您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文根据沈剑在2018年10月18日【第十届中国系统架构师大会(SACC2018)】现场演讲内容整理而成。
讲师介绍:

沈剑,快狗打车CTO,互联网架构技术专家,“架构师之路”公众号作者。曾任百度高级工程师,58同城高级架构师,58同城技术委员会主席。2015年调至58到家任高级总监,技术委员会主席,负责基础架构,技术平台,运维安全,信息系统等后端技术体系搭建。现任快狗打车CTO,负责快狗打车技术体系的搭建,本质是技术人一枚。
本文摘要:
沈剑分享了快狗打车数据库架构的一致性实践,在一致性实践的过程中,能够体现快狗打车数据库架构的演进历程。从单库到多库再到高可用等等,包括在研究的过程中,每个阶段可能会碰到不同的问题,快狗打车是采用一些什么样的技术手段去解决这些问题?以快狗打车的实践跟大家做一些分享。
分享大纲:
主从不一致,优化实践
缓存不一致,优化实践
数据冗余不一致,优化实践
多库事务不一致,优化实践
总结
演讲正文:
快狗打车(原58速运)是一个创业型公司,技术架构、技术体系、数据库架构的变迁,和在座很多公司是很相近的,今天和大家聊一聊,我们在快狗打车数据库架构一致性方面碰到一些问题。
不一致的优化历程,也是数据库架构演进的过程
主线是我们的数据库架构变化的过程,在这个过程中,我列出了四个跟一致性相关的节点,主从会不一致、缓存会不一致、冗余数据会不一致、多库多实例会不一致。不一致的优化历程,也是我们数据库架构演进的一个过程。从单库到现在,有哪些坑在等着我们呢?

先看一下,最初的数据库架构,最早是这个样子的。那个时候没有什么微服务分层, web通过DAO访问一个单库数据库,最早我这么玩的。单库,它不具备什么高可用,高并发特性,扩展性也比较差。我相信很多创业公司初期也是这样。
单库最早会遇到什么样的瓶颈呢?在创业的时候,数据量变大了,并发量大了,业务变复杂了,整个系统的瓶颈最先出现在哪里?我的经验是数据库。数据库的瓶颈又会在哪里?我的经验是读。因为绝大部分的业务是读多写少的业务,读,最容易称为系统的瓶颈。
最早在数据库读扛不住的时候,最先想到的优化方式是什么?互联网公司都讲快,今天出问题,能不能明天后天给我搞定?最先想到的方案是什么,如何能快速扩充数据库的读性能呢?
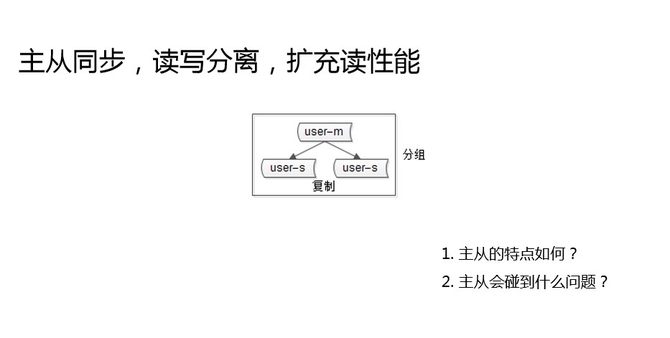
加两个实例,主从同步,读写分离,这是创业型公司,当数据库读成为瓶颈的时候,最先想到的方案,快速扩充读性能。主从同步碰到的问题是什么?这就是本主题要讲的第一个问题,主从一致性的问题。
当数据量越来越多,吞吐量越来越大的时候,写到了主库,主库同步到从库,主从同步存在延时,在延时窗口期内,读写分离去读从库,就有可能读到一个旧数据。这个问题,我相信大家也会碰到。
对于这个问题,不少接业务的解法方案是,忍,有些业务如果对一致性的要求没这么高。但有没有优化方案呢?
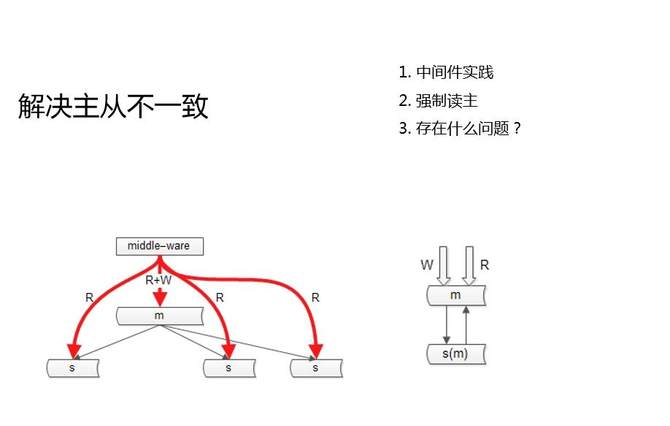
这两个图是我们的两个常见的实践。
第一个是中间件,我们的服务层或者站点层不直接调数据库,通过一个中间层,去调数据库。中间层它能够知道哪一个库,哪一个表,哪一个KEY发生了写操作,如果说接下来的这一段时间(假设主从同步一秒钟完成),有读请求落到从库上,就会读到旧数据。那么此时,中间件就要将读请求,路由到主库上去,读新数据。
第二个是强制读主。第二个图,双主同步,强制读主有什么好处?第一解决了高可用问题,双主使用同一个VIP,一个主库如果挂了,另一个主库能随时顶上,保障高可用。第二避免了主从之间的不一致。
强制读主它带来的新的问题是什么呢?解决了一致性问题,但读性能扩展的问题又来了,主库抗读写,还是没有解决读性的扩大的问题。
除了增加从库,互联网公司还有一种常见的提升系统读性能的方式,缓存加服务化。抽象出服务层,向调用方屏蔽底层数据库的复杂性,屏蔽数据库的高可用的复杂性,屏蔽缓存的复杂性,对业务层提供服务。
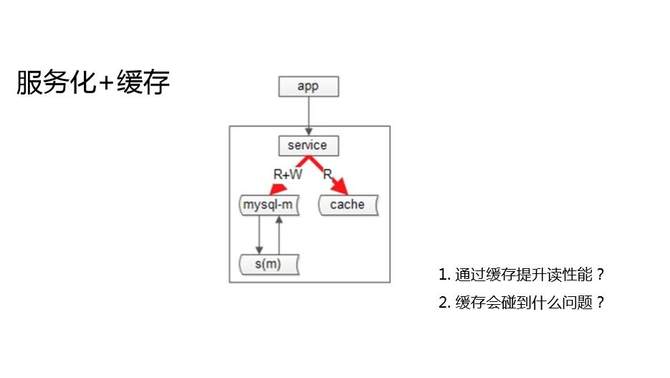
服务化加缓存确实是提升系统读容量的架构方案。通过缓存来提升读性,又会遇到什么新的问题呢?用主从架构,有主从不一致问题;用缓存架构,当然也有缓存不一致的问题。只要你把同一份数据放在了多个地方,多个地方的修改有时间差,这个时间差就会有数据访问不一致的问题。
当我们出现数据库与缓存中的数据不一致的时候,我们怎么来解决?
首先来看一下为什么会不一致。缓存的常用玩法是“Cache Aside Pattern”。Cache Aside Pattern,旁路缓存,一般是怎么玩的?淘汰缓存,而不是更新缓存,这是Cache Aside Pattern的结论。
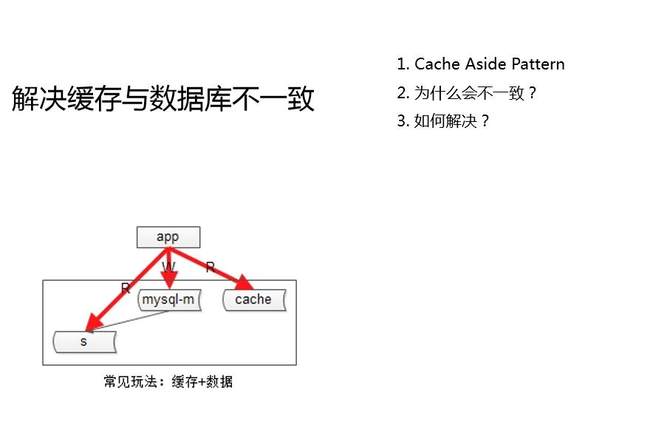
读写时序是什么样的?对于读请求有缓存,毫无争议的,先读缓存,如果数据命中我就直接返回,如果数据没有命中,读从库读写分离,把这个数据从从库里拿出,放到缓存里,这是读请求的一个流程。
对于写请求,Cache Aside Pattern的做法是,先写数据库,再淘汰缓存。在什么情况下会出现不一致?当并发量相对会比较高时,对于同一个KEY做了一个写操作,马上又来了一个读操作,会出现什么样的情况?先发生一个写操作,先更新到数据库,淘汰了Cache,马上又来了一个读操作,这个时候主从同步还没同步完成,先读缓存,缓存被刚刚的写操作已经淘汰掉了,又去读从库,把从库的脏数据拿过来放到缓存里去,不一致就出现。
高并发状态下,写后立即读的场景,容易出现脏数据入Cache。
大家发现没有,这里的数据不一致,比主从的数据不一致的情况更严重。主从不一致,只有一个主动同步时间差不一致,同步之后,从库就能读到新数据了。但是缓存与数据库的不一致,它会导致后续一直不一致,一旦脏数据入了缓存,脏数据会延续到下一个写发生的时候才会被淘汰掉,所以它其实更严重。
如何来解决呢?缓存和数据库的数据不一致,我们的两个实践:异步淘汰缓存,确保从库已经同步成功;设定超时时间,极限情况下有机会修正。
第一个,等从库已经完全同步成功,再去异步淘汰缓存?只要监听从库的binlog,从库binlog完成,一定是写操作执行完毕,此时再淘汰缓存,就能避免时间差。
第二个,就是如果允许Cache miss,不要将缓存过期时间设为永久,如果你设置为无限长的过期时间,就没有一个机会去修正不一致了。
随着业务的发展,除了流量的增加,我们要提升系统的读性能,我们要提升系统的数据库高可用,还会面临一个什么问题?对了,数据量会增大。我们业务数据量越来越大了,通常采用什么样的方式去解决?创业型公司,这两个方案应该是大家用得最多的。
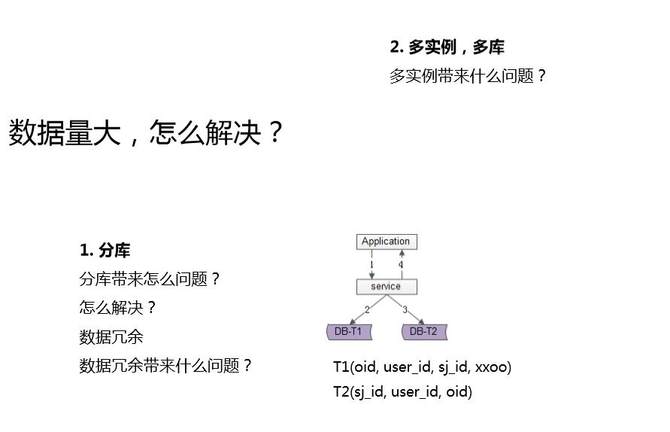
第一个,分库。降低每个库,降低每个实例的数据量,这样就能够承载更多的数据。分库又带来什么新的问题?举了个例子,订单一个库,它有多个维度的查询,有订单ID的查询,有用户ID的查询,有司机ID的查询,一个库没有任何问题。
但分库以后,变成多个库以后,一旦用了一个维度分库,你会发现其他的维度的查询就要变成多个库了,是不是?
一般来说是通过用户的ID去分库,在订单ID里去放上分库因子,这样通过用户ID以及订单ID都能够定位到相关数据。但是对于司机ID就不同了,司机ID和用户ID是一个多对多的关系。一个用户他可能下了多个司机的单,一个司机接了多个用户的单,通过司机ID去查询,并不能一次性查询到所有的数据,同一个司机的订单一定是分布在多个库里。怎么办呢?此时最常用解决方案是,数据冗余。
我用一个存储元数据,用一个存储关系数据,元数据通过用户ID来分库,保证同一个用户的所有订单在一个库里。关系数据用司机ID来分库,保证同一个司机的所有订单在一个库里。同一份数据,由于它存在两个维度的查询,这两个维度查询都可以不夸库,而通过数据冗余来实现,这个在业内属于很常见的方案。
数据冗余,又会出现什么问题?一起来看一下。上面是应用,中间是服务,一个数据存在两个库里,一个库是通过用户ID分库,一个库是通过司机ID去分库,调用方来了一个请求,先要往第一份数据里写一个数据,再往另外一个库里写一个冗余数据。能保证冗余数据的一致性么?是不能够保证,这两个库同时写成功的,那怎么办呢?
这就是冗余数据的一致性问题。数据冗余数据的不一致优化,今天介绍三种方法,其实本质的方法论都是最终一致性。
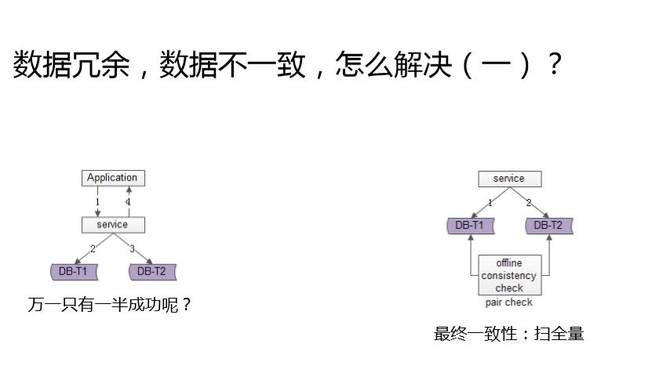
第一个方案是扫全量。怎么发现冗余数据不一致?写个脚本,每天晚上跑,理论上A库里有的B库里面也有,一旦扫库发现怎么A库有B库里没有,就是出现不一致了,就要根据业务特性来做补偿。到底是将后一半补进去,还是把前一半删掉,跟业务特性相关,不过思路大致是这样的,一个异步的方式,最终来保证一致性。
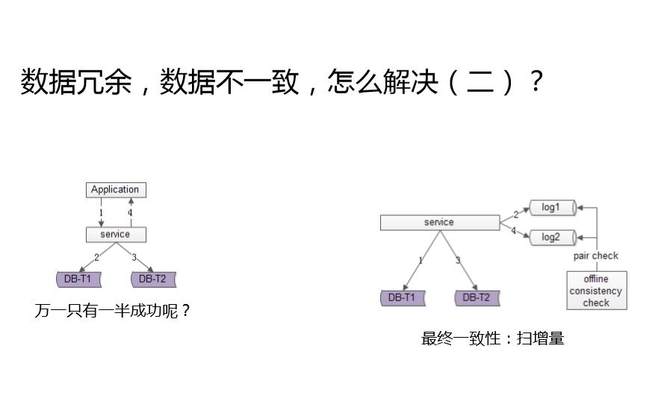
第二个方案是扫增量。通过服务操作两个库,写成功第一个库写一条日志,写成功第二个库再写一条日志。这些日志里的就是每天改变的数据,每天不用扫描全量,只要扫描每天改变的数据就行了。如果扫描日志不匹配,就通过异步的方式修复,保证最终一致性。
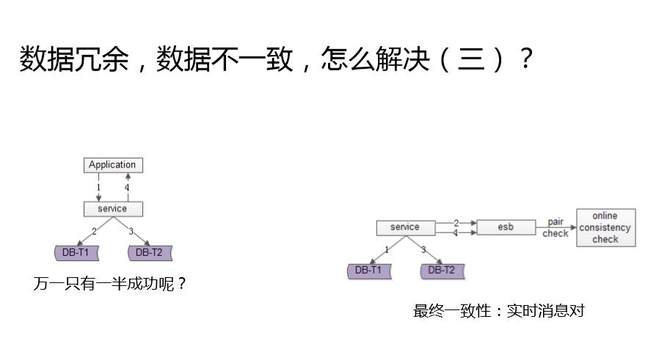
第三个方式,比前两种方式更加实时。不写日志了,而是发消息。用一个消息组件,数据库正向表操作成功了,发一个消息,冗余表操作成功了,发另一个消息。用一个异步的服务去监听这两个消息,如果只有一条消息到达,就去数据库检测一致性,并用异步的方式来补偿。

最后是多实例多库,这也是解决数据量大的一个常见方案。它会带来什么样的不一致呢?这里有一个案例,下单的一个操作,可能有三个数据要修改,一个是余额的数据,我可能要扣减一些余额;一个是订单的数据,要新增一条订单;一个是流水的数据,要新增一条流水。原来是单库事务来保证一致性,现在数据量大了,变成多个库,余额是一个单独的实例,订单是一个单独的实例,流水是一个单独的实例,所以原来的一个事务,在多库状态下,就变成三个事务。
多实例,多库事务,不一致,怎么办?这一块我们有两个优化实践。

第一个是补偿事务,业内应该也经常用到补偿事务。
余额操作,正向的操作是扣减余额,补偿事务就是把余额加回来。
订单操作,正向的操作是新增订单,补偿事务就是把订单删除掉。
流水操作,正向的操作是新增流水,补偿事务就是把流水删除。
总之,补偿事务就是当你发现前面的事务执行失败的时候,要执行一个应用层的事务,回滚一个动作。
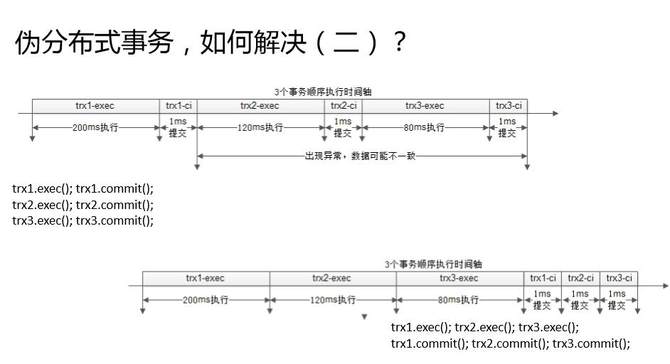
另外一种方式,伪分布式事务的解决方案,是后置提交。
先细化的看一下三个事务是怎么执行的?第一个事务先执行再提交,第二个事务执行再提交,第三个事务执行再提交。事务的执行过程很慢,事务的提交过程很快。上图这个例子,可能执行时间200毫秒,提交时间几毫秒,什么时候会出现不一致呢?第一个事务提交成功之后,最后一个事务提交成功之前的中间,任何一个地方出现异常都会导致不一致。
优化其实也很简单,后置提交。第一个事务执行,第二个事务执行,第三个事务执行;第一个事务提交,第二个事务提交,第三个事务提交。什么时候会出现不一致呢?仍然是第一个事务提交成功之后,第三个事务提交成功之前的时间间隔,如果出现了,网络异常,服务器挂了,就会不一致。但是这个间隔就只有后面的两毫秒,所以整个不一致的概率是降低了百倍左右。
最后做一个简单的总结。根据我的经验,40分钟50分钟的一个技术分享,第二天能够记住的只有10%。如果只记住10%,那我希望大家能够记住这一页的内容,并希望自己的逻辑是清晰的。

数据库架构最初是单库,单库会碰到什么问题?会碰到读性能瓶颈的问题。读性能瓶颈最早用什么样的方式去解决?主从同步读写分离,它会带来什么问题?主从的不一致,用什么方案解决?我们的实践是中间件,以及强制读主。
提升读性能,服务化加缓存也是常见方案,带来什么新的问题?缓存和数据库的不一致。在Cache Aside Pattern的情况下,有写后立即读的问题,旧数据可能入缓存。我们的实践,可以通过异步淘汰的方式,当写操作在从库上真正完成的时候再去淘汰缓存。同时,我们建议为所有允许Cache miss的数据设置超时时间。
数据库架构,数据量大的问题,怎么解决?常用的解决方案是分库,多实例。分库带来什么新的问题?记得我的例子么,分了库之后,可以保证同一个用户的数据在同一个库里,不能够保证同一个司机数据也在同一个库里,怎么解决?使用数据冗余。冗余带来什么问题?冗余数据的不一致问题,方向是最终一致性。怎么最终保证一致性?扫全量,扫增量,实时消息对。除了多库,多实例也可以扩展数据存储量,会遇到什么问题?多库的事务不能在保证原则性,补偿事务,后置提交,都是我们的优化实践。
今天的内容这么多,希望大家有收获,谢谢大家。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。