您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》

HAWQ, 取自Hadoop With Query,这是一款原生Hadoop并行SQL引擎。同时作为一款面向企业的分析型数据库HAWQ有很多优良的特性,例如它完整兼容ANSI-SQL标准语法,支持标准JDBC/ODBC连接,支持ACID事务特性,高性能,拥有比传统MPP数据库更先进的弹性执行引擎,可以秒级动态加减节点,拥有各种容错机制,支持多级资源和负载管理,提供Hadoop上PB级数据高性能交互式查询能力,并且提供对主要BI工具的描述性分析支持,以及支持预测型分析的机器学习库。目前HAWQ属于Apache的孵化项目,即将成为Apache顶级项目。而由HAWQ创始团队成立的偶数科技推出的HAWQ++则是基于Apache HAWQ的增强企业版。
HAWQ++体系架构
HAWQ++是典型的主从架构。其中有几个Master节点:HAWQ++ master节点,HDFS master节点NameNode,YARN master节点ResourceManager。现阶段HAWQ++元数据服务还集成在HAWQ++ master节点里面,未来会独立开来成为单独的Catalog Service。将元数据独立会带来很多的好处,一方面可以将HAWQ++元数据与Hadoop集群元数据进行融合,另一方面可以不再区分HAWQ++ master/slave角色,任意节点都可以接收查询处理查询,更好地实现负载均衡。HAWQ++每个Slave节点上都部署有一个HDFS DataNode,一个YARN NodeManager以及一个HAWQ++ Segment。其中YARN是可选组件。如果没有YARN的话,HAWQ++会使用自己内置的资源管理器。HAWQ++ Segment在执行查询的时候会启动多个QE(Query Executor,查询执行器)。查询执行器运行在资源容器里。在这个架构下,节点可以动态的加入集群,并且不需要数据重分布。当一个节点加入集群时,它会向HAWQ++ Master节点发送心跳,然后就可以接收未来查询了。
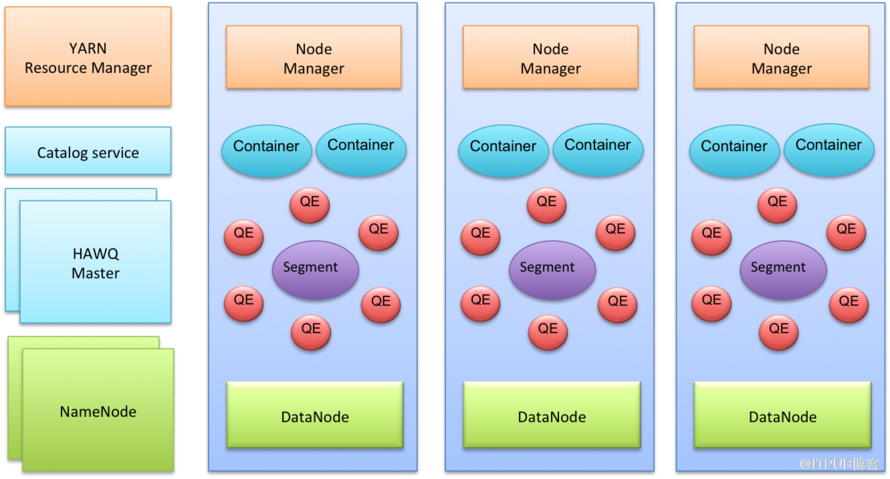
图1 HAWQ++体系架构
HAWQ++内部架构
图2是HAWQ++内部架构图。可以看到在HAWQ++ Master节点内部有如下重要组件:查询解析器,优化器,资源代理,资源管理器,HDFS元数据缓存,容错服务,查询派遣器和元数据服务。在Slave节点上安装有一个物理Segment,在查询执行时,针对一个查询,弹性执行引擎会启动多个虚拟Segment同时执行查询,节点间数据交换通过Interconnect(高速互联网络)进行。如果一个查询启动了1000个虚拟Segment,意思是这个查询被均匀的分成了1000份任务,这些任务会并行执行。所以说虚拟Segment数其实表明了查询的并行度。查询的并行度是由弹性执行引擎根据查询大小以及当前资源使用情况动态确定的。这里简单说一下几个组件的作用。Parser做词法语法分析,生成一棵Parse Tree,交给Analyzer做语义分析生成一棵Query Tree,再经过基于规则系统的Rewriter将一棵Query Tree可能改写成Query Tree List,交给优化器做逻辑优化和基于cost的物理优化,生成优化的并行Plan。资源管理器通过资源代理向全局资源管理器(比如YARN)动态申请资源并缓存资源,在不需要的时候返回资源。HDFS元数据缓存用于确定HAWQ++哪些Segment扫描表的哪些部分。因为HAWQ++的计算和数据是完全分离的,所以需要data locality信息把计算派遣到数据所在的地方。如果每个查询都去访问NameNode获取位置信息会造成NameNode的瓶颈,所以建立了元数据缓存。容错服务负责检测哪些节点可用,哪些节点不可用。不可用的机器会被排除出资源池。优化完的Plan由查询派遣器发送到各个节点上执行,并协调查询执行的全过程。元数据服务负责存储HAWQ++的各种元数据,包括数据库和表信息,以及访问权限等等。高速互联网络负责在各节点间传输数据,默认基于UDP协议。UDP协议不需要建立连接,可以避免TCP高并发连接数的限制。HAWQ++通过libhdfs3模块访问HDFS。libhdfs3是Hadoop Native的C/C++接口,相比JNI的接口具有部署方便,消耗资源少和高性能的优势。
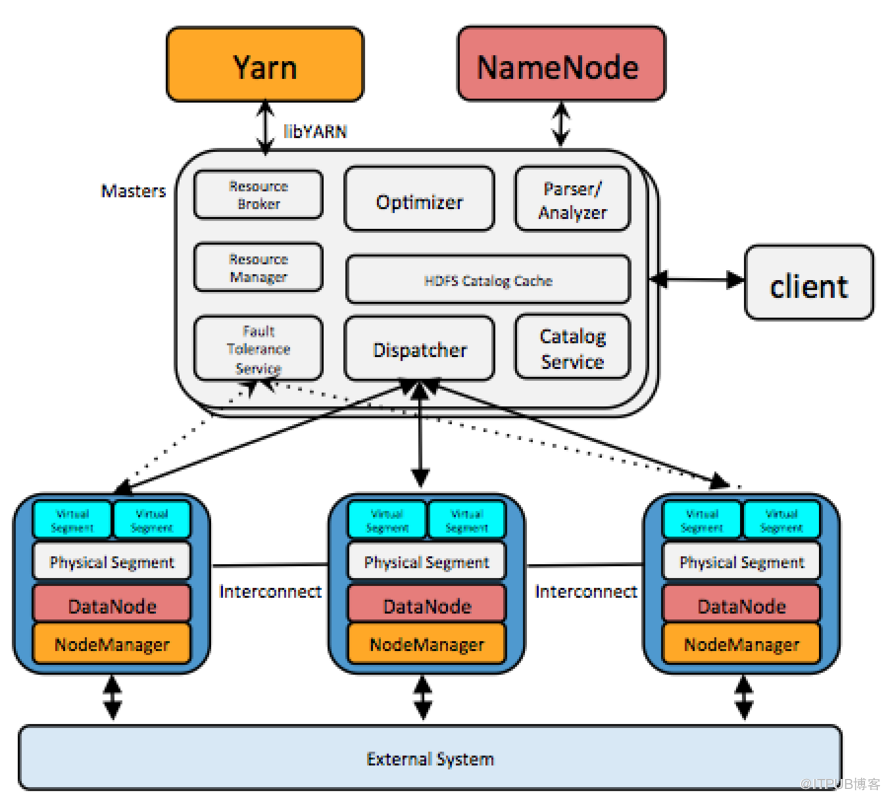
图2 HAWQ++内部架构
HAWQ++并行优化器
接下来具体解释一下HAWQ++并行优化器这个模块,因为在一款数据库系统里优化器在很大程度上决定了SQL执行性能的好坏。HAWQ++原生优化器是在PostgresSQL优化器的基础上开发的,简单来说就是在pg生成的串行plan上插入了Motion的操作。Motion代表数据的移动,底层是通过高速互联网络实现的。基于插入的Motion,plan被切割成若干个Slice。同一个Slice在不同节点上可以并行执行。Motion一共有三类:1.Redistribute Motion,负责按照hash键值重新分布数据;2.Broadcast Motion,负责广播数据;3.Gather Motion,负责搜集数据到一起。图3中左边的查询计划表示了一个不需要重新分布数据的例子,因为表lineitem和orders都使用了连接键进行分布。而如果这两张表都是随机分布,那么就会生成右边的查询计划,和左边查询计划相比多了一个Redistribute Motion的节点。可能有些人会有疑问,HAWQ++的数据存储在HDFS上,如果遇到HDFS加减节点某个Datanode上的block可能会被rebalance到其他Datanode上,那么对于hash分布的表不做Redistribute Motion怎么能够直接做HashJoin?原因在于对于hash分布的表HAWQ++有维护QE和写入文件的映射关系,所以即便该文件某个block不在本地了,那么影响的也只是对于该block的本地读还是远程读,和是否需要做Redistribute Motion是没有关系的。另外基于cost的物理优化的输入数据来源于统计信息,因此预先通过analyze命令收集表的统计信息可以帮助优化器产生更为优化的Plan。
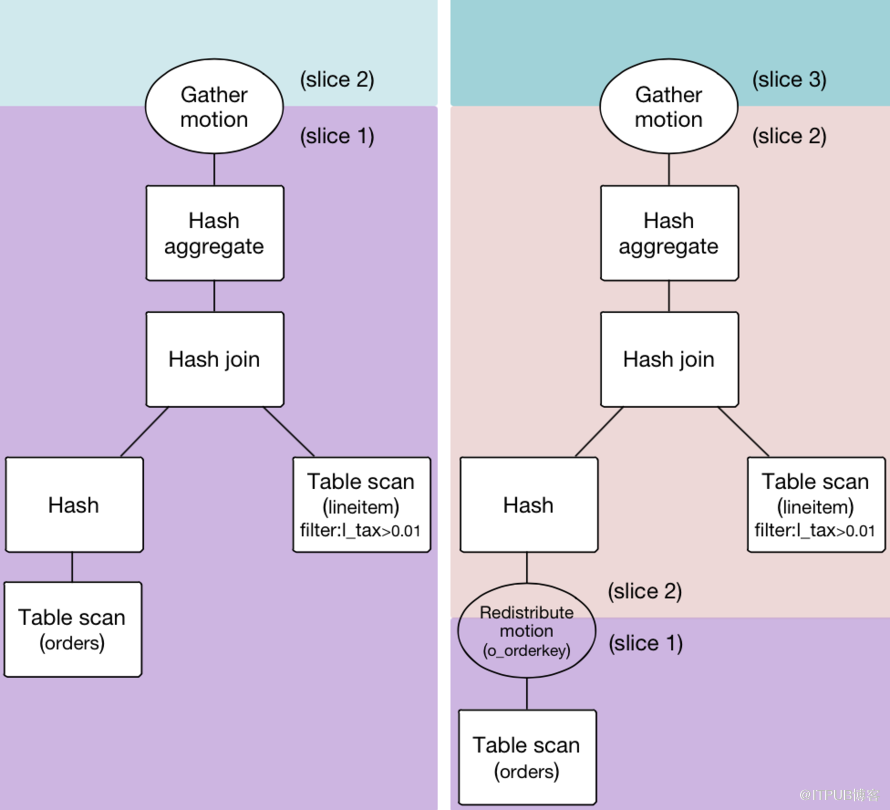
图3 并行查询计划
HAWQ++查询处理流程
图4展示了图3中右边查询计划的处理流程。HAWQ++的Master节点收到客户端的连接请求会启动QD(Query Dispatcher,查询派遣器),进入词法分析,语法分析,语义分析,优化器生成并行的Plan,再根据查询数据量大小以及当前资源使用情况,结合datalocality的信息,计算出需要启动多少个virtual segment以及在哪些segment节点上启动这些VSEG。接着dispatcher模块会通过libpq协议连接这些segment节点启动QE,同时把并行plan做序列化经过压缩dispatch过去。VSEG是一个逻辑的概念,如图4中包含任意一组分别执行slice1和slice2的QE进程。同一个slice在所有VSEG上的QE进程集合我们称为一个gang。每一个QE收到属于自己的slice构建一棵查询执行器树,树中每一个节点称做一个operator,对应各自的执行器节点实现逻辑。HAWQ++整个执行流程是Pipeline的模式,从上往下pull数据。Gang与gang之间的slice通过Motion传输数据,最终所有数据通过Gather Motion汇集到Master节点上返回给客户端。
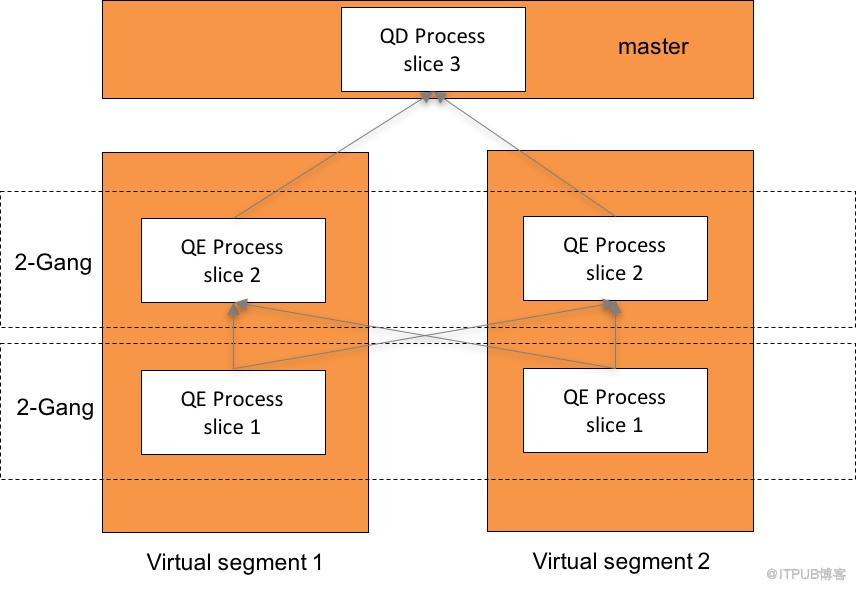
图4 查询处理流程
HAWQ++弹性执行引擎
HAWQ++弹性执行引擎是区别于传统MPP数据库的关键技术。针对传统MPP数据库,比如Greenplum Database,因为Segment配置死板,SQL计算执行往往必须调动所有集群节点,造成资源浪费,约束SQL并发能力。每个节点又有各自独占的目录和数据,对每个节点的可用性有比较严格的要求,扩展复杂。而HAWQ++引入的弹性执行引擎通过存储和计算的完全分离使得我们可以启动任意多个虚拟Segment来执行查询。每一个Segment都是无状态的,元数据和事务管理在Master节点实现,因此加入集群的Segment节点无需状态同步,用户可根据需要动态加减节点。针对每一条具体的查询,根据用户配置、SQL特征以及实时数据库运转状态动态决定SQL执行的计算并发度,动态分配使用健康低负载节点。同时根据表数据块分布动态分配IO任务到并行VSEG上,实现最优本地读取比例,保障最优SQL执行性能。
HAWQ++可插拔外部存储
HAWQ++可插拔外部存储基于增强版的外部表读写框架开发完成,通过新框架HAWQ++可以更加高效地访问更多类型外部存储,可以实现可插拔文件系统,比如S3,Ceph等,以及可插拔文件格式,比如ORC,Parquet等。同内部表一样,HAWQ++可以根据查询数据量大小和数据库资源利用率等动态调整集群中外部表读写并发数,根据数据分布选择最优计算节点,从而达到优化和灵活控制外部表访问性能的效果。相比于Apache HAWQ原有的外部数据访问方案PXF,可插拔外部存储避免了数据传输路径中的多次数据转换,打破了通过固有并行度提供外部代理的方式,给用户提供了更简单更有效的数据导入导出方案,而且性能高数倍。
HAWQ++容器云支持
HAWQ++是世界上第一个可以原生运行在容器云平台中的MPP SQL引擎。众所周知,将简单的无状态应用(比如Web服务器)迁移到容器比较简单,而将大数据平台迁移到容器却面临很多技术挑战。HAWQ++支持在主流Kubernetes CaaS平台的安装部署,HAWQ++ 的服务运行在CaaS平台管理的Docker容器中。在Kubernetes上部署HAWQ++和部署其他应用集群一样,都可以通过Dashboard用户界面或者命令行进行部署,也可以像管理其他CaaS平台应用程序一样来管理HAWQ++集群。将HAWQ++和云平台结合带来应用和服务一体化,很容易做弹性扩容,自恢复和滚动升级。在资源管理和自动化运维也带来很多便捷。
HAWQ++展望
目前HAWQ++还在持续不断的开发过程当中,在不久的将来会添加update/delete 功能,成为云时代大数据管理引擎当之无愧的领跑者。

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。