您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
单机的数据库名和实例名都是DB521102, ,恢复到RAC后db_name为DB521102,instance_name分别为DB52110201、DB52110202
经过实验:不管11.2.0.4是直接安装的还是由11.2.0.1升级到11.2.0.4的,都是以下一模一样的方式。
1. 单机必须是spfile启动的,备份数据库(以spfile启动则会自动备份spfile和crontrolfile)和归档日志
Rman>backup databast format ‘/u01/app/rman/full%U.bak’ plus archivelog format ‘/u01/app/rman/arch%U.bak’
2. 把单机的备份拷贝到RAC的随机一台机器testdb01的相同目录/u01/app/rman中
3. 在RAC的testdb01机器上进行单机数据库的恢复
ORACLE_SID=DB521102
rman>startup nomount
rman>restore spfile to pfile '/u01/app/oracle/product/11.2.0/db_1/dbs/initDB521102.ora'
from '/u01/app/rman/full10pu0tdo_1_1.bak ';
以上startup nomount的过程中会出现如下报错,暂时不用管,会正常startup到nomount状态,启动后就可以把pfile定义成报错中的文件信息了
startup failed: ORA-01078: failure in processing system parameters
LRM-00109: could not open parameter file '/u01/app/oracle/product/11.2.0/db_1/dbs/initDB521102.ora'
4. 在RAC的testdb01机器上修改刚刚恢复过来的pfile文件,只留下如下参数信息信息,参数的具体值参考原来RAC的参数值。
但是一些目录必须手工建立,比如在ASM中建立+DATA/DB521102和+ARCH/ DB521102目录,其中本地文件路径必须在所有RAC服务器中都创建,比如*.audit_file_dest='/u01/app/oracle/admin/DB521102/adump'需要在testdb01和testdb02中都建立
*.audit_file_dest='/u01/app/oracle/admin/DB521102/adump'
*.audit_trail='none'
*.compatible='11.2.0.0.0'
*.control_files='+DATA/DB521102/control01.ctl','+ARCH/DB521102/control02.ctl'
*.db_block_size=8192
*.db_create_file_dest='+DATA'
*.db_domain=''
*.db_name='DB521102'
*.db_recovery_file_dest='+ARCH'
*.db_recovery_file_dest_size=4070572032
*.diagnostic_dest='/u01/app/oracle'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=DB521102XDB)'
*.memory_target=1656750080
*.log_archive_dest_1='location=+ARCH'
*.log_archive_format='%t_%s_%r.dbf'
*.open_cursors=300
*.processes=150
*.remote_login_passwordfile='EXCLUSIVE'
5. 在RAC的testdb01机器上创建Spfile到ASM目录,并关闭该DUMMY实例
ORACLE_SID= DB521102
SQL> create spfile ='+DATA/DB521102/spfileDB521102.ora' from pfile='/u01/app/oracle/product/11.2.0/db_1/dbs/initDB521102.ora';
Sql>shutdown abort;
6. 在RAC的testdb01机器上执行
echo "spfile='+DATA/DB521102/spfileDB521102.ora'">/u01/app/oracle/product/11.2.0/db_1/dbs/initDB521102.ora
7. ORACLE_SID=DB521102
在RAC的testdb01机器上 startup nomount数据库,并show parameter spfile查看spfile是否来自ASM
8. 在RAC的testdb01机器上恢复单机的控制文件
Rman> restore controlfile from '/u01/app/rman/full10pu0tdo_1_1.bak';
9. 在RAC的testdb01机器上
Rman>alter database mount;
10.在RAC的testdb01机器上恢复数据文件
RMAN>run{
set newname for datafile 1 to '+DATA/DB521102/system01.dbf';
set newname for datafile 2 to '+DATA/DB521102/sysaux01.dbf';
set newname for datafile 3 to '+DATA/DB521102/undotbs01.dbf';
set newname for datafile 4 to '+DATA/DB521102/users01.dbf';
set newname for tempfile 1 to '+DATA/DB521102/temp01.dbf';
restore database;
switch datafile all;
switch tempfile all;
}
11.在RAC的testdb01机器上注册单机最后备份的那个归档日志备份包
Rman>catalog backuppiece '/u01/app/rman/arch21pu0tdr_1_1.bak';
12.在RAC的testdb01机器上recover数据库到最后一个归档日志的sequence+1
RMAN> recover database until sequence 9;
13.在RAC的testdb01机器上把单机的在线日志路径修改为ASM路径
alter database rename file '/oracle/ora11g/oradata/DB521102/redo01.log' to '+DATA/DB521102/redo01.log';
alter database rename file '/oracle/ora11g/oradata/DB521102/redo02.log' to '+DATA/DB521102/redo02.log';
alter database rename file '/oracle/ora11g/oradata/DB521102/redo03.log' to '+DATA/DB521102/redo03.log';
alter database rename file '/oracle/ora11g/oradata/DB521102/redo04.log' to '+DATA/DB521102/redo04.log';
14.在RAC的testdb01机器上
Sql>alter database open resetlogs;
出现如下报错信息
ORA-01092: ORACLE instance terminated. Disconnection forced
ORA-00704: bootstrap process failure
ORA-39700: database must be opened with UPGRADE option
15.解决方法如下,目标库重新登陆按如下执行(执行catupgrd.sql完后实例会自动shutdown,之后直接startup的过程不再需要resetlogs了)
ORACLE_SID=DB521102
sql>startup upgrade;
sql>@$ORACLE_HOME/rdbms/admin/catupgrd.sql;
sql> startup
16.在RAC的testdb01机器上修改参数,修改数据库的实例数目,为每个实例命名,并使每个实例拥有独立的thread
alter system set cluster_database=true scope=spfile;
alter system set cluster_database_instances=2 scope=spfile;
alter system set instance_number=1 scope=spfile sid='DB52110201';
alter system set instance_number=2 scope=spfile sid='DB52110202';
alter system set thread=1 scope=spfile sid='DB52110201';
alter system set thread=2 scope=spfile sid='DB52110202';
17.在RAC的testdb01机器上查看undo tablespace,保证只有一个undo tablespace
show parameter undo
18.在RAC的testdb01机器上创建第二个undo tablespace
create undo tablespace undotbs2 datafile '+DATA/DB521102/undotbs02.dbf' size 512m;
19.在RAC的testdb01机器上修改参数,使每个实例有独立的undo tablespace
alter system set undo_tablespace='undotbs1' scope=spfile sid='DB52110201';
alter system set undo_tablespace='undotbs2' scope=spfile sid='DB52110202';
20.在RAC的testdb01机器上为第二个thread创建在线日志组
alter database add logfile thread 2 group 4 '+DATA/DB521102/redo04.log' size 50m;
alter database add logfile thread 2 group 5 '+DATA/DB521102/rede05.log' size 50m;
alter database add logfile thread 2 group 6 '+DATA/DB521102/rede06.log' size 50m;
21.在RAC的testdb01机器上启动第二个thread
alter database enable thread 2;
22.在RAC的testdb01机器上检查归档路径是否在ASM中
Archive log list
23.在RAC的testdb01机器上关闭数据库
ORACLE_SID=DB521102
Sql>Shutdown immediate
24.在RAC的testdb01、testdb02机器上关闭RAC数据库
Source ~/.bash_profile
Sql>Shutdown immediate
25.在RAC的所有机器即testdb01、testdb02上重新配置初始化pfile
[oracle@testdb01 dbs]$ echo "spfile='+DATA/DB521102/spfileDB521102.ora'">/u01/app/oracle/product/11.2.0/db_1/dbs/initDB52110201.ora
[oracle@testdb02 ~]$ echo "spfile='+DATA/DB521102/spfileDB521102.ora'">/u01/app/oracle/product/11.2.0/db_1/dbs/initDB52110202.ora
26.在RAC的所有机器即testdb01、testdb02上上配置oracle的.bash_profile,把ORACLE_UNQNAME、ORACLE_SID设置为新值,并source .bash_profile
27.在RAC的所有机器即testdb01、testdb02上都启动数据库,并在每台机器上检查是否能够查询到所有实例信息
Sql>starup
Sql>select status,instance_number,instance_name,host_name from gv$instance;
28.在RAC的所有机器即testdb01、testdb02上再创建各自实例的密码文件
orapwd file='$ORACLE_HOME/dbs/orapwDB5211021' password=123456 entries=5 force=y
orapwd file='$ORACLE_HOME/dbs/orapwDB5211022' password=123456 entries=5 force=y
29.在RAC的随机一台机器如testdb01机器上把数据库加入集群(grid或oracle用户都可以)
srvctl add database -d DB521102 -o $ORACLE_HOME -p +DATA/DB521102/spfileDB521102.ora
srvctl add instance -d DB521102 -i DB52110201 -n testdb01
srvctl add instance -d DB521102 -i DB52110202 -n testdb02
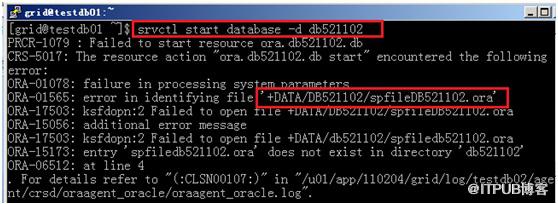
srvctl start database -d DB521102
30.在RAC的所有机器即testdb01、testdb02上都检查一下看集群中是否有这个数据库了
srvctl status database -d DB521102
以上方法过程中可能粗心遇到一个问题,具体如下
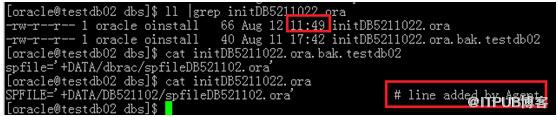
20160812 11:45时刻重启服务器后,srvctl status database –d db521102显示没有正常运行,手工执行srvctl start database –d db521102发现如下信息,查看initDB5211022.ora发现该文件自动修改了被备份了一份initDB5211022.ora.bak.testdb02,备份文件显示的目录为为/dbrac/。当然解决方法还是简单把参数文件从dbrac目录拷贝一份到DB521102就ok了。个人感觉这个错误应该引起原因可能是以下2种中的一种,个人倾向第二种。
1. 第26步过程中一开始echo的路径是dbrac,并在RAC中启动启动了DB,后来手工修改成了DB521102,所以重启服务器后,集群不认DB521102,还认dbrac。
2. 第26步echo配错成dbrac,但是第29步-p成DB521102
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。