жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢMHAи°ғз ”дёҺеә”з”Ёзҡ„зӨәдҫӢеҲҶжһҗпјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
1гҖҒжІЎжңүе·Ҙе…·жқҘеҝ«йҖҹеҲҮжҚўйӣҶзҫӨдё»еә“пјҢеҰӮжһңеҲҮжҚўдё»еә“пјҢйңҖиҰҒDBAжүӢеҠЁдҝ®ж”№д»Һеә“жҢҮеҗ‘пјҢдҝ®ж”№е…ғдҝЎжҒҜзӯү
2гҖҒйңҖиҰҒиғҪеҝ«йҖҹдёҠзәҝпјҢдёҚеҪұе“ҚеҪ“еүҚжһ¶жһ„
3гҖҒйңҖиҰҒе…ЁйғЁиҮӘеҠЁеҢ–еӨ„зҗҶпјҢж–№дҫҝDBAдҪҝз”ЁпјҢдҫӢеҰӮжЈҖжҹҘпјҢж“ҚдҪңпјҢеұ•зӨәзӯү
MHAпјҲMaster High Availabilityпјүзӣ®еүҚеңЁMySQLй«ҳеҸҜз”Ёж–№йқўжҳҜдёҖдёӘзӣёеҜ№жҲҗзҶҹзҡ„и§ЈеҶіж–№жЎҲпјҢе®ғз”ұж—Ҙжң¬DeNAе…¬еҸёyoushimatonејҖеҸ‘пјҢжҳҜдёҖеҘ—дјҳз§Җзҡ„дҪңдёәMySQLй«ҳеҸҜз”ЁжҖ§зҺҜеўғдёӢж•…йҡңеҲҮжҚўе’Ңдё»д»ҺжҸҗеҚҮзҡ„й«ҳеҸҜз”ЁиҪҜ件гҖӮ
еңЁMySQLж•…йҡңеҲҮжҚўиҝҮзЁӢдёӯпјҢMHAиғҪеҒҡеҲ°еңЁ0~30з§’д№ӢеҶ…иҮӘеҠЁе®ҢжҲҗж•°жҚ®еә“зҡ„ж•…йҡңеҲҮжҚўж“ҚдҪңпјҢ并且еңЁиҝӣиЎҢж•…йҡңеҲҮжҚўзҡ„иҝҮзЁӢдёӯпјҢMHAиғҪеңЁжңҖеӨ§зЁӢеәҰдёҠдҝқиҜҒж•°жҚ®зҡ„дёҖиҮҙжҖ§пјҢд»ҘиҫҫеҲ°зңҹжӯЈж„Ҹд№үдёҠзҡ„й«ҳеҸҜз”ЁгҖӮ
phase 1: Configuration Check Phase..
mha will check the mha default file,then it can get the status of all mysql nodes and the relationship between them, who is master ,who is slave and who is dead ,who is alive.
Phase 2: Dead Master Shutdown Phase
дҪҝз”Ёmaster_ip_failover_scirptе’Ңshutdown script to shutdown or inactive the dead master ,пјҲsush as IP or DNS switchingпјҢwhich was defined in a self-defined script in advance ,just in case of split-brainпјү and I tend to use python.
пјҲжү§иЎҢmaster_ip_failover_script --command=stopssh дҪҝеҺҹдё»еә“IP еӨұж•Ҳпјӣжү§иЎҢSHUTDOWN script --command=stopsshпјҢе…ій—ӯеҺҹдё»еә“пјү
Phase 3: Master Recovery Phase
3.1 жҜ”иҫғжүҖжңүд»Һеә“зҡ„bin logзҡ„posзӮ№пјҢжүҫеҮәlatest binlog file&posе’Ңoldest file&pos
3.2 е°қиҜ•еҺ»еҺҹдё»еә“дёҠиҺ·еҸ–binlog
3.3 ж №жҚ®no_masterгҖҒcandidate_masterе’Ңеҗ„д»Һеә“延иҝҹжғ…еҶөпјҢйҖүеҮәж–°дё»еә“пјӣиҺ·еҸ–ж–°дё»еә“зҡ„ж—Ҙеҝ—зјәеӨұжғ…еҶө
3.4 з»ҷж–°йҖүеҮәжқҘзҡ„дё»еә“иЎҘж—Ҙеҝ—пјҢ并жҝҖжҙ»ж–°дё»еә“гҖӮ пјҲз”ҹжҲҗchange master toиҜӯеҸҘпјү
Phase 4: Slaves Recovery Phase
4.1 з»ҷд»Һеә“иЎҘж—Ҙеҝ—пјҡд»Һдё»еә“дёҠиЎҘж—Ҙеҝ—пјҢжҲ–иҖ…пјҢд»Һlastestд»Һеә“дёҠз»ҷе…¶д»–д»Һеә“иЎҘж—Ҙеҝ—
4.2 execute "change master to" command in all avaiable slaves , which is generated in former steps
Phase 5: New master cleanup
жё…йҷӨж–°дё»еә“зҡ„slave info
[info] * Phase 1: Configuration Check Phase..
[info] ** Phase 1: Configuration Check Phase completed.
[info] * Phase 2: Dead Master Shutdown Phase..
[info] * Phase 2: Dead Master Shutdown Phase completed.
[info] * Phase 3: Master Recovery Phase..
[info] * Phase 3.1: Getting Latest Slaves Phase..
[info] * Phase 3.2: Saving Dead Master's Binlog Phase..
[info] * Phase 3.3: Determining New Master Phase..
[info] * Phase 3.3: New Master Diff Log Generation Phase..
[info] * Phase 3.4: Master Log Apply Phase..
[info] * Phase 3: Master Recovery Phase completed.
[info] * Phase 4: Slaves Recovery Phase..
[info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
[info] * Phase 4.2: Starting Parallel Slave Log Apply Phase..
[info] * Phase 5: New master cleanup phase..
[info] Sending mail..
1гҖҒдёҚеҪұе“ҚжңҚеҠЎеҷЁжҖ§иғҪпјҢжҳ“е®үиЈ…пјҢдёҚж”№еҸҳзҺ°жңүйғЁзҪІ
2гҖҒж•…йҡңеҲҮжҚўпјҲе®һзҺ°иҮӘеҠЁж•…йҡңжЈҖжөӢе’Ңж•…йҡңиҪ¬з§»пјҢйҖҡеёёеңЁ30з§’д»ҘеҶ…;пјү
3гҖҒж•°жҚ®дёҖиҮҙжҖ§дҝқиҜҒ
жҢүиҠӮзӮ№еҲҶдёәпјҡmanage/nodeжЁЎејҸпјҢеҚіMHAз®ЎзҗҶжңәеҷЁдёҺйӣҶзҫӨnodeиҠӮзӮ№
жҢүеҲҮжҚўеҲҶдёәпјҡonline/failoverжЁЎејҸеҲҮжҚўпјҢеҚіеңЁзәҝеҲҮжҚўдёҺдё»еә“жҚҹеқҸеҲҮжҚў
1гҖҒжңҖе°‘дёҖдё»дёҖд»Һ
2гҖҒsshдә’дҝЎ
3гҖҒmysqlиҙҰеҸ·
4гҖҒlinuxзі»з»ҹ
5гҖҒmysqlзүҲжң¬5.0еҸҠд»ҘеҗҺ
6гҖҒmysqlbinlogеҝ…йЎ»жҳҜ3.3еҸҠд»ҘдёҠзүҲжң¬
7гҖҒlog-binеҝ…йЎ»еңЁжҜҸдёҖдёӘеҸҜз§°дёәmasterзҡ„mysqlжңҚеҠЎеҷЁдёҠи®ҫзҪ®
8гҖҒжүҖжңүmysqlжңҚеҠЎеҷЁзҡ„еӨҚеҲ¶иҝҮж»Ө规еҲҷеҝ…йЎ»дёҖиҮҙ
9гҖҒ еҝ…йЎ»еңЁиғҪжҲҗдёәmasterзҡ„жңҚеҠЎеҷЁдёҠи®ҫзҪ®еӨҚеҲ¶иҙҰжҲ·
10гҖҒеҹәдәҺиҜӯеҸҘзҡ„еӨҚеҲ¶ж—¶пјҢдёҚиҰҒдҪҝз”Ёload datainfileе‘Ҫд»Ө
11гҖҒе…ій—ӯrelay_log_purgeпјҢйңҖиҰҒи„ҡжң¬/жүӢеҠЁе®ҡжңҹжё…зҗҶпјҲжё…зҗҶж–№ејҸпјҡset global relay_log_purge=1;flush logs;пјү
2.6гҖҒMHAзүҲжң¬йҖүжӢ©
д»ҺMHAзҡ„0.56зүҲжң¬ејҖе§ӢпјҢд№ҹж”ҜжҢҒеҹәдәҺGTIDзҡ„ж•…йҡңеҲҮжҚўгҖӮMHAдјҡиҮӘеҠЁжЈҖжөӢmysqldжҳҜеҗҰеңЁGTIDиҝҗиЎҢпјҢеҰӮжһңGTIDејҖеҗҜпјҢMHAе°ұе®һзҺ°еёҰGTIDзҡ„ж•…йҡңеҲҮжҚўпјҢеҰӮжһңжІЎжңүеҗҜз”ЁпјҢMHAе°ұдҪҝз”ЁеҹәдәҺrelay logзҡ„ж•…йҡңеҲҮжҚўгҖӮ
2.7гҖҒйҮҚиҰҒеҸӮж•°
ignore_fail=1 еҝҪз•ҘжҠҘй”ҷ
candidate_master=1 1пјҡдјҳе…ҲжҲҗдёәmaster 0пјҡдёҚдјҳе…Ҳ
no_master=1 1пјҡдёҚиғҪжҲҗдёәmaster 0пјҡеҸҜд»ҘжҲҗдёәmaster
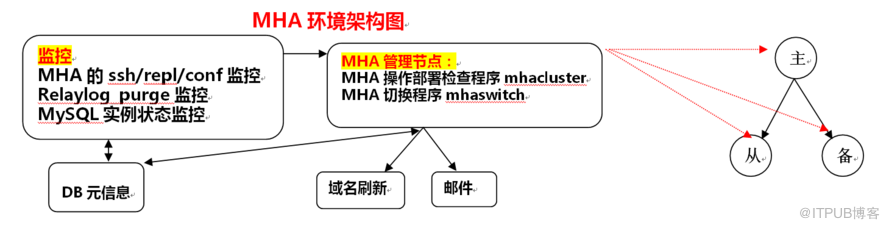

йӣҶжҲҗmhaж—Ҙеёёж“ҚдҪңпјҢйғЁзҪІпјҢжЈҖжҹҘпјҢдҝ®еӨҚзӯүеҠҹиғҪ
еҢ…жӢ¬пјҡ
<1>ж·»еҠ дә’дҝЎе…ізі»
<2>е®үиЈ…MHAиҪҜ件еҢ…зӯү
<3>жҺҲжқғзӣёе…іиҙҰжҲ·
<4>жЈҖжҹҘsshгҖҒreplгҖҒconfжӯЈзЎ®жҖ§зӯү
<5>иҮӘеҠЁдҝ®еӨҚй—®йўҳйӣҶзҫӨ
<6>иҮӘеҠЁжӣҙж–°жҜҸдёӘйӣҶзҫӨзҡ„confж–Ү件
<7>иҮӘеҠЁжӣҙж–°еҲ«еҗҚпјҢж–№дҫҝдҪҝз”Ё
<8>иҮӘеҠЁжё…зҗҶrelaylog
еҠҹиғҪжғ…еҶөеҰӮдёӢ
дёӯжҺ§/MHAз®ЎзҗҶжңәеҲ°жүҖжңүжңәеҷЁдә’дҝЎ е®ҢжҲҗ
ж·»еҠ йӣҶзҫӨеҶ…йғЁдә’дҝЎпјҢеҲ©з”Ёmake_ssh_authentication.shи„ҡжң¬жқҘиҮӘеҠЁж·»еҠ дә’дҝЎ
йңҖиҰҒsuper жқғйҷҗзҡ„ж•°жҚ®еә“з”ЁжҲ·пјҢжқҘжәҗ йӣҶзҫӨзҡ„жүҖжңүе®һдҫӢIP е®ҢжҲҗ
й»ҳи®Өи®ҫзҪ®дёәoffпјҢеҲ©з”Ёи„ҡжң¬д»»еҠЎпјҢе®ҡжңҹжё…зҗҶ
еҲ©з”ЁMHAиҮӘеёҰзҡ„purgeи„ҡжң¬пјҢйғЁзҪІеҲ°crontabе°ұеҸҜд»ҘдәҶпјҲе®үиЈ…е®ҢnodeиҮӘеҠЁдјҡжңүпјҢжҡӮж—¶жІЎжңүдҪҝз”ЁжӯӨж–№ејҸпјҢжЁЎжӢҹжӯӨж–№ејҸиҝӣиЎҢжё…зҗҶпјү
еӣ зӣ®еүҚеӯҳеңЁbinlogзӣ®еҪ•дёҚеӣәе®ҡпјҢжҡӮж—¶е…ҲеҲ©з”Ёи„ҡжң¬ж”¶йӣҶе…Ҙеә“иҮіе…ғдҝЎжҒҜ
жүҖжңүе®һдҫӢе®үиЈ…2дёӘиҪҜ件еҢ…
rpm -ivh /data/soft/perl-DBD-MySQL-4.013-3.el6.x86_64.rpm
rpm -ivh /data/soft/mha4mysql-node-0.56-0.el6.noarch.rpm
жЈҖжҹҘmhaиҰҒжұӮзҡ„masterha_check_ssh/repl
жЈҖжҹҘmhaй…ҚзҪ®ж–Ү件дёҺе…ғдҝЎжҒҜжҳҜеҗҰдёҖиҮҙ
иҮӘеҠЁдҝ®еӨҚssh/repl/conf жЈҖжҹҘй—®йўҳзҡ„йӣҶзҫӨ
жӣҙж–°mhaзҡ„еёёз”ЁеҲ«еҗҚ
alias masterha_check_ssh.1='masterha_check_repl --conf=/data/masterha/conf/1#testdb
alias masterha_check_repl.1='masterha_check_repl --conf=/data/masterha/conf/1#testdb
жіЁпјҡжӯӨеӨ„зҡ„1дёәйӣҶзҫӨеҸ·
жӣҙж–°mhaй…ҚзҪ®ж–Ү件
ж №жҚ®е…ғдҝЎжҒҜжқҘжӣҙж–°mhaзҡ„confж–Ү件
иҮӘеҠЁжҺҲжқғmhaиҰҒжұӮзҡ„иҙҰеҸ·
cluster_id йӣҶзҫӨеҸ·
cluster_name йӣҶзҫӨеҗҚ
roleпјҡMasterпјҢSlave,Backup и§’иүІ
binlog_dir binlogең°еқҖ
no_master дёҚиғҪжҲҗдёәmasterпјҢ1дёҚиғҪжҲҗдёәmasterпјҢ0еҸҜд»Ҙ
candidate_master жҳҜеҗҰдјҳе…ҲеҸҜеҲҮдёәmasterпјҢ1дјҳе…ҲпјҢ0дёҚдјҳе…Ҳ',
mha_write_into_conf жҳҜеҗҰеҶҷеҲ°й…ҚзҪ®ж–Ү件пјҢ1еҶҷе…ҘпјҢ0дёҚеҶҷе…Ҙ
[root@dbmon conf]# vi /etc/masterha_default.cnf
[server default]
manager_workdir=/data/masterha/work/
user=dba
password=
ssh_user=root
repl_user=repadm
repl_password=
ping_interval=30
shutdown_script=""
master_ip_failover_script="/data/mha/master_ip_failover_script.py" жіЁпјҡ failoverжЁЎејҸеҲҮжҚўдё»и„ҡжң¬
master_ip_online_change_script="/data/mha/master_ip_online_change_script.py" жіЁпјҡ onlineжЁЎејҸеҲҮжҚўдё»и„ҡжң¬
report_script="/data/mha/send_report.py" жіЁпјҡ еҸ‘йҖҒеҲҮжҚўеҗҺйӮ®д»¶дё»и„ҡжң¬
ж №жҚ®е…ғдҝЎжҒҜиҮӘеҠЁз”ҹжҲҗ
[server1]
hostname=10.0.0.1
port=3306
master_binlog_dir=/data/my3306/
ignore_fail=1
no_master=1
candidate_master=0
[server2]
hostname=10.0.0.2
port=3306
master_binlog_dir=/data/my3306/
ignore_fail=1
no_master=0
candidate_master=0
еҲҮжҚўзЁӢеәҸпјҢеҲ©з”ЁPythonе°ҒиЈ…пјҢж–№дҫҝж—ҘеёёеҲҮжҚўдҪҝз”Ё
ж”ҜжҢҒжү№йҮҸеҲҮжҚўйӣҶзҫӨ
еҲҮжҚўж–№ејҸпјҡonline/dead жЁЎејҸеҲҮжҚўпјҢеҚіеҺҹдё»еә“еӯҳжҙ»еҲҮжҚўпјҢеҺҹдё»еә“ж•…йҡңеҲҮжҚў

жіЁпјҡе…¶д»–иҫ…еҠ©и„ҡжң¬жҡӮж—¶дёҚж ҮжіЁ
еҸҜд»Ҙеұ•зӨәйӣҶзҫӨзҡ„е®һдҫӢдҝЎжҒҜпјҢеҰӮдёӢ
ж”ҜжҢҒonlineжЁЎејҸдёҺfailoverжЁЎејҸ еҲҮжҚўпјҲеҜ№еә”зЁӢеәҸзҡ„aliveпјҢdeadпјү
onlineжЁЎејҸпјҡеҸҜйҖүеҺҹдё»еә“жҳҜеҗҰдҪңдёәж–°дё»еә“зҡ„д»Һеә“
failoverжЁЎејҸпјҡе…ій—ӯеҺҹдё»еә“иҝӣиЎҢеҲҮжҚў
<1>еҪ“дј е…Ҙе‘Ҫд»Өдёәstopssh жҲ– stopпјҢеҚіе…ій—ӯеҺҹдё»еә“
<2>зӯү2з§’жЈҖжҹҘеҺҹдё»еә“жҳҜеҗҰе…ій—ӯпјҢжІЎжңүе…ій—ӯдјҡprint "old master still run,please check",зЁӢеәҸйҖҖеҮә
<3>еҪ“дј е…Ҙе‘Ҫд»Өдёәstart ж—¶пјҢејҖе§ӢиҝӣиЎҢе…ғж•°жҚ®зҡ„дҝ®ж”№
<4>дҝ®ж”№еҹҹеҗҚ-IPзҡ„еҜ№еә”е…ізі»
<5>и®ҫзҪ®ж–°дё»еә“read_only=offпјҢеҗҢж—¶дҝ®ж”№й…ҚзҪ®ж–Ү件
<6>дҝ®ж”№еҺҹдё»еә“read_only=onпјҢеҗҢж—¶дҝ®ж”№й…ҚзҪ®ж–Ү件
<1>еҪ“дј е…Ҙе‘Ҫд»Өдёәstopssh жҲ– stopпјҢеҚіи®ҫзҪ®еҺҹдё»еә“дёәread_only
<2>жЈҖжҹҘеҺҹдё»еә“жҳҜеҗҰдёәread_onlyпјҢеҰӮжһңжІЎжңүread_onlyдјҡprint " not read_only,please check",зЁӢеәҸйҖҖеҮә
<3>еҪ“дј е…Ҙе‘Ҫд»Өдёәstart ж—¶пјҢејҖе§ӢиҝӣиЎҢе…ғж•°жҚ®зҡ„дҝ®ж”№
<4>дҝ®ж”№еҹҹеҗҚ-IPзҡ„еҜ№еә”е…ізі»
<5>и®ҫзҪ®ж–°дё»еә“read_only=offпјҢеҗҢж—¶дҝ®ж”№й…ҚзҪ®ж–Ү件
<6>дҝ®ж”№еҺҹдё»еә“read_only=onпјҢеҗҢж—¶дҝ®ж”№й…ҚзҪ®ж–Ү件
<1>еҸ‘йҖҒfailoverжЁЎејҸеҲҮжҚўзҡ„ж—Ҙеҝ—пјҢеҲҮжҚўз»“жһң
<2>еҸ‘йҖҒMHAй…ҚзҪ®ж–Ү件ең°еқҖ
<3>иҖҒдё»еә“IPпјҢз«ҜеҸЈ
<4>ж–°дё»еә“IPпјҢз«ҜеҸЈ
<5>еә“еҗҚпјҢжңҚеҠЎеҗҚ
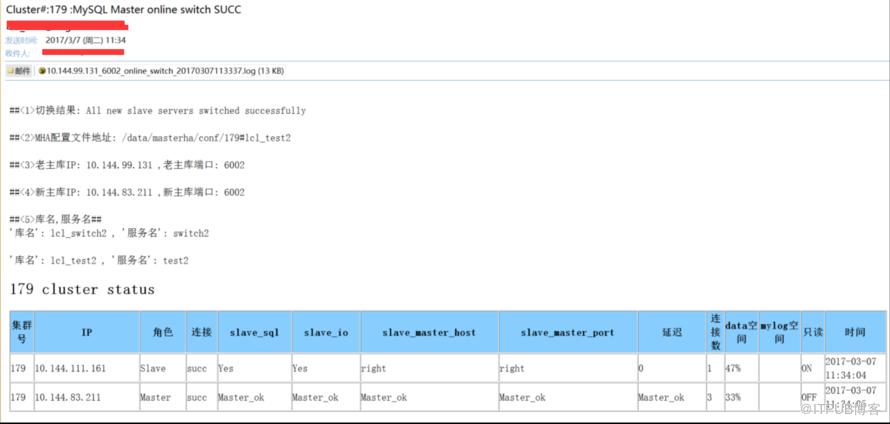
<6>жЈҖжҹҘеҲҮжҚўеҗҺзҡ„йӣҶзҫӨзҠ¶жҖҒпјҲиЎЁж јеҪўејҸпјүпјҡ
йӣҶзҫӨеҸ·пјҢIPпјҢи§’иүІпјҢжҳҜеҗҰеҸҜд»ҘиҝһжҺҘпјҢslave sqlзәҝзЁӢпјҢslave ioзәҝзЁӢпјҢslaveжүҖжҢҮдё»еә“hostжЈҖжҹҘпјҢslaveжүҖжҢҮдё»еә“з«ҜеҸЈжЈҖжҹҘпјҢslave延иҝҹпјҢиҝһжҺҘж•°пјҢ/dataз©әй—ҙжғ…еҶөпјҢеҸӘиҜ»жғ…еҶөпјҢж—¶й—ҙ
<1>еҸ‘йҖҒеңЁзәҝеҲҮжҚўзҡ„ж—Ҙеҝ—пјҢеҲҮжҚўз»“жһң
<2>еҸ‘йҖҒMHAй…ҚзҪ®ж–Ү件ең°еқҖ
<3>иҖҒдё»еә“IPпјҢз«ҜеҸЈ
<4>ж–°дё»еә“IPпјҢз«ҜеҸЈ
<5>еә“еҗҚпјҢжңҚеҠЎеҗҚ
<6>жЈҖжҹҘеҲҮжҚўеҗҺзҡ„йӣҶзҫӨзҠ¶жҖҒпјҲиЎЁж јеҪўејҸпјүпјҡ
йӣҶзҫӨеҸ·пјҢIPпјҢи§’иүІпјҢжҳҜеҗҰеҸҜд»ҘиҝһжҺҘпјҢslave sqlзәҝзЁӢпјҢslave ioзәҝзЁӢпјҢslaveжүҖжҢҮдё»еә“hostжЈҖжҹҘпјҢslaveжүҖжҢҮдё»еә“з«ҜеҸЈжЈҖжҹҘпјҢslave延иҝҹпјҢиҝһжҺҘж•°пјҢ/dataз©әй—ҙжғ…еҶөпјҢеҸӘиҜ»жғ…еҶөпјҢж—¶й—ҙ
<1>жӣҙж”№еҹҹеҗҚ-IPзҡ„еҜ№еә”е…ізі»и„ҡжң¬
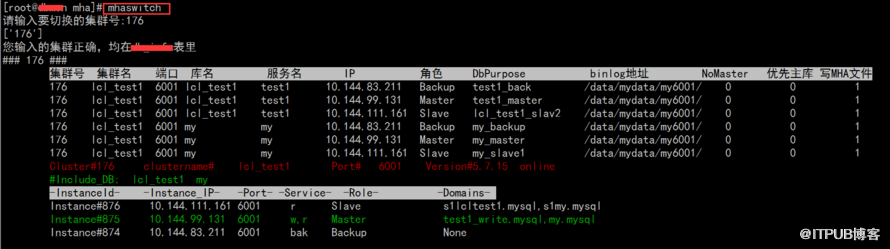
mhaswitch
иҜ·иҫ“е…ҘиҰҒеҲҮжҚўзҡ„йӣҶзҫӨеҸ·:78 жіЁпјҡеҲҮжҚўзҡ„йӣҶзҫӨеҸ·
###иҜ·иҫ“е…ҘйӣҶзҫӨ ['78'] дё»еә“зҡ„зҠ¶жҖҒгҖҗalive/deadгҖ‘:alive жіЁпјҡйҖүжӢ©еҲҮжҚўж–№ејҸ
<1>aliveпјҢдёҚе…ій—ӯеҺҹдё»еә“
<2>deadпјҢе…ій—ӯеҺҹдё»еә“
е°ҶеҲ©з”ЁMHAзҡ„onlineжЁЎејҸеҲҮжҚўпјҢдё»еә“дёҚдјҡе…ій—ӯпјҢдё” 'иҖҒдё»еә“' жҳҜеҗҰдҪңдёә 'ж–°йӣҶзҫӨ' зҡ„ 'д»Һеә“' е‘ўпјҹгҖҗyes/noгҖ‘,й»ҳи®Өno:yes жіЁпјҡйҖүжӢ©aliveеҗҺпјҡйңҖиҰҒйҖүжӢ© еҺҹдё»еә“ жҳҜеҗҰ дҪңдёәж–°дё»еә“зҡ„д»Һеә“пјҢyes жҳҜпјҢnoдёҚеҒҡпјҲеҚіи®ҫзҪ®read_onlyеҗҺдёҚе…ій—ӯпјү
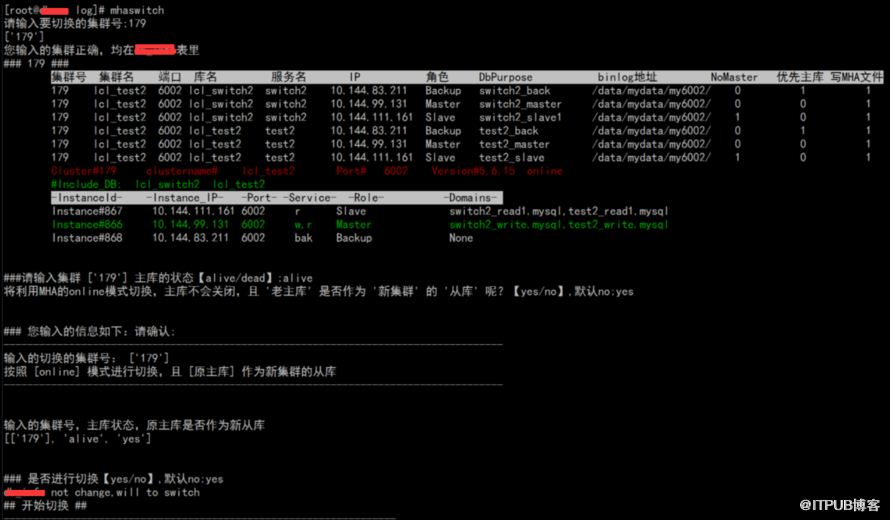
### жҳҜеҗҰиҝӣиЎҢеҲҮжҚўгҖҗyes/noгҖ‘,й»ҳи®Өno:yes жіЁпјҡжҳҜеҗҰзЎ®и®ӨејҖе§ӢеҲҮжҚўпјҢyesзЎ®и®ӨеҚіејҖе§ӢеҲҮжҚўпјҢnoйҖҖеҮә
<1>жҹҘзңӢmhaswitchиҫ“еҮә
<2>жҹҘзңӢйӮ®д»¶
<3>жҹҘзңӢе®һдҫӢзҠ¶жҖҒжҠҘиЎЁ
<4>жҹҘзңӢж–°дё»еә“и®ҝй—®зӯү
<5>жЈҖжҹҘж•°жҚ®дёҖиҮҙжҖ§зӯү
жӯӨеӨ„еҸӘдёҫдҫӢдёҖдёӘonlineжЁЎејҸзҡ„еҲҮжҚўпјҢfailoverжЁЎејҸзұ»дјј


жӢ“жү‘жғ…еҶө

йӮ®д»¶жғ…еҶө
иҫ“е…Ҙз”Ёж—¶пјҡ 10з§’ е·ҰеҸі
еҲҮжҚўз”Ёж—¶пјҡ 3-5з§’е·ҰеҸі
жЈҖжҹҘгҖҒжӣҙж–°еҸҠйӮ®д»¶з”Ёж—¶пјҡ 5з§’
жҖ»и®Ўпјҡ18-20з§’е·ҰеҸіпјҢе®һйҷ…еҪұе“ҚдёҡеҠЎеҶҷж—¶й—ҙдёә3-5з§’е·ҰеҸі
жЈҖжҹҘsshгҖҒreplгҖҒconfжӯЈзЎ®жҖ§пјҢжЈҖжҹҘзЁӢеәҸдёәmhaclusterпјҢз»“жһңе…Ҙеә“并еҲ©з”ЁdjangoеүҚз«Ҝеұ•зӨә
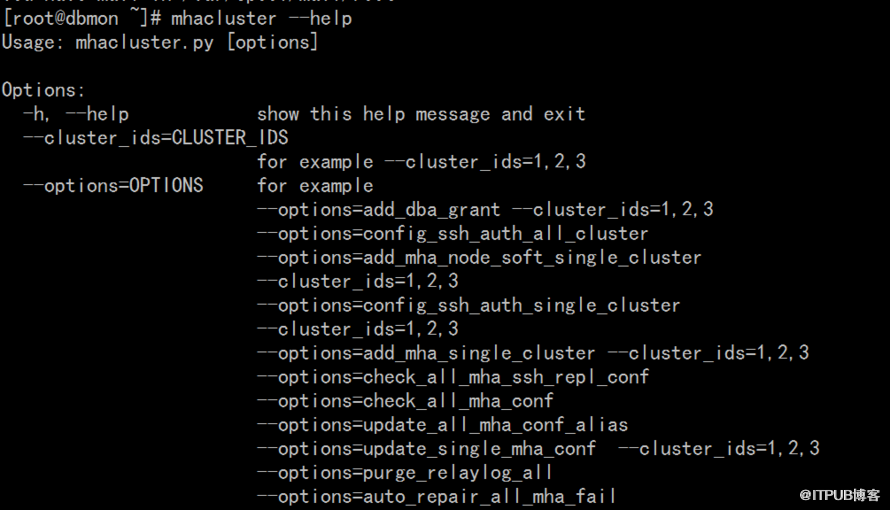
е‘Ҫд»Өдёәпјҡ
python mhacluster.py --options=check_all_mha_ssh_repl_conf
еүҚз«ҜжҠҘиЎЁдёәпјҡ

дё”ж”ҜжҢҒиҮӘеҠЁдҝ®еӨҚпјҢеҚіж №жҚ®жҠҘй”ҷжғ…еҶөиҝӣиЎҢдҝ®еӨҚпјҢе‘Ҫд»ӨеҰӮдёӢпјҡ
python mhacluster.py --options=auto_repair_all_mha_fail
жё…зҗҶиҝҮжңҹrelay_logпјҢ并жЈҖжҹҘзЁӢеәҸиҝҗиЎҢзҠ¶жҖҒеҸҠжё…зҗҶеҗҺзҠ¶жҖҒпјҢе…Ҙеә“并еүҚз«Ҝеұ•зӨәпјҢе‘Ҫд»ӨеҰӮдёӢ
python mhacluster.py --options=purge_relaylog_all
еүҚз«Ҝпјҡ

жЈҖжҹҘе®һдҫӢиҝҗиЎҢзҠ¶жҖҒпјҢеҢ…жӢ¬readonlyпјҢд»Һеә“IO,SQLзәҝзЁӢпјҢд»Һеә“жүҖжҢҮдё»еә“IP,portжҳҜеҗҰжӯЈзЎ®пјҢдё»д»Һ延иҝҹпјҢиҝһжҺҘж•°пјҢз©әй—ҙжғ…еҶөзӯүпјҢжқҘж–№дҫҝжҹҘзңӢйӣҶзҫӨеҲҮжҚўеҗҺзҡ„зҠ¶жҖҒпјҢеҸҜеҝ«йҖҹе®ҡдҪҚй—®йўҳ
python mysql_check.py --options=check_all
еүҚз«ҜжҠҘиЎЁеҰӮдёӢпјҡ

<1>жІЎжңүеҲҮжҚўпјҢе…ғдҝЎжҒҜзӯүйғҪжІЎжңүжӣҙж”№
<2>еҲҮжҚўдәҶпјҢйғЁеҲҶд»Һеә“е®һдҫӢеҲҮжҚўеӨұиҙҘ
жғ…еҶөпјҡжІЎжңүеҲҮжҚўпјҢе…ғдҝЎжҒҜжІЎжңүдҝ®ж”№
еҺҹеӣ пјҡ
masterha_check_repl жЈҖжҹҘеӨұиҙҘзҡ„еҺҹеӣ жңүеӨҡз§Қпјҡ
<1>ж— дҝЎд»»е…ізі»
<2>иҙҰжҲ·жқғйҷҗй—®йўҳ
<3>ж— еҸҜеҲҮдёәдё»еә“и®ҫзҪ®й—®йўҳзӯү
и§ЈеҶіпјҡ
1,2й—®йўҳеҸҜд»ҘйҖҡиҝҮеҲқе§ӢеҢ–mhaзҺҜеўғжқҘи§ЈеҶі
python mhacluster.py --options=add_mha_single_cluster --cluster_ids=1,2,3
3й—®йўҳпјҡж•°жҚ®еә“дёҚеҸҜеҲҮпјҢдјҳе…ҲеҲҮпјҢжҳҜеҗҰеҶҷе…Ҙй…ҚзҪ®ж–Ү件 й…ҚзҪ®й”ҷиҜҜй—®йўҳпјҢж”№жӯЈзЎ®еҚіеҸҜ
жғ…еҶөпјҡе·Із»ҸеҲҮжҚўдәҶпјҢйғЁеҲҶд»Һеә“жңүй—®йўҳ
еҺҹеӣ пјҡеҺҹеӣ жҜ”иҫғеӨҚжқӮпјҢдҫӢеҰӮзҪ‘з»ңпјҢжң¬иә«changeе‘Ҫд»Өж— жі•жү§иЎҢпјҲдҫӢеҰӮ5.7зҡ„жҹҗдәӣй…ҚзҪ®еҜјиҮҙпјүзӯү
еӨ„зҗҶпјҡ
<1>жЈҖжҹҘе®һдҫӢзҠ¶жҖҒпјҢзЎ®и®Өе“Әдәӣе®һдҫӢжңүй—®йўҳ
жҹҘзңӢжҠҘиЎЁпјҡе®һдҫӢзҠ¶жҖҒеҚіеҸҜзЎ®и®ӨпјҢдҫӢеҰӮпјҡ
<2>дҝ®еӨҚеҲҮжҚўеӨұиҙҘзҡ„д»Һеә“
ж №жҚ®ж—Ҙеҝ—зӯүжғ…еҶөиҝӣиЎҢдҝ®еӨҚжҲ–иҖ…йҮҚеҒҡгҖӮ
зӣ®еүҚе·Із»ҸжҲҗеҠҹеңЁзәҝдёҠиҝҗиЎҢ4дёӘжңҲд»ҘдёҠпјҢе·Із»ҸеҲҮжҚўзәҝдёҠйӣҶзҫӨ6дёӘд»ҘдёҠпјҲзәҝдёҠжөӢиҜ•зҺҜеўғеҲҮжҚў30+пјүпјҢжҡӮж—¶жІЎжңүеҸ‘зҺ°й—®йўҳ
зңҹжӯЈеҲҮжҚўиҖ—ж—¶еӨ§зәҰеңЁз§’зә§пјҲеӨҡж•°еңЁ3-5sд№Ӣй—ҙпјү
1гҖҒжІЎжңүж–№дҫҝзҡ„е·Ҙе…·жқҘеҝ«йҖҹеҲҮжҚўйӣҶзҫӨдё»еә“пјҢеҸ‘з”ҹдё»еә“ж•…йҡңж—¶пјҡ
йңҖиҰҒDBAиҠұиҙ№5еҲҶй’ҹжүӢеҠЁдҝ®ж”№д»Һеә“жҢҮеҗ‘пјҢ2-3еҲҶй’ҹжЈҖжҹҘйӣҶзҫӨзҠ¶жҖҒпјҢ3-5еҲҶй’ҹдҝ®ж”№е…ғдҝЎжҒҜпјҢ
е®һйҷ…еҒңжңәж“ҚдҪңж—¶й—ҙ3-5еҲҶй’ҹпјӣзӯүе…ұйңҖиҰҒ10-20еҲҶй’ҹ
пјҲд»…DBAж“ҚдҪңпјү
2гҖҒжІЎжңүе·Ҙе…·еҝ«йҖҹжҳҫзӨәжҹҗйӣҶзҫӨжӢ“жү‘жғ…еҶө
3гҖҒжІЎжңүе·Ҙе…·еҝ«йҖҹжЈҖжҹҘе®һдҫӢиҝҗиЎҢжғ…еҶө
1гҖҒеҲ©з”Ёmhaswitchе·Ҙе…·жқҘеҝ«йҖҹеҲҮжҚўдё»еә“
<1>еҸҜд»ҘйҷҚдҪҺдёўеӨұж•°жҚ®зҡ„йЈҺйҷ©
<2>еҪұе“ҚеҶҷе…Ҙж—¶й—ҙе°‘пјҢз§’зә§
еҲҮжҚўеүҚеҗҺе…ұйңҖиҰҒ5еҲҶй’ҹе·ҰеҸіпјҲд»…DBAж“ҚдҪңпјүпјҢе®һйҷ…еҒңжңәж“ҚдҪңпјҡ3-30sе·ҰеҸіпјҲеҰӮжһңеңЁзәҝеҲҮжҚўеӨ§иҮҙеңЁ3-5sпјҢеҰӮжһңжҳҜеҒңеҺҹдё»еә“еҲҮжҚўпјҢеҲҷеӨ§дәҺ10sпјү
DBAж•ҲзҺҮжҸҗеҚҮ 50%-75%е·ҰеҸіпјҢеҝ«зҡ„иҜқжҖ»ж—¶й—ҙеҸҜжҺ§еҲ¶еңЁ1еҲҶй’ҹеҶ…
зәҝдёҠе®һйҷ…ж“ҚеҒҡпјҡиҫ“е…ҘдҝЎжҒҜ10sе·ҰеҸіпјҢеҲҮжҚўеҪұе“ҚеҶҷе…Ҙ 3-5s е·ҰеҸіпјҢжӣҙж–°дёҺжЈҖжҹҘзӯү9sе·ҰеҸіпјҢе…ұи®Ў22-24sе·ҰеҸі
<3>mhaclusterйӣҶжҲҗйғЁзҪІпјҢеҮ дёӘе°Ҹж—¶еҚіеҸҜиҮӘеҠЁйғЁзҪІе…ЁйғЁmysqlе®һдҫӢпјҲзӣ®еүҚиҝ‘700дёӘе®һдҫӢпјҢиҝ‘500еҸ°жңәеҷЁпјҢе®һйҷ…йғЁзҪІдёҺжЈҖжҹҘеӨ§зәҰ4-6дёӘе°Ҹж—¶пјү
<4>ж— йңҖDBAжүӢеҠЁдҝ®ж”№дё»д»ҺпјҢиҠӮзәҰжүӢеҠЁж“ҚдҪңж—¶й—ҙзәҰ10-20еҲҶй’ҹ
<5>ж— йңҖDBAжүӢеҠЁдҝ®ж”№е…ғдҝЎжҒҜ,иҠӮзәҰдҝ®ж”№е…ғдҝЎжҒҜж—¶й—ҙ3-5еҲҶй’ҹе·ҰеҸі
ж— йңҖDBAжүӢеҠЁи°ғж•ҙеҹҹеҗҚIPе…ізі»пјҢиҠӮзәҰи°ғж•ҙеҹҹеҗҚIPж—¶й—ҙ1-3еҲҶй’ҹе·ҰеҸі
<6>е°ҒиЈ…MHAпјҢж–№дҫҝDBAдҪҝз”ЁпјҢж— йңҖз№Ғзҗҗе‘Ҫд»Ө
<7>йӮ®д»¶зЁӢеәҸпјҢеҸ‘йҖҒдҝЎжҒҜе…ЁпјҢеҸҜеҝ«йҖҹжҹҘзңӢеҲҮжҚўз»“жһңдёҺж—Ҙеҝ—зӯү
2гҖҒжҹҘиҜўйӣҶзҫӨжӢ“жү‘е·Ҙе…·qmysqlпјҢ1з§’еҶ…жҹҘзңӢйӣҶзҫӨжӢ“жү‘
3гҖҒжЈҖжҹҘйӣҶзҫӨзҠ¶жҖҒе·Ҙе…·mysql_checkпјҢжҹҘиҜўиҝ‘700дёӘе®һдҫӢпјҢиҝ‘500еҸ°жңәеҷЁ д»…йңҖ30sе·ҰеҸі
4гҖҒdjangoеүҚз«Ҝеұ•зӨәпјҢMHAзӣ‘жҺ§пјҢжҠҘиЎЁпјҢж–№дҫҝзӣ‘жҺ§MHAжғ…еҶөдёҺжҺ’й”ҷзӯү
д»ҘдёҠжҳҜвҖңMHAи°ғз ”дёҺеә”з”Ёзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ