您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
原文: https://www.modb.pro/db/6143
前言
一年一度的数据库领域顶级会议VLDB 2019于美国当地时间8月26日-8月30日在洛杉矶召开。在本届大会上,阿里云数据库产品团队多篇论文入选Research Track和Industrial Track。
本文将对入围ResearchTrack 的论文《iBTune: Individualized Buffer Tuning for Largescale Cloud Databases》进行详细解读,以飨读者。
背景
大概五六年前,阿里数据库团队开始尝试如何将DBA的经验转换成产品,为业务开发提供更高效,更智能的数据库服务。从14年CloudDBA开始为用户提供自助式智能诊断优化服务,经过四年的持续探索和努力,18年进化到CloudDBA下一代产品
—— 自治数据库平台SDDP(Self-Driving Database Platform)。
SDDP是一个赋予多种数据库无人驾驶能力的智能数据库平台,让运行于该平台的数据库具备自感知、自决策、自恢复、自优化的能力,为用户提供无感知的不间断服务。自治数据库平台涵盖了非常多的能力,包括物理资源管理,实例生命周期管理,诊断优化,安全,弹性伸缩等,而其中自动异常诊断与恢复和自动优化是自治数据库平台最核心的能力之一。
2017年底,SDDP开始对全网数据库实例进行端到端的全自动优化,除了常见的自动慢SQL优化和自动空间优化外,还包含了本文重点介绍的大规模数据库自动参数优化。
基于数据驱动和机器学习算法的数据库参数优化是近年来数据库智能优化的一个热点方向,但也面临着很大的技术挑战。要解决的问题是在大规模数据库场景下,如何对百万级别运行不同业务的数据库实例完成自动配置,同时权衡性能和成本,在满足SLA的前提下资源成本最低,该技术对于CSP(Cloud Service Provider)有重要价值。
学术界近一两年在该方向有一些研究(比如CMU的OtterTune),但该算法依赖于一些人工先验经验且在大规模场景下不具备可扩展性。据了解, 其他云厂商Azure SQL Database以及AWS该方向都有投入,目前尚未看到相关论文或产品发布。
从18年初开始我们开始数据库智能参数优化的探索,从问题定义,关键算法设计,算法评估及改进,到最终端到端自动化流程落地,多个团队通力合作完成了技术突破且实现了大规模落地。
由谭剑、铁赢、飞刀、艾奥、祺星、池院、洪林、石悦、鸣嵩、张瑞共同撰写的论文《iBTune: Individualized Buffer Tuning for Largescale Cloud Databases》被VLDB 2019 Research Track接受,这是阿里巴巴在数据库智能化方向的重要里程碑事件。
这项工作不仅在数据库智能参数优化理论方面提出了创新想法,而且目前已经在阿里集团~10000实例上实现了规模化落地,累计节省~12%内存资源,是目前业界唯一一家真正实现数据库智能参数优化大规模落地的公司。
问题定义
参数优化是数据库优化的重要手段,而数据库参数之多也增加了参数调优的难度,比如最新版本的MySQL参数超过500,PostgreSQL参数也超过290。通常数据库调优化主要关心性能相关的参数,而其中对性能影响最大的是Buffer Pool的设置。
目前集团环境多个数据库实例共享主机的部署方式导致经常出现主机内存严重不足,但CPU和存储资源还有较多剩余,造成了机器资源浪费,因此内存资源紧张成为影响数据库实例部署密度的关键瓶颈。
Buffer Pool是内存资源消耗的最大头,如何实现Buffer Pool最优配置是影响全网机器成本的关键,同时也是影响数据库实例性能的关键,因此我们将智能参数优化重点放在了Buffer Pool参数优化。
对于大规模数据库场景,挑战在于如何为每个数据库实例配置合理的Buffer Pool Size,可以在不影响实例性能的前提下,Buffer Pool Size最小。传统大规模数据库场景为了方便统一管控,通常采用静态配置模板的配置数据库实例参数。
以阿里集团数据库场景为例,集团内提供了10种BufferPool规格的数据库实例供业务方选择。开发同学在申请实例时,由于不清楚自己的业务对BP的需求是什么,通常会选用默认配置规格或者较高配置规格。这种资源分配,带来了严重的资源浪费。
另外业务多样性和持续可变性使得传统依赖DBA手工调优方式在大规模场景下完全不可行,因此基于数据驱动和机器学习算法来根据数据库负载和性能变化动态调整数据库Buffer Pool成为一个重要的研究问题。
问题分析
从问题本身来看,缓存的大小(BP)与缓存命中率(hit ratio)是存在直接关系的。设想一下,如果可以找到一个公式BP=Function(hit_ratio),然后从业务方或者DBA的视角找到一个业务可接受的缓存命中率,就可以下调BP且不影响业务。
经过调研,我们发现在操作系统的Cache研究领域中,研究者已经对buffer size和hit ratio的对应关系有了很多研究,其中有研究表明在数据长尾部分这二者的关系服从Power Law分布,即:
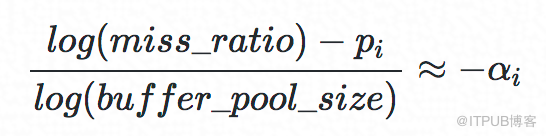
其中,
αi是Power Law分布的指数,miss_ratio=1−hit_ratio。
经过上面的理论调研,关系模型已经得到解决,接下来需要求解该模型中的超参数,即MySQL数据库Cache的αi。
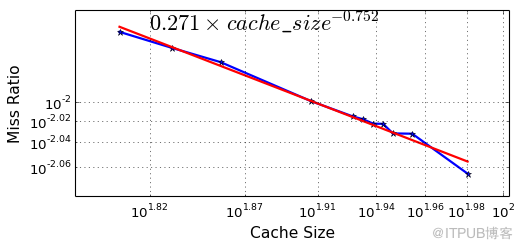
在集团DBA同学开发的Frodo工具帮助下,我们针对集团内的几个重要OLTP场景(例如购物车场景、交易支付场景)进行了不同BP配置的压测实验。实验结果也印证了前面的理论结果,在长尾部分MySQL的缓存确实是符合Power Law分布假设的。
于是,给定当前未命中率 mrcur、当前BP大小BPcur和目标未命中率 mrtarget的情况下,我们可以推导出如下公式来计算调整后的BP BPtarget,公式:
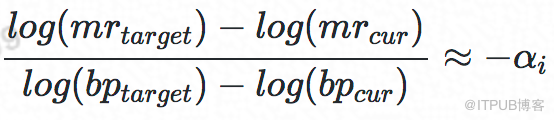
通过上面的理论调研和MySQL实际场景验证,该理论公式经验证在MySQL场景下成立,并且可计算出关键系数αi,接下来看如何计算 miss_ratiotarget。
寻找合适的miss ratio
阿里巴巴集团中有数万+数据库实例主节点,我们考虑从这数万数据库中寻找与待调整实例相似的实例,然后利用这些相似实例的miss ratio来找到待调整实例的目标miss ratio.
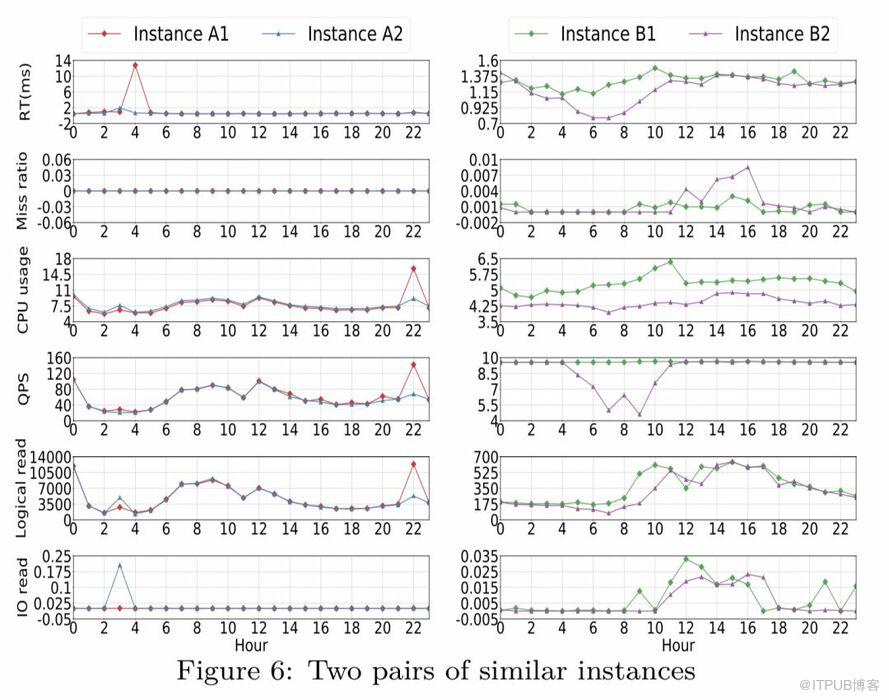
特征选择上,我们选用了CPU usage, logical read, io read, miss ratio, response time 等性能指标来描述一个业务workload,并对这些特征选取了几个统计量(如mean、media、70th percentile、90th percentile)作为具体的特征数值。
为了降低工作日、周末对数据的影响,我们选取了跨度4周的性能数据来做相似度计算,下图为两对相似实例的示例。
算法挑战
经 过前部分的处理,公式、参数和目标mr都有了,已经可以代入公式计算出目标BP,接下来需要解决算法在工程落地过程中所面临的问题。
由于hit ratio这个指标并不能直接的反应数据库对业务的影响,导致业务方和DBA都没有直接的体感,并且该指标也不能用来直接衡量数据库业务稳定性。因此,受限于稳定性要求,该算法在无法给出对业务影响的量化数值情况下,尚不能落地具体业务。
针对这个问题,经过与DBA和业务方的多次讨论,我们发现业务方和DBA最关心的是数据库的Response Time(RT),尤其是数据库实例对应用服务时的最大RT。
设想一下,如果可以预测出BP调整后的数据库实例RT的最差值,也就是RT的上界RT upperbound,那么就可以量化的描述出调整BP之后对业务的影响,也就消除了业务方与DBA对该参数优化的担忧,算法就具备了落地生产环境的必要条件。于是,我们对数据库实例RT upperbound进行了算法预测。
RT预测模型
针对RT预测问题,我们提出了一个pairwise的DNN模型,具体的结构如图:
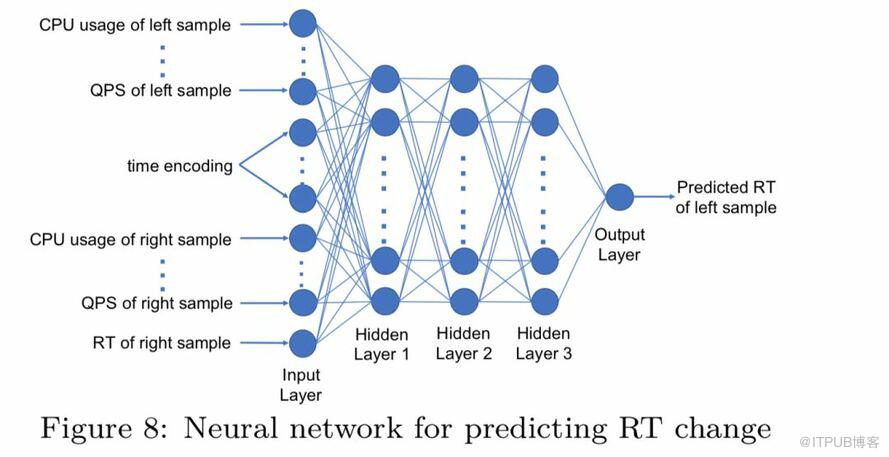
在训练阶段,左实例代表的是我们要预测RT的实例,右实例代表的是某一个相似实例(前面寻找 mrtarget时筛选出的相似实例),左右实例的RT都是已知的。
在测试阶段,我们用该模型来预测实例BP调整后的RT,左右实例均是当前实例,但是把mrcur替换成 mrtarget。
该DNN网络模型中采用了全连接形式,激活函数为ReLU,隐藏层节点数分别为100,50,50。
损失函数:
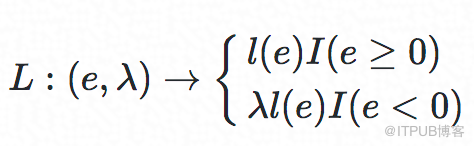
其中I(.)是个指示函数,e=RT− RTpredict,λ∈[0,1]是个超参数,e=RT−RTpredict,用来控制underestimate时的惩罚程度。
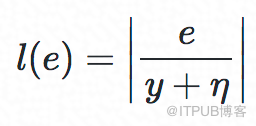
其中,y为实际RT观测值。由于不同实例y的值域跨度很大,我们将e用y来做正则化,同时增加η来避免RT非常小时引入的优化误差。
实验
在预测RT的实验中,我们对比了包括线性回归模型(LR)、XGBoost、RANSAC、决策树(DTree)、ENet、AdaBoost线性回归(Ada)、GBDT、k近邻回归(KNR)、bagging Regressor(BR)、extremely randomized trees regressor (ETR)、随机森林(RF)、sparse subspace clustering (SSC)等回归算法,DNN模型、添加了embedding层进行instance-to-vector转换的DNN(I2V-DNN)模型,以及pairwise DNN模型等深度学习算法。
I2V-DNN的结构如图:
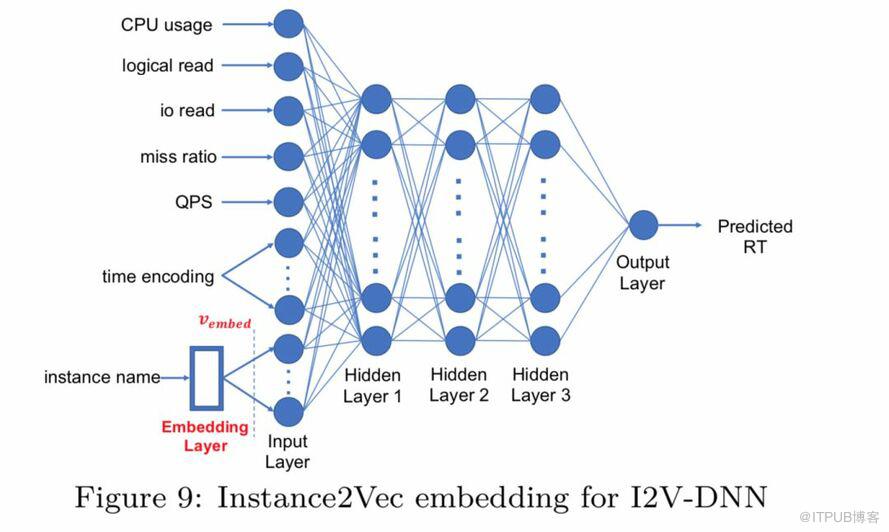
为了证明该算法的普适性,我们从集团数据库的几个重要业务场景中选择了1000个实例,覆盖了不同读写比的示例,包括只读示例、只写实例、读写均衡实例等情况。
在评价算法效果方面,我们主要采用了如下3个评价指标:
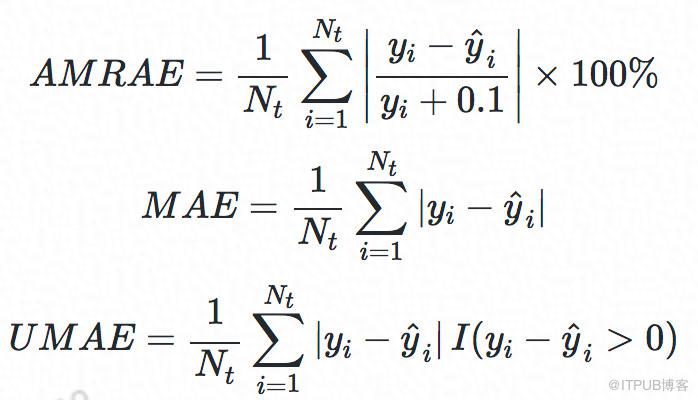
其中,AMRAE可以评估出RT预测结果的误差比例,MAE用于衡量RT预测的平均误差,UMAE用于衡量RT预测值低估的情况。
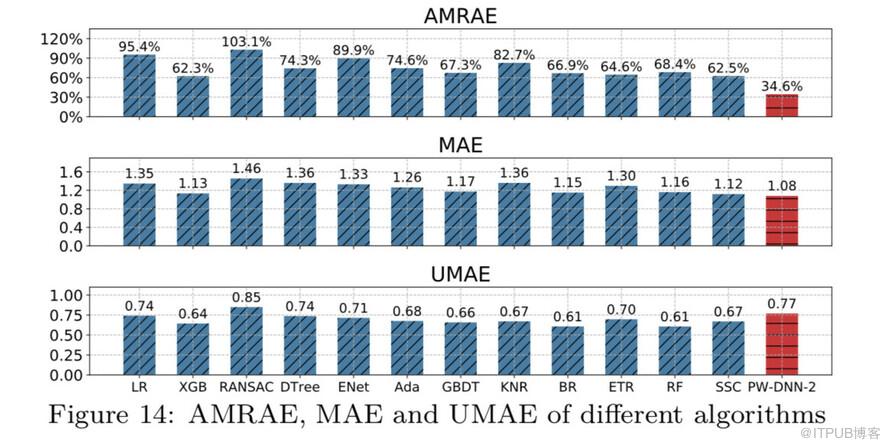
在实验数据集上,RT预测结果对比如图:
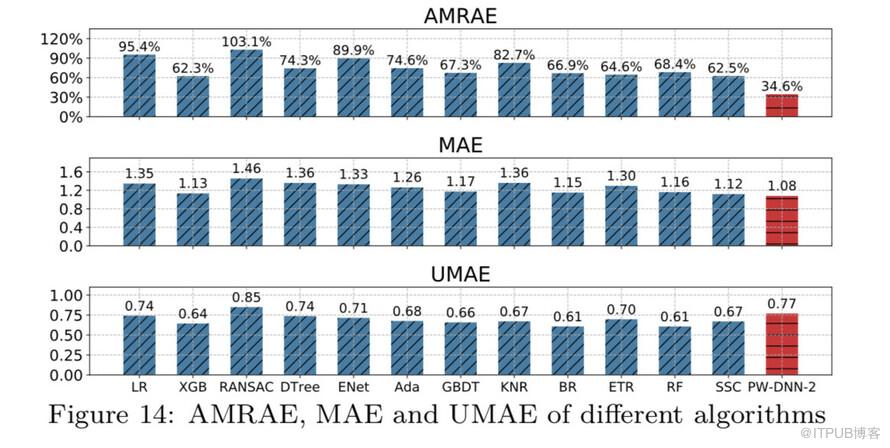
由上图看出,PW-DNN模型在AMRAE这一指标上对比其他算法优势比较明显,综合其他指标,PW-DNN模型的算法效果最好,所以我们最终选择用来预测RT的算法是PW-DNN。
实际效果
为了更加直观的观察实例变更BP前后的变化,我们随机选择了10个实例来展示调整BP前后数据库各项指标,数据如图:
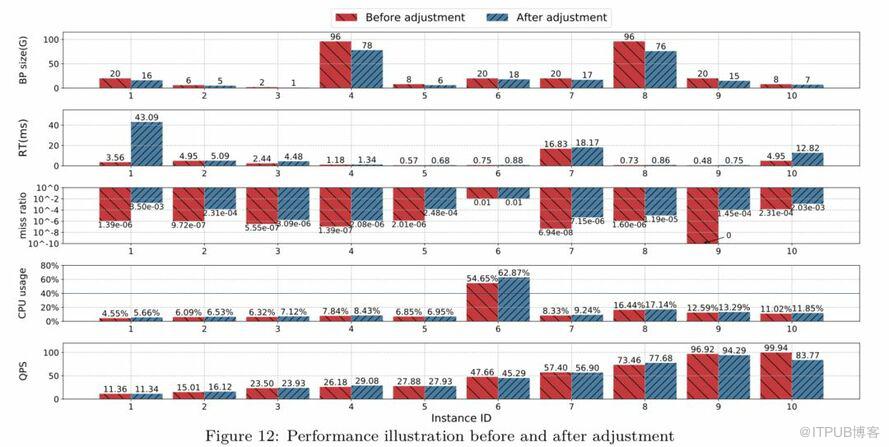
从上图中可以看出,不同规格实例在调整BP之后的RT与调整之前的RT相差不大(实例1除外)。通过QPS、CPU usage可以看出,调整前后的业务访问量相差不大,并且资源消耗很接近,但节省了不同幅度的内存。
在实例1中出现了调整后RT大幅上升的情况,经过对该case的仔细排查发现,该业务的日常QPS非常低,耗时占比最高的只有一个query,在调整后该query查询的值不一样,导致logical read和physical read升高很多,因此最终平均RT的值也升高很多。但是调整后RT的绝对值并不大,没有发生慢SQL异常,对业务来说是可以接受的,因此没有触发回滚操作。
落地
我们实现了一个端到端的算法落地流程,从数据采集到BP优化指令的执行。该系统包含4个主要模块,分别是指标采集、数据处理、决策和执行,模块设计如图:
· 指标采集:数据库管控平台已经实现对集团内全部数据库实例的指标数据采集,覆盖了算法所使用的各项指标;
· 数据处理:采集后的指标经过流式处理进行不同窗口维度的统计汇总,并存储在odps中供算法使用;
· 决策:本文算法的具体实现部分,读取odps中存储的指标统计数据,经算法模型计算得到待优化实例调整后的BP值;
· 执行:数据库管控平台对BP优化指令进行专项实现,并调度该优化操作的具体执行时间窗口,在符合发布约束的前提下高效执行该操作。
稳定性挑战
由于降低BufferPool配置的这个操作是个会降低稳定性的操作,一旦操作不当,轻则给DBA带来额外工作,重则引发业务故障。因此,该项目受到了BU内DBA和各稳定性相关同学的挑战和压力。
我们主要采取了多项措施来确保业务稳定性,具体包括:
1. 算法模型: 调整BufferPool大小与缓存命中率映射关系的敏感系数αα,使调整结果较为保守;
2. 在线调整:我们仅针对可online调整参数的实例进行调整,避免因MySQL内核原因导致MySQL crash的情况;
3. 灰度策略:全网规模化参数调整采用了严格的灰度策略,最开始由业务DBA根据算法给出的BP大小进行少量实例调整,确保业务稳定;然后通过较多实例的白名单机制,仅对白名单中的实例自动调整BufferPool大小,在指定范围内实例上进行灰度;最后,在业务DBA确认过非核心实例上,严格按照发布流程和管控流程进行规模化全自动操作,并严格限制每次操作的数量。
4. 流程闭环:从数据采集,BP大小决策、自动化BP调整到调整后的量化跟踪,以及回滚机制,整个流程闭环,每天发出调整后的统计分析报告。
成果
经过算法探索和端到端自动Buffer Pool优化流程建设,FY2019集团内全网最终优化 ~10000 个实例,将整体内存使用量从 217T内存缩减到 190T内存,节省 12.44%内存资源(27TB)。
未来
业务方面,FY2020我们一方面继续扩大BP优化的实例范围以节省更多的内存资源;另一方面将继续优化该算法模型通过HDM产品输出到公有云,为云上用户提供数据库实例规格建议。
技术方面,我们将从Buffer Pool参数优化扩展到数据库其他性能参数优化,探索多性能参数之间的关系及影响,建立基于数据库负载和性能关系影响模型,从整个数据库实例视角进行统一数据库参数优化。
想了解更多关于数据库、云技术的内容吗?
快来关注“数据和云"、"云和恩墨,"公众号及"云和恩墨"官方网站,我们期待大家一同学习与进步!

数据和云小程序”DBASK“在线问答,随时解惑,欢迎了解和关注!

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。