жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іеҰӮдҪ•зҗҶи§ЈMYSQL-GroupCommit е’Ң 2pcжҸҗдәӨпјҢж–Үз« еҶ…е®№иҙЁйҮҸиҫғй«ҳпјҢеӣ жӯӨе°Ҹзј–еҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҜ№зӣёе…ізҹҘиҜҶжңүдёҖе®ҡзҡ„дәҶи§ЈгҖӮ
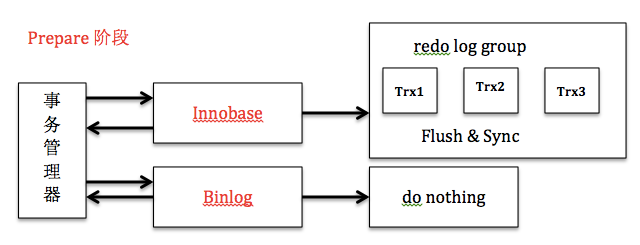
з»„жҸҗдәӨ(group commit)жҳҜMYSQLеӨ„зҗҶж—Ҙеҝ—зҡ„дёҖз§ҚдјҳеҢ–ж–№ејҸпјҢдё»иҰҒдёәдәҶи§ЈеҶіеҶҷж—Ҙеҝ—ж—¶йў‘з№ҒеҲ·зЈҒзӣҳзҡ„й—®йўҳгҖӮз»„жҸҗдәӨдјҙйҡҸзқҖMYSQLзҡ„еҸ‘еұ•дёҚж–ӯдјҳеҢ–пјҢд»ҺжңҖеҲқеҸӘж”ҜжҢҒredo log з»„жҸҗдәӨпјҢеҲ°зӣ®еүҚ5.6е®ҳж–№зүҲжң¬еҗҢж—¶ж”ҜжҢҒredo log е’Ңbinlogз»„жҸҗдәӨгҖӮз»„жҸҗдәӨзҡ„е®һзҺ°еӨ§еӨ§жҸҗй«ҳдәҶmysqlзҡ„дәӢеҠЎеӨ„зҗҶжҖ§иғҪпјҢе°Ҷд»Ҙinnodb еӯҳеӮЁеј•ж“ҺдёәдҫӢпјҢиҜҰз»Ҷд»Ӣз»Қз»„жҸҗдәӨеңЁеҗ„дёӘйҳ¶ж®өзҡ„е®һзҺ°еҺҹзҗҶгҖӮ
redo logзҡ„з»„жҸҗдәӨ
WAL(Write-Ahead-Logging)жҳҜе®һзҺ°дәӢеҠЎжҢҒд№…жҖ§зҡ„дёҖдёӘеёёз”ЁжҠҖжңҜпјҢеҹәжң¬еҺҹзҗҶжҳҜеңЁжҸҗдәӨдәӢеҠЎж—¶пјҢдёәдәҶйҒҝе…ҚзЈҒзӣҳйЎөйқўзҡ„йҡҸжңәеҶҷпјҢеҸӘйңҖиҰҒдҝқиҜҒдәӢеҠЎзҡ„redo logеҶҷе…ҘзЈҒзӣҳеҚіеҸҜпјҢиҝҷж ·еҸҜд»ҘйҖҡиҝҮredo logзҡ„йЎәеәҸеҶҷд»ЈжӣҝйЎөйқўзҡ„йҡҸжңәеҶҷпјҢ并且еҸҜд»ҘдҝқиҜҒдәӢеҠЎзҡ„жҢҒд№…жҖ§пјҢжҸҗй«ҳдәҶж•°жҚ®еә“зі»з»ҹзҡ„жҖ§иғҪгҖӮиҷҪ然WALдҪҝз”ЁйЎәеәҸеҶҷжӣҝд»ЈдәҶйҡҸжңәеҶҷпјҢдҪҶжҳҜпјҢжҜҸж¬ЎдәӢеҠЎжҸҗдәӨпјҢд»Қ然йңҖиҰҒжңүдёҖж¬Ўж—Ҙеҝ—еҲ·зӣҳеҠЁдҪңпјҢеҸ—йҷҗдәҺзЈҒзӣҳIOпјҢиҝҷдёӘж“ҚдҪңд»Қ然жҳҜдәӢеҠЎе№¶еҸ‘зҡ„瓶йўҲгҖӮ
з»„жҸҗдәӨжҖқжғіжҳҜпјҢе°ҶеӨҡдёӘдәӢеҠЎredo logзҡ„еҲ·зӣҳеҠЁдҪңеҗҲ并пјҢеҮҸе°‘зЈҒзӣҳйЎәеәҸеҶҷгҖӮInnodbзҡ„ж—Ҙеҝ—зі»з»ҹйҮҢйқўпјҢжҜҸжқЎredo logйғҪжңүдёҖдёӘLSN(Log Sequence Number)пјҢLSNжҳҜеҚ•и°ғйҖ’еўһзҡ„гҖӮжҜҸдёӘдәӢеҠЎжү§иЎҢжӣҙж–°ж“ҚдҪңйғҪдјҡеҢ…еҗ«дёҖжқЎжҲ–еӨҡжқЎredo logпјҢеҗ„дёӘдәӢеҠЎе°Ҷж—Ҙеҝ—жӢ·иҙқеҲ°log_sys_bufferж—¶(log_sys_buffer йҖҡиҝҮlog_mutex
дҝқжҠӨ)пјҢйғҪдјҡиҺ·еҸ–еҪ“еүҚжңҖеӨ§зҡ„LSNпјҢеӣ жӯӨеҸҜд»ҘдҝқиҜҒдёҚеҗҢдәӢеҠЎзҡ„LSNдёҚдјҡйҮҚеӨҚгҖӮйӮЈд№ҲеҒҮи®ҫдёүдёӘдәӢеҠЎTrx1,Trx2е’ҢTrx3зҡ„ж—Ҙеҝ—зҡ„жңҖеӨ§LSNеҲҶеҲ«дёәLSN1,LSN2,LSN3(LSN1<lsn2<lsn3)пјҢе®ғ们еҗҢж—¶иҝӣиЎҢжҸҗдәӨпјҢйӮЈд№ҲеҰӮжһңtrx3ж—Ҙеҝ—е…ҲиҺ·еҸ–еҲ°log_mutexиҝӣиЎҢиҗҪзӣҳпјҢе®ғе°ұеҸҜд»ҘйЎәдҫҝжҠҠ[lsn1---lsn3]иҝҷж®өж—Ҙеҝ—д№ҹеҲ·дәҶпјҢиҝҷж ·trx1е’Ңtrx2е°ұдёҚз”ЁеҶҚж¬ЎиҜ·жұӮзЈҒзӣҳioгҖӮз»„жҸҗдәӨзҡ„еҹәжң¬жөҒзЁӢеҰӮдёӢпјҡ </lsn2<lsn3)пјҢе®ғ们еҗҢж—¶иҝӣиЎҢжҸҗдәӨпјҢйӮЈд№ҲеҰӮжһңtrx3ж—Ҙеҝ—е…ҲиҺ·еҸ–еҲ°log_mutexиҝӣиЎҢиҗҪзӣҳпјҢе®ғе°ұеҸҜд»ҘйЎәдҫҝжҠҠ[lsn1---lsn3]иҝҷж®өж—Ҙеҝ—д№ҹеҲ·дәҶпјҢиҝҷж ·trx1е’Ңtrx2е°ұдёҚз”ЁеҶҚж¬ЎиҜ·жұӮзЈҒзӣҳioгҖӮз»„жҸҗдәӨзҡ„еҹәжң¬жөҒзЁӢеҰӮдёӢпјҡ<>
иҺ·еҸ– log_mutex
иӢҘflushed_to_disk_lsn>=lsnпјҢиЎЁзӨәж—Ҙеҝ—е·Із»Ҹиў«еҲ·зӣҳ,и·іиҪ¬5
иӢҘ current_flush_lsn>=lsnпјҢиЎЁзӨәж—Ҙеҝ—жӯЈеңЁеҲ·зӣҳдёӯпјҢи·іиҪ¬5еҗҺиҝӣе…Ҙзӯүеҫ…зҠ¶жҖҒ
е°Ҷе°ҸдәҺLSNзҡ„ж—Ҙеҝ—еҲ·зӣҳ(flush and sync)
йҖҖеҮәlog_mutex
еӨҮжіЁпјҡlsnиЎЁзӨәдәӢеҠЎзҡ„lsnпјҢflushed_to_disk_lsnе’Ңcurrent_flush_lsnеҲҶеҲ«иЎЁзӨәе·ІеҲ·зӣҳзҡ„LSNе’ҢжӯЈеңЁеҲ·зӣҳзҡ„LSNгҖӮ
redo log з»„жҸҗдәӨдјҳеҢ–
жҲ‘们зҹҘйҒ“пјҢеңЁејҖеҗҜbinlogзҡ„жғ…еҶөдёӢпјҢprepareйҳ¶ж®өпјҢдјҡеҜ№redo logиҝӣиЎҢдёҖж¬ЎеҲ·зӣҳж“ҚдҪң(innodb_flush_log_at_trx_commit=1)пјҢзЎ®дҝқеҜ№dataйЎөе’Ңundo йЎөзҡ„жӣҙж–°е·Із»ҸеҲ·ж–°еҲ°зЈҒзӣҳпјӣcommitйҳ¶ж®өпјҢдјҡиҝӣиЎҢеҲ·binlogж“ҚдҪң(sync_binlog=1),并且дјҡеҜ№дәӢеҠЎзҡ„undo logд»ҺprepareзҠ¶жҖҒи®ҫзҪ®дёәжҸҗдәӨзҠ¶жҖҒ(еҸҜжё…зҗҶзҠ¶жҖҒ)гҖӮйҖҡиҝҮдёӨйҳ¶ж®өжҸҗдәӨж–№ејҸ(innodb_support_xa=1)пјҢеҸҜд»ҘдҝқиҜҒдәӢеҠЎзҡ„binlogе’Ңredo logйЎәеәҸдёҖиҮҙгҖӮдәҢйҳ¶ж®өжҸҗдәӨиҝҮзЁӢдёӯпјҢmysql_binlogдҪңдёәеҚҸи°ғиҖ…пјҢеҗ„дёӘеӯҳеӮЁеј•ж“Һе’Ңmysql_binlogдҪңдёәеҸӮдёҺиҖ…гҖӮж•…йҡңжҒўеӨҚж—¶пјҢжү«жҸҸжңҖеҗҺдёҖдёӘbinlogж–Ү件(иҝӣиЎҢrotate binlogж–Ү件时пјҢзЎ®дҝқиҖҒзҡ„binlogж–Ү件еҜ№еә”зҡ„дәӢеҠЎе·Із»ҸжҸҗдәӨ)пјҢжҸҗеҸ–е…¶дёӯзҡ„xidпјӣйҮҚеҒҡжЈҖжҹҘзӮ№д»ҘеҗҺзҡ„redoж—Ҙеҝ—пјҢиҜ»еҸ–дәӢеҠЎзҡ„undoж®өдҝЎжҒҜпјҢжҗңйӣҶеӨ„дәҺprepareйҳ¶ж®өзҡ„дәӢеҠЎй“ҫиЎЁпјҢе°ҶдәӢеҠЎзҡ„xidдёҺbinlogдёӯзҡ„xidеҜ№жҜ”пјҢиӢҘеӯҳеңЁпјҢеҲҷжҸҗдәӨпјҢеҗҰеҲҷе°ұеӣһж»ҡгҖӮ
йҖҡиҝҮдёҠиҝ°зҡ„жҸҸиҝ°еҸҜзҹҘпјҢжҜҸдёӘдәӢеҠЎжҸҗдәӨж—¶пјҢйғҪдјҡи§ҰеҸ‘дёҖж¬Ўredo flushеҠЁдҪңпјҢз”ұдәҺзЈҒзӣҳиҜ»еҶҷжҜ”иҫғж…ўпјҢеӣ жӯӨеҫҲеҪұе“Қзі»з»ҹзҡ„еҗһеҗҗйҮҸгҖӮж·ҳе®қз«ҘйһӢеҒҡдәҶдёҖдёӘдјҳеҢ–пјҢе°Ҷprepareйҳ¶ж®өзҡ„еҲ·redoеҠЁдҪң移еҲ°дәҶcommit(flush-sync-commit)зҡ„flushйҳ¶ж®өд№ӢеүҚпјҢдҝқиҜҒеҲ·binlogд№ӢеүҚпјҢдёҖе®ҡдјҡеҲ·redoгҖӮиҝҷж ·е°ұдёҚдјҡиҝқиғҢеҺҹжңүзҡ„ж•…йҡңжҒўеӨҚйҖ»иҫ‘гҖӮ移еҲ°commitйҳ¶ж®өзҡ„еҘҪеӨ„жҳҜпјҢеҸҜд»ҘдёҚз”ЁжҜҸдёӘдәӢеҠЎйғҪеҲ·зӣҳпјҢиҖҢжҳҜleaderзәҝзЁӢеё®еҠ©еҲ·дёҖжү№redoгҖӮеҰӮдҪ•е®һзҺ°пјҢеҫҲз®ҖеҚ•пјҢеӣ дёәlog_sys->lsnе§Ӣз»ҲдҝқжҢҒдәҶеҪ“еүҚжңҖеӨ§зҡ„lsnпјҢеҸӘиҰҒжҲ‘们еҲ·redoеҲ·еҲ°еҪ“еүҚзҡ„log_sys->lsnпјҢе°ұдёҖе®ҡиғҪдҝқиҜҒпјҢе°ҶиҰҒеҲ·binlogзҡ„дәӢеҠЎredoж—Ҙеҝ—дёҖе®ҡе·Із»ҸиҗҪзӣҳгҖӮйҖҡиҝҮ延иҝҹеҶҷredoж–№ејҸпјҢе®һзҺ°дәҶredo logз»„жҸҗдәӨзҡ„зӣ®зҡ„пјҢиҖҢдё”еҮҸе°‘дәҶlog_sys->mutexзҡ„з«һдәүгҖӮзӣ®еүҚиҝҷз§Қзӯ–з•Ҙе·Із»Ҹиў«е®ҳж–№mysql5.7.6еј•е…ҘгҖӮ
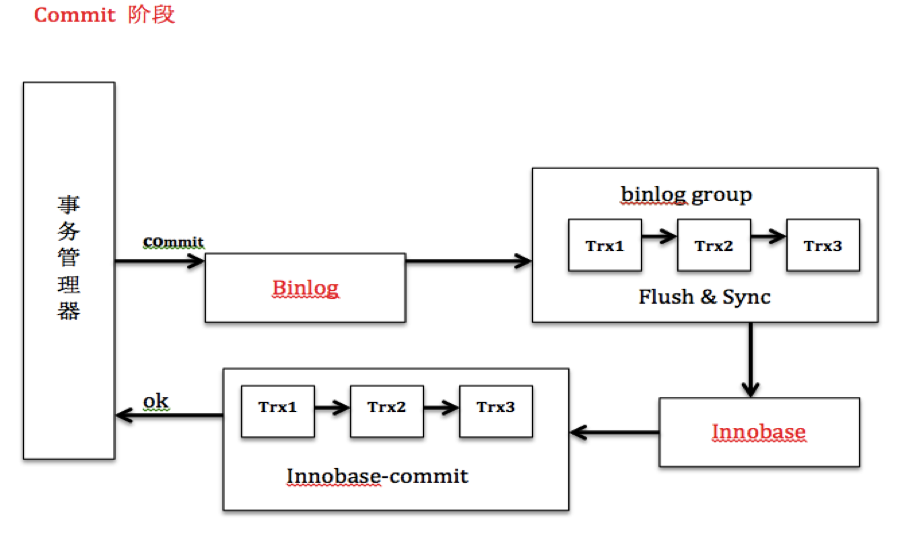
дёӨйҳ¶ж®өжҸҗдәӨ
еңЁеҚ•жңәжғ…еҶөдёӢпјҢredo logз»„жҸҗдәӨеҫҲеҘҪең°и§ЈеҶідәҶж—Ҙеҝ—иҗҪзӣҳй—®йўҳпјҢйӮЈд№ҲејҖеҗҜbinlogеҗҺпјҢbinlogиғҪеҗҰе’Ңredo logдёҖж ·д№ҹејҖеҗҜз»„жҸҗдәӨпјҹйҰ–е…ҲејҖеҗҜbinlogеҗҺпјҢжҲ‘们иҰҒи§ЈеҶізҡ„дёҖдёӘй—®йўҳжҳҜпјҢеҰӮдҪ•дҝқиҜҒbinlogе’Ңredo logзҡ„дёҖиҮҙжҖ§гҖӮеӣ дёәbinlogжҳҜMaster-Slaveзҡ„жЎҘжўҒпјҢеҰӮжһңйЎәеәҸдёҚдёҖиҮҙпјҢж„Ҹе‘ізқҖMaster-SlaveеҸҜиғҪдёҚдёҖиҮҙгҖӮMYSQLйҖҡиҝҮдёӨйҳ¶ж®өжҸҗдәӨеҫҲеҘҪең°и§ЈеҶідәҶиҝҷдёҖй—®йўҳгҖӮPrepareйҳ¶ж®өпјҢinnodbеҲ·redo logпјҢ并е°Ҷеӣһж»ҡж®өи®ҫзҪ®дёәPreparedзҠ¶жҖҒпјҢbinlogдёҚдҪңд»»дҪ•ж“ҚдҪңпјӣcommitйҳ¶ж®өпјҢinnodbйҮҠж”ҫй”ҒпјҢйҮҠж”ҫеӣһж»ҡж®өпјҢи®ҫзҪ®жҸҗдәӨзҠ¶жҖҒпјҢbinlogеҲ·binlogж—Ҙеҝ—гҖӮеҮәзҺ°ејӮеёёпјҢйңҖиҰҒж•…йҡңжҒўеӨҚж—¶пјҢиӢҘеҸ‘зҺ°дәӢеҠЎеӨ„дәҺPrepareйҳ¶ж®өпјҢ并且binlogеӯҳеңЁеҲҷжҸҗдәӨпјҢеҗҰеҲҷеӣһж»ҡгҖӮйҖҡиҝҮдёӨйҳ¶ж®өжҸҗдәӨпјҢдҝқиҜҒдәҶredo logе’ҢbinlogеңЁд»»дҪ•жғ…еҶөдёӢзҡ„дёҖиҮҙжҖ§гҖӮ
binlogзҡ„з»„жҸҗдәӨ
еӣһеҲ°дёҠиҠӮзҡ„й—®йўҳпјҢејҖеҗҜbinlogеҗҺпјҢеҰӮдҪ•еңЁдҝқиҜҒredo log-binlogдёҖиҮҙзҡ„еҹәзЎҖдёҠпјҢе®һзҺ°з»„жҸҗдәӨгҖӮеӣ дёәиҝҷдёӘй—®йўҳпјҢ5.6д»ҘеүҚпјҢmysqlеңЁејҖеҗҜbinlogзҡ„жғ…еҶөдёӢпјҢж— жі•е®һзҺ°з»„жҸҗдәӨпјҢйҖҡиҝҮдёҖдёӘиҮӯеҗҚжҳӯи‘—зҡ„prepare_commit_mutexпјҢе°Ҷredo logе’ҢbinlogеҲ·зӣҳдёІиЎҢеҢ–пјҢдёІиЎҢеҢ–зҡ„зӣ®зҡ„д№ҹд»…д»…жҳҜдёәдәҶдҝқиҜҒredo log-BinlogдёҖиҮҙпјҢдҪҶиҝҷз§Қе®һзҺ°ж–№ејҸзүәзүІдәҶжҖ§иғҪгҖӮиҝҷдёӘжғ…еҶөжҳҫ然жҳҜдёҚиғҪе®№еҝҚзҡ„пјҢеӣ жӯӨеҗ„дёӘmysqlеҲҶж”ҜпјҢmariadbпјҢfacebookпјҢperconalзӯүзӣёз»§еҮәдәҶиЎҘдёҒж”№иҝӣиҝҷдёҖй—®йўҳпјҢmysqlе®ҳж–№зүҲжң¬5.6д№ҹз»ҲдәҺи§ЈеҶідәҶиҝҷдёҖй—®йўҳгҖӮз”ұдәҺеҗ„дёӘеҲҶж”ҜзүҲжң¬и§ЈеҶіж–№жі•зұ»дјјпјҢжҲ‘дё»иҰҒйҖҡиҝҮеҲҶжһҗ5.6зҡ„е®һзҺ°жқҘиҜҙжҳҺе®һзҺ°ж–№жі•гҖӮ
binlogз»„жҸҗдәӨзҡ„еҹәжң¬жҖқжғіжҳҜпјҢеј•е…ҘйҳҹеҲ—жңәеҲ¶дҝқиҜҒinnodb commitйЎәеәҸдёҺbinlogиҗҪзӣҳйЎәеәҸдёҖиҮҙпјҢ并е°ҶдәӢеҠЎеҲҶз»„пјҢз»„еҶ…зҡ„binlogеҲ·зӣҳеҠЁдҪңдәӨз»ҷдёҖдёӘдәӢеҠЎиҝӣиЎҢпјҢе®һзҺ°з»„жҸҗдәӨзӣ®зҡ„гҖӮbinlogжҸҗдәӨе°ҶжҸҗдәӨеҲҶдёәдәҶ3дёӘйҳ¶ж®өпјҢFLUSHйҳ¶ж®өпјҢSYNCйҳ¶ж®өе’ҢCOMMITйҳ¶ж®өгҖӮжҜҸдёӘйҳ¶ж®өйғҪжңүдёҖдёӘйҳҹеҲ—пјҢжҜҸдёӘйҳҹеҲ—жңүдёҖдёӘmutexдҝқжҠӨпјҢзәҰе®ҡиҝӣе…ҘйҳҹеҲ—第дёҖдёӘзәҝзЁӢдёәleaderпјҢе…¶д»–зәҝзЁӢдёәfollowerпјҢжүҖжңүдәӢжғ…дәӨз”ұleaderеҺ»еҒҡпјҢleaderеҒҡе®ҢжүҖжңүеҠЁдҪңеҗҺпјҢйҖҡзҹҘfollowerеҲ·зӣҳз»“жқҹгҖӮbinlogз»„жҸҗдәӨеҹәжң¬жөҒзЁӢеҰӮдёӢпјҡ
FLUSH йҳ¶ж®ө
1) жҢҒжңүLock_log mutex [leaderжҢҒжңүпјҢfollowerзӯүеҫ…]
2) иҺ·еҸ–йҳҹеҲ—дёӯзҡ„дёҖз»„binlog(йҳҹеҲ—дёӯзҡ„жүҖжңүдәӢеҠЎ)
3) е°Ҷbinlog bufferеҲ°I/O cache
4) йҖҡзҹҘdumpзәҝзЁӢdump binlog
SYNCйҳ¶ж®ө
1) йҮҠж”ҫLock_log mutexпјҢжҢҒжңүLock_sync mutex[leaderжҢҒжңүпјҢfollowerзӯүеҫ…]
2) е°ҶдёҖз»„binlog иҗҪзӣҳ(syncеҠЁдҪңпјҢжңҖиҖ—ж—¶пјҢеҒҮи®ҫsync_binlogдёә1)
COMMITйҳ¶ж®ө
1) йҮҠж”ҫLock_sync mutexпјҢжҢҒжңүLock_commit mutex[leaderжҢҒжңүпјҢfollowerзӯүеҫ…]
2) йҒҚеҺҶйҳҹеҲ—дёӯзҡ„дәӢеҠЎпјҢйҖҗдёҖиҝӣиЎҢinnodb commit
3) йҮҠж”ҫLock_commit mutex
4) е”ӨйҶ’йҳҹеҲ—дёӯзӯүеҫ…зҡ„зәҝзЁӢ
иҜҙжҳҺпјҡз”ұдәҺжңүеӨҡдёӘйҳҹеҲ—пјҢжҜҸдёӘйҳҹеҲ—еҗ„иҮӘжңүmutexдҝқжҠӨпјҢйҳҹеҲ—д№Ӣй—ҙжҳҜйЎәеәҸзҡ„пјҢзәҰе®ҡиҝӣе…ҘйҳҹеҲ—зҡ„дёҖдёӘзәҝзЁӢдёәleaderпјҢеӣ жӯӨFLUSHйҳ¶ж®өзҡ„leaderеҸҜиғҪжҳҜSYNCйҳ¶ж®өзҡ„followerпјҢдҪҶжҳҜfollowerж°ёиҝңжҳҜfollowerгҖӮ
йҖҡиҝҮдёҠж–ҮеҲҶжһҗпјҢжҲ‘们зҹҘйҒ“MYSQLзӣ®еүҚзҡ„з»„жҸҗдәӨж–№ејҸи§ЈеҶідәҶдёҖиҮҙжҖ§е’ҢжҖ§иғҪзҡ„й—®йўҳгҖӮйҖҡиҝҮдәҢйҳ¶ж®өжҸҗдәӨи§ЈеҶідёҖиҮҙжҖ§пјҢйҖҡиҝҮredo logе’Ңbinlogзҡ„з»„жҸҗдәӨи§ЈеҶізЈҒзӣҳIOзҡ„жҖ§иғҪгҖӮдёӢйқўжҲ‘ж•ҙзҗҶдәҶPrepareйҳ¶ж®өе’ҢCommitйҳ¶ж®өзҡ„жЎҶжһ¶еӣҫдҫӣеҗ„дҪҚеҸӮиҖғгҖӮ
еҸӮиҖғж–ҮжЎЈ
http://mysqlmusings.blogspot.com/2012/06/binary-log-group-commit-in-mysql-56.html
http://www.lupaworld.com/portal.php?mod=view&aid=250169&page=all
http://www.oschina.net/question/12_89981
http://kristiannielsen.livejournal.com/12254.html
http://blog.chinaunix.net/uid-26896862-id-3432594.html
http://www.csdn.net/article/2015-01-16/2823591
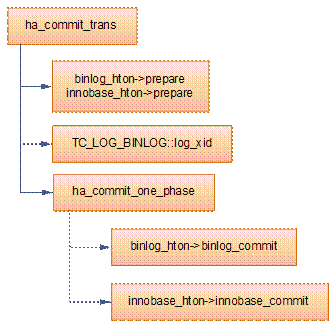
MySQLзҡ„дәӢеҠЎжҸҗдәӨйҖ»иҫ‘дё»иҰҒеңЁеҮҪж•°ha_commit_transдёӯе®ҢжҲҗгҖӮдәӢеҠЎзҡ„жҸҗдәӨж¶үеҸҠеҲ°binlogеҸҠе…·дҪ“зҡ„еӯҳеӮЁзҡ„еј•ж“Һзҡ„дәӢеҠЎжҸҗдәӨгҖӮжүҖд»ҘMySQLз”Ё2PCжқҘдҝқиҜҒзҡ„дәӢеҠЎзҡ„е®Ңж•ҙжҖ§гҖӮMySQLзҡ„2PCиҝҮзЁӢеҰӮдёӢпјҡ

T@4 : | | | | >trans_commit T@4 : | | | | | enter: stmt.ha_list: , all.ha_list: T@4 : | | | | | debug: stmt.unsafe_rollback_flags: T@4 : | | | | | debug: all.unsafe_rollback_flags: T@4 : | | | | | >trans_check T@4 : | | | | | <trans_check 49 T@4 : | | | | | info: clearing SERVER_STATUS_IN_TRANS T@4 : | | | | | >ha_commit_trans T@4 : | | | | | | info: all=1 thd->in_sub_stmt=0 ha_info=0x0 is_real_trans=1 T@4 : | | | | | | >MYSQL_BIN_LOG::commit T@4 : | | | | | | | enter: thd: 0x2b9f4c07beb0, all: yes, xid: 0, cache_mngr: 0x0 T@4 : | | | | | | | >ha_commit_low T@4 : | | | | | | | | >THD::st_transaction::cleanup T@4 : | | | | | | | | | >free_root T@4 : | | | | | | | | | | enter: root: 0x2b9f4c07d660 flags: 1 T@4 : | | | | | | | | | <free_root 396 T@4 : | | | | | | | | <thd::st_transaction::cleanup 2521 T@4 : | | | | | | | <ha_commit_low 1535 T@4 : | | | | | | <mysql_bin_log::commit 6383 T@4 : | | | | | | >THD::st_transaction::cleanup T@4 : | | | | | | | >free_root T@4 : | | | | | | | | enter: root: 0x2b9f4c07d660 flags: 1 T@4 : | | | | | | | <free_root 396 T@4 : | | | | | | <thd::st_transaction::cleanup 2521 T@4 : | | | | | <ha_commit_trans 1458 T@4 : | | | | | debug: reset_unsafe_rollback_flags T@4 : | | | | <trans_commit 233</ha_commit_trans<> T@4 : | | | | >MDL_context::release_transactional_locks T@4 : | | | | | >MDL_context::release_locks_stored_before T@4 : | | | | | <mdl_context::release_locks_stored_before 2771 T@4 : | | | | | >MDL_context::release_locks_stored_before T@4 : | | | | | <mdl_context::release_locks_stored_before 2771 T@4 : | | | | <mdl_context::release_transactional_locks 2926 T@4 : | | | | >set_ok_status T@4 : | | | | <set_ok_status 446 T@4 : | | | | THD::enter_stage: /usr/src/mysql-5.6.28/sql/sql_parse.cc:4996 T@4 : | | | | >PROFILING::status_change T@4 : | | | | <profiling::status_change 354 T@4 : | | | | >trans_commit_stmt T@4 : | | | | | enter: stmt.ha_list: , all.ha_list: T@4 : | | | | | enter: stmt.ha_list: , all.ha_list: T@4 : | | | | | debug: stmt.unsafe_rollback_flags: T@4 : | | | | | debug: all.unsafe_rollback_flags: T@4 : | | | | | debug: add_unsafe_rollback_flags: 0 T@4 : | | | | | >MYSQL_BIN_LOG::commit
(1)е…Ҳи°ғз”Ёbinglog_htonе’Ңinnobase_htonзҡ„prepareж–№жі•е®ҢжҲҗ第дёҖйҳ¶ж®өпјҢbinlog_htonзҡ„papareж–№жі•е®һйҷ…дёҠд»Җд№Ҳд№ҹжІЎеҒҡпјҢinnodbзҡ„prepareе°ҶдәӢеҠЎзҠ¶жҖҒи®ҫдёәTRX_PREPAREDпјҢ并е°Ҷredo logеҲ·зЈҒзӣҳ (innobase_xa_prepare Г trx_prepare_for_mysql Г trx_prepare_off_kernel)гҖӮ
(2)еҰӮжһңдәӢеҠЎж¶үеҸҠзҡ„жүҖжңүеӯҳеӮЁеј•ж“Һзҡ„prepareйғҪжү§иЎҢжҲҗеҠҹпјҢеҲҷи°ғз”ЁTC_LOG_BINLOG::log_xidе°ҶSQLиҜӯеҸҘеҶҷеҲ°binlogпјҢжӯӨж—¶пјҢдәӢеҠЎе·Із»Ҹй“Ғе®ҡиҰҒжҸҗдәӨдәҶгҖӮеҗҰеҲҷпјҢи°ғз”Ёha_rollback_transеӣһж»ҡдәӢеҠЎпјҢиҖҢSQLиҜӯеҸҘе®һйҷ…дёҠд№ҹдёҚдјҡеҶҷеҲ°binlogгҖӮ
(3)жңҖеҗҺпјҢи°ғз”Ёеј•ж“Һзҡ„commitе®ҢжҲҗдәӢеҠЎзҡ„жҸҗдәӨгҖӮе®һйҷ…дёҠbinlog_hton->commitд»Җд№Ҳд№ҹдёҚдјҡеҒҡ(еӣ дёә(2)е·Із»Ҹе°ҶbinlogеҶҷе…ҘзЈҒзӣҳ)пјҢinnobase_hton->commitеҲҷжё…йҷӨundoдҝЎжҒҜпјҢеҲ·redoж—Ҙеҝ—пјҢе°ҶдәӢеҠЎи®ҫдёәTRX_NOT_STARTEDзҠ¶жҖҒ(innobase_commit Г innobase_commit_low Г trx_commit_for_mysql Г trx_commit_off_kernel)гҖӮ
//ha_innodb.cc static int innobase_commit( /*============*/ /* out: 0 */ THD* thd, /* in: MySQL thread handle of the user for whom the transaction should be committed */ bool all) /* in: TRUE - commit transaction FALSE - the current SQL statement ended */ { ... trx->mysql_log_file_name = mysql_bin_log.get_log_fname(); trx->mysql_log_offset = (ib_longlong)mysql_bin_log.get_log_file()->pos_in_file; ... } |
еҮҪж•°innobase_commitжҸҗдәӨдәӢеҠЎпјҢе…Ҳеҫ—еҲ°еҪ“еүҚзҡ„binlogзҡ„дҪҚзҪ®пјҢ然еҗҺеҶҚеҶҷе…ҘдәӢеҠЎзі»з»ҹPAGE(trx_commit_off_kernel Г trx_sys_update_mysql_binlog_offset)гҖӮ
InnoDBе°ҶMySQL binlogзҡ„дҪҚзҪ®и®°еҪ•еҲ°trx system headerдёӯпјҡ
//trx0sys.h /* The offset of the MySQL binlog offset info in the trx system header */ #define TRX_SYS_MYSQL_LOG_INFO (UNIV_PAGE_SIZE - 1000) #define TRX_SYS_MYSQL_LOG_MAGIC_N_FLD 0 /* magic number which shows if we have valid data in the MySQL binlog info; the value is ..._MAGIC_N if yes */ #define TRX_SYS_MYSQL_LOG_OFFSET_HIGH 4 /* high 4 bytes of the offset within that file */ #define TRX_SYS_MYSQL_LOG_OFFSET_LOW 8 /* low 4 bytes of the offset within that file */ #define TRX_SYS_MYSQL_LOG_NAME 12 /* MySQL log file name */ |
5.3.2 дәӢеҠЎжҒўеӨҚжөҒзЁӢ
InnodbеңЁжҒўеӨҚзҡ„ж—¶еҖҷпјҢдёҚеҗҢзҠ¶жҖҒзҡ„дәӢеҠЎпјҢдјҡиҝӣиЎҢдёҚеҗҢзҡ„еӨ„зҗҶ(и§Ғtrx_rollback_or_clean_all_without_sessеҮҪж•°)пјҡ
<1>еҜ№дәҺTRX_COMMITTED_IN_MEMORYзҡ„дәӢеҠЎпјҢжё…йҷӨеӣһж»ҡж®өпјҢ然еҗҺе°ҶдәӢеҠЎи®ҫдёәTRX_NOT_STARTEDпјӣ
<2>еҜ№дәҺTRX_NOT_STARTEDзҡ„дәӢеҠЎпјҢиЎЁзӨәдәӢеҠЎе·Із»ҸжҸҗдәӨпјҢи·іиҝҮпјӣ
<3>еҜ№дәҺTRX_PREPAREDзҡ„дәӢеҠЎпјҢиҰҒж №жҚ®binlogжқҘеҶіе®ҡдәӢеҠЎзҡ„е‘ҪиҝҗпјҢжҡӮж—¶и·іиҝҮ;
<4>еҜ№дәҺTRX_ACTIVEзҡ„дәӢеҠЎпјҢеӣһж»ҡгҖӮ
MySQLеңЁжү“ејҖbinlogж—¶пјҢдјҡжЈҖжҹҘbinlogзҡ„зҠ¶жҖҒ(TC_LOG_BINLOG::open)гҖӮеҰӮжһңbinlogжІЎжңүжӯЈеёёе…ій—ӯ(LOG_EVENT_BINLOG_IN_USE_Fдёә1)пјҢеҲҷиҝӣиЎҢжҒўеӨҚж“ҚдҪңпјҢеҹәжң¬жөҒзЁӢеҰӮдёӢпјҡ
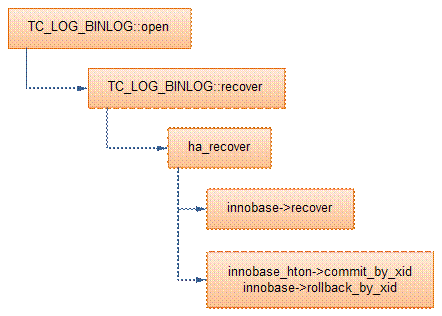
<1>жү«жҸҸbinlogпјҢиҜ»еҸ–XID_EVENTдәӢеҠЎпјҢеҫ—еҲ°жүҖжңүе·Із»ҸжҸҗдәӨзҡ„XAдәӢеҠЎеҲ—иЎЁ(е®һйҷ…дёҠдәӢеҠЎеңЁinnodbеҸҜиғҪеӨ„дәҺprepareжҲ–иҖ…commit)пјӣ
<2>еҜ№жҜҸдёӘXAдәӢеҠЎпјҢи°ғз”Ёhandlerton::recoverпјҢжЈҖжҹҘеӯҳеӮЁеј•ж“ҺжҳҜеҗҰеӯҳеңЁеӨ„дәҺprepareзҠ¶жҖҒзҡ„иҜҘдәӢеҠЎ(и§Ғinnobase_xa_recover)пјҢд№ҹе°ұжҳҜжЈҖжҹҘиҜҘXAдәӢеҠЎеңЁеӯҳеӮЁеј•ж“Һдёӯзҡ„зҠ¶жҖҒпјӣ
<3>еҰӮжһңеӯҳеңЁеӨ„дәҺprepareзҠ¶жҖҒзҡ„иҜҘXAдәӢеҠЎпјҢеҲҷи°ғз”Ёhandlerton::commit_by_xidжҸҗдәӨдәӢеҠЎпјӣ
<4>еҗҰеҲҷпјҢи°ғз”Ёhandlerton::rollback_by_xidеӣһж»ҡXAдәӢеҠЎгҖӮ
5.3.3 еҮ дёӘеҸӮж•°и®Ёи®ә
(1)sync_binlog
MysqlеңЁжҸҗдәӨдәӢеҠЎж—¶и°ғз”ЁMYSQL_LOG::writeе®ҢжҲҗеҶҷbinlogпјҢе№¶ж №жҚ®sync_binlogеҶіе®ҡжҳҜеҗҰиҝӣиЎҢеҲ·зӣҳгҖӮй»ҳи®ӨеҖјжҳҜ0пјҢеҚідёҚеҲ·зӣҳпјҢд»ҺиҖҢжҠҠжҺ§еҲ¶жқғи®©з»ҷOSгҖӮеҰӮжһңи®ҫдёә1пјҢеҲҷжҜҸж¬ЎжҸҗдәӨдәӢеҠЎпјҢе°ұдјҡиҝӣиЎҢдёҖж¬ЎеҲ·зӣҳпјӣиҝҷеҜ№жҖ§иғҪжңүеҪұе“Қ(5.6е·Із»Ҹж”ҜжҢҒbinlog group)пјҢжүҖд»ҘеҫҲеӨҡдәәе°Ҷе…¶и®ҫзҪ®дёә100гҖӮ
bool MYSQL_LOG::flush_and_sync()
{
int err=0, fd=log_file.file;
safe_mutex_assert_owner(&LOCK_log);
if (flush_io_cache(&log_file))
return 1;
if (++sync_binlog_counter >= sync_binlog_period && sync_binlog_period)
{
sync_binlog_counter= 0;
err=my_sync(fd, MYF(MY_WME));
}
return err;
}
(2) innodb_flush_log_at_trx_commit
иҜҘеҸӮж•°жҺ§еҲ¶innodbеңЁжҸҗдәӨдәӢеҠЎж—¶еҲ·redo logзҡ„иЎҢдёәгҖӮй»ҳи®ӨеҖјдёә1пјҢеҚіжҜҸж¬ЎжҸҗдәӨдәӢеҠЎпјҢйғҪиҝӣиЎҢеҲ·зӣҳж“ҚдҪңгҖӮдёәдәҶйҷҚдҪҺеҜ№жҖ§иғҪзҡ„еҪұе“ҚпјҢеңЁеҫҲеӨҡз”ҹдә§зҺҜеўғи®ҫзҪ®дёә2пјҢз”ҡиҮі0гҖӮ
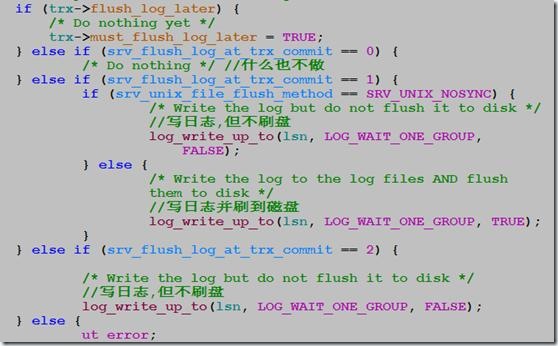
trx_flush_log_if_needed_low( /*========================*/ lsn_t lsn) /*!< in: lsn up to which logs are to be
flushed. */ { switch (srv_flush_log_at_trx_commit) { case 0: /* Do nothing */ break; case 1: /* Write the log and optionally flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP,
srv_unix_file_flush_method != SRV_UNIX_NOSYNC); break; case 2: /* Write the log but do not flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE); break; default:
ut_error;
}
}
If the value of innodb_flush_log_at_trx_commit is 0, the log buffer is written out to the log file once per second and the flush to disk operation is performed on the log file, but nothing is done at a transaction commit. When the value is 1 (the default), the log buffer is written out to the log file at each transaction commit and the flush to disk operation is performed on the log file. When the value is 2, the log buffer is written out to the file at each commit, but the flush to disk operation is not performed on it. However, the flushing on the log file takes place once per second also when the value is 2. Note that the once-per-second flushing is not 100% guaranteed to happen every second, due to process scheduling issues.
The default value of 1 is required for full ACID compliance. You can achieve better performance by setting the value different from 1, but then you can lose up to one second worth of transactions in a crash. With a value of 0, any mysqld process crash can erase the last second of transactions. With a value of 2, only an operating system crash or a power outage can erase the last second of transactions.
(3) innodb_support_xa
з”ЁдәҺжҺ§еҲ¶innodbжҳҜеҗҰж”ҜжҢҒXAдәӢеҠЎзҡ„2PCпјҢй»ҳи®ӨжҳҜTRUEгҖӮеҰӮжһңе…ій—ӯпјҢеҲҷinnodbеңЁprepareйҳ¶ж®өе°ұд»Җд№Ҳд№ҹдёҚеҒҡпјӣиҝҷеҸҜиғҪдјҡеҜјиҮҙbinlogзҡ„йЎәеәҸдёҺinnodbжҸҗдәӨзҡ„йЎәеәҸдёҚдёҖиҮҙ(жҜ”еҰӮAдәӢеҠЎжҜ”BдәӢеҠЎе…ҲеҶҷbinlogпјҢдҪҶжҳҜеңЁinnodbеҶ…йғЁеҚҙеҸҜиғҪAдәӢеҠЎжҜ”BдәӢеҠЎеҗҺжҸҗдәӨ)пјҢиҝҷдјҡеҜјиҮҙеңЁжҒўеӨҚжҲ–иҖ…slaveдә§з”ҹдёҚеҗҢзҡ„ж•°жҚ®гҖӮ
int
innobase_xa_prepare(
/*================*/
/* out: 0 or error number */
THD* thd, /* in: handle to the MySQL thread of the user
whose XA transaction should be prepared */
bool all) /* in: TRUE - commit transaction
FALSE - the current SQL statement ended */
{
вҖҰ
if (!thd->variables.innodb_support_xa) {
return(0);
}
ver mysql 5.7
bool trans_xa_commit(THD *thd)
{ bool res= TRUE; enum xa_states xa_state= thd->transaction.xid_state.xa_state;
DBUG_ENTER("trans_xa_commit"); if (!thd->transaction.xid_state.xid.eq(thd->lex->xid))
{ /* xid_state.in_thd is always true beside of xa recovery procedure.
Note, that there is no race condition here between xid_cache_search
and xid_cache_delete, since we always delete our own XID
(thd->lex->xid == thd->transaction.xid_state.xid).
The only case when thd->lex->xid != thd->transaction.xid_state.xid
and xid_state->in_thd == 0 is in the function
xa_cache_insert(XID, xa_states), which is called before starting
client connections, and thus is always single-threaded. */ XID_STATE *xs= xid_cache_search(thd->lex->xid);
res= !xs || xs->in_thd; if (res)
my_error(ER_XAER_NOTA, MYF(0)); else {
res= xa_trans_rolled_back(xs);
ha_commit_or_rollback_by_xid(thd, thd->lex->xid, !res);
xid_cache_delete(xs);
}
DBUG_RETURN(res);
} if (xa_trans_rolled_back(&thd->transaction.xid_state))
{
xa_trans_force_rollback(thd);
res= thd->is_error();
} else if (xa_state == XA_IDLE && thd->lex->xa_opt == XA_ONE_PHASE)
{ int r= ha_commit_trans(thd, TRUE); if ((res= MY_TEST(r)))
my_error(r == 1 ? ER_XA_RBROLLBACK : ER_XAER_RMERR, MYF(0));
} else if (xa_state == XA_PREPARED && thd->lex->xa_opt == XA_NONE)
{
MDL_request mdl_request; /* Acquire metadata lock which will ensure that COMMIT is blocked
by active FLUSH TABLES WITH READ LOCK (and vice versa COMMIT in
progress blocks FTWRL).
We allow FLUSHer to COMMIT; we assume FLUSHer knows what it does. */ mdl_request.init(MDL_key::COMMIT, "", "", MDL_INTENTION_EXCLUSIVE,
MDL_TRANSACTION); if (thd->mdl_context.acquire_lock(&mdl_request,
thd->variables.lock_wait_timeout))
{
ha_rollback_trans(thd, TRUE);
my_error(ER_XAER_RMERR, MYF(0));
} else {
DEBUG_SYNC(thd, "trans_xa_commit_after_acquire_commit_lock"); if (tc_log)
res= MY_TEST(tc_log->commit(thd, /* all */ true)); else res= MY_TEST(ha_commit_low(thd, /* all */ true)); if (res)
my_error(ER_XAER_RMERR, MYF(0));
}
} else {
my_error(ER_XAER_RMFAIL, MYF(0), xa_state_names[xa_state]);
DBUG_RETURN(TRUE);
}
thd->variables.option_bits&= ~OPTION_BEGIN;
thd->transaction.all.reset_unsafe_rollback_flags();
thd->server_status&=
~(SERVER_STATUS_IN_TRANS | SERVER_STATUS_IN_TRANS_READONLY);
DBUG_PRINT("info", ("clearing SERVER_STATUS_IN_TRANS"));
xid_cache_delete(&thd->transaction.xid_state);
thd->transaction.xid_state.xa_state= XA_NOTR;
DBUG_RETURN(res);
}
5.3.4 е®үе…ЁжҖ§/жҖ§иғҪи®Ёи®ә
дёҠйқў3дёӘеҸӮж•°дёҚеҗҢзҡ„еҖјдјҡеёҰжқҘдёҚеҗҢзҡ„ж•ҲжһңгҖӮдёүиҖ…йғҪи®ҫзҪ®дёә1(TRUE)пјҢж•°жҚ®жүҚиғҪзңҹжӯЈе®үе…ЁгҖӮsync_binlogйқһ1пјҢеҸҜиғҪеҜјиҮҙbinlogдёўеӨұ(OSжҢӮжҺү)пјҢд»ҺиҖҢдёҺinnodbеұӮйқўзҡ„ж•°жҚ®дёҚдёҖиҮҙгҖӮinnodb_flush_log_at_trx_commitйқһ1пјҢеҸҜиғҪдјҡеҜјиҮҙinnodbеұӮйқўзҡ„ж•°жҚ®дёўеӨұ(OSжҢӮжҺү)пјҢд»ҺиҖҢдёҺbinlogдёҚдёҖиҮҙгҖӮ
е…ідәҺжҖ§иғҪеҲҶжһҗпјҢеҸҜд»ҘеҸӮиҖғ
http://www.mysqlperformanceblog.com/2011/03/02/what-is-innodb_support_xa/
http://www.mysqlperformanceblog.com/2009/01/21/beware-ext3-and-sync-binlog-do-not-play-well-together/
еңЁдәӢеҠЎжҸҗдәӨж—¶innobaseдјҡи°ғз”Ёha_innodb.cc дёӯзҡ„innobase_commitпјҢиҖҢinnobase_commitйҖҡиҝҮи°ғз”Ёtrx_commit_complete_for_mysqlпјҲtrx0trx.c)жқҘи°ғз”Ёlog_write_up_toпјҲlog0log.c),д№ҹе°ұжҳҜеҪ“innobaseжҸҗдәӨдәӢеҠЎзҡ„ж—¶еҖҷе°ұдјҡи°ғз”Ёlog_write_up_toжқҘеҶҷredo log
innobase_commitдёӯ if (all # еҰӮжһңжҳҜдәӢеҠЎжҸҗдәӨ || (!thd_test_options(thd, OPTION_NOT_AUTOCOMMIT | OPTION_BEGIN))) {
йҖҡиҝҮдёӢйқўзҡ„д»Јз Ғе®һзҺ°дәӢеҠЎзҡ„commitдёІиЎҢеҢ– if (innobase_commit_concurrency > 0) {
pthread_mutex_lock(&commit_cond_m);
commit_threads++; if (commit_threads > innobase_commit_concurrency) {
commit_threads--;
pthread_cond_wait(&commit_cond, &commit_cond_m);
pthread_mutex_unlock(&commit_cond_m); goto retry;
} else {
pthread_mutex_unlock(&commit_cond_m);
}
}
trx->flush_log_later = TRUE; # еңЁеҒҡжҸҗдәӨж“ҚдҪңж—¶зҰҒжӯўflush binlog еҲ°зЈҒзӣҳ
innobase_commit_low(trx);
trx->flush_log_later = FALSE;
е…Ҳз•ҘиҝҮinnobase_commit_lowи°ғз”Ё ,дёӢйқўејҖе§Ӣи°ғз”Ёtrx_commit_complete_for_mysqlеҒҡwriteж—Ҙеҝ—ж“ҚдҪң
trx_commit_complete_for_mysql(trx); #ејҖе§Ӣflush log
trx->active_trans = 0;
еңЁtrx_commit_complete_for_mysqlдёӯпјҢдё»иҰҒеҒҡзҡ„жҳҜеҜ№зі»з»ҹеҸӮж•°srv_flush_log_at_trx_commitеҖјеҒҡеҲӨж–ӯжқҘи°ғз”Ё
log_write_up_toпјҢжҲ–иҖ…write redo log fileжҲ–иҖ…write&&flush to disk if (!trx->must_flush_log_later) { /* Do nothing */ } else if (srv_flush_log_at_trx_commit == 0) { #flush_log_at_trx_commit=0пјҢдәӢеҠЎжҸҗдәӨдёҚеҶҷredo log /* Do nothing */ } else if (srv_flush_log_at_trx_commit == 1) { #flush_log_at_trx_commit=1,дәӢеҠЎжҸҗдәӨеҶҷlog并flushзЈҒзӣҳ,еҰӮжһңflushж–№ејҸдёҚжҳҜSRV_UNIX_NOSYNC пјҲиҝҷдёӘдёҚжҳҜеҫҲзҶҹжӮүпјү if (srv_unix_file_flush_method == SRV_UNIX_NOSYNC) { /* Write the log but do not flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE);
} else { /* Write the log to the log files AND flush them to
disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, TRUE);
}
} else if (srv_flush_log_at_trx_commit == 2) { #еҰӮжһңжҳҜ2пјҢеҲҷеҸӘwriteеҲ°redo log /* Write the log but do not flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE);
} else {
ut_error;
}
йӮЈд№ҲдёӢйқўзңӢlog_write_up_to if (flush_to_disk #еҰӮжһңflushеҲ°зЈҒзӣҳпјҢеҲҷжҜ”иҫғеҪ“еүҚcommitзҡ„lsnжҳҜеҗҰеӨ§дәҺе·Із»ҸflushеҲ°зЈҒзӣҳзҡ„lsn && ut_dulint_cmp(log_sys->flushed_to_disk_lsn, lsn) >= 0) {
mutex_exit(&(log_sys->mutex)); return;
} if (!flush_to_disk #еҰӮжһңдёҚflushзЈҒзӣҳеҲҷжҜ”иҫғеҪ“еүҚcommitзҡ„lsnжҳҜеҗҰеӨ§дәҺе·Із»ҸеҶҷеҲ°жүҖжңүredo log fileзҡ„lsn,жҲ–иҖ…еңЁеҸӘзӯүдёҖдёӘgroupе®ҢжҲҗжқЎд»¶дёӢжҳҜеҗҰеӨ§дәҺе·Із»ҸеҶҷеҲ°жҹҗдёӘredo fileзҡ„lsn && (ut_dulint_cmp(log_sys->written_to_all_lsn, lsn) >= 0 || (ut_dulint_cmp(log_sys->written_to_some_lsn, lsn) >= 0 && wait != LOG_WAIT_ALL_GROUPS))) {
mutex_exit(&(log_sys->mutex)); return;
}
#дёӢйқўзҡ„д»Јз ҒеҲӨж–ӯжҳҜеҗҰlogеңЁwrite,жңүзҡ„иҜқзӯүеҫ…е…¶е®ҢжҲҗ if (log_sys->n_pending_writes > 0) { if (flush_to_disk # еҰӮжһңйңҖиҰҒеҲ·ж–°еҲ°зЈҒзӣҳпјҢеҰӮжһңжӯЈеңЁflushзҡ„lsnеҢ…жӢ¬дәҶcommitзҡ„lsnпјҢеҸӘиҰҒзӯүеҫ…ж“ҚдҪңе®ҢжҲҗе°ұеҸҜд»ҘдәҶ && ut_dulint_cmp(log_sys->current_flush_lsn, lsn) >= 0) { goto do_waits;
} if (!flush_to_disk # еҰӮжһңжҳҜеҲ·еҲ°redo log fileзҡ„йӮЈд№ҲеҰӮжһңеңЁwriteзҡ„lsnеҢ…жӢ¬дәҶcommitзҡ„lsn,д№ҹеҸӘиҰҒзӯүеҫ…е°ұеҸҜд»ҘдәҶ && ut_dulint_cmp(log_sys->write_lsn, lsn) >= 0) { goto do_waits;
}
...... if (!flush_to_disk # еҰӮжһңеңЁеҪ“еүҚIOз©әй—Іжғ…еҶөдёӢ пјҢиҖҢдё”дёҚйңҖиҰҒflushеҲ°зЈҒзӣҳпјҢйӮЈд№Ҳ еҰӮжһңдёӢж¬ЎеҶҷзҡ„дҪҚзҪ®е·Із»ҸеҲ°иҫҫbuf_freeдҪҚзҪ®иҜҙжҳҺwirteж“ҚдҪңйғҪе·Із»Ҹе®ҢжҲҗдәҶпјҢзӣҙжҺҘиҝ”еӣһ && log_sys->buf_free == log_sys->buf_next_to_write) {
mutex_exit(&(log_sys->mutex)); return;
}
дёӢйқўеҸ–еҲ°group,и®ҫзҪ®зӣёе…іwrite or flushзӣёе…іеӯ—ж®өпјҢ并且еҫ—еҲ°иө·е§Ӣе’Ңз»“жқҹдҪҚзҪ®зҡ„blockеҸ·
log_sys->n_pending_writes++;
group = UT_LIST_GET_FIRST(log_sys->log_groups);
group->n_pending_writes++; /* We assume here that we have only
one log group! */ os_event_reset(log_sys->no_flush_event);
os_event_reset(log_sys->one_flushed_event);
start_offset = log_sys->buf_next_to_write;
end_offset = log_sys->buf_free;
area_start = ut_calc_align_down(start_offset, OS_FILE_LOG_BLOCK_SIZE);
area_end = ut_calc_align(end_offset, OS_FILE_LOG_BLOCK_SIZE);
ut_ad(area_end - area_start > 0);
log_sys->write_lsn = log_sys->lsn; if (flush_to_disk) {
log_sys->current_flush_lsn = log_sys->lsn;
}
log_block_set_checkpoint_noи°ғз”Ёи®ҫзҪ®end_offsetжүҖеңЁblockзҡ„LOG_BLOCK_CHECKPOINT_NOдёәlog_sysдёӯдёӢдёӘжЈҖжҹҘзӮ№еҸ·
log_block_set_flush_bit(log_sys->buf + area_start, TRUE); # иҝҷдёӘжІЎзңӢжҳҺзҷҪ
log_block_set_checkpoint_no(
log_sys->buf + area_end - OS_FILE_LOG_BLOCK_SIZE,
log_sys->next_checkpoint_no);
дҝқеӯҳдёҚеұһдәҺend_offsetдҪҶеңЁе…¶жүҖеңЁзҡ„blockдёӯзҡ„ж•°жҚ®еҲ°дёӢдёҖдёӘз©әй—Ізҡ„block
ut_memcpy(log_sys->buf + area_end,
log_sys->buf + area_end - OS_FILE_LOG_BLOCK_SIZE,
OS_FILE_LOG_BLOCK_SIZE);
еҜ№дәҺжҜҸдёӘgroupи°ғз”Ёlog_group_write_bufеҶҷredo log buffer while (group) {
log_group_write_buf(
group, log_sys->buf + area_start,
area_end - area_start,
ut_dulint_align_down(log_sys->written_to_all_lsn,
OS_FILE_LOG_BLOCK_SIZE),
start_offset - area_start);
log_group_set_fields(group, log_sys->write_lsn); # и®Ўз®—иҝҷж¬ЎеҶҷзҡ„lsnе’ҢoffsetжқҘи®ҫзҪ®group->lsnе’Ңgroup->lsn_offset
group = UT_LIST_GET_NEXT(log_groups, group);
}
...... if (srv_unix_file_flush_method == SRV_UNIX_O_DSYNC) { # иҝҷдёӘжҳҜд»Җд№ҲдёңиҘҝ /* O_DSYNC means the OS did not buffer the log file at all:
so we have also flushed to disk what we have written */ log_sys->flushed_to_disk_lsn = log_sys->write_lsn;
} else if (flush_to_disk) {
group = UT_LIST_GET_FIRST(log_sys->log_groups);
fil_flush(group->space_id); # жңҖеҗҺи°ғз”Ёfil_flushжү§иЎҢflushеҲ°зЈҒзӣҳ
log_sys->flushed_to_disk_lsn = log_sys->write_lsn;
}
жҺҘдёӢжқҘзңӢlog_group_write_bufеҒҡдәҶзӮ№д»Җд№Ҳ
еңЁlog_group_calc_size_offsetдёӯ,д»ҺgroupдёӯеҸ–еҲ°дёҠж¬Ўи®°еҪ•зҡ„lsnдҪҚзҪ®пјҲжіЁж„ҸжҳҜlog filesз»„жҲҗзҡ„1дёӘзҺҜзҠ¶buffer),并计算иҝҷж¬Ўзҡ„lsnзӣёеҜ№дәҺдёҠж¬Ўзҡ„е·®еҖј
# и°ғз”Ёlog_group_calc_size_offsetи®Ўз®—group->lsn_offsetйҷӨеҺ»еӨҡдёӘLOG_FILEеӨҙйғЁй•ҝеәҰеҗҺзҡ„еӨ§е°ҸпјҢжҜ”еҰӮlsn_offsetиҗҪеңЁз¬¬3дёӘlog fileдёҠпјҢйӮЈд№ҲйңҖиҰҒеҮҸжҺү3*LOG_FILE_HDR_SIZEзҡ„еӨ§е°Ҹ
gr_lsn_size_offset = (ib_longlong)
log_group_calc_size_offset(group->lsn_offset, group);
group_size = (ib_longlong) log_group_get_capacity(group); # и®Ўз®—groupйҷӨеҺ»жүҖжңүLOG_FILE_HDR_SIZEй•ҝеәҰеҗҺзҡ„DATAйғЁеҲҶеӨ§е°Ҹ
# дёӢйқўжҳҜе…ёеһӢзҡ„зҺҜзҠ¶з»“жһ„е·®еҖји®Ўз®— if (ut_dulint_cmp(lsn, gr_lsn) >= 0) {
difference = (ib_longlong) ut_dulint_minus(lsn, gr_lsn);
} else {
difference = (ib_longlong) ut_dulint_minus(gr_lsn, lsn);
difference = difference % group_size;
difference = group_size - difference;
}
offset = (gr_lsn_size_offset + difference) % group_size;
# жңҖеҗҺз®—дёҠжҜҸдёӘlog file еӨҙйғЁеӨ§е°ҸпјҢиҝ”еӣһзңҹе®һзҡ„offset return(log_group_calc_real_offset((ulint)offset, group));
жҺҘзқҖзңӢ
# еҰӮжһңйңҖиҰҒеҶҷзҡ„еҶ…е®№и¶…иҝҮдёҖдёӘж–Ү件еӨ§е°Ҹ if ((next_offset % group->file_size) + len > group->file_size) {
write_len = group->file_size # еҶҷеҲ°fileжң«е°ҫ - (next_offset % group->file_size);
} else {
write_len = len; # еҗҰиҖ…еҶҷlenдёӘblock
}
# жңҖеҗҺзңҹжӯЈзҡ„еҶ…е®№е°ұжҳҜеҶҷbufferдәҶпјҢеҰӮжһңи·Ёи¶Ҡfileзҡ„иҜқеҸҰеӨ–йңҖиҰҒеҶҷfile log file headйғЁеҲҶ if ((next_offset % group->file_size == LOG_FILE_HDR_SIZE) && write_header) { /* We start to write a new log file instance in the group */ log_group_file_header_flush(group,
next_offset / group->file_size,
start_lsn);
srv_os_log_written+= OS_FILE_LOG_BLOCK_SIZE;
srv_log_writes++;
}
# и°ғз”Ёfil_ioжқҘжү§иЎҢbufferеҶҷ if (log_do_write) {
log_sys->n_log_ios++;
srv_os_log_pending_writes++;
fil_io(OS_FILE_WRITE | OS_FILE_LOG, TRUE, group->space_id,
next_offset / UNIV_PAGE_SIZE,
next_offset % UNIV_PAGE_SIZE, write_len, buf, group);
srv_os_log_pending_writes--;
srv_os_log_written+= write_len;
srv_log_writes++;
然иҖҢжҲ‘们иҖғиҷ‘еҰӮдёӢеәҸеҲ—пјҲCopy from worklogвҖҰпјү
Trx1 ------------P----------C--------------------------------> | Trx2 ----------------P------+---C----------------------------> | | Trx3 -------------------P---+---+-----C----------------------> | | | Trx4 -----------------------+-P-+-----+----C-----------------> | | | | Trx5 -----------------------+---+-P---+----+---C-------------> | | | | | Trx6 -----------------------+---+---P-+----+---+---C----------> | | | | | | Trx7 -----------------------+---+-----+----+---+-P-+--C-------> | | | | | | |
еңЁд№ӢеүҚзҡ„йҖ»иҫ‘дёӯпјҢtrx5 е’Ң trx6жҳҜеҸҜд»Ҙ并еҸ‘жү§иЎҢзҡ„пјҢеӣ дёә他们жӢҘжңүзӣёеҗҢзҡ„еәҸеҲ—еҸ·пјӣTrx4ж— жі•е’ҢTrx5并иЎҢпјҢеӣ дёә他们зҡ„еәҸеҲ—еҸ·дёҚеҗҢгҖӮеҗҢж ·зҡ„trx6е’Ңtrx7д№ҹж— жі•е№¶иЎҢгҖӮеҪ“еҸ‘зҺ°дёҖдёӘж— жі•е№¶еҸ‘зҡ„дәӢеҠЎж—¶пјҢе°ұйңҖиҰҒзӯүеҫ…еүҚйқўзҡ„дәӢеҠЎжү§иЎҢе®ҢжҲҗжүҚиғҪ继з»ӯдёӢеҺ»пјҢиҝҷдјҡеҪұе“ҚеҲ°еӨҮеә“зҡ„TPSгҖӮ
дҪҶжҳҜзҗҶи®әдёҠtrx4еә”иҜҘеҸҜд»Ҙе’Ңtrx5е’Ңtrx6并иЎҢпјҢеӣ дёәtrx4е…ҲдәҺtrx5е’Ңtrx6 prepareпјҢеҰӮжһңtrx5 е’Ңtrx6иғҪиҝӣе…ҘPrepareйҳ¶ж®өпјҢиҜҒжҳҺе…¶е’Ңtrx4жҳҜжІЎжңүеҶІзӘҒзҡ„гҖӮ
и§ЈеҶіж–№жЎҲпјҡ
0.еўһеҠ дёӨдёӘе…ЁеұҖеҸҳйҮҸпјҡ
/* Committed transactions timestamp */
Logical_clock max_committed_transaction;
/* "Prepared" transactions timestamp */
Logical_clock transaction_counter;
жҜҸдёӘдәӢеҠЎеҜ№еә”дёӨдёӘcounterпјҡlast_committed еҸҠ sequence_number
1.жҜҸж¬ЎrotateжҲ–жү“ејҖж–°зҡ„binlogж—¶
MYSQL_BIN_LOG::open_binlog:
max_committed_transaction.update_offset(transaction_counter.get_timestamp());
transaction_counter.update_offset(transaction_counter.get_timestamp());
вҖ”>жӣҙж–°max_committed_transactionе’Ңtransaction_counterзҡ„offsetдёәеҪ“еүҚзҡ„stateеҖјпјҲжҲ–иҖ…иҜҙпјҢдёәдёҠдёӘBinlogж–Ү件жңҖеӨ§зҡ„transaction counterеҖјпјү
2.жҜҸжү§иЎҢдёҖжқЎDMLиҜӯеҸҘе®ҢжҲҗж—¶пјҢжӣҙж–°еҪ“еүҚдјҡиҜқзҡ„last_committed= mysql_bin_log.max_committed_transaction
еҸӮиҖғеҮҪж•°пјҡ binlog_prepare пјҲеҸӮж•°allдёәfalseпјү
3. дәӢеҠЎжҸҗдәӨж—¶пјҢеҶҷе…Ҙbinlogд№ӢеүҚ
binlog_cache_data::flush:
trn_ctx->sequence_number= mysql_bin_log.transaction_counter.step();
е…¶дёӯtransaction_counterйҖ’еўһ1
4.еҶҷе…Ҙbinlog
е°Ҷsequence_number е’Ң last_committedеҶҷе…Ҙbinlog
MYSQL_BIN_LOG::write_gtid
и®°еҪ•binlogж–Ү件зҡ„seq number е’Ңlast committedдјҡеҮҸеҺ»max_committed_transaction.get_offset()пјҢд№ҹе°ұжҳҜиҜҙпјҢжҜҸдёӘBinlogж–Ү件зҡ„еәҸеҲ—еҸ·жҖ»жҳҜд»Һ(last_committed, sequence_number)=(0,1)ејҖе§Ӣ
5.еј•ж“ҺеұӮжҸҗдәӨжҜҸдёӘдәӢеҠЎеүҚжӣҙж–°max_committed_transaction
еҰӮжһңеҪ“еүҚдәӢеҠЎзҡ„sequence_numberеӨ§дәҺmax_committed_transactionпјҢеҲҷжӣҙж–°max_committed_transactionзҡ„еҖј
MYSQL_BIN_LOG::process_commit_stage_queue вҖ“> MYSQL_BIN_LOG::update_max_committed
6.еӨҮеә“并еҸ‘жЈҖжҹҘ
еҮҪж•°пјҡMts_submode_logical_clock::schedule_next_event
еҒҮи®ҫеҲқе§ӢзҠ¶жҖҒдёӢtransaction_counter=1, max_committed_transaction=1пјҢ д»ҘдёҠиҝ°жөҒзЁӢдёәдҫӢпјҢжҜҸдёӘдәӢеҠЎзҡ„<last_committed, sequence_number>еәҸеҲ—дёә:
Trx1 prepare: last_commited = max_committed_transaction = 1;
Trx2 prepare: last_commited = max_committed_transaction = 1;
Trx3 prepare: last_commited = max_committed_transaction = 1;
Trx1 commit: sequence_number=++transaction_counter = 2, (transaction_counter=2, max_committed_transaction=2), write(1,2)
Trx4 prepare: last_commited =max_committed_transaction = 2;
Trx2 commit: sequence_number=++transaction_counter= 3, (transaction_counter=3, max_committed_transaction=3), write(1,3)
Trx5 prepare: last_commited = max_committed_transaction = 3;
Trx6 prepare: last_commited = max_committed_transaction = 3;
Trx3 commit: sequence_number=++transaction_counter= 4, (transaction_counter=4, max_committed_transaction=4), write(1,4)
Trx4 commit: sequence_number=++transaction_counter= 5, (transaction_counter=5, max_committed_transaction=5), write(2, 5)
Trx5 commit: sequence_number=++transaction_counter= 6, (transaction_counter=6, max_committed_transaction=6), write(3, 6)
Trx7 prepare: last_commited = max_committed_transaction = 6;
Trx6 commit: sequence_number=++transaction_counter= 7, (transaction_counter=7, max_committed_transaction=7), write(3, 7)
Trx7 commit: sequence_number=++transaction_counter= 8, (transaction_counter=8, max_committed_transaction=8), write(6, 8)
并еҸ‘规еҲҷпјҡ
еӣ жӯӨдёҠиҝ°еәҸеҲ—дёӯеҸҜд»Ҙ并еҸ‘зҡ„еәҸеҲ—дёәпјҡ
trx1 1вҖҰ..2
trx2 1вҖҰвҖҰвҖҰвҖҰ.3
trx3 1вҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰ.4
trx4 2вҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰ.5
trx5 3вҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰ..6
trx6 3вҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰ7
trx7 6вҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰ..8
еӨҮеә“并иЎҢ规еҲҷпјҡеҪ“еҲҶеҸ‘дёҖдёӘдәӢеҠЎж—¶пјҢе…¶last_committed еәҸеҲ—еҸ·жҜ”еҪ“еүҚжӯЈеңЁжү§иЎҢзҡ„дәӢеҠЎзҡ„жңҖе°Ҹsequence_numberиҰҒе°Ҹж—¶пјҢеҲҷе…Ғи®ёжү§иЎҢгҖӮ
еӣ жӯӨпјҢ
a)trx1жү§иЎҢпјҢlast_commit<2зҡ„еҸҜ并еҸ‘пјҢtrx2, trx3еҸҜ继з»ӯеҲҶеҸ‘жү§иЎҢ
b)trx1жү§иЎҢе®ҢжҲҗеҗҺпјҢlast_commit < 3зҡ„еҸҜд»Ҙжү§иЎҢпјҢ trx4еҸҜеҲҶеҸ‘
c)trx2жү§иЎҢе®ҢжҲҗеҗҺпјҢlast_commit < 4зҡ„еҸҜд»Ҙжү§иЎҢпјҢ trx5, trx6еҸҜеҲҶеҸ‘
d)trx3гҖҒtrx4гҖҒtrx5е®ҢжҲҗеҗҺпјҢlast_commit < 7зҡ„еҸҜд»Ҙжү§иЎҢпјҢtrx7еҸҜеҲҶеҸ‘
е…ідәҺеҰӮдҪ•зҗҶи§ЈMYSQL-GroupCommit е’Ң 2pcжҸҗдәӨе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ