时第一个定义的非空唯一索引为主键。
-如果不符合上述条件,innodb存储引擎自动创建一个6字节大小的指针。
点击(此处)折叠或打开
由于b为允许为null的唯一索引,所以该表的主键为d
create table wwj.z(
a int not null,
b int null,
c int not null,
d int not null,
unique key (b),
unique key (d),
unique key (c)
);
insert into wwj.z select 1,2,3,4;
insert into wwj.z select 5,6,7,8;
insert into wwj.z select 9,10,11,12;
mysql> select a,b,c,d,_rowid from wwj.z;
+---+------+----+----+--------+
| a | b | c | d | _rowid |
+---+------+----+----+--------+
| 1 | 2 | 3 | 4 | 4 |
| 5 | 6 | 7 | 8 | 8 |
| 9 | 10 | 11 | 12 | 12 |
+---+------+----+----+--------+
二.innodb逻辑存储结构
1.表空间
默认为所有数据都存放在共享表空间中。如果开启参数innodb_file_per_table之后,则每张表的数据将会放在单独的表空间中。
如果启用了innodb_file_per_table,则每张表的表空间内存放的只是数据,索引,和插入缓冲的bitmap页。其他类的数据,如插入缓冲索引页,系统事务信息,二次写缓冲,还是存放在原来的共享表空间中。
2.段
表空间是由各个段组成的,常见的段有数据段,索引段,回滚段等。
段的管理都是由引擎自身所完成,DBA不能也没有必要对其进行控制。
3.区
区是由连续页组成的空间,在任何情况下每个区的大小都为1m。
为了保证区中页的连续性,innodb存储引擎一次从磁盘申请4~5个区。默认情况innodb存储引擎页的大小为16kb,即一个区中一共有64个连续的页。
当用户启用参数innodb_file_er_table后,创建的表默认大小是96kb,而不是区的默认大小1m。这是因为在每个段开始时,先用32个页大小的碎片页来存放数据,使用完这些碎片页后,才是64个连续页的申请。这样做的目的是,对于一些小表,或者是undo这类的段,可以在开始时申请较少的空间,节省磁盘容量的开销。
4.页
innodb磁盘管理的最小单位
常见的页类型有:
数据页
undo页
系统页
事务数据页
插入缓冲位图页
插入缓冲空闲列表页
未压缩的二进制大对象页
压缩的二进制大对象页
5.行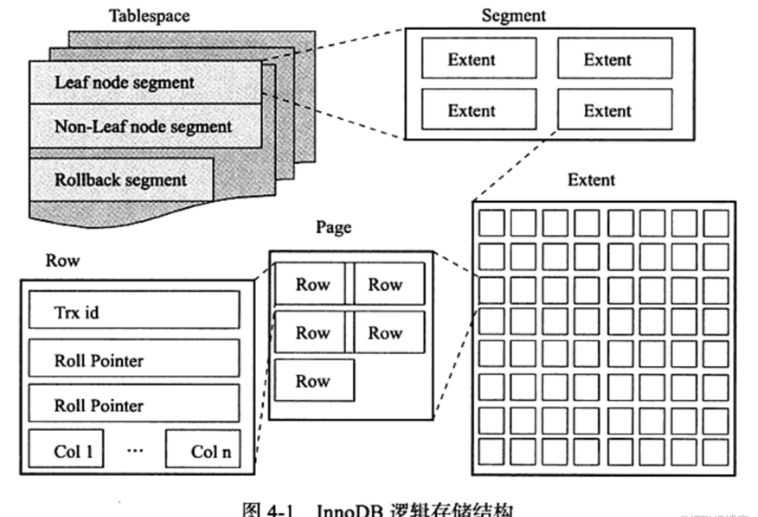
三.innodb行记录格式
1.compact行记录格式
5.0以后引入,其设计目的是高效的存储数据,简单来说,一个页中存放的行数据越多,其性能越高。
2.redundant
5.0之前的行记录存储格式
3.行溢出数据
行存放varchar类型的数据最大长度和为65532字节。
建表时varchar(N)表示的是字符长度。
例如:下面建表语句将会报错
create table haha22(
a varchar(65532)
) charset=utf8 engine=innodb;
ERROR 1074 (42000): Column length too big for column 'a' (max = 21845); use BLOB or TEXT instead
下面语句可以正常执行
create table haha22(
a varchar(1)
) charset=utf8 engine=innodb;
insert into wwj.haha22 values ('阳');
行溢出数据存储图: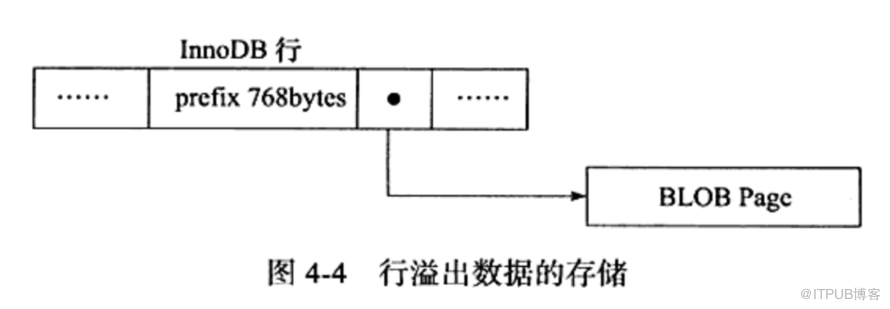
那么多长的varchar是保存在单个数据页中的,从多长开始又会保存在blob页呢?
可以这样进行思考:innodb存储引擎表是索引组织的,即B+Tree结构,这样每个页中至少应该有两条行记录,因此如果页中只能存放下一条记录,那么innodb存储引擎会自动将行数据存放到溢出页中。
经过实验发现当行的长度为8098字节时,可以在页中放入两条记录,并且不用扩展至blob页。
对于TEXT 和 BLOB数据类型也是如此,如果在数据页中能存放至少2条记录,则将不会将记录扩展至blob页。
4.新的文件格式barracuda
该文件格式下拥有两种新的行记录格式:compressed 和 dynamic
新的记录格式对于存放在blob中的数据采用了完全的行溢出的方式,在数据页中只存放20个字节的指针,实际数据都存放在off page中,而之前的compact 和 redundant两种格式会存放768个前缀字节。
图
compressed行记录格式的另一个功能就是,存储在其中的行数据会以zlib的算法进行压缩。因此对于blob,text,varchar这类大长度类型的数据能够进行非常有效的存储。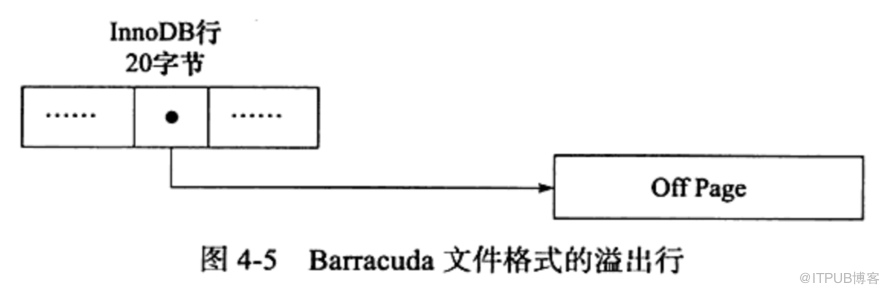
参数innodb_file_format用来指定文件格式
四.约束
约束类型
primary key
unique key
foreign key
default
not null
五.分区表
1.mysql支持以下几种类型的分区:
range分区
list分区
hash分区
key分区
* 如果表中存在主键或唯一索引时,分区列必须是唯一索引的一个组成部分.如果建表时没有指定主键,唯一索引,可以指定任何一个列为分区列。
* mysql分区表中的索引都是局部分区索引,不支持全局索引
2.分区类型
(1).range分区
create table wwj.sales(
money int,
date1 datetime
) engine=innodb
partition by range(year(date1)) (
partition p2008 values less than (year('2009-01-01')),
partition p2009 values less than (year('2010-01-01')),
partition p2010 values less than (year('2011-01-01'))
);
优化器只能对year(),to_days(),to_seconds(),unix_timestamp()这类函数进行优化选择
(2).list 分区
create table wwj.tt(
a int,
b int
) engine=innodb
partition by list(b) (
partition p0 values in (1,3,5,7,9),
partition p1 values in (0,2,4,6,8)
);
(3).hash 分区
目的是将数据均匀的分布到预先定义的各个分区中,保证各分区的数据量大致都是一样的
--普通hash分区
create table wwj.qqq(
a int,
b datetime
) engine=innodb
partition by hash (year(b))
partitions 4;
分配记录的算法如下:
mod(year('2010-04-01'),4) = mod(2010,4) =2
因此记录会放在p2分区中
--linear hash分区
create table wwj.qqq(
a int,
b datetime
) engine=innodb
partition by hash (year(b))
partitions 4;
分配记录的算法如下:
取大于分区数量4的下一个2的幂值V V=POWER(2,CEILING(LOG(2,num)))=4
所在分区N=YEAR('2010-04-01')&(V-1)=2
因此记录会放在p2分区中
linear hash分区的优点在于,增加,删除,合并,拆分分区将变得更加快捷,有利于处理含有大量数据的表。
缺点在于数据分布可能不太均衡。
(4).key分区
和hash分区相似,不同之处在于hash分区使用用户定义的函数进行分区,key分区使用mysql数据库提供的函数进行分区。
create table wwj.www(
a int,
b datetime
) engine=innodb
partition by key (b)
partitions 4;
(5).columns 分区
前面的4种分区中,分区的条件是:数据必须是整形,如果不是整形,则需要通过函数将其转化为整形。
columns分区可以直接使用非整形的数据进行分区,分区根据类型直接比较而得,不需要转化为整形,并且支持多个列的值进行分区。
columns支持以下数据类型:
int,smallint,tinyint,bigint,date,datetime,char,varchar,binary,varbinary
“怎么理解并掌握mysql的表”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。