您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍Nebula Graph如何安装部署,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
Nebula Graph:一个开源的分布式图数据库。作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,还能够实现服务高可用且保障数据安全性。
Nebula Graph 是开源的第三代分布式图数据库,不仅能够存储万亿个带属性的节点和边,而且还能在高并发场景下满足毫秒级的低时延查询要求。不同于 Gremlin 和 Cypher,Nebula 提供了一种 SQL-LIKE 的查询语言
nGQL,通过三种组合方式(管道、分号和变量)完成对图的 CRUD 的操作。在存储层 Nebula Graph 目前支持
RocksDB 和
HBase 两种方式。
感谢 Nebula Graph 社区 Committer 伊兴路供稿本文。
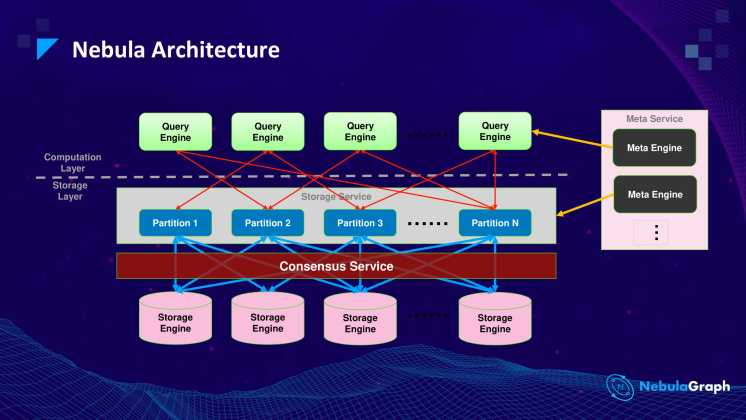
Nebula Graph 主要有三个服务进程:
Meta Service 是整个集群的元数据管理中心,采用 Raft 协议保证高可用。主要提供两个功能:
管理各种元信息,比如 Schema
指挥存储扩容和数据迁移
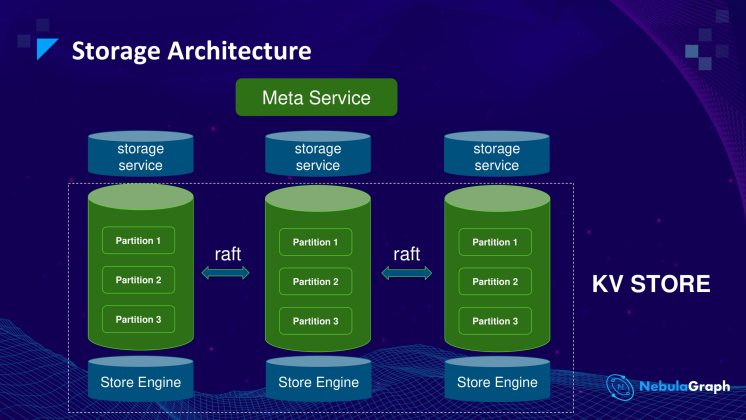
Storage Service 负责 Graph 数据存储。图数据被切分成很多的分片 Partition,相同 ID 的 Partition 组成一个 Raft Group,实现多副本一致性。Nebula Graph 默认的存储引擎是 RocksDB 的 Key-Value 存储。
Graph Service 位于架构中的计算层,负责同 Console 等 Client 通信,解析 nGQL 的请求并生成执行计划。执行计划经过优化器优化之后,交与执行引擎执行。执行引擎会向 MetaService 请求点边的 Schema 和向存储引擎获取点边的数据。
GraphService 是个无状态的服务,可以无限的水平拓展,并且计算层的执行计划最终会下发到数据节点执行。
Nebula Graph 提供两种部署方式:单机和集群。单机部署主要用于测试和体验使用,生产场景推荐集群方式。
在单机上实践或者测试 Nebula Graph 的最好方式是通过
Docker 容器运行,参照
文档拉取镜像,并进入容器:
$ docker pull vesoft/nebula-graph:latest $ docker run --rm -ti vesoft/nebula-graph:latest bash
进入容器之后首先启动 Nebula 的所有 Services,再通过 Console 客户端连接本容器内部的
graphd 服务来执行 nGQL 语句
$ cd /usr/local/nebula $ ./scripts/nebula.service start all $ ./bin/nebula -u user -p password (user@127.0.0.1) [(none)]> SHOW HOSTS; =============================== | Ip | Port | Status | =============================== | 172.17.0.2 | 44500 | online | ------------------------------- Got 1 rows (Time spent: 15621/16775 us)
Nebula 支持编译安装和通过打包好的 Package 安装。由于 Nebula 依赖较多,简便起见推荐使用安装包安装。
本文准备了 3 台装有 CentOS 7.5 系统的机器,IP 如下所示:
192.168.8.14 # cluster-14 192.168.8.15 # cluster-15 192.168.8.16 # cluster-16
在每台机器上下载对应的 安装包:
$ wget -O nebula-1.0.0-beta.el7-5.x86_64.rpm https://github.com/vesoft-inc/nebula/releases/download/v1.0.0-beta/nebula-1.0.0-beta.el7-5.x86_64.rpm
此外由于 Nebula 的服务之间通信需要开放一些端口,所以可以临时关掉所有机器上的防火墙: (具体使用端口见
/usr/local/nebula/etc/ 下面的配置文件)
$ systemctl disable firewalld
本文将按如下的方式部署 Nebula 的集群:
- cluster-14: metad/storaged/graphd - cluster-15: metad/storaged - cluster-16: metad/storaged
使用 rpm 安装上步准备好的安装包
$ rpm -ivh nebula-*.rpm
Nebula 默认的安装目录位于
/usr/local/nebula
Nebula 的所有配置文件都位于
/usr/local/nebula/etc 目录下,并且提供了三份默认配置。分别编辑这些配置文件:
第一份配置文件:nebula-metad.conf
metad 通过 raft 协议保证高可用,需要为每个 metad 的 service 都配置该服务部署的机器 ip 和端口。主要涉及
meta_server_addrs 和
local_ip 两个字段,其他使用默认配置。
cluster-14 上的两项配置示例如下所示:
# Peers --meta_server_addrs=192.168.8.14:45500,192.168.8.15:45500,192.168.8.16:45500 # Local ip --local_ip=192.168.8.14 # Meta daemon listening port --port=45500
第二份配置文件:nebula-graphd.conf
graphd 运行时需要从 metad 中获取 schema 数据,所以在配置中必须显示指定集群中 metad 的 ip 地址和端口选项
meta_server_addrs ,其他使用默认配置。
cluster-14 上的 graphd 配置如下:
# Meta Server Address --meta_server_addrs=192.168.8.14:45500,192.168.8.15:45500,192.168.8.16:45500
第三份配置文件:nebula-storaged.conf
storaged 也是使用的 raft 协议保证高可用,在数据迁移时会与 metad 通信,所以需要配置 metad 的地址和端口
meta_server_addrs 和本机地址
local_ip ,其 peers 可以通过 metad 获得。
cluster-14 上的部分配置选项如下:
# Meta server address --meta_server_addrs=192.168.8.14:45500,192.168.8.15:45500,192.168.8.16:45500 # Local ip --local_ip=192.168.8.14 # Storage daemon listening port --port=44500
cluster-14
$ /usr/local/nebula/scripts/nebula.service start all [INFO] Starting nebula-metad... [INFO] Done [INFO] Starting nebula-graphd... [INFO] Done [INFO] Starting nebula-storaged... [INFO] Done
cluster-15/cluster-16
$ /usr/local/nebula/scripts/nebula.service start metad [INFO] Starting nebula-metad... [INFO] Done $ /usr/local/nebula/scripts/nebula.service start storaged [INFO] Starting nebula-storaged... [INFO] Done
注:部分用户可能会遇到
[WARN] The maximum files allowed to open might be too few: 1024
可以自己修改
/etc/security/limits.conf
登陆集群中的一台,执行如下命令:
$ /usr/local/nebula/bin/nebula -u user -p password --addr 192.168.8.14 --port 3699 (user@192.168.8.14) [(none)]> SHOW HOSTS; ================================== | Ip | Port | Status | ================================== | 192.168.8.14 | 44500 | offline | ---------------------------------- Got 1 rows (Time spent: 3511/4024 us)
以上是“Nebula Graph如何安装部署”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。