您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
摘要: 作者介绍 韩锋,宜信技术研发中心数据库架构师。精通多种关系型数据库,曾任职于当当网、TOM在线等公司,曾任多家公司首席DBA、数据库架构师等职,多年一线数据库架构、设计、开发经验。著有《SQL优化最佳实践》一书。
作者介绍
韩锋,宜信技术研发中心数据库架构师。精通多种关系型数据库,曾任职于当当网、TOM在线等公司,曾任多家公司首席DBA、数据库架构师等职,多年一线数据库架构、设计、开发经验。著有《SQL优化最佳实践》一书。
Oracle中的AWR,全称为Automatic Workload Repository,自动负载信息库。它收集关于特定数据库的操作统计信息和其他统计信息,Oracle以固定的时间间隔(默认为1个小时)为其所有重要的统计信息和负载信息执行一次快照,并将快照存放入AWR中。这些信息在AWR中保留指定的时间(默认为1周),然后执行删除。执行快照的频率和保持时间都是可以自定义的。
AWR的引入,为我们分析数据库提供了非常好的便利条件(这方面MySQL就相差了太多)。曾经有这样的一个比喻——“一个系统,就像是一个黑暗的大房间,系统收集的统计信息,就如同放置在房间不同位置的蜡烛,用于照亮这个黑暗大房间。Oracle,恰到好处地放置了足够的蜡烛(AWR),房间中只有极少的烛光未覆盖之处,性能瓶颈就容易定位。而对于蜡烛较少或是没有蜡烛的系统,性能优化就如同黑暗中的舞者。”
那如何解读AWR的数据呢?Oracle本身提供了一些报告,方便进行查看、分析。下面就针对最为常见的一种报告——《AWR数据库报告》进行说明。希望通过这篇文章,能方便大家更好地利用AWR,方便进行分析工作。
一、MAIN
1 Database Information

2 Snapshot Information
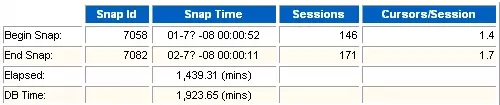
(1)Sessions
表示采集实例连接的会话数。这个数可以帮助我们了解数据库的并发用户数大概的情况。这个数值对于我们判断数据库的类型有帮助。
(2)Cursors/session
每个会话平均打开的游标数。
(3)Elapsed
通过Elapsed/DB Time比较,反映出数据库的繁忙程度。如果DB Time>>Elapsed,则说明数据库很忙。
(4)DB Time
表示用户操作花费的时间,包括CPU时间和等待事件。通常同时这个数值判读数据库的负载情况。
具体含义
db time = cpu time + wait time(不包含空闲等待)(非后台进程)
*db time就是记录的服务器花在数据库运算(非后台进程)和等待(非空闲等待)上的时间。对应于V$SESSION的elapsed_time字段累积。
"合集数据"
需要注意的是AWR是一个数据合集。比如在1分钟之内,1个用户等待了30秒钟,那么10个用户等待事件就是300秒。CPU时间也是一样,在1分钟之内,1个CPU处理30秒钟,那么4个CPU就是120秒。这些时间都是以累积的方式记录在AWR当中的。
示例
DB CPU——这是一个用于衡量CPU的使用率的重要指标。假设系统有N个CPU,那么如果CPU全忙的话,一秒钟内的DB CPU就是N秒。除了利用CPU进行计算外,数据库还会利用其它计算资源,如网络、硬盘、内存等等,这些对资源的利用同样可以利用时间进行度量。假设系统有M个session在运行,同一时刻有的session可能在利用CPU,有的session可能在访问硬盘,那么在一秒钟内,所有session的时间加起来就可以表征系统在这一秒内的繁忙程度。一般的,这个和的最大值应该为M。这其实就是Oracle提供的另一个重要指标:DB time,它用以衡量前端进程所消耗的总时间。
对除CPU以后的计算资源的访问,Oracle用等待事件进行描述。同样地,和CPU可分为前台消耗CPU和后台消耗CPU一样,等待事件也可以分为前台等待事件和后台等待事件。DB Time一般的应该等于"DB CPU + 前台等待事件所消耗时间"的总和。等待时间通过v$system_event视图进行统计,DB Time和DB CPU则是通过同一个视图,即v$sys_time_model进行统计。
--"Load Profile"中关于DB Time的描述
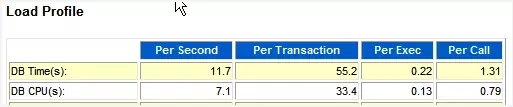
*这个系统的CPU个数是8,因此我们可以知道前台进程用了系统CPU的7.1/8=88.75%。DB Time/s为11.7,可以看出这个系统是CPU非常繁忙的。里面CPU占了7.1,则其它前台等待事件占了11.7 – 7.1 = 4.6 Wait Time/s。DB Time 占 DB CPU的比重: 7.1/11.7= 60.68%
--"Top 5 Timed Events"中关于DB CPU的描述
按照CPU/等待事件占DB Time的比例大小,这里列出了Top 5。如果一个工作负载是CPU繁忙型的话,那么在这里应该可以看到 DB CPU的影子。
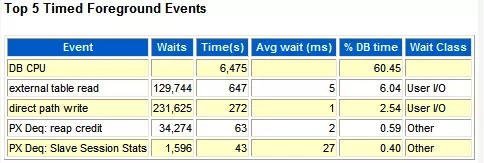
*注意到,我们刚刚已经算出了DB CPU 的%DB time,60%。其它的external table read、direct path write、PX Deq: read credit、PX Deq: Slave Session Stats这些就是占比重40的等待事件里的Top 4了。
--"Top 5 Timed Foreground Events"的局限性
再研究下这个Top 5 Timed Foreground Events,如果先不看Load Profile,是不能计算出一个CPU-Bound的工作负载。要知道系统CPU的繁忙程序,还要知道这个AWR所基于两个snapshot的时间间隔,还要知道系统CPU的个数。要不系统可以是一个很IDLE的系统呢。记住CPU利用率 = DB CPU/(CPU_COUNT*Elapsed TIME)。这个Top 5 给我们的信息只是这个工作负载应该是并行查询,从外部表读取数据,并用insert append的方式写入磁盘,同时,主要时间耗费在CPU的运算上。
--解读"DB Time" > "DB CPU" + "前台等待事件所消耗时间" ——进程排队时间
上面提到,DB Time一般的应该等于DB CPU + 前台等待事件所消耗时间的总和。在下面有对这三个值的统计:
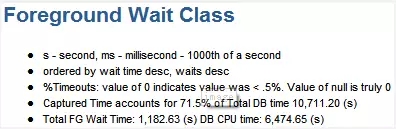
DB CPU = 6474.65
DB TIME = 10711.2
FG Wait Time = 1182.63
明显的,DB CPU + FG Wait Time < DB Time,只占了71.5%
*其它的28.5%被消耗到哪里去了呢?这里其实又隐含着一个Oracle如何计算DB CPU和DB Time的问题。当CPU很忙时,如果系统里存在着很多进程,就会发生进程排队等待CPU的现象。在这样,DB TIME是把进程排队等待CPU的时间算在内的,而DB CPU是不包括这一部分时间。这是造成 DB CPU + FG Wait Time < DB Time的一个重要原因。如果一个系统CPU不忙,这这两者应该就比较接近了。不要忘了在这个例子中,这是一个CPU非常繁忙的系统,而71.5%就是一个信号,它提示着这个系统可能是一个CPU-Bound的系统。
二、Report Summary
1 Cache Sizes

这部分列出AWR在性能采集开始和结束的时候,数据缓冲池(buffer cache)和共享池(shared pool)的大小。通过对比前后的变化,可以了解系统内存消耗的变化。
2 Load Profile
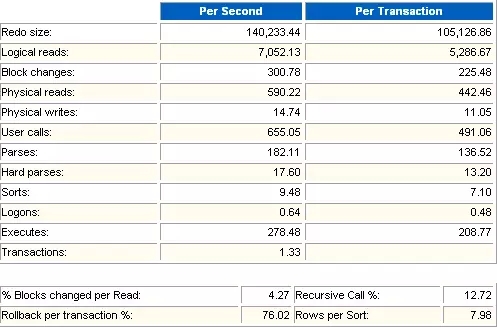
这两部分是数据库资源负载的一个明细列表,分隔成每秒钟的资源负载和每个事务的资源负载。
Redo size
每秒(每个事务)产生的日志大小(单位字节)
Logical reads
每秒(每个事务)产生的逻辑读(单位是block)。在很多系统里select执行次数要远远大于transaction次数。这种情况下,可以参考Logical reads/Executes。在良好的oltp环境下,这个应该不会超过50,一般只有10左右。如果这个值很大,说明有些语句需要优化。
Block Changes
每秒(每个事务)改变的数据块数。
Physical reads
每秒(每个事务)产生的物理读(单位是block)。一般物理读都会伴随逻辑读,除非直接读取这种方式,不经过cache。
Physical writes
每秒(每个事务)产生的物理写(单位是block)。
User calls
每秒(每个事务)用户调用次数。User calls/Executes基本上代表了每个语句的请求次数,Executes越接近User calls越好。
Parses
每秒(每个事务)产生的解析(或分析)的次数,包括软解析和硬解析,但是不包括快速软解析。软解析每秒超过300次意味着你的"应用程序"效率不高,没有使用soft soft parse,调整session_cursor_cache。
Hard parses
每秒(每个事务)产生的硬解析次数。每秒超过100次,就可能说明你绑定使用的不好。
Sorts
每秒(每个事务)排序次数。
Logons
每秒(每个事务)登录数据库次数。
Executes
每秒(每个事务)SQL语句执行次数。包括了用户执行的SQL语句与系统执行的SQL语句,表示一个系统SQL语句的繁忙程度。
Transactions
每秒的事务数。表示一个系统的事务繁忙程度。目前已知的最繁忙的系统为淘宝的在线交易系统,这个值达到了1000。
% Blocks changed per Read
表示逻辑读用于只读而不是修改的块的比例。如果有很多PLSQL,那么就会比较高。
Rollback per transaction %
看回滚率是不是很高,因为回滚很耗资源。
Recursive Call %
递归调用SQL的比例,在PL/SQL上执行的SQL称为递归的SQL。
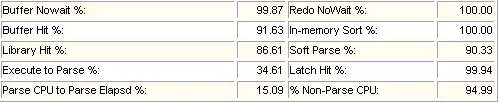
3 Instance Efficiency Percentages (Target 100%)
这个部分是内存效率的统计信息。对于OLTP系统而言,这些值都应该尽可能地接近100%。对于OLAP系统而言,意义不太大。因为在OLAP系统中,大查询的速度才是对性能影响的最大因素。
Buffer Nowait %
非等待方式获取数据块的百分比。
这个值偏小,说明发生SQL访问数据块时数据块正在被别的会话读入内存,需要等待这个操作完成。发生这样的事情通常就是某些数据块变成了热块。
Buffer Nowait<99%说明,有可能是有热块(查找x$bh的 tch和v$latch_children的cache buffers chains)。
Redo NoWait %
非等待方式获取redo数据百分比。
Buffer Hit %
数据缓冲命中率,表示了数据块在数据缓冲区中的命中率。
Buffer Hit<95%,可能是要加db_cache_size,但是大量的非选择的索引也会造成该值很高(大量的db file sequential read)。
In-memory Sort %
数据块在内存中排序的百分比。总排序中包括内存排序和磁盘排序。当内存中排序空间不足时,使用临时表空间进行排序,这个是内存排序对总排序的百分比。
过低说明有大量排序在临时表空间进行。在oltp环境下,最好是100%。如果太小,可以调整PGA参数。
Library Hit %
共享池中SQL解析的命中率。
Library Hit<95%,要考虑加大共享池,绑定变量,修改cursor_sharing等。
Soft Parse %
软解析占总解析数的百分比。可以近似当作sql在共享区的命中率。
这个数值偏低,说明系统中有些SQL没有重用,最优可能的原因就是没有使用绑定变量。
<95%:需要考虑到绑定
<80%:那么就可能sql基本没有被重用
Execute to Parse %
执行次数对分析次数的百分比。
如果该值偏小,说明解析(硬解析和软解析)的比例过大,快速软解析比例小。根据实际情况,可以适当调整参数session_cursor_cache,以提高会话中sql执行的命中率。
round(100*(1-:prse/:exe),2) 即(Execute次数 - Parse次数)/Execute次数 x 100%
prse = select value from v$sysstat where name = 'parse count (total)';
exe = select value from v$sysstat where name = 'execute count';
没绑定的话导致不能重用也是一个原因,当然sharedpool太小也有可能,单纯的加session_cached_cursors也不是根治的办法,不同的sql还是不能重用,还要解析。即使是soft parse 也会被统计入 parse count,所以这个指标并不能反应出fast soft(pga 中)/soft (shared pool中)/hard (shared pool 中新解析) 几种解析的比例。只有在pl/sql的类似循环这种程序中使用使用变量才能避免大量parse,所以这个指标跟是否使用bind并没有必然联系增加session_cached_cursors 是为了在大量parse的情况下把soft转化为fast soft而节约资源。
Latch Hit %
latch的命中率。
其值低是因为shared_pool_size过大或没有使用绑定变量导致硬解析过多。要确保>99%,否则存在严重的性能问题,比如绑定等会影响该参数。
Parse CPU to Parse Elapsd %
解析总时间中消耗CPU的时间百分比。即:100*(parse time cpu / parse time elapsed)
解析实际运行事件/(解析实际运行时间+解析中等待资源时间),越高越好。
% Non-Parse CPU
CPU非分析时间在整个CPU时间的百分比。
100*(parse time cpu / parse time elapsed)= Parse CPU to Parse Elapsd %
查询实际运行时间/(查询实际运行时间+sql解析时间),太低表示解析消耗时间过多。
4 Shared Pool Statistics

Memory Usage %
共享池内存使用率。
应该稳定在70%-90%间,太小浪费内存,太大则内存不足。
% SQL with executions>1
执行次数大于1的SQL比率。
若太小可能是没有使用绑定变量。
% Memory for SQL w/exec>1
执行次数大于1的SQL消耗内存/所有SQL消耗的内存(即memory for sql with execution > 1)。
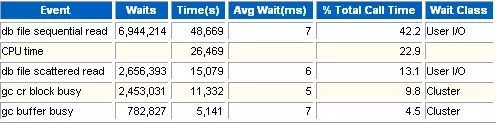
5 Top 5 Timed Events
三、RAC Statistics
这一部分只在有RAC环境下才会出现,是一些全局内存中数据发送、接收方面的性能指标,还有一些全局锁的信息。除非这个数据库在运行正常是设定了一个基线作为参照,否则很难从这部分数据中直接看出性能问题。
经验
Oracle公司经验,下面GCS和GES各项指标中,凡是与时间相关的指标,只要GCS指标低于10ms,GES指标低于15ms,则一般表示节点间通讯效率正常。但是,即便时间指标正常,也不表示应用本身或应用在RAC部署中没有问题。
1 Global Cache Load Profile
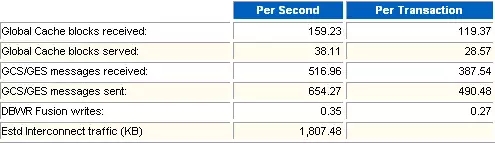
2 Global Cache Efficiency Percentages (Target local+remote 100%)

3 Global Cache and Enqueue Services - Workload Characteristics
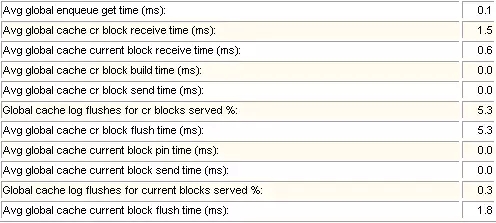
4 Global Cache and Enqueue Services - Messaging Statistics

5 Global Cache Transfer Stats

*如果CR的%Busy很大,说明节点间存在大量的块争用。
四、Wait Events Statistics
1 Time Model Statistics
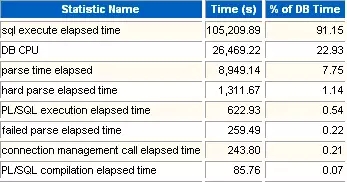
这部分信息列出了各种操作占用的数据库时间比例。
parse time elapsed/hard parse elapsed time
通过这两个指标的对比,可以看出硬解析占整个的比例。如果很高,就说明存在大量硬解析。
% Not-Parse CPU
花费在非解析上CPU消耗占整个CPU消耗的比例。反之,则可以看出解析占用情况。如果很高,也可以反映出解析过多(进一步可以看看是否是硬解析过多)。
示例 - 计算CPU消耗
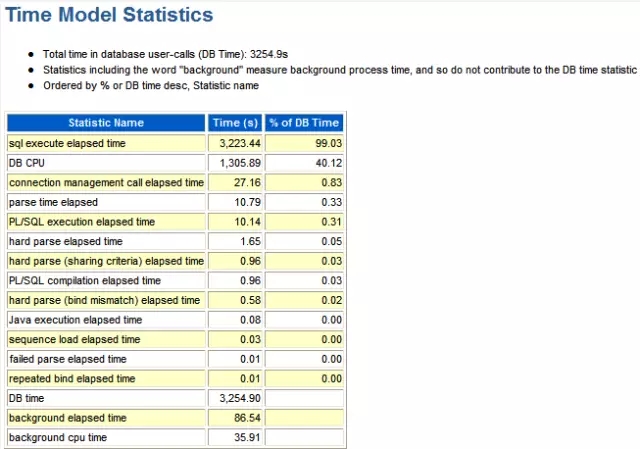
Total DB CPU = DB CPU + background cpu time = 1305.89 + 35.91 = 1341.8 seconds
再除以总的 BUSY_TIME + IDLE_TIME
% Total CPU = 1341.8/1941.76 = 69.1%,这刚好与上面Report的值相吻合。
其实,在Load Profile部分,我们也可以看出DB对系统CPU的资源利用情况。
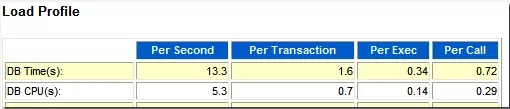
用DB CPU per Second除以CPU Count就可以得到DB在前台所消耗的CPU%了。
这里 5.3/8 = 66.25 %
比69.1%稍小,说明DB在后台也消耗了大约3%的CPU。
2 Wait Class
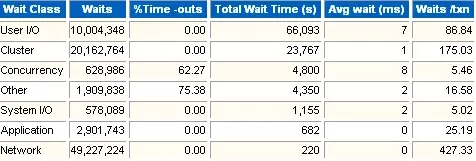
这一部分是等待的类型。可以看出那类等待占用的时间最长。
3 Wait Events
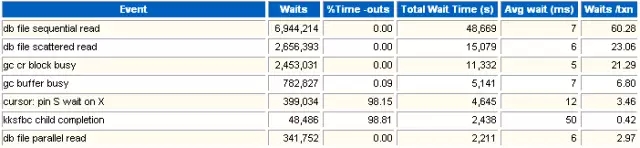
这一部分是整个实例等待事件的明细,它包含了TOP 5等待事件的信息。
%Time-outs: 超时百分比(超时依据不太清楚?)
4 Background Wait Events
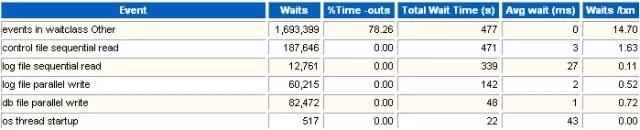
这一部分是实例后台进程的等待事件。如果我们怀疑那个后台进程(比如DBWR)无法及时响应,可以在这里确认一下是否有后台进程等待时间过长的事件存在。
5 Operating System Statistics
(1)背景知识
如果关注数据库的性能,那么当拿到一份AWR报告的时候,最想知道的第一件事情可能就是系统资源的利用情况了,而首当其冲的,就是CPU。而细分起来,CPU可能指的是:
OS级的User%, Sys%, Idle%
DB所占OS CPU资源的Busy%
DB CPU又可以分为前台所消耗的CPU和后台所消耗的CPU
(2)11g
如果数据库的版本是11g,那么很幸运的,这些信息在AWR报告中一目了然:
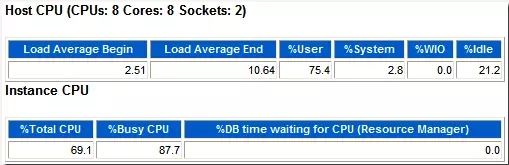
OS级的%User为75.4,%Sys为2.8,%Idle为21.2,所以%Busy应该是78.8。
DB占了OS CPU资源的69.1,%Busy CPU则可以通过上面的数据得到:%Busy CPU = %Total CPU/(%Busy) * 100 = 69.1/78.8 * 100 = 87.69,和报告的87.7相吻合。
(3)10g
如果是10g,则需要手工对Report里的一些数据进行计算了。Host CPU的结果来源于DBA_HIST_OSSTAT,AWR报告里已经帮忙整出了这段时间内的绝对数据(这里的时间单位是厘秒-也就是1/100秒)。
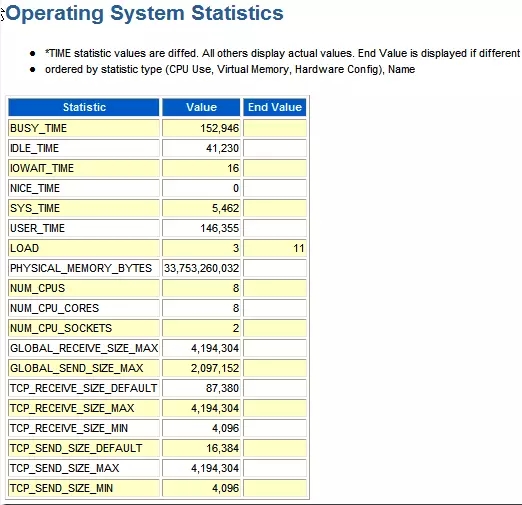
解读输出
%User = USER_TIME/(BUSY_TIME+IDLE_TIME)*100 = 146355/(152946+41230)*100 = 75.37
%Sys = SYS_TIME/(BUSY_TIME+IDLE_TIME)*100
%Idle = IDLE_TIME/(BUSY_TIME+IDLE_TIME)*100
ELAPSED_TIME
这里已经隐含着这个AWR报告所捕捉的两个snapshot之间的时间长短了。有下面的公式。正确的理解这个公式可以对系统CPU资源的使用及其度量的方式有更深一步的理解。
BUSY_TIME + IDLE_TIME = ELAPSED_TIME * CPU_COUNT
推算出:ELAPSED_TIME = (152946+41230)/8/100 = 242.72 seconds //这是正确的。
时间统计视图v$sys_time_model
至于DB对CPU的利用情况,这就涉及到10g新引入的一个关于时间统计的视图 - v$sys_time_model。简单而言,Oracle采用了一个统一的时间模型对一些重要的时间指标进行了记录,具体而言,这些指标包括:
1) background elapsed time
2) background cpu time
3) RMAN cpu time (backup/restore)
1) DB time
2) DB CPU
2) connection management call elapsed time
2) sequence load elapsed time
2) sql execute elapsed time
2) parse time elapsed
3) hard parse elapsed time
4) hard parse (sharing criteria) elapsed time
5) hard parse (bind mismatch) elapsed time
3) failed parse elapsed time
4) failed parse (out of shared memory) elapsed time
2) PL/SQL execution elapsed time
2) inbound PL/SQL rpc elapsed time
2) PL/SQL compilation elapsed time
2) Java execution elapsed time
2) repeated bind elapsed time
我们这里关注的只有和CPU相关的两个: background cpu time 和 DB CPU。这两个值在AWR里面也有记录。
五、SQL Statistics
1 SQL ordered by Elapsed Time

这一部分是按照SQL执行时间从长到短的排序。
Elapsed Time(S)
SQL语句执行用总时长,此排序就是按照这个字段进行的。注意该时间不是单个SQL跑的时间,而是监控范围内SQL执行次数的总和时间。单位时间为秒。Elapsed Time = CPU Time + Wait Time
CPU Time(s)
为SQL语句执行时CPU占用时间总时长,此时间会小于等于Elapsed Time时间。单位时间为秒。
Executions
SQL语句在监控范围内的执行次数总计。如果Executions=0,则说明语句没有正常完成,被中间停止,需要关注。
Elap per Exec(s)
执行一次SQL的平均时间。单位时间为秒。
% Total DB Time
为SQL的Elapsed Time时间占数据库总时间的百分比。
SQL ID
SQL语句的ID编号,点击之后就能导航到下边的SQL详细列表中,点击IE的返回可以回到当前SQL ID的地方。
SQL Module
显示该SQL是用什么方式连接到数据库执行的,如果是用SQL*Plus或者PL/SQL链接上来的那基本上都是有人在调试程序。一般用前台应用链接过来执行的sql该位置为空。
SQL Text
简单的SQL提示,详细的需要点击SQL ID。
分析说明
如果看到SQL语句执行时间很长,而CPU时间很少,则说明SQL在I/O操作时(包括逻辑I/O和物理I/O)消耗较多。可以结合前面I/O方面的报告以及相关等待事件,进一步分析是否是I/O存在问题。当然SQL的等待时间主要发生在I/O操作方面,不能说明系统就存在I/O瓶颈,只能说SQL有大量的I/O操作。
如果SQL语句执行次数很多,需要关注一些对应表的记录变化。如果变化不大,需要从前面考虑是否大多数操作都进行了Rollback,导致大量的无用功。
2 SQL ordered by CPU Time

记录了执行占CPU时间总和时间最长的TOP SQL(请注意是监控范围内该SQL的执行占CPU时间总和,而不是单次SQL执行时间)。这部分是SQL消耗的CPU时间从高到底的排序。
CPU Time (s)
SQL消耗的CPU时间。
Elapsed Time (s)
SQL执行时间。
Executions
SQL执行次数。
CPU per Exec (s)
每次执行消耗CPU时间。
% Total DB Time
SQL执行时间占总共DB time的百分比。
3 SQL ordered by Gets

这部分列出SQL获取的内存数据块的数量,按照由大到小的顺序排序。buffer get其实就是逻辑读或一致性读。在sql 10046里面,也叫query read。表示一个语句在执行期间的逻辑IO,单位是块。在报告中,该数值是一个累计值。Buffer Get=执行次数 * 每次的buffer get。记录了执行占总buffer gets(逻辑IO)的TOP SQL(请注意是监控范围内该SQL的执行占Gets总和,而不是单次SQL执行所占的Gets)。
Buffer Gets
SQL执行获得的内存数据块数量。
Executions
SQL执行次数。
Gets per Exec
每次执行获得的内存数据块数量。
%Total
占总数的百分比。
CPU Time (s)
消耗的CPU时间。
Elapsed Time (s)
SQL执行时间。
筛选SQL的标准
因为statspack/awr列出的是总体的top buffer,它们关心的是总体的性能指标,而不是把重心放在只执行一次的语句上。为了防止过大,采用了以下原则。如果有sql没有使用绑定变量,执行非常差但是由于没有绑定,因此系统人为是不同的sql。有可能不会被列入到这个列表中。
大于阀值buffer_gets_th的数值,这是sql执行缓冲区获取的数量(默认10000)。
小于define top_n_sql=65的数值。
4 SQL ordered by Reads

这部分列出了SQL执行物理读的信息,按照从高到低的顺序排序。记录了执行占总磁盘物理读(物理IO)的TOP SQL(请注意是监控范围内该SQL的执行占磁盘物理读总和,而不是单次SQL执行所占的磁盘物理读)。
Physical Reads
SQL物理读的次数。
Executions
SQL执行次数。
Reads per Exec
SQL每次执行产生的物理读。
%Total
占整个物理读的百分比。
CPU Time (s)
SQL执行消耗的CPU时间。
Elapsed Time (s)
SQL的执行时间。
5 SQL ordered by Executions

这部分列出了SQL执行次数的信息,按照从大到小的顺序排列。如果是OLTP系统的话,这部分比较有用。因此SQL执行频率非常大,SQL的执行次数会对性能有比较大的影响。OLAP系统因为SQL重复执行的频率很低,因此意义不大。
Executions
SQL的执行次数。
Rows Processed
SQL处理的记录数。
Rows per Exec
SQL每次执行处理的记录数。
CPU per Exec (s)
每次执行消耗的CPU时间。
Elap per Exec (s)
每次执行的时长。
6 SQL ordered by Parse Calls

这部分列出了SQL按分析次(软解析)数的信息,按照从高到底的顺序排列。这部分对OLTP系统比较重要,这里列出的总分析次数并没有区分是硬分析还是软分析。但是即使是软分析,次数多了,也是需要关注的。这样会消耗很多内存资源,引起latch的等待,降低系统的性能。软分析过多需要检查应用上是否有频繁的游标打开、关闭操作。
Parse Calls
SQL分析的次数。
Executions
SQL执行的次数。
% Total Parses
占整个分析次数的百分比。
7 SQL ordered by Sharable Memory
记录了SQL占用library cache的大小的TOP SQL。
Sharable Mem (b)
占用library cache的大小。单位是byte。
8 SQL ordered by Version Count

这部分列出了SQL多版本的信息。记录了SQL的打开子游标的TOP SQL。一个SQL产生多版本的原因有很多,可以查询视图v$sql_sahred_cursor视图了解具体原因。对于OLTP系统,这部分值得关注,了解SQL被重用的情况。
Version Count
SQL的版本数。
Executions
SQL的执行次数。
9 SQL ordered by Cluster Wait Time
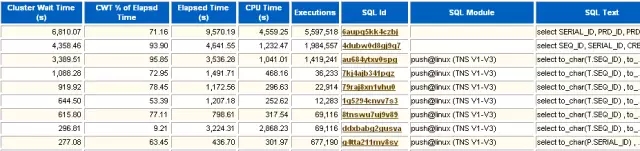
记录了集群的等待时间的TOP SQL。这部分只在RAC环境中存在,列出了实例之间共享内存数据时发生的等待。在RAC环境下,几个实例之间需要有一种锁的机制来保证数据块版本的一致性,这就出现了一类新的等待事件,发生在RAC实例之间的数据访问等待。对于RAC结构,还是采用业务分隔方式较好。这样某个业务固定使用某个实例,它访问的内存块就会固定地存在某个实例的内存中,这样降低了实例之间的GC等待事件。此外,如果RAC结构采用负载均衡模式,这样每个实例都会被各种应用的会话连接,大量的数据块需要在各个实例的内存中被拷贝和锁定,会加剧GC等待事件。
Cluster Wait Time (s)
集群等待时长。
CWT % of Elapsd Time
集群操作等待时长占总时长的百分比。
Elapsed Time(s)
SQL执行总时长。
10 Complete List of SQL Text

这部分是上面各部分涉及的SQL的完整文本。
六、Instance Activity Statistics
1 Instance Activity Stats
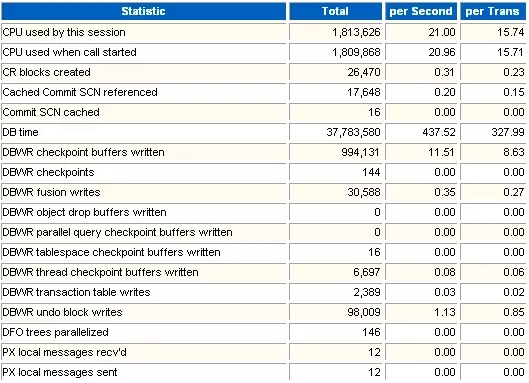
这部分是实例的信息统计,项目非常多。对于RAC架构的数据库,需要分析每个实例的AWR报告,才能对整体性能做出客观的评价。
CPU used by this session
这个指标用来上面在当前的性能采集区间里面,Oracle消耗的CPU单位。一个CPU单位是1/100秒。从这个指标可以看出CPU的负载情况。
案例 - 分析系统CPU繁忙程度

在TOP5等待事件里,找到"CPU time",可以看到系统消耗CPU的时间为26469秒。

在实例统计部分,可以看到整个过程消耗了1813626个CPU单位。每秒钟消耗21个CPU单位,对应实际的时间就是0.21秒。也就是每秒钟CPU的处理时间为0.21秒。

系统内CPU个数为8。每秒钟每个CPU消耗是21/8=2.6(个CPU单位)。在一秒钟内,每个CPU处理时间就是2.6/100=0.026秒。
*总体来看,当前数据库每秒钟每个CPU处理时间才0.026秒,远远算不上高负荷。数据库CPU资源很丰富,远没有出现瓶颈。
七、IO Stats
1 Tablespace IO Stats
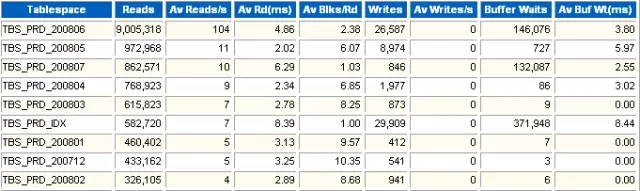
表空间的I/O性能统计。
Reads
发生了多少次物理读。
Av Reads/s
每秒钟物理读的次数。
Av Rd(ms)
平均一次物理读的时间(毫秒)。一个高相应的磁盘的响应时间应当在10ms以内,最好不要超过20ms;如果达到了100ms,应用基本就开始出现严重问题甚至不能正常运行。
Av Blks/Rd
每次读多少个数据块。
Writes
发生了多少次写。
Av Writes/s
每秒钟写的次数。
Buffer Waits
获取内存数据块等待的次数。
Av Buf Wt(ms)
获取内存数据块平均等待时间。
2 File IO Stats
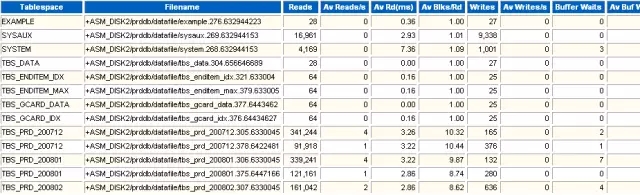
文件级别的I/O统计。
八、Advisory Statistics
顾问信息。这块提供了多种顾问程序,提出在不同情况下的模拟情况。包括databuffer、pga、shared pool、sga、stream pool、java pool等的情况。
1 Buffer Pool Advisory
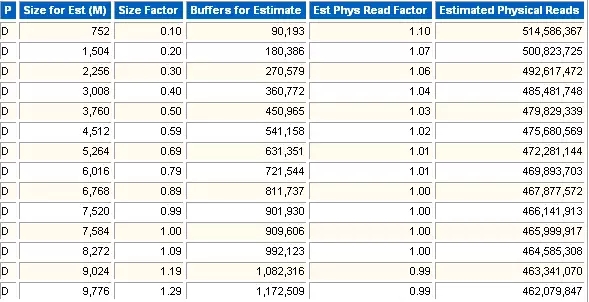
Buffer pool的大小建议。
Size for Est (M)
Oracle估算Buffer pool的大小。
Size Factor
估算值与实际值的比例。如果0.9就表示估算值是实际值的0.9倍。1.0表示buffer pool的实际大小。
Buffers for Estimate
估算的Buffer的大小(数量)。
Est Phys Read Factor
估算的物理读的影响因子,是估算物理读和实际物理读的一个比例。1.0表示实际的物理读。
Estimated Physical Reads
估计的物理读次数。
2 PGA Memory Advisory
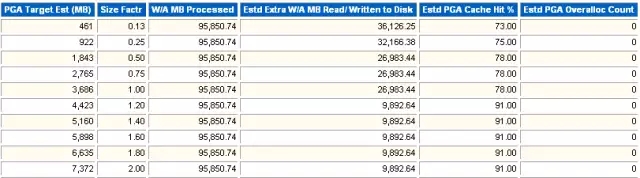
PGA的大小建议。
PGA Target Est (MB)
PGA的估算大小。
Size Factr
影响因子,作用和buffer pool advisory中相同。
W/A MB Processed
Oracle为了产生影响估算处理的数据量。
Estd Extra W/A MB Read/ Written to Disk
处理数据中需要物理读写的数据量。
Estd PGA Cache Hit %
估算的PGA命中率。
Estd PGA Overalloc Count
需要在估算的PGA大小下额外分配内存的个数。
3 Shared Pool Advisory

建议器通过设置不同的共享池大小,来获取相应的性能指标值。
Shared Pool Size(M)
估算的共享池大小。
SP Size Factr
共享池大小的影响因子。
Est LC Size (M)
估算的库高速缓存占用的大小。
Est LC Mem Obj
高速缓存中的对象数。
Est LC Time Saved (s)
需要额外将对象读入共享池的时间。
Est LC Time Saved Factr
对象读入共享池时间的影响因子。
表示每一个模拟的shared pool大小对重新将对象读入共享池的影响情况。当这个值的变化很小或不变的时候,增加shared pool的大小就意义不大。
Est LC Load Time (s)
分析所花费的时间。
Est LC Load Time Factr
分析花费时间的影响因子。
Est LC Mem Obj Hits
内存中对象被发现的次数。
4 SGA Target Advisory
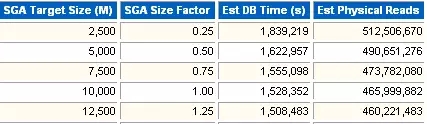
建议器对SGA整体的性能的一个建议。
SGA Target Size (M)
估算的SGA大小。
SGA Size Factor
SGA大小的影响因子。
Est DB Time (s)
估算的SGA大小计算出的DB Time。
Est Physical Reads
物理读的次数。
九、Latch Statistics
1 Latch Activity

Get Requests/Pct Get Miss/Avg Slps /Miss
表示愿意等待类型的latch的统计信息。
NoWait Requests/Pct NoWait Miss
表示不愿意等待类型的latch的统计信息。
Pct Misses
比例最好接近0。
十、Segment Statistics
1 Segments by Logical Reads

段的逻辑读情况。
2 Segments by Physical Reads
段的物理读情况。
3 Segments by Buffer Busy Waits

从这部分可以发现那些对象访问频繁。Buffer Busy Waits事件通常由于某些数据块太过频繁的访问,导致热点块的产生。
4 Segments by Row Lock Waits
AWR报告Segment Statistics部分的Segments by Row Lock Waits,非常容易引起误解,它包含的不仅仅是事务的行级锁等待,还包括了索引分裂的等待。之前我一直抱怨为什么v$segment_statistics中没有统计段级别的索引分裂计数,原来ORACLE已经实现了。但是统计进这个指标中,你觉得合适吗?
十一、其他问题
SQL运行周期对报告的影响
对SQL语句来讲,只有当它执行完毕之后,它的相关信息才会被Oracle所记录(比如:CPU时间、SQL执行时长等)。当时当某个SQL终止于做AWR报告选取的2个快照间隔时间之后,那么它的信息就不能被这个AWR报告反映出来。尽管它在采样周期里面的运行,也消耗了很多资源。
也就是说某个区间的性能报告并不能精确地反映出在这个采样周期中资源的消耗情况。因为有些在这个区间运行的SQL可能结束于这个时间周期之后,也可能有一些SQL在这个周期开始之前就已经运行了很久,恰好结束于这个采样周期。这些因素都导致了采样周期里面的数据并不绝对是这个时间段发生的所有数据库操作的资源使用的数据。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。