您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇“LevelDB数据文件SSTable结构是怎样的”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“LevelDB数据文件SSTable结构是怎样的”文章吧。
SSTable 文件的内容分为 5 个部分,Footer、IndexBlock、MetaIndexBlock、FilterBlock 和 DataBlock。其中存储了键值对内容的就是 DataBlock,存储了布隆过滤器二进制数据的是 FilterBlock,DataBlock 有多个,FilterBlock 也可以有多个,但是通常最多只有 1 个,之所以设计成多个是考虑到扩展性,也许未来会支持其它类型的过滤器。另外 3 个部分为管理块,其中 IndexBlock 记录了 DataBlock 相关的元信息,MetaIndexBlock 记录了过滤器相关的元信息,而 Footer 则指出 IndexBlock 和 MetaIndexBlock 在文件中的偏移量信息,它是元信息的元信息,它位于 sstable 文件的尾部。下面我们至顶向下挨个分析每个结构
它的占用空间很小只有 48 字节,内部只存了几个字段。下面我们用伪代码来描述一下它的结构
// 定义了数据块的位置和大小
struct BlockHandler {
varint offset;
varint size;
}
struct Footer {
BlockHandler metaIndexHandler; // MetaIndexBlock的文件偏移量和长度
BlockHandler indexHandler; // IndexBlock的文件偏移量和长度
byte[n] padding; // 内存垫片
int32 magicHighBits; // 魔数后32位
int32 magicLowBits; // 魔数前32位
}
Footer 结构的中间部分增加了内存垫片,其作用就是将 Footer 的空间撑到 48 字节。结构的尾部还有一个 64位的魔术数字 0xdb4775248b80fb57,如果文件尾部的 8 字节不是这个数字说明文件已经损坏。这个魔术数字的来源很有意思,它是下面返回的字符串的前64bit。
$ echo http://code.google.com/p/leveldb/ | sha1sum
db4775248b80fb57d0ce0768d85bcee39c230b61
IndexBlock 和 MetaIndexBlock 都只有唯一的一个,所以分别使用一个 BlockHandler 结构来存储偏移量和长度。
除了 Footer 之外,其它部分都是 Block 结构,在名称上也都是以 Block 结尾。所谓的 Block 结构是指除了内部的有效数据外,还会有额外的压缩类型字段和校验码字段。
struct Block {
byte[] data;
int8 compressType;
int32 crcValue;
}
每一个 Block 尾部都会有压缩类型和循环冗余校验码(crcValue),这会要占去 5 字节。如果是压缩类型,块内的数据 data 会被压缩。校验码会针对压缩和的数据和压缩类型字段一起计算循环冗余校验和。压缩算法默认是 snappy ,校验算法是 crc32。
crcValue = crc32(data, compressType)
在下面介绍的所有 Block 结构中,我们不再提及压缩和校验码。
DataBlock 的大小默认是 4K 字节(压缩前),里面存储了一系列键值对。前面提到 sst 文件里面的 Key 是有序的,这意味着相邻的 Key 会有很大的概率有共同的前缀部分。正是考虑到这一点,DataBlock 在结构上做了优化,这个优化可以显著减少存储空间。
Key = sharedKey + unsharedKey
Key 会划分为两个部分,一个是 sharedKey,一个是 unsharedKey。前者表示相对基准 Key 的共同前缀内容,后者表示相对基准 Key 的不同后缀部分。
比如基准 Key 是 helloworld,那么 hellouniverse 这个 Key 相对于基准 Key 来说,它的 sharedKey 就是 hello,unsharedKey 就是 universe。
DataBlock 中存储的是连续的一系列键值对,它会每隔若干个 Key 设置一个基准 Key。基准 Key 的特点就是它的 sharedKey 部分是空串。基准 Key 的位置,也就是它在块中的偏移量我们称之为「重启点」RestartPoint,在 DataBlock 中会记录所有「重启点」位置。第一个「重启点」的位置是零,也就是 DataBlock 中的第一个 Key。
struct Entry {
varint sharedKeyLength;
varint unsharedKeyLength;
varint valueLength;
byte[] unsharedKeyContent;
byte[] valueContent;
}
struct DataBlock {
Entry[] entries;
int32 [] restartPointOffsets;
int32 restartPointCount;
}
DataBlock 中基准 Key 是默认每隔 16 个 Key 设置一个。从节省空间的角度来说,这并不是一个智能的策略。比如连续 26 个 Key 仅仅是最后一个字母不同,DataBlock 却每隔 16 个 Key 强制「重启」,这明显不是最优的。这同时也意味着 sharedKey 是空串的 Key 未必就是基准 Key。
一个 DataBlock 的默认大小只有 4K 字节,所以里面包含的键值对数量通常只有几十个。如果单个键值对的内容太大一个 DataBlock 装不下咋整?
这里就必须纠正一下,DataBlock 的大小是 4K 字节,并不是说它的严格大小,而是在追加完最后一条记录之后发现超出了 4K 字节,这时就会再开启一个 DataBlock。这意味着一个 DataBlock 可以大于 4K 字节,如果 value 值非常大,那么相应的 DataBlock 也会非常大。DataBlock 并不会将同一个 Value 值分块存储。
如果没有开启布隆过滤器,FilterBlock 这个块就是不存在的。FilterBlock 在一个 SSTable 文件中可以存在多个,每个块存放一个过滤器数据。不过就目前 LevelDB 的实现来说它最多只能有一个过滤器,那就是布隆过滤器。
布隆过滤器用于加快 SSTable 磁盘文件的 Key 定位效率。如果没有布隆过滤器,它需要对 SSTable 进行二分查找,Key 如果不在里面,就需要进行多次 IO 读才能确定,查完了才发现原来是一场空。布隆过滤器的作用就是避免在 Key 不存在的时候浪费 IO 操作。通过查询布隆过滤器可以一次性知道 Key 有没有可能在里面。
单个布隆过滤器中存放的是一个定长的位图数组,该位图数组中存放了若干个 Key 的指纹信息。这若干个 Key 来源于 DataBlock 中连续的一个范围。FilterBlock 块中存在多个连续的布隆过滤器位图数组,每个数组负责指纹化 SSTable 中的一部分数据。
struct FilterEntry {
byte[] rawbits;
}
struct FilterBlock {
FilterEntry[n] filterEntries;
int32[n] filterEntryOffsets;
int32 offsetArrayOffset;
int8 baseLg; // 分割系数
}
其中 baseLg 默认 11,表示每隔 2K 字节(2<<11)的 DataBlock 数据(压缩后),就开启一个布隆过滤器来容纳这一段数据中 Key 值的指纹。如果某个 Value 值过大,以至于超出了 2K 字节,那么相应的布隆过滤器里面就只有 1 个 Key 值的指纹。每个 Key 对应的指纹空间在打开数据库时指定。
// 每个 Key 占用 10bit 存放指纹信息
options.SetFilterPolicy(levigo.NewBloomFilter(10))
这里的 2K 字节的间隔是严格的间隔,这样才可以通过 DataBlock 的偏移量和大小来快速定位到相应的布隆过滤器的位置 FilterOffset,再进一步获得相应的布隆过滤器位图数据。
MetaIndexBlock 存储了前面一系列 FilterBlock 的元信息,它在结构上和 DataBlock 是一样的,只不过里面 Entry 存储的 Key 是带固定前缀的过滤器名称,Value 是对应的 FilterBlock 在文件中的偏移量和长度。
key = "filter." + filterName
// value 定义了数据块的位置和大小
struct BlockHandler {
varint offset;
varint size;
}
就目前的 LevelDB,这里面最多只有一个 Entry,那么它的结构非常简单,如下图所示
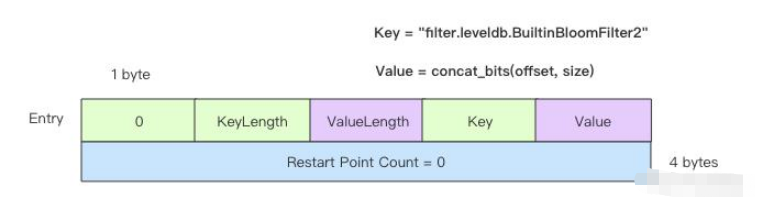
IndexBlock 结构
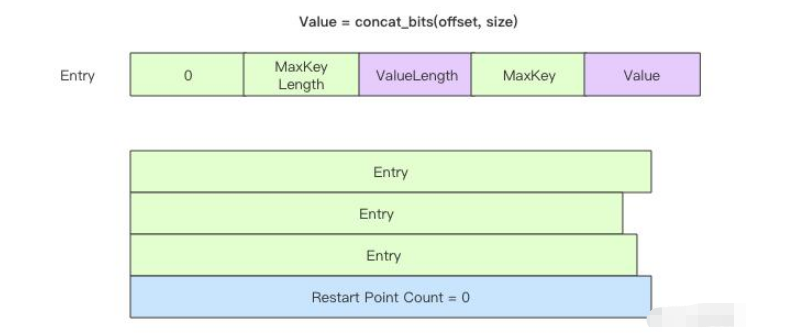
它和 MetaIndexBlock 结构一样,也存储了一系列键值对,每一个键值对存储的是 DataBlock 的元信息,SSTable 中有几个 DataBlock,IndexBlock 中就有几个键值对。键值对的 Key 是对应 DataBlock 内部最大的 Key,Value 是 DataBlock 的偏移量和长度。不考虑 Key 之间的前缀共享,不考虑「重启点」,它的结构如下图所示
以上就是关于“LevelDB数据文件SSTable结构是怎样的”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。