您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
欢迎转载,请注明作者、出处。


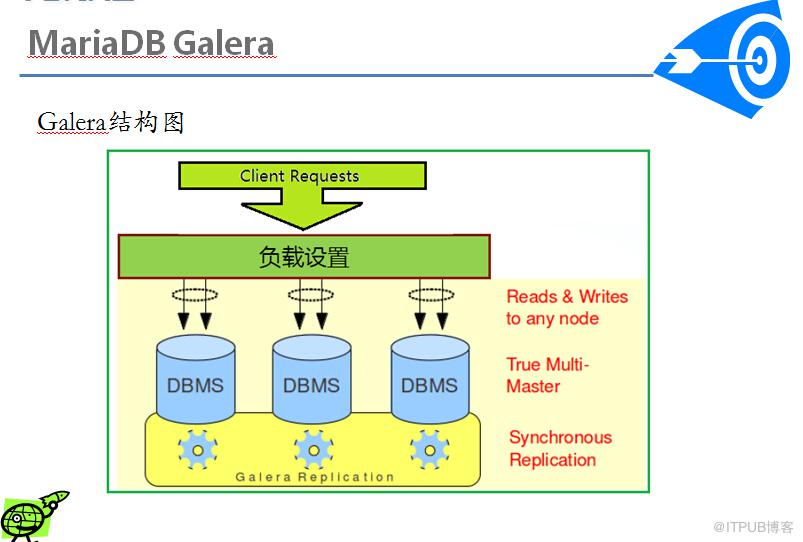
MySQL-Transefer(下称Transfer)是一个基于MySQL+patch后得到的主从同步工具。
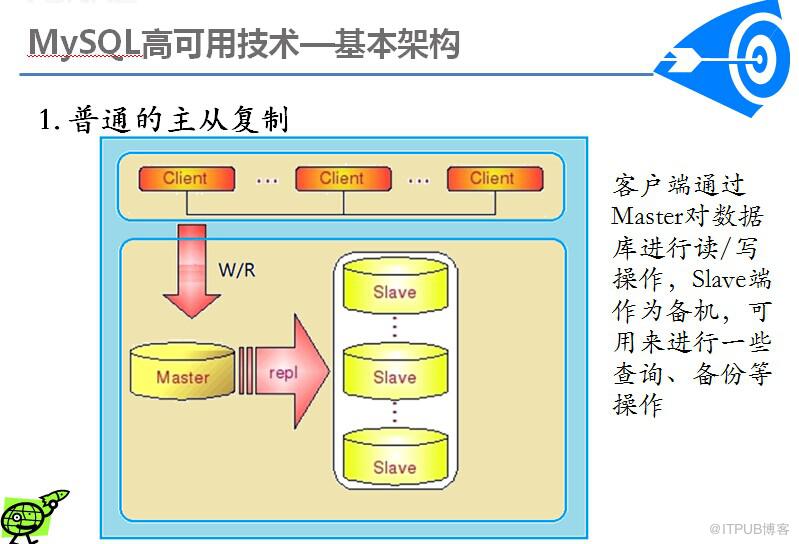
其主要目的是为了解决原版本的主从同步里,从库是单线程apply主库的binlog,导致的延迟。
MySQL5.6以后的版本,从库即可多现在apply主库的binlog。

对于数据实时性要求不是特别严格的应用,只需要通过廉价的pc server 来扩展Slave 的数量,将读压力分散到多台Slave 的机器上面,即可通过分散单台数据库服务器的读压力来解决数据库端的读性能瓶颈,毕竟在大多数数据库应用系统中的读压力还是要比写压力大很多。这在很大程度上解决了目前很多中小型网站的数据库压力瓶颈问题,甚至有些大型网站也在使用类似方案解决数据库瓶颈。

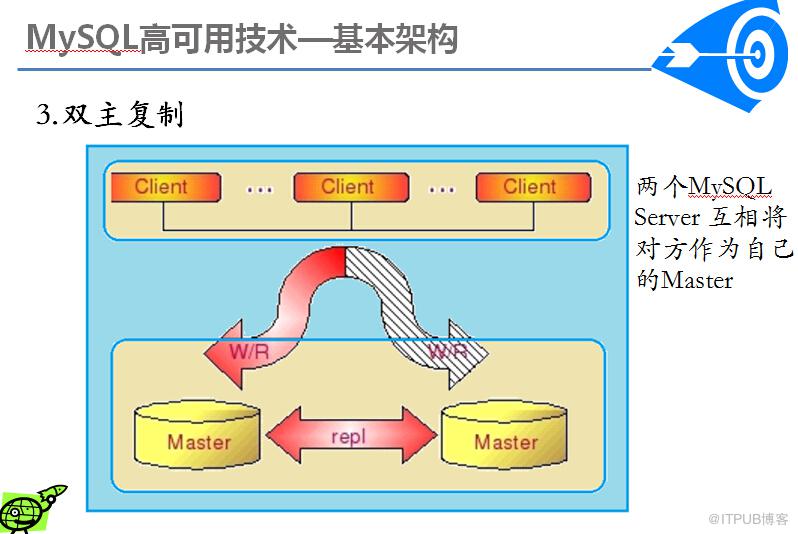
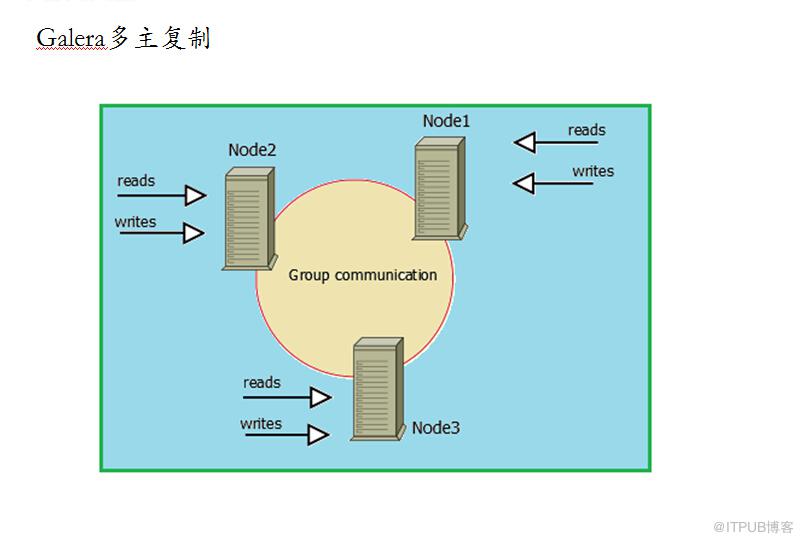
搭建成一个Dual Master 环境,并不是为了让两端都提供写的服务。在正常情况下,我们都只会将其中一端开启写服务,另外一端仅仅只是提供读服务,或者完全不提供任何服务,仅仅只是作为一个备用的机器存在。主要还是为了避免数据的冲突,防止造成数据的不一致性。因为即使在两边执行的修改有先后顺序,但由于Replication 是异步的实现机制,同样会导致即使晚做的修改也可能会被早做的修改所覆盖

通过Dual Master 复制架构,我们不仅能够避免因为正常的常规维护操作需要的停机所带来的重新搭建Replication 环境的操作,因为我们任何一端都记录了自己当前复制到对方的什么位置了,当系统起来之后,就会自动开始从之前的位置重新开始复制,而不需要人为去进行任何干预,大大节省了维护成本。
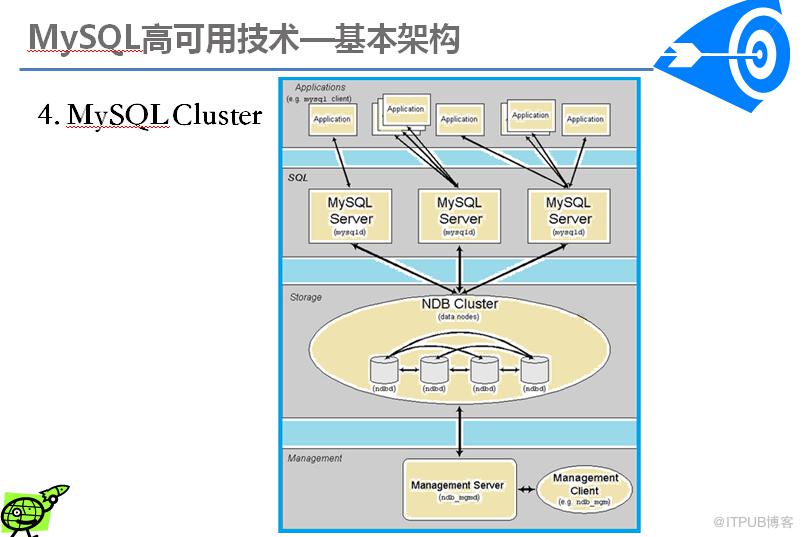

在MySQL Cluster 主配置文件(在管理节点上面,一般为config.ini)中,有一个非常重要的参数叫NoOfReplicas,这个参数
指定了每一份数据被冗余存储在不同节点上面的份数,该参数一般至少应该被设置成2

mysql cluster成本更低,oracle
rac更成熟,而且应用案例很多;
mysql cluster虽然设计很好,但是功能实现还不够完美,目前应用案例并不多,更多的案例是mysql replication
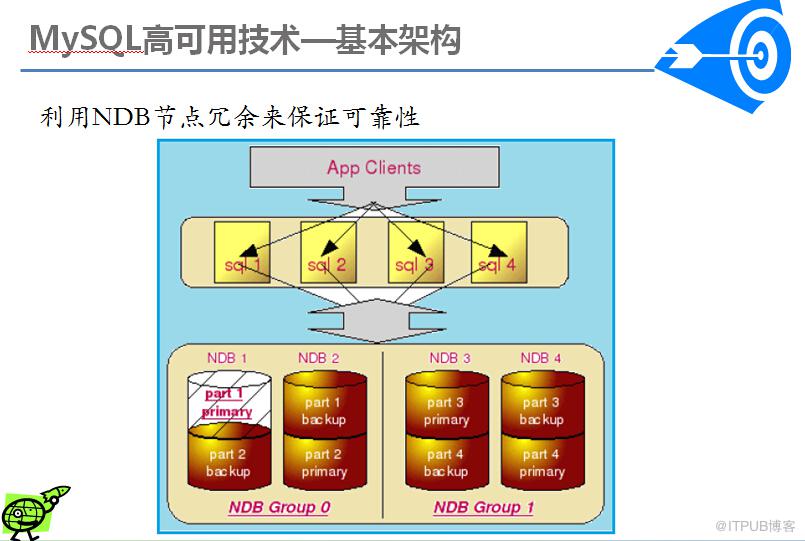

因为MySQL Cluster将数据分布到几个NDB节点之上,连接查询时,如果需要连接的表位于不同的NDB节点上,就需要将不同节点上的数据拿到本地再进行连接查询,这样对资源消耗比较大。(不过在MySQL Cluster7.3版本中,增加了适应性join查询,减小了以往join查询对资源的消耗)

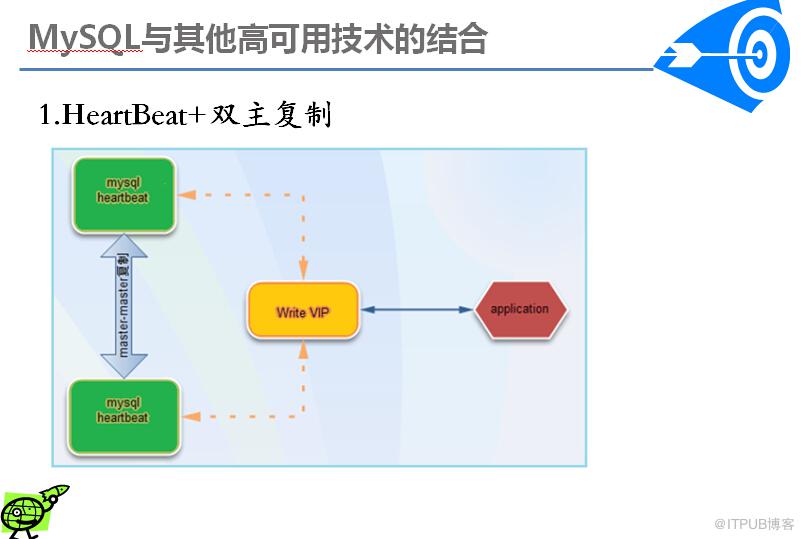
Heartbeat是Linux-HA工程的一个组件。heartbeat最核心的包括两个部分:心跳监测和资源接管。在指定的时间内未收到对方发送的报文,那么就认为对方失效,这时需启动资源接管模块来接管运 行在对方主机上的资源或者服务。

比如用shell脚本监测到master的mysql不可用就将主上的heartbeat停掉,这样就会切换到backup中去
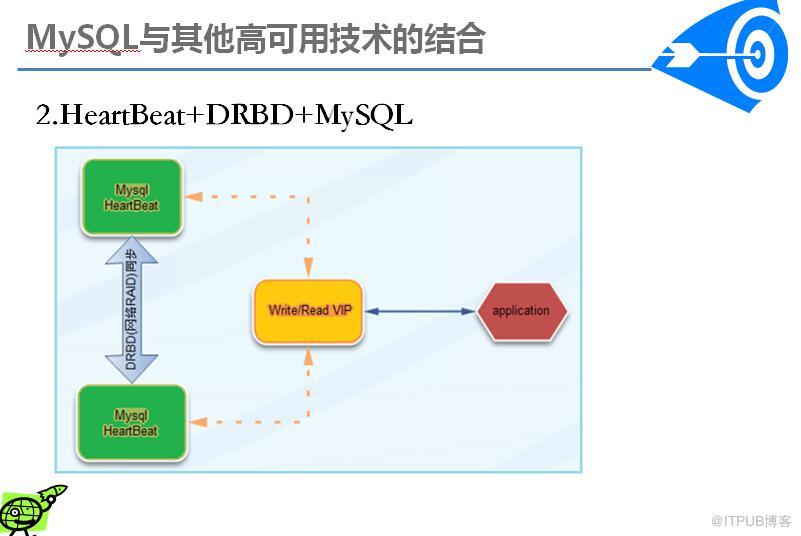
DRBD是通过网络来实现块设备的数据镜像同步的一款开源Cluster软件。

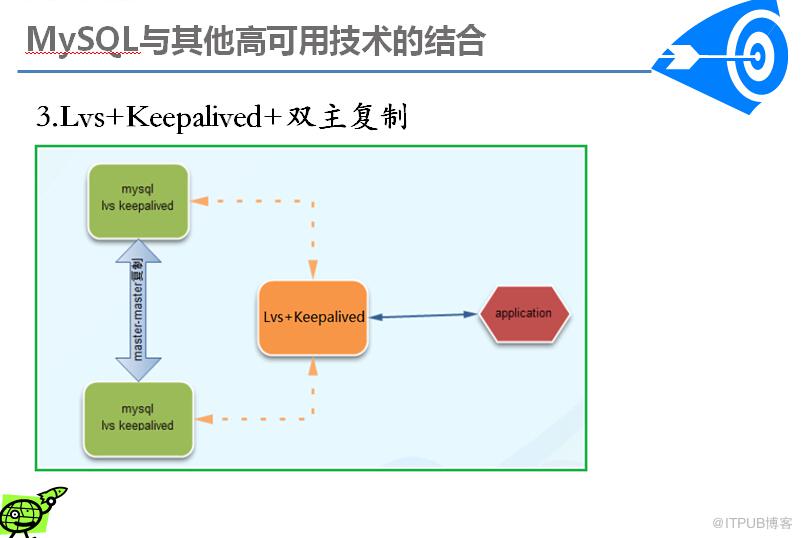
Lvs是一个虚拟的服务器集群系统,可以实现LINUX平台下的简单负载均衡。
keepalived是一个类似于layer3, 4 & 5交换机制的软件,主要用于 主机与备机 的故障转移。
高可用web架构: LVS+keepalived+nginx+apache+php+eaccelerator,也常与MySQL数据库一起使用
 ]
]
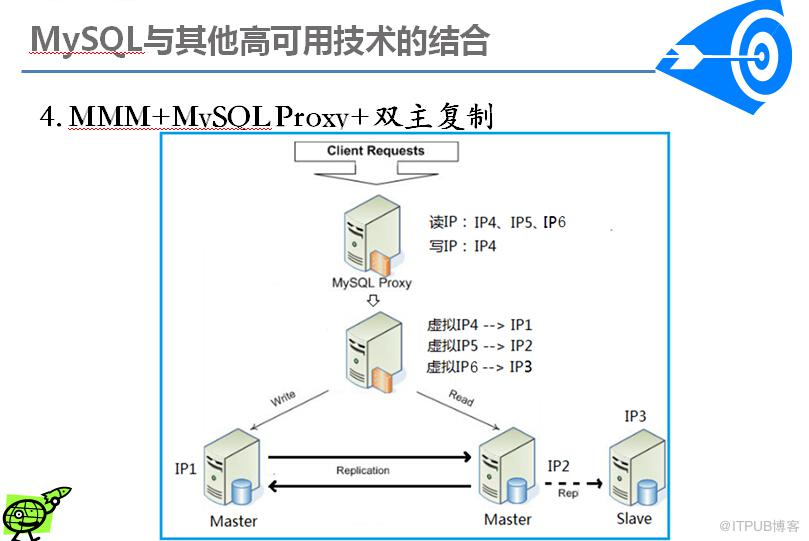
MMM即Master-Master Replication Manager for MySQL(mysql主主复制管理器)是一套灵活的脚本程序?用来对mysql replication进行监控和故障迁移?并能管理mysql Master-Master复制的配置 。附带的工具套件可以实现多个slaves的read负载均衡



HAProxy提供高可用性、负载均衡,比较适合负载特大的web站点。



免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。