您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“redis5.0集群的安装过程”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“redis5.0集群的安装过程”吧!
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
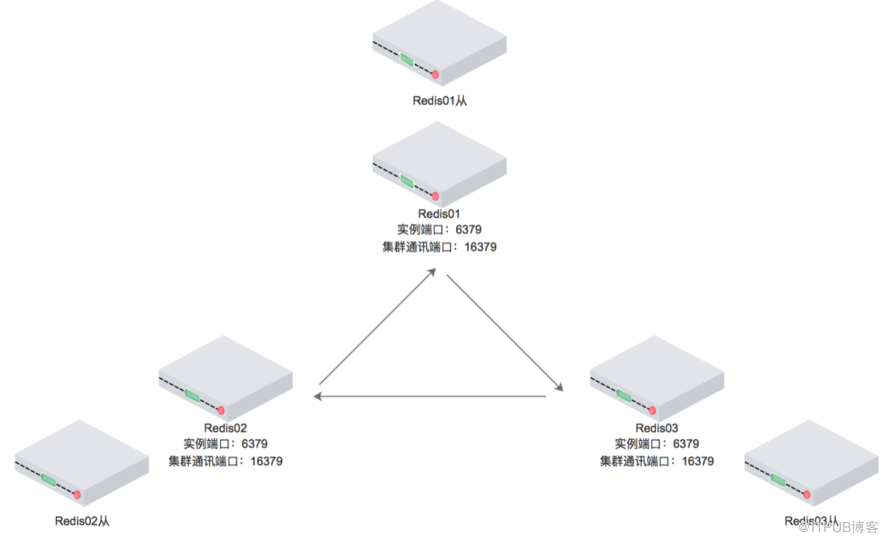
图中描述的是六个redis实例构成的集群
6379端口为客户端通讯端口
16379端口为集群总线端口
集群内部划分为16384个数据分槽,分布在三个主redis中。
从redis中没有分槽,不会参与集群投票,也不会帮忙加快读取数据,仅仅作为主机的备份。
三个主节点中平均分布着16384数据分槽的三分之一,每个节点中不会存有有重复数据,仅仅有自己的从机帮忙冗余。
注意:redis cluster至少要有三个主节点,为了冗余,至少还要有三个从节点。
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了。
不过当B和B1 都失败后,集群是不可用的.
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
客户端向主节点B写入一条命令.
主节点B向客户端回复命令状态.
主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。
Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(cluster-node-timeout), 是 Redis 集群的一个重要的配置选项:
node1:172.18.22.100 node2:172.18.22.101
https://redis.io/download
我下载的是redis-5.0.3.tar.gz
[root@node1 ~]# cd /opt/ [root@node1 opt]# tar -xvf redis-5.0.3.tar.gz [root@node1 opt]# cd redis-5.0.3/ [root@node1 opt]# make MALLOC=lib [root@node1 opt]# make install
node1服务器上: [root@node1 ~]# cd /opt/ [root@node1 opt]# tar -xvf redis-5.0.3.tar.gz [root@node1 opt]# cd redis-5.0.3/ [root@node1 redis-5.0.3]# mkdir -p redis_cluster/7000/data [root@node1 redis-5.0.3]# mkdir -p redis_cluster/7001/data [root@node1 redis-5.0.3]# mkdir -p redis_cluster/7002/data
在上面的三个目录里面创建redis.conf文件,需要修改的地方下面已经标注:
#redis.conf默认配置 daemonize yes ############多实例情况下需修改,例如redis_6380.pid pidfile /var/run/redis_7000.pid ##############多实例情况下需要修改,例如6380 port 7000 tcp-backlog 511 bind 0.0.0.0 timeout 0 tcp-keepalive 0 loglevel notice ###################多实例情况下需要修改,例如6380.log logfile /var/log/redis_7000.log databases 16 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes ##################多实例情况下需要修改,例如dump.6380.rdb dbfilename dump.7000.rdb slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-disable-tcp-nodelay no slave-priority 100 appendonly yes #######################多实例情况下需要修改,例如 appendonly_6380.aof appendfilename "appendonly_7000.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 #系统配置 #vim /etc/sysctl.conf #vm.overcommit_memory = 1 #自定义配置 aof-rewrite-incremental-fsync yes maxmemory 4096mb maxmemory-policy allkeys-lru ######################多实例情况下需要修改,例如/data/6380 dir /opt/redis-5.0.3/redis_cluster/7000/data #集群配置 cluster-enabled yes ######################多实例情况下需要修改 cluster-config-file /opt/redis-5.0.3/redis_cluster/7000/nodes.conf cluster-node-timeout 5000 #从ping主间隔默认10秒 #复制超时时间 #repl-timeout 60 #远距离主从 #config set client-output-buffer-limit "slave 536870912 536870912 0" #config set repl-backlog-size 209715200
[root@node1 redis-5.0.3]# scp -pr /opt/redis-5.0.3/ node2:/opt/
cluster-node-timeout这个参数很重要,设置太小,会频繁发生主从自动切换,设置时间太大,会发生主宕机了,不能及时进行主从切换。
一旦某个主节点进入了FAIL状态,如果这个主节点有一个或者多个从节点存在,那么其中一个从节点会被升级为主节点,而其它从节点会开始对这个新主节点进行复制
[root@node1 redis-5.0.3]# /opt/redis-5.0.3/src/redis-server /opt/redis-5.0.3/redis_cluster/7000/redis.conf [root@node1 redis-5.0.3]# /opt/redis-5.0.3/src/redis-server /opt/redis-5.0.3/redis_cluster/7001/redis.conf [root@node1 redis-5.0.3]# /opt/redis-5.0.3/src/redis-server /opt/redis-5.0.3/redis_cluster/7002/redis.conf 备注: [root@node1 redis-5.0.3]# /opt/redis-5.0.3/src/redis-cli -h localhost -p 7000 shutdown [root@node1 redis-5.0.3]# /opt/redis-5.0.3/src/redis-cli -h localhost -p 7000 -c localhost:7000> ping PONG
备注: -c是启动集群模式
[root@node1 opt]# /opt/redis-5.0.3/src/redis-cli --cluster create 172.18.22.100:7000 172.18.22.100:7001 172.18.22.100:7002 172.18.22.101:7000 172.18.22.101:7001 172.18.22.101:7002 --cluster-replicas 1
中间要输入一次yes。
选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
[root@node1 opt]# /opt/redis-5.0.3/src/redis-cli -h localhost -p 7001
localhost:7001> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:2 cluster_stats_messages_ping_sent:1302 cluster_stats_messages_pong_sent:946 cluster_stats_messages_meet_sent:4 cluster_stats_messages_sent:2252 cluster_stats_messages_ping_received:945 cluster_stats_messages_pong_received:1306 cluster_stats_messages_meet_received:1 cluster_stats_messages_received:2252 localhost:7001>
localhost:7001> CLUSTER NODES ed9ac7cfe6847f39dfcf56ad4244c4213a0965b1 172.18.22.100:7002@17002 slave f881aa4c6fdce6f7ac058600ca712fd9df110b1a 0 1551346045000 4 connected fb56d260650dfad25e6b54c1519e9530e1b33b62 172.18.22.100:7001@17001 myself,master - 0 1551346046000 2 connected 10923-16383 09f371cfd0933a343dd6d84159a6f8ad508b1eff 172.18.22.100:7000@17000 master - 0 1551346047131 1 connected 0-5460 a7573d643ede9facb1e9b3b629a1604ed88b6a61 172.18.22.101:7002@17002 slave fb56d260650dfad25e6b54c1519e9530e1b33b62 0 1551346046000 6 connected f881aa4c6fdce6f7ac058600ca712fd9df110b1a 172.18.22.101:7000@17000 master - 0 1551346046629 4 connected 5461-10922 8d3b210324f24aac0c146363e95d3c87a7eb474c 172.18.22.101:7001@17001 slave 09f371cfd0933a343dd6d84159a6f8ad508b1eff 0 1551346045627 5 connected
在第一台机器上连接集群的7000端口的节点,在另外一台连接7002节点,连接方式为 redis-cli -h localhost -c -p 7002 ,
加参数 -C 可连接到集群。
在7000节点执行命令 set hello world ,执行结果如下:
localhost:7000> set hello world OK localhost:7000> get hello "world"
然后在另外一台7002端口,查看 key 为 hello 的内容, get hello ,执行结果如下:
localhost:7002> get hello -> Redirected to slot [866] located at 172.18.22.100:7000 "world"
说明集群运作正常。
简单说一下原理
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,
每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我
们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。
redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key
分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转
到了7000端口的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,
也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,
充当 master 。
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,
整个集群就无法提供服务了。
到此,相信大家对“redis5.0集群的安装过程”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。