您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、遇到问题
某个项目采用了数据库(MySQL)自增ID作为主要业务数据的主键。数据库自增ID使用简单,自动编号,速度快,而且是增量增长,按顺序存放,对于检索非常有利。
单库环境下,数据库自增ID问题不大。但在分布式环境或分库分表环境下,数据库自增ID逐渐暴露出一些问题。例如,分库分表的情况下保证ID唯一变得困难;订单号等业务数据如果用数据库自增ID,竞对很容易算出大概的业务量。
二、常见的ID生成策略
1、数据库自增ID(前面提到了)
2、UUID
算法的核心思想是结合机器的网卡、当地时间、一个随记数来生成UUID。
优点:本地生成,生成简单,性能好,没有高可用风险
缺点:长度过长,存储冗余,且无序不可读,查询效率低
3、Redis生成ID
Redis生成ID可以看做数据库自增ID的升级版。Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
优点:不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:如果系统中没有Redis,还需要引入新的组件,增加系统复杂度;需要编码和配置的工作量比较大。
考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量。假如一个集群中有5台 Redis。可以初始化每台 Redis 的值分别是1, 2, 3, 4, 5,然后步长都是 5。各个 Redis 生成的 ID 为

4、Twitter的snowflake算法。
三、snowflake算法
snowflake算法,采用64位二进制整数。二进制具体位数含义如下图。
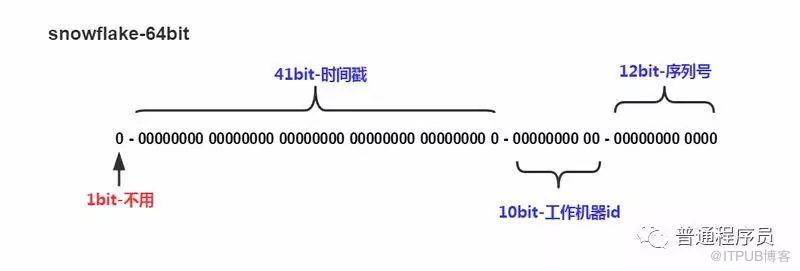
1位,不用。二进制中最高位为1的都是负数,但是我们生成的id都使用正数,所以这个最高位固定是0
41位,用来记录时间戳(毫秒)。
如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 241−1,减1是因为可表示的数值范围是从0开始算的,而不是1。
也就是说41位可以表示241−1个毫秒的值,转化成单位年则是(241−1)/(1000∗60∗60∗24∗365)=69年
10位,用来记录工作机器id。
可以部署在1024个节点,包括5位datacenterId和5位workerId
12位,序列号,用来记录同毫秒内产生的不同id。
12位(bit)可以表示的最大正整数是4095,即可以用0、1、2、3、....4095这4096个数字,来表示同一机器同一时间截(毫秒)内产生的4096个ID序号
大多数人都知道这个算法,但Twitter 利用 zookeeper 还做了很多工程上的实现,感兴趣可以看https://github.com/twitter/snowflake
截取git上该工程的主要文件目录,
git工程README.md文件中有这么一段话
We have retired the initial release of Snowflake and working on open sourcing the next version based on Twitter-server, in a form that can run anywhere without requiring Twitter's own infrastructure services.
Twitter几年前就停止了对这个项目的维护,新的版本也没见着放出来。好在现有版本的核心算法已经能够满足常规的需求。
当然,snowflake有众多优点的同时也是有缺点的。
优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
可以根据自身业务特性分配bit位,非常灵活。
缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
强依赖时钟在有些情况下很致命,我个人就遇到过服务器刚重启的短时间内时间没有同步,造成生成ID出问题的情况!
四、一些改进策略
1、美团Leaf比较完美的方案
美团Leaf比较好的解决了这些问题,参看《Leaf——来自美团点评的分布式ID生成系统》
美团Leaf的方案核心有两点
(1)依靠zookeeper实现workerId的自动化租用
(2)通过算法解决了时钟回拨问题
美团Leaf目前是开源软件,可以在https://github.com/weizhenyi/leaf-snowflake下载
2、一个候选人不严谨但成本很低的实现
我在面试中,一个候选人提出的方法也比较有意思(尽管这个方法不严谨)。
在redis中设置一个整数变量workerNum,初始值为0,snowflake id生成客户端每次启动时读取redis中的变量,用workerNum%1024作为worker的值,然后把redis中的workerNum+1。
在idworker数量不多的情况下,这个方案一般不会出现workerId重复(因为随着业务的迭代,一般情况下idworker过一段时间都会因为业务部署而重启)。如果研发资源特别有限,又想使用snowflake可以考虑一下这个办法。

3、个人项目中hash分库的解决办法
实际使用中,有时候ID需要支持分库分表,snowflake的默认实现对这块支持得不够。在业务量不大的情况下,snowflake生成的id序列号部分大多都是0,转换为十进制会是偶数。用这个id通过取模hash分库,显然不平均。
万一有这样的需求怎么办呢?可以考虑借助ID时间戳部分实现均匀分布
(1)分库分表逻辑使用ID中时间戳部分做取模。这个方法需要把10进制ID转成2进制,然后移位,再进行计算。比较麻烦
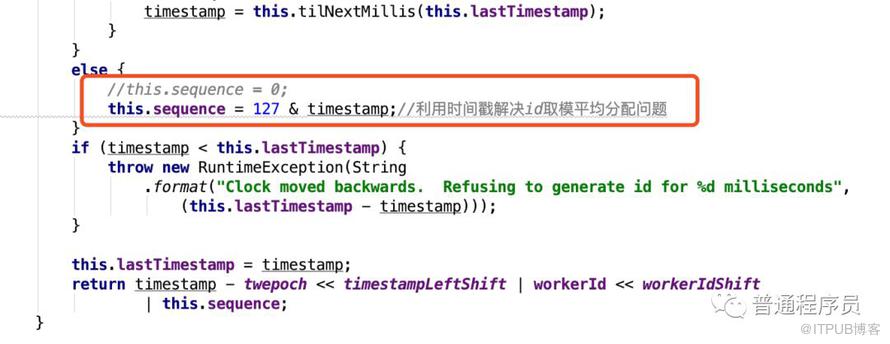
(2)生成ID的时候把序列号部分尾数用时间戳对应的位置覆盖。截段代码,这段代码的取值能保证ID除以128的余数均匀分布。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。