您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下MySQL中HA MHA如何搭建,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
mha结构恢复过程: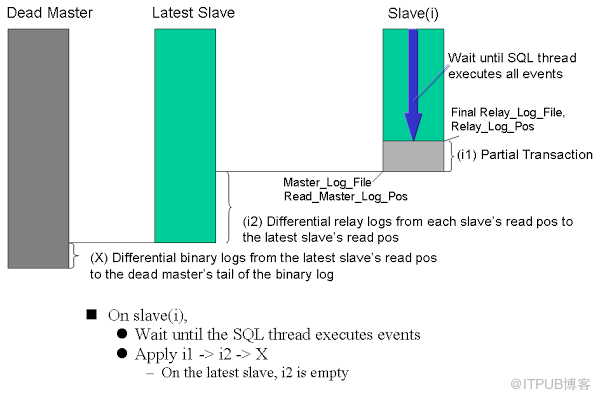
mha架构图: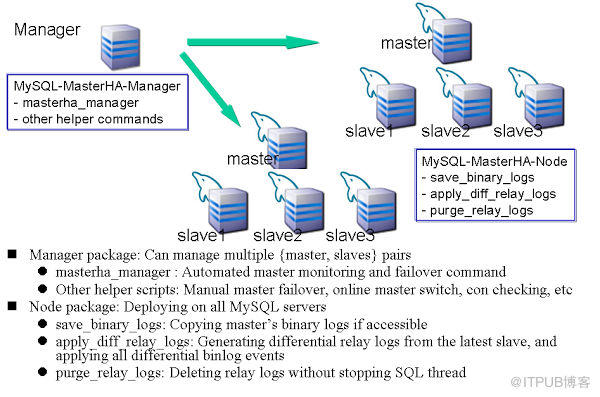
本次测试环境为3台服务器
其中将一台slave作为mha中的manager节点
--------------------------------------
ip hostname mysql
--------------------------------------
10.1.10.244 data01 master
10.1.10.80 data02 slave
10.1.10.91 manager slave
--------------------------------------
主机情况:
服务器发行版:centos6.7
内核:2.6.32-220.el6.x86_64
数据库软件版本:MySQL Community 5.6.29
------------------------------------- 修改主机名 -------------------------------------
undefined
244(master):
# vi /etc/sysconfig/network
将HOSTNAME修改为 data01
80(slave):
# vi /etc/sysconfig/network
将HOSTNAME修改为 data02
91(slave):
# vi /etc/sysconfig/network
将HOSTNAME修改为 manager
同时修改三台服务器hosts:
# vi /etc/hosts
添加:
10.1.10.244 data01
10.1.10.80 data02
10.1.10.91 manager
------------------------------------- 建立互信关系 -------------------------------------
在三台服务器上分别执行:
244(master)、80(slave)、91(slave):
# cd /root/.ssh
# ssh-keygen -t rsa
全部默认,直接回车
在224(master)上执行:
# cd /root/.ssh
# cat id_dsa.pub >> authorized_keys
# scp root@10.1.10.80:/root/.ssh/id_dsa.pub ./id_dsa.pub.data02.80
# scp root@10.1.10.91:/root/.ssh/id_dsa.pub ./id_dsa.pub.manager.91
# cat id_dsa.pub.data02.80 >> authorized_keys
# cat id_dsa.pub.manager.91 >> authorized_keys
# scp authorized_keys root@10.1.10.80:/root/.ssh/authorized_keys
# scp authorized_keys root@10.1.10.91:/root/.ssh/authorized_keys
从244(master)开始两两验证:
[root@data01 ~]# ssh data02
……略……
[root@data02 ~]# ssh manager
……略……
[root@manager ~]# ssh data01
……略……
[root@data01 ~]# ssh manager
……略……
[root@manager ~]# ssh data02
……略……
[root@data02 ~]# ssh data01
……略……
------------------------------------- 建立主从关系 -------------------------------------
在三台服务器上的mysql-server上分别执行:
244(master)、80(slave)、91(slave):
mysql> GRANT super, replication slave, reload ON *.* TO repl_user@'10.1.10.%' IDENTIFIED BY 'repl_user';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
分别修改三台服务器上mysql的配置文件:
244(master):
[mysqld]
log-bin = /var/lib/mysql/data01-bin
log-bin-index = /var/lib/mysql/data01-bin.index
server-id = 244
relay-log = /var/lib/mysql/data01-relay-bin
relay-log-index = /var/lib/mysql/data01-relay-bin.index
log-slave-updates
80(slave):
[mysqld]
log-bin = /var/lib/mysql/data02-bin
log-bin-index = /var/lib/mysql/data02-bin.index
server-id = 80
relay-log = /var/lib/mysql/data02-relay-bin
relay-log-index = /var/lib/mysql/data02-relay-bin.index
log-slave-updates
91(slave):
[mysqld]
log-bin = /var/lib/mysql/manager-bin
log-bin-index = /var/lib/mysql/manager-bin.index
server-id = 91
relay-log = /var/lib/mysql/manager-relay-bin
relay-log-index = /var/lib/mysql/manager-relay-bin.index
log-slave-updates
在两台slave上分别执行:
80(slave)、91(slave):
mysql> CHANGE MASTER TO
-> MASTER_HOST = '10.1.10.244',
-> MASTER_PORT = 3306,
-> MASTER_USER = 'repl_user',
-> MASTER_PASSWORD = 'repl_user';
Query OK, 0 rows affected, 2 warnings (0.03 sec)
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)
执行完后可以查看一下复制进程是否出问题:
mysql> SHOW SLAVE STATUS\G
若显示IO和SQL线程为Yes则表示复制建立好了:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
也可以通过SHOW PROCESSLIST来看。
------------------------------------- 安装mha-manager及mha-node -------------------------------------
即将需要用到的附件:
mha4mysql-node-0.56.tar.gz
mha4mysql-manager-0.56.tar.gz
这两个tar包可以搜一下
在三台服务器上分别执行:
244(data01)、80(data02)、91(manager):
# yum install -y perl-DBD-MySQL
继续分别在三台服务器上安装mha-node工具:
mha-node安装:
# tar zxvf mha4mysql-node-0.56.tar.gz
# cd mha4mysql-node-0.56
# perl Makefile.PL
# make && make install
在管理服务器上安装mha-manager工具:
91(manager):
先在manager服务器上安装一些依赖工具或perl模块:
# yum install -y perl-Config-Tiny
以下三个可能安不上:
# yum install -y perl-Log-Dispatch
# yum install -y perl-Parallel-ForkManager
# yum install -y perl-Config-IniFiles
可以通过perl CPAN来安装,如果没有,要先通过yum安装一下CPAN:
# yum install -y perl-CPAN
进入CPAN来安装perl模块:
# perl -MCPAN -e shell
cpan[1]> install Log::Dispatch
cpan[1]> install Parallel::ForkManager
cpan[1]> install Config::IniFiles
如果安装失败,可以根据提示信息,先安装一些依赖模块,暂时总结如下(CPAN中):
install Test::Requires
install Module::Runtime
install Dist::CheckConflicts
install Params::Validate
install Module::Runtime
install Module::Implementation
install ExtUtils::MakeMaker
mha-manger安装:
# tar zxvf mha4mysql-manager-0.56.tar.gz
# cd mha4mysql-manager-0.56
# perl Makefile.PL
通过检查Makefile.PL可以得知之前的模块是否安装成功。
检查效果如下:
…………
[Core Features]
- DBI ...loaded. (1.609)
- DBD::mysql ...loaded. (4.013)
- Time::HiRes ...loaded. (1.9728)
- Config::Tiny ...loaded. (2.12)
- Log::Dispatch ...loaded. (2.54)
- Parallel::ForkManager ...loaded. (1.17)
- MHA::NodeConst ...loaded. (0.56)
…………
如果missing则表示缺少。
如果都ok,则编译:
# make && make install
------------------------------------- 添加mha配置文件 -------------------------------------
在管理服务器上配置:
91(manager):
# mkdir /var/log/mha
# vi /etc/mha-manger.cnf
此次实验仅一个节点,若多个节点可以改一下manager服务器的配置文件结构:
touch /etc/masterha_default.cnf 写[server default]
touch /etc/node1.cnf 写该节点上的server信息,如[server_1]、[server_2]等
分别用 --global_conf=/etc/masterha_default.cnf --conf=/etc/node1.cnf来使用
-------- 配置文件 --------
[server default]
manager_workdir = /var/log/mha/
manager_log = /var/log/mha/manager.log
ssh_user = root
repl_user = repl_user
repl_password = repl_user
[server_1]
hostname = 10.1.10.244
user = root
password = root
candidate_master = 1
master_binlog_dir = /var/lib/mysql
[server_2]
hostname = 10.1.10.80
user = root
password = root
#candidate_master = 1
master_binlog_dir = /var/lib/mysql
[server_3]
hostname = 10.1.10.91
user = root
password = root
#candidate_master = 1
master_binlog_dir = /var/lib/mysql
其他参数此处取默认值,更多参数可查阅本文结尾处的参考文档。
-------- 配置文件 --------
undefined
# masterha_check_ssh --conf=/etc/mha-manager.cnf
- [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
- [info] Reading application default configuration from /etc/mha-manager.cnf..
- [info] Reading server configuration from /etc/mha-manager.cnf..
- [info] Starting SSH connection tests..
- [debug]
- [debug] Connecting via SSH from root@10.1.10.244(10.1.10.244:22) to root@10.1.10.80(10.1.10.80:22)..
- [debug] ok.
- [debug] Connecting via SSH from root@10.1.10.244(10.1.10.244:22) to root@10.1.10.91(10.1.10.91:22)..
- [debug] ok.
- [debug]
- [debug] Connecting via SSH from root@10.1.10.80(10.1.10.80:22) to root@10.1.10.244(10.1.10.244:22)..
- [debug] ok.
- [debug] Connecting via SSH from root@10.1.10.80(10.1.10.80:22) to root@10.1.10.91(10.1.10.91:22)..
- [debug] ok.
- [debug]
- [debug] Connecting via SSH from root@10.1.10.91(10.1.10.91:22) to root@10.1.10.244(10.1.10.244:22)..
Warning: Permanently added '10.1.10.91' (RSA) to the list of known hosts.
- [debug] ok.
- [debug] Connecting via SSH from root@10.1.10.91(10.1.10.91:22) to root@10.1.10.80(10.1.10.80:22)..
- [debug] ok.
- [info] All SSH connection tests passed successfully.
继续检查复制是否通:
# masterha_check_repl --conf=/etc/mha-manager.cnf
若看到【MySQL Replication Health is OK.】则表示成功连通。
若失败,则可以从防火墙,对应mysql服务器用户权限,对应操作系统用户对文件的读写权限等方面排查。
------------------------------------- 管理manager -------------------------------------
继续在管理服务器上启动:
91(manager):
启动manager:
# nohup masterha_manager --conf=/etc/mha-manager.cnf /var/log/mha/manager.log 2>&1 &
检查进程:
# ps -ef | grep manager
root 18210 10044 0 18:11 pts/1 00:00:00 perl /usr/local/bin/masterha_manager --conf=/etc/mha-manager.cnf /var/log/mha/manager.log
可以看一下最后的日志情况:
# tail -20 /var/log/mha/manager.log
……………………
Thu Feb 18 18:11:37 2016 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
继续检查master状态:
# masterha_check_status --conf=/etc/mha-manager.cnf
mha-manager (pid:18210) is running(0:PING_OK), master:10.1.10.244
关闭manager:
# masterha_stop --conf=/etc/mha-manager.cnf
Stopped mha-manager successfully.
------------------------------------- failover检测 -------------------------------------
此处模拟服务器整个宕机
操作:直接重启master服务器(此处是data01,即244)
通过tail -f查看mha-manager.log日志,刷出来如下记录:
Thu Feb 18 18:23:37 2016 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away)
Thu Feb 18 18:23:37 2016 - [info] Executing SSH check script: save_binary_logs --command=test --start_pos=4 --binlog_dir=/var/lib/mysql --output_file=/var/tmp/save_binary_logs_test --manager_version=0.56 --binlog_prefix=data01-bin
Thu Feb 18 18:23:37 2016 - [warning] HealthCheck: SSH to 10.1.10.244 is NOT reachable.
Thu Feb 18 18:23:43 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.1.10.244' (4))
Thu Feb 18 18:23:43 2016 - [warning] Connection failed 2 time(s)..
Thu Feb 18 18:23:46 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.1.10.244' (4))
Thu Feb 18 18:23:46 2016 - [warning] Connection failed 3 time(s)..
Thu Feb 18 18:23:49 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.1.10.244' (4))
Thu Feb 18 18:23:49 2016 - [warning] Connection failed 4 time(s)..
Thu Feb 18 18:23:49 2016 - [warning] Master is not reachable from health checker!
Thu Feb 18 18:23:49 2016 - [warning] Master 10.1.10.244(10.1.10.244:3306) is not reachable!
Thu Feb 18 18:23:49 2016 - [warning] SSH is NOT reachable.
Thu Feb 18 18:23:49 2016 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/mha-manager.cnf again, and trying to connect to all servers to check server status..
Thu Feb 18 18:23:49 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Thu Feb 18 18:23:49 2016 - [info] Reading application default configuration from /etc/mha-manager.cnf..
Thu Feb 18 18:23:49 2016 - [info] Reading server configuration from /etc/mha-manager.cnf..
Thu Feb 18 18:23:50 2016 - [info] GTID failover mode = 0
Thu Feb 18 18:23:50 2016 - [info] Dead Servers:
Thu Feb 18 18:23:50 2016 - [info] 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:50 2016 - [info] Alive Servers:
Thu Feb 18 18:23:50 2016 - [info] 10.1.10.80(10.1.10.80:3306)
Thu Feb 18 18:23:50 2016 - [info] 10.1.10.91(10.1.10.91:3306)
Thu Feb 18 18:23:50 2016 - [info] Alive Slaves:
Thu Feb 18 18:23:50 2016 - [info] 10.1.10.80(10.1.10.80:3306) Version=5.6.29-log (oldest major version between slaves) log-bin:enabled
Thu Feb 18 18:23:50 2016 - [info] Replicating from 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:50 2016 - [info] 10.1.10.91(10.1.10.91:3306) Version=5.6.29-log (oldest major version between slaves) log-bin:enabled
Thu Feb 18 18:23:50 2016 - [info] Replicating from 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:50 2016 - [info] Checking slave configurations..
Thu Feb 18 18:23:50 2016 - [info] read_only=1 is not set on slave 10.1.10.80(10.1.10.80:3306).
Thu Feb 18 18:23:50 2016 - [warning] relay_log_purge=0 is not set on slave 10.1.10.80(10.1.10.80:3306).
Thu Feb 18 18:23:50 2016 - [info] read_only=1 is not set on slave 10.1.10.91(10.1.10.91:3306).
Thu Feb 18 18:23:50 2016 - [warning] relay_log_purge=0 is not set on slave 10.1.10.91(10.1.10.91:3306).
Thu Feb 18 18:23:50 2016 - [info] Checking replication filtering settings..
Thu Feb 18 18:23:50 2016 - [info] Replication filtering check ok.
Thu Feb 18 18:23:50 2016 - [info] Master is down!
Thu Feb 18 18:23:50 2016 - [info] Terminating monitoring script.
Thu Feb 18 18:23:50 2016 - [info] Got exit code 20 (Master dead).
Thu Feb 18 18:23:50 2016 - [info] MHA::MasterFailover version 0.56.
Thu Feb 18 18:23:50 2016 - [info] Starting master failover.
Thu Feb 18 18:23:50 2016 - [info]
Thu Feb 18 18:23:50 2016 - [info] * Phase 1: Configuration Check Phase..
Thu Feb 18 18:23:50 2016 - [info]
Thu Feb 18 18:23:51 2016 - [info] GTID failover mode = 0
Thu Feb 18 18:23:51 2016 - [info] Dead Servers:
Thu Feb 18 18:23:51 2016 - [info] 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:51 2016 - [info] Checking master reachability via MySQL(double check)...
Thu Feb 18 18:23:52 2016 - [info] ok.
Thu Feb 18 18:23:52 2016 - [info] Alive Servers:
Thu Feb 18 18:23:52 2016 - [info] 10.1.10.80(10.1.10.80:3306)
Thu Feb 18 18:23:52 2016 - [info] 10.1.10.91(10.1.10.91:3306)
Thu Feb 18 18:23:52 2016 - [info] Alive Slaves:
Thu Feb 18 18:23:52 2016 - [info] 10.1.10.80(10.1.10.80:3306) Version=5.6.29-log (oldest major version between slaves) log-bin:enabled
Thu Feb 18 18:23:52 2016 - [info] Replicating from 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:52 2016 - [info] 10.1.10.91(10.1.10.91:3306) Version=5.6.29-log (oldest major version between slaves) log-bin:enabled
Thu Feb 18 18:23:52 2016 - [info] Replicating from 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:52 2016 - [info] Starting Non-GTID based failover.
Thu Feb 18 18:23:52 2016 - [info]
Thu Feb 18 18:23:52 2016 - [info] ** Phase 1: Configuration Check Phase completed.
Thu Feb 18 18:23:52 2016 - [info]
Thu Feb 18 18:23:52 2016 - [info] * Phase 2: Dead Master Shutdown Phase..
Thu Feb 18 18:23:52 2016 - [info]
Thu Feb 18 18:23:52 2016 - [info] Forcing shutdown so that applications never connect to the current master..
Thu Feb 18 18:23:52 2016 - [warning] master_ip_failover_script is not set. Skipping invalidating dead master IP address.
Thu Feb 18 18:23:52 2016 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Thu Feb 18 18:23:53 2016 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] * Phase 3: Master Recovery Phase..
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] The latest binary log file/position on all slaves is data01-bin.000016:120
Thu Feb 18 18:23:53 2016 - [info] Latest slaves (Slaves that received relay log files to the latest):
Thu Feb 18 18:23:53 2016 - [info] 10.1.10.80(10.1.10.80:3306) Version=5.6.29-log (oldest major version between slaves) log-bin:enabled
Thu Feb 18 18:23:53 2016 - [info] Replicating from 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:53 2016 - [info] 10.1.10.91(10.1.10.91:3306) Version=5.6.29-log (oldest major version between slaves) log-bin:enabled
Thu Feb 18 18:23:53 2016 - [info] Replicating from 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:53 2016 - [info] The oldest binary log file/position on all slaves is data01-bin.000016:120
Thu Feb 18 18:23:53 2016 - [info] Oldest slaves:
Thu Feb 18 18:23:53 2016 - [info] 10.1.10.80(10.1.10.80:3306) Version=5.6.29-log (oldest major version between slaves) log-bin:enabled
Thu Feb 18 18:23:53 2016 - [info] Replicating from 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:53 2016 - [info] 10.1.10.91(10.1.10.91:3306) Version=5.6.29-log (oldest major version between slaves) log-bin:enabled
Thu Feb 18 18:23:53 2016 - [info] Replicating from 10.1.10.244(10.1.10.244:3306)
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] * Phase 3.2: Saving Dead Master's Binlog Phase..
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [warning] Dead Master is not SSH reachable. Could not save it's binlogs. Transactions that were not sent to the latest slave (Read_Master_Log_Pos to the tail of the dead master's binlog) were lost.
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] * Phase 3.3: Determining New Master Phase..
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] Finding the latest slave that has all relay logs for recovering other slaves..
Thu Feb 18 18:23:53 2016 - [info] All slaves received relay logs to the same position. No need to resync each other.
Thu Feb 18 18:23:53 2016 - [info] Searching new master from slaves..
Thu Feb 18 18:23:53 2016 - [info] Candidate masters from the configuration file:
Thu Feb 18 18:23:53 2016 - [info] Non-candidate masters:
Thu Feb 18 18:23:53 2016 - [info] New master is 10.1.10.80(10.1.10.80:3306)
Thu Feb 18 18:23:53 2016 - [info] Starting master failover..
Thu Feb 18 18:23:53 2016 - [info]
From:
10.1.10.244(10.1.10.244:3306) (current master)
+--10.1.10.80(10.1.10.80:3306)
+--10.1.10.91(10.1.10.91:3306)
To:
10.1.10.80(10.1.10.80:3306) (new master)
+--10.1.10.91(10.1.10.91:3306)
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] * Phase 3.3: New Master Diff Log Generation Phase..
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] This server has all relay logs. No need to generate diff files from the latest slave.
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] * Phase 3.4: Master Log Apply Phase..
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] *NOTICE: If any error happens from this phase, manual recovery is needed.
Thu Feb 18 18:23:53 2016 - [info] Starting recovery on 10.1.10.80(10.1.10.80:3306)..
Thu Feb 18 18:23:53 2016 - [info] This server has all relay logs. Waiting all logs to be applied..
Thu Feb 18 18:23:53 2016 - [info] done.
Thu Feb 18 18:23:53 2016 - [info] All relay logs were successfully applied.
Thu Feb 18 18:23:53 2016 - [info] Getting new master's binlog name and position..
Thu Feb 18 18:23:53 2016 - [info] data02-bin.000003:684
Thu Feb 18 18:23:53 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.1.10.80', MASTER_PORT=3306, MASTER_LOG_FILE='data02-bin.000003', MASTER_LOG_POS=684, MASTER_USER='repl_user', MASTER_PASSWORD='xxx';
Thu Feb 18 18:23:53 2016 - [warning] master_ip_failover_script is not set. Skipping taking over new master IP address.
Thu Feb 18 18:23:53 2016 - [info] ** Finished master recovery successfully.
Thu Feb 18 18:23:53 2016 - [info] * Phase 3: Master Recovery Phase completed.
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] * Phase 4: Slaves Recovery Phase..
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
Thu Feb 18 18:23:53 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] -- Slave diff file generation on host 10.1.10.91(10.1.10.91:3306) started, pid: 18577. Check tmp log /var/log/mha//10.1.10.91_3306_20160218182350.log if it takes time..
Thu Feb 18 18:23:54 2016 - [info]
Thu Feb 18 18:23:54 2016 - [info] Log messages from 10.1.10.91 ...
Thu Feb 18 18:23:54 2016 - [info]
Thu Feb 18 18:23:53 2016 - [info] This server has all relay logs. No need to generate diff files from the latest slave.
Thu Feb 18 18:23:54 2016 - [info] End of log messages from 10.1.10.91.
Thu Feb 18 18:23:54 2016 - [info] -- 10.1.10.91(10.1.10.91:3306) has the latest relay log events.
Thu Feb 18 18:23:54 2016 - [info] Generating relay diff files from the latest slave succeeded.
Thu Feb 18 18:23:54 2016 - [info]
Thu Feb 18 18:23:54 2016 - [info] * Phase 4.2: Starting Parallel Slave Log Apply Phase..
Thu Feb 18 18:23:54 2016 - [info]
Thu Feb 18 18:23:54 2016 - [info] -- Slave recovery on host 10.1.10.91(10.1.10.91:3306) started, pid: 18579. Check tmp log /var/log/mha//10.1.10.91_3306_20160218182350.log if it takes time..
Thu Feb 18 18:23:55 2016 - [info]
Thu Feb 18 18:23:55 2016 - [info] Log messages from 10.1.10.91 ...
Thu Feb 18 18:23:55 2016 - [info]
Thu Feb 18 18:23:54 2016 - [info] Starting recovery on 10.1.10.91(10.1.10.91:3306)..
Thu Feb 18 18:23:54 2016 - [info] This server has all relay logs. Waiting all logs to be applied..
Thu Feb 18 18:23:54 2016 - [info] done.
Thu Feb 18 18:23:54 2016 - [info] All relay logs were successfully applied.
Thu Feb 18 18:23:54 2016 - [info] Resetting slave 10.1.10.91(10.1.10.91:3306) and starting replication from the new master 10.1.10.80(10.1.10.80:3306)..
Thu Feb 18 18:23:54 2016 - [info] Executed CHANGE MASTER.
Thu Feb 18 18:23:54 2016 - [info] Slave started.
Thu Feb 18 18:23:55 2016 - [info] End of log messages from 10.1.10.91.
Thu Feb 18 18:23:55 2016 - [info] -- Slave recovery on host 10.1.10.91(10.1.10.91:3306) succeeded.
Thu Feb 18 18:23:55 2016 - [info] All new slave servers recovered successfully.
Thu Feb 18 18:23:55 2016 - [info]
Thu Feb 18 18:23:55 2016 - [info] * Phase 5: New master cleanup phase..
Thu Feb 18 18:23:55 2016 - [info]
Thu Feb 18 18:23:55 2016 - [info] Resetting slave info on the new master..
Thu Feb 18 18:23:55 2016 - [info] 10.1.10.80: Resetting slave info succeeded.
Thu Feb 18 18:23:55 2016 - [info] Master failover to 10.1.10.80(10.1.10.80:3306) completed successfully.
Thu Feb 18 18:23:55 2016 - [info]
----- Failover Report -----
mha-manager: MySQL Master failover 10.1.10.244(10.1.10.244:3306) to 10.1.10.80(10.1.10.80:3306) succeeded
Master 10.1.10.244(10.1.10.244:3306) is down!
Check MHA Manager logs at manager:/var/log/mha/manager.log for details.
Started automated(non-interactive) failover.
The latest slave 10.1.10.80(10.1.10.80:3306) has all relay logs for recovery.
Selected 10.1.10.80(10.1.10.80:3306) as a new master.
10.1.10.80(10.1.10.80:3306): OK: Applying all logs succeeded.
10.1.10.91(10.1.10.91:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
10.1.10.91(10.1.10.91:3306): OK: Applying all logs succeeded. Slave started, replicating from 10.1.10.80(10.1.10.80:3306)
10.1.10.80(10.1.10.80:3306): Resetting slave info succeeded.
Master failover to 10.1.10.80(10.1.10.80:3306) completed successfully.
模拟结束
测的不太多,目前知道的一个坑:
mha建议关闭relay_log_purge,以保证用于有足够的中继日志去恢复其他的从库,也就是需要将relay_log_purge=0,导致relay-log无法定期清理。
可能需要手动添加定时任务来清理,清理方式可以是:
....../purge_relay_logs --user=$user --password=$password–disable_relay_log_purge >> ....../log/purge_relay_logs.log 2>&1
当然还需要配合vip节点等保证应用透明性,实现failover。
以上是“MySQL中HA MHA如何搭建”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。