жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іRedis SortedSetз»“жһ„scoreеӯ—ж®өдёўеӨұзІҫеәҰй—®йўҳи§ЈеҶіеҠһжі•жҳҜд»Җд№ҲпјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒй—®йўҳзҺ°иұЎ
йЎ№зӣ®дёӯйҮҮз”ЁRedis SortedSetеӯҳеӮЁз”ЁжҲ·зҡ„зҰ»зәҝж¶ҲжҒҜпјҢscoreеҖјеӯҳеӮЁзҡ„msgidпјҲж¶ҲжҒҜIDпјүгҖӮmsgidйҮҮз”Ёsnowflakeз®—жі•з”ҹжҲҗпјҢжҢүз…§ж—¶й—ҙжңүеәҸгҖӮ
з”ҹжҲҗзҡ„msgidжңү18дҪҚеҚҒиҝӣеҲ¶ж•ҙж•°пјҢдҫӢеҰӮ 215857550229364736
жҲ‘们еҸ‘зҺ°ж•°еҖјеҫҲжҺҘиҝ‘зҡ„msgidпјҢеңЁredisдёӯж— жі•йҖҡиҝҮscoreиҝӣиЎҢеҢәеҲҶгҖӮ
дёҫдёӘеҲ—еӯҗпјҢеңЁredisдёӯtzsetз»“жһ„йҮҢеӯҳе…ҘеҰӮдёӢеҮ жқЎж•°жҚ®
ZADD tzset 215857497028812800 test1
ZADD tzset 215857540511162369 test2
ZADD tzset 215857550229364736 test3
ZADD tzset 215857550229364737 test4
жҹҘиҜўзңӢдёҖдёӢз»“жһң
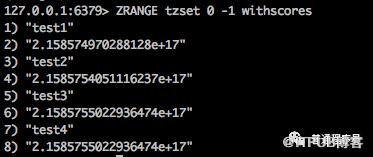
жҲ‘们еҸ‘зҺ°scoreеҖјйҮҮ用科еӯҰи®Ўж•°жі•иЎЁзӨәпјҢtest3,test4дёӨдёӘе…ғзҙ зҡ„scoreеҖјжҳҫзӨәжҳҜдёҖж ·зҡ„гҖӮ
дҪҝз”Ёscore=215857550229364736 жү§иЎҢжҹҘиҜўпјҢз»“жһңеҰӮдёӢеӣҫ

дҪҝз”Ё215857550229364736жҹҘиҜўпјҢз»“жһңscoreдёә215857550229364737зҡ„test4д№ҹиў«жҹҘеҮәжқҘдәҶ
з”Ё215857550229364739еҺ»жҹҘпјҢз«ҹ然д№ҹиғҪжҹҘеҮәжқҘ

иҝҷдёҖзҺ°иұЎз»ҷжҲ‘们зҡ„зі»з»ҹеҠҹиғҪеёҰдәҶеӣ°жү°пјҢдјҡеҪұе“ҚеҲ°ж¶ҲжҒҜеҗҢжӯҘTimeLineзҡ„зІҫзЎ®жҖ§пјҲеҸӮзңӢгҖҠеҹәдәҺTimeLineжЁЎеһӢзҡ„ж¶ҲжҒҜеҗҢжӯҘжңәеҲ¶гҖӢпјүгҖӮ
дәҢгҖҒй—®йўҳеҺҹеӣ
жҹҘиҜўзӣёе…іиө„ж–ҷеҸ‘зҺ°Sorted Setsдёӯзҡ„ScoreжҳҜdoubleзұ»еһӢпјҢжҲ‘们зҡ„msgidжҳҜlongзұ»еһӢгҖӮй—®йўҳжҳҜlongиҪ¬жҚўдёәdoubleж—¶пјҢдёўеӨұзІҫеәҰгҖӮ
1гҖҒsnowflakeз®—жі•з®Җд»Ӣ
ж¶ҲжҒҜIDйҮҮз”Ёsnowflakeз®—жі•пјҢйҮҮз”Ё64дҪҚдәҢиҝӣеҲ¶ж•ҙж•°гҖӮдәҢиҝӣеҲ¶е…·дҪ“дҪҚж•°еҗ«д№үеҰӮдёӢеӣҫгҖӮ
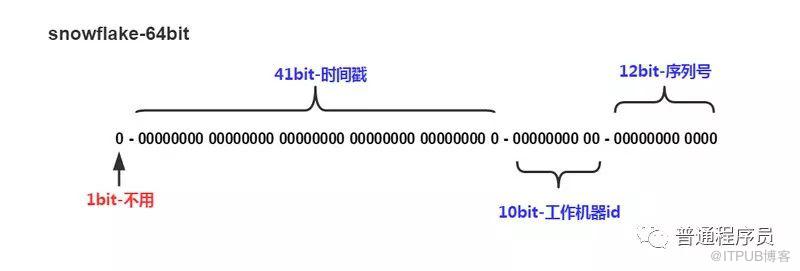
1дҪҚпјҢдёҚз”ЁгҖӮдәҢиҝӣеҲ¶дёӯжңҖй«ҳдҪҚдёә1зҡ„йғҪжҳҜиҙҹж•°пјҢдҪҶжҳҜжҲ‘们з”ҹжҲҗзҡ„idйғҪдҪҝз”ЁжӯЈж•°пјҢжүҖд»ҘиҝҷдёӘжңҖй«ҳдҪҚеӣәе®ҡжҳҜ0
41дҪҚпјҢз”ЁжқҘи®°еҪ•ж—¶й—ҙжҲіпјҲжҜ«з§’пјүгҖӮ
еҰӮжһңеҸӘз”ЁжқҘиЎЁзӨәжӯЈж•ҙж•°пјҲи®Ўз®—жңәдёӯжӯЈж•°еҢ…еҗ«0пјүпјҢеҸҜд»ҘиЎЁзӨәзҡ„ж•°еҖјиҢғеӣҙжҳҜпјҡ0 иҮі 241вҲ’1пјҢеҮҸ1жҳҜеӣ дёәеҸҜиЎЁзӨәзҡ„ж•°еҖјиҢғеӣҙжҳҜд»Һ0ејҖе§Ӣз®—зҡ„пјҢиҖҢдёҚжҳҜ1гҖӮ
д№ҹе°ұжҳҜиҜҙ41дҪҚеҸҜд»ҘиЎЁзӨә241вҲ’1дёӘжҜ«з§’зҡ„еҖјпјҢиҪ¬еҢ–жҲҗеҚ•дҪҚе№ҙеҲҷжҳҜ(241вҲ’1)/(1000вҲ—60вҲ—60вҲ—24вҲ—365)=69е№ҙ
10дҪҚпјҢз”ЁжқҘи®°еҪ•е·ҘдҪңжңәеҷЁidгҖӮ
еҸҜд»ҘйғЁзҪІеңЁ1024дёӘиҠӮзӮ№пјҢеҢ…жӢ¬5дҪҚdatacenterIdе’Ң5дҪҚworkerId
12дҪҚпјҢеәҸеҲ—еҸ·пјҢз”ЁжқҘи®°еҪ•еҗҢжҜ«з§’еҶ…дә§з”ҹзҡ„дёҚеҗҢidгҖӮ
12дҪҚпјҲbitпјүеҸҜд»ҘиЎЁзӨәзҡ„жңҖеӨ§жӯЈж•ҙж•°жҳҜ4095пјҢеҚіеҸҜд»Ҙз”Ё0гҖҒ1гҖҒ2гҖҒ3гҖҒ....4095иҝҷ4096дёӘж•°еӯ—пјҢжқҘиЎЁзӨәеҗҢдёҖжңәеҷЁеҗҢдёҖж—¶й—ҙжҲӘпјҲжҜ«з§’)еҶ…дә§з”ҹзҡ„4096дёӘIDеәҸеҸ·
2гҖҒdoublelж•°жҚ®з»“жһ„
doubleж•°жҚ®зҡ„з»“жһ„еҰӮдёӢеӣҫ

3гҖҒй—®йўҳе®ҡдҪҚ
63bitпјҲеҺ»жҺүз¬ҰеҸ·дҪҚпјүзҡ„ж•°иҪ¬жҚўдёә52bitзҡ„ж•°пјҢд»ҺжҹҗдёҖдҪҚејҖе§ӢиҝӣиЎҢдәҶеӣӣиҲҚдә”е…ҘпјҢеҜјиҮҙзІҫеәҰдёӢйҷҚгҖӮжүҖд»Ҙ215857550229364736гҖҒ215857550229364737гҖҒ215857550229364739дёүдёӘж•°жҚ®иў«иҪ¬жҚўдёәdoubleзұ»еһӢеҗҺпјҢи®Ўз®—жңәи®ӨдёәжҳҜзӣёеҗҢзҡ„ж•°гҖӮ
дёүгҖҒи§ЈеҶіеҠһжі•
й—®йўҳжүҫеҲ°дәҶпјҢжҖҺд№Ҳи§ЈеҶіе‘ўпјҹ
idз”ҹжҲҗзӯ–з•ҘиҰҒдҝқиҜҒж•ҙдёӘзі»з»ҹз”ҹе‘Ҫе‘Ёжңҹзұ»жүҖжңүIDе”ҜдёҖпјҢи®ҫи®ЎдёҖдёӘ52bitзҡ„IDз”ҹжҲҗеҷЁдҝқиҜҒIDе”ҜдёҖйҡҫеәҰиҫғеӨ§гҖӮ
Redisзҡ„scoreж•°жҚ®зұ»еһӢжӣҙжҳҜдҝ®ж”№дёҚдәҶ
з”Ё52bitжқҘиЎЁзӨә63bitзҡ„ж•°жҚ®дёҖе®ҡдјҡдёўеӨұдҝЎжҒҜпјҢй•ҝж•ҙеһӢlongй»ҳи®ӨиҪ¬жҚўдёәdoubleзҡ„ж–№ејҸдёўеӨұзҡ„дҝЎжҒҜдјҡеҪұе“ҚеҲ°дёҡеҠЎпјҢиғҪдёҚиғҪз»“еҗҲдёҡеҠЎзү№зӮ№иҮӘе®ҡд№үдёҖз§ҚиҪ¬жҚўпјҲжҳ е°„пјүж–№ејҸпјҢзӯ”жЎҲжҳҜиӮҜе®ҡзҡ„гҖӮ
жңүд»ҘдёӢеҮ з§Қжғіжі•
1гҖҒеӣ дёәRedisзј“еӯҳзҡ„ж¶ҲжҒҜжңҖеӨҡдҝқеӯҳ15еӨ©пјҲеҒҮи®ҫпјүжҲ–иҖ…жңҖеӨҡдҝқеӯҳеӨҡе°‘жқЎгҖӮиғҪдёҚиғҪжҲӘеҺ»41дҪҚж—¶й—ҙжҲізҡ„йғЁеҲҶй«ҳдҪҚпјҢзЎ®дҝқRedisзј“еӯҳж—¶й—ҙе‘ЁжңҹеҶ…ж—¶й—ҙжҲій•ҝеәҰеӨҹз”Ёе°ұиЎҢе‘ўпјҹи®Ўз®—дәҶдёҖдёӢй•ҝеәҰ log(15*24*60*60*1000)=30.2пјҢеӨ§зәҰ30дҪҚдәҢиҝӣеҲ¶ж•°еҚіеҸҜеңЁзҺ°жңү规еҲҷдёӢиЎЁзӨә15еӨ©ж—¶й—ҙгҖӮжүҖд»Ҙе°Ҷ41дҪҚж—¶й—ҙжҲізҡ„еүҚ11дҪҚеұҸи”ҪжҺүпјҢеҸҜд»ҘиҠӮзәҰ11дҪҚдәҢиҝӣеҲ¶дҝЎжҒҜгҖӮиҝҷж ·63bitеҲҡеҘҪиғҪз”Ё52bitжқҘиЎЁзӨәгҖӮ
然иҖҢиҝҷдёӘж–№ејҸжңүдёӘиҮҙе‘Ҫй—®йўҳпјҢеҪ“15еӨ©ж—¶й—ҙе‘ЁжңҹеҲ°дәҶеҗҺпјҢж—¶й—ҙжҲідјҡеҸҳеҫ—зү№еҲ«е°ҸпјҲж–°зҡ„е‘ЁжңҹпјүпјҢиҝҷеҜјиҮҙдёҠдёҖдёӘе‘ЁжңҹеҗҺиҫ№зҡ„ж•°жҚ®ScoreеҖјеӨ§дәҺж–°е‘ЁжңҹгҖӮж¶ҲжҒҜйЎәеәҸж··д№ұдәҶпјҢдјҡеҜјиҮҙжӢүзҰ»зәҝдёўж¶ҲжҒҜпјҢиҝҷдёҚиғҪжҺҘеҸ—пјҒ
2гҖҒеҺ»жҺү10bitе·ҘдҪңжңәidе’ҢеәҸеҲ—еҸ·зҡ„жңҖй«ҳдҪҚbitгҖӮ
еҺ»жҺүиҝҷ11bitпјҢдёҚдјҡеҜ№ж¶ҲжҒҜзҡ„йЎәеәҸйҖ жҲҗеҪұе“ҚпјҢдҪҶжҳҜеҸҜиғҪйҖ жҲҗscoreж•°еҖјеҶІзӘҒпјҲзӣёеҗҢпјүгҖӮеҲҶжһҗдёҖдёӢscoreеҶІзӘҒзҡ„еҸҜиғҪжҖ§гҖӮ
пјҲ1пјү12bitеәҸеҲ—еҸ·иғҪиЎЁзӨә4096дёӘж•°гҖӮеҺ»жҺүжңҖй«ҳдҪҚпјҢиғҪиЎЁзӨә2048дёӘж•°гҖӮжүҖд»ҘеҚ•дёӘmsgidз”ҹжҲҗиҠӮзӮ№пјҲdispatchжЁЎеқ—пјүжҜҸжҜ«з§’пјҢжҜҸдёӘз”ЁжҲ·иҰҒи¶…иҝҮ2048жқЎж¶ҲжҒҜпјҢжүҚеҸҜиғҪеҮәзҺ°scoreйҮҚеӨҚгҖӮиҝҷдёӘеҹәжң¬дёҚеҸҜиғҪеҸ‘з”ҹгҖӮ
пјҲ2пјүеҺ»жҺү10bitе·ҘдҪңжңәidеҸ·пјҢйңҖиҰҒеҗҢдёҖжҜ«з§’пјҢеҗҢдёҖз”ЁжҲ·еңЁдёҚеҗҢзҡ„dispatchиҠӮзӮ№йғҪжҺҘ收еҲ°ж¶ҲжҒҜпјҢscoreжүҚеҸҜиғҪеҶІзӘҒгҖӮеҚідҪҝеҮәзҺ°иҝҷз§Қжғ…еҶөпјҢз”ұдәҺ12дҪҚеәҸеҲ—еҸ·жҲ‘们еҒҡдәҶжЁЎ128зҡ„йҡҸжңәеҲҶеёғпјҲи§ЈеҶіеҲҶеә“й—®йўҳпјүпјҢеҚідҪҝеҮәзҺ°еҗҢдёҖжҜ«з§’дёҚеҗҢdisptchз”ҹжҲҗеҗҢдёҖз”ЁжҲ·msgidзҡ„жғ…еҶөдёӢпјҢscoreеҶІзӘҒзҡ„жҰӮзҺҮиҝҳиҰҒйҷӨд»Ҙ 128*128гҖӮиҝҷдёӘжҰӮзҺҮйқһеёёдҪҺгҖӮ
пјҲ3пјүеҚідҪҝеҮәзҺ°дәҶscoreеҶІзӘҒпјҲдёӨжқЎж¶ҲжҒҜжңүзӣёеҗҢscoreпјүпјҢжңҖеӨҡйҖ жҲҗжӢүеҸ–зҰ»зәҝж¶ҲжҒҜеӨҡжӢүеҸ–зӣёеҗҢscoreзҡ„ж¶ҲжҒҜпјҲжң¬жқҘдёҖж¬ЎжӢүеҸ–10жқЎзҰ»зәҝпјҢз»“жһңеҸҜиғҪжӢүеҲ°11жқЎпјүпјҢеҜ№дёҡеҠЎд№ҹжІЎжңүеҪұе“ҚгҖӮ
еӣ жӯӨйҮҮз”ЁеҺ»жҺү10bitе·ҘдҪңжңәidе’ҢеәҸеҲ—еҸ·зҡ„жңҖй«ҳдҪҚbitе°Ҷ63bitпјҲдёҚеҗ«з¬ҰеҸ·дҪҚпјүзҡ„msgidиҪ¬жҚўжҲҗ52bitзҡ„scoreеҜ№дёҡеҠЎдёҠжІЎжңүеҪұе“ҚгҖӮеҗҢж—¶и§ЈеҶідәҶredis sorted setдёўеӨұзІҫеәҰзҡ„й—®йўҳгҖӮ
еӣ жӯӨйҮҮз”ЁеҺ»жҺү10bitе·ҘдҪңжңәidе’ҢеәҸеҲ—еҸ·зҡ„жңҖй«ҳдҪҚbitе°Ҷ63bitпјҲдёҚеҗ«з¬ҰеҸ·дҪҚпјүзҡ„msgidиҪ¬жҚўжҲҗ52bitзҡ„scoreеҜ№дёҡеҠЎдёҠжІЎжңүеҪұе“ҚгҖӮеҗҢж—¶и§ЈеҶідәҶredis sorted setдёўеӨұзІҫеәҰзҡ„й—®йўҳгҖӮ
дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„Redis SortedSetз»“жһ„scoreеӯ—ж®өдёўеӨұзІҫеәҰй—®йўҳи§ЈеҶіеҠһжі•жҳҜд»Җд№ҲдәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ