жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жҚ®жӮүпјҢйЎә丰科жҠҖж•°жҚ®дёӯеҝғзҡ„дёҖдҪҚйӮ“жҹҗеӣ иҜҜеҲ з”ҹдә§ж•°жҚ®еә“пјҢеҜјиҮҙжҹҗйЎ№жңҚеҠЎж— жі•дҪҝ用并жҢҒз»ӯ590еҲҶй’ҹгҖӮдәӢеҸ‘еҗҺпјҢйЎәдё°е°ҶйӮ“жҹҗиҫһйҖҖпјҢдё”еңЁйЎә丰科жҠҖе…ЁзҪ‘йҖҡжҠҘжү№иҜ„гҖӮзңҹе®һең°зҺ©дәҶдёҖжҠҠвҖңд»ҺеҲ еә“еҲ°и·‘и·ҜвҖқгҖӮ
жҜ«ж— з–‘й—®ең°пјҢжҲ‘们еҸҲзӘҒ然иұЎиў«жү“дәҶйёЎиЎҖиҲ¬пјҢж•ҙдәҶж•ҙиЎЈйўҶпјҢжҢәдәҶжҢәиғёпјҢеӯҳеңЁж„ҹз«Ӣ马зҲҶжЈҡпјҢжӢүдёӘе°ҸжқҝеҮіпјҢе°ұзқҖдёӯз§ӢиҠӮзҡ„жңҲе…үпјҢзө®зө®еҸЁеҸЁең°и®Іи®ІжғіеҪ“е№ҙгҖӮ
жғіеҪ“е№ҙпјҢжҲ‘еӣҪйӮЈе•Ҙжңәжһ„пјҢи®ҫеӨҮеҚҮзә§ж”№йҖ пјҢз”ҹдә§еә“еңЁзәҝзғӯиҝҒпјҢи„ҡжң¬еҶҷй”ҷпјҢrmжҺүдәҶпјҢ然еҗҺпјҢжҲ‘们XXXпјҢе…ЁйғЁжҒўеӨҚжүҖжңүж•°жҚ®пјҲжӯӨеӨ„зңҒз•ҘеҮ дёҮеӯ—пјҢеҢ…еҗ«ж•°еҚҒдёӘиҮӘжҲ‘ж ҮжҰңзҡ„вҖңзүӣXвҖқеҠ©иҜҚпјүгҖӮеҸҜжғңпјҢеҫ—жӣҝз”ЁжҲ·дҝқеҜҶгҖӮ
жғіеҪ“е№ҙпјҢйӮЈе•Ҙжңәжһ„пјҢеӣ дёәйӮЈе•ҘпјҢ然еҗҺпјҢвҖҰвҖҰпјҢз®—дәҶпјҢдёҚиғҪиҜҙпјҢеҸҚжӯЈиҖҒдј еҘҮдәҶгҖӮ
е•Ҙд№ҹдёҚиғҪиҜҙпјҢе°ұд»ҺжҠҖжңҜи§’еәҰиҒҠдёҖиҒҠпјҢи®әеҲ еә“еҲ°жҒўеӨҚпјҢеҶҚеҲ°и·‘дёҚдәҶи·Ҝзҡ„дҪңжӯ»дәәз”ҹгҖӮ
жҲ‘иӮҜе®ҡдёҚдјҡиҒҠжүҫдёӘ收иҙ№жҲ–ејҖжәҗж•°жҚ®жҒўеӨҚиҪҜ件жҒўеӨҚпјҢдёўдёҚиө·йӮЈдәәгҖӮ
дёҚиҒҠWindowsпјҢеӣ дёәеҹәжң¬е’Ңе®ғж— е…ігҖӮ
д»…йҷҗUnixгҖҒLinuxдёҠеҲ йҷӨoracleгҖҒdb2гҖҒmysqlгҖҒHadoopзӯүзҡ„жғ…еҶөпјҢе°ұд»Ҙrm -fдёәдҫӢеҗ§гҖӮ
ж•°жҚ®еә“зҡ„иҪҪдҪ“жңүеӨҡз§Қе®һзҺ°ж–№ејҸпјҢж–Ү件жҲ–иЈёи®ҫеӨҮгҖӮеӨҡж•°жғ…еҶөдёӢпјҢзі»з»ҹдјҡд»Ҙж–Ү件зҡ„ж–№ејҸ(дёҖеҲҮзҡҶдёәж–Ү件)еҜ№ж•°жҚ®еә“ж•°жҚ®ж–Ү件иҝӣиЎҢз®ЎзҗҶгҖӮдёҖеҘ—ж•°жҚ®еә“пјҢз®ҖеҚ•ең°зңӢпјҢзү©зҗҶдёҠеҸҜд»ҘзҗҶи§ЈдёәдёҖдёӘжҲ–еӨҡдёӘж–Ү件гҖӮеҲ еә“пјҢд№ҹе°ұжҳҜеҲ дёҖдёӘжҲ–еӨҡдёӘж–Ү件дәҶгҖӮ
ж–Ү件жҳҜеӯҳеӮЁеңЁж–Ү件系з»ҹеҶ…зҡ„гҖӮUnixе’ҢLinuxдёҠжңүеҫҲеӨҡз§Қж–Ү件系з»ҹпјҢиҝҷдәӣж–Ү件系з»ҹдҝқз•ҷзӣёеҗҢзҡ„VFSж–Ү件и®ҝй—®жҺҘеҸЈпјҢзЎ®дҝқз”ЁжҲ·йҖҸжҳҺең°дҪҝз”ЁжҜҸз§Қж–Ү件系з»ҹ(еҪ“然пјҢд№ҹдјҡжңүдёҖдәӣе°Ҹе·®ејӮпјҢдҪҶдёҖиҲ¬йғҪдјҡйҒөеҫӘPOSIXд№Ӣзұ»зҡ„ж ҮеҮҶ)гҖӮдҪҶе®һйҷ…дёҠпјҢдёҚеҗҢзҡ„ж–Ү件系з»ҹеңЁеҶ…ж ёи®ҫи®ЎдёҠеҚғе·®дёҮеҲ«пјҢиҝҷд№ҹеҜјиҮҙдәҶrm -fзҡ„дёҚеҗҢеә•еұӮиЎЁзҺ°пјҢеҶҚеҜјиҮҙжҜҸдёӘж–Ү件系з»ҹеңЁrm -fеҗҺжҒўеӨҚзҡ„еҸҜиғҪжҖ§гҖҒйҡҫеәҰзҡ„дёҚеҗҢгҖӮз®ҖеҚ•ең°иҜҙпјҢеҲ йҷӨж–Ү件еҗҺзҡ„жҒўеӨҚпјҢ并дёҚжҳҜж–Ү件系з»ҹ规иҢғдёӯзәҰе®ҡзҡ„жҠҖжңҜз»ҶиҠӮпјҢж–Ү件系з»ҹи®ҫи®Ўдәәе‘ҳеҺӢж №е°ұжІЎиҖғиҷ‘иҝҮгҖӮ
еңЁж–Ү件系з»ҹдёҠжҒўеӨҚдёҖдёӘеҲ йҷӨзҡ„еә“пјҢеӨ§жҰӮзҡ„жҖқи·Ҝеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡ
еӣҫ1пјҡжҒўеӨҚиў«еҲ йҷӨж•°жҚ®еә“зҡ„жҖқи·Ҝ
жҢҮд»Ҙж–Ү件дёәеҜ№иұЎиҝӣиЎҢжҒўеӨҚпјҢд№ҹе°ұжҳҜжҒўеӨҚж–Ү件系з»ҹдёҠеҲ йҷӨ(жҲ–дёўеӨұ)зҡ„жҹҗеҮ дёӘж–Ү件пјҢдёҚе…іеҝғж–Ү件зҡ„еҶ…е®№пјҢд»…йҖҡиҝҮж–Ү件系з»ҹзҡ„е…ғж•°жҚ®иҝӣиЎҢеҲҶжһҗе’ҢжҒўеӨҚгҖӮе…ғж•°жҚ®жҳҜдёҖдёӘж–Ү件系з»ҹзҡ„з®ЎзҗҶдҝЎжҒҜпјҢдёҖиҲ¬дёҚд»Ҙз”ЁжҲ·ж–Ү件дёәиҪҪдҪ“пјҢйҖҡеёёеҸӘиғҪйҖҡиҝҮеә•еұӮеқ—зҡ„дәҢиҝӣеҲ¶жөҒиҝӣиЎҢиҺ·еҸ–е’ҢеҲҶжһҗгҖӮ
ж–Ү件系з»ҹдёӯпјҢеҜ№ж–Ү件зҡ„еҜ»еқҖеӨ§иҮҙжҳҜиҝҷж ·дёҖдёӘжөҒзЁӢпјҢжҜҸдёӘж–Ү件系з»ҹеңЁжң¬ж–Үи®Ёи®әзҡ„иҢғеӣҙпјҢеҮ д№ҺйғҪдёҚдҫӢеӨ–гҖӮ

еӣҫ2 ж–Ү件еҜ»еқҖй“ҫ
вҖңиҠӮзӮ№вҖқиЎЁиҝ°дёҖдёӘж–Ү件(жҲ–зӣ®еҪ•)зҡ„ж‘ҳиҰҒдҝЎжҒҜпјҢд№ҹеҢ…жӢ¬жҢҮеҗ‘дёӢдёҖеұӮж•°жҚ®еҚ•е…ғзҡ„жҢҮй’ҲпјҢдёӢдёҖеұӮж•°жҚ®еҚ•е…ғжҢҮдёҖдёӘжҲ–еӨҡдёӘжҢҮеҗ‘пјҢеҸҜиғҪжҳҜдёҖдәӣйҷ„еҠ дҝЎжҒҜпјҢдҪҶиӮҜе®ҡдјҡжҢҮеҮәвҖңж•°жҚ®еқ—зҙўеј•вҖқгҖӮ
вҖңж•°жҚ®еқ—зҙўеј•вҖқжҳҜжҢҮжҢҮеҗ‘зңҹжӯЈж•°жҚ®еҢәзҡ„жҢҮй’ҲдҝЎжҒҜгҖӮ
вҖңж•°жҚ®еқ—вҖқе°ұжҳҜж•°жҚ®жң¬иә«гҖӮ
йҷӨйқһеңЁSSDзӯүд»ӢиҙЁдёҠеҗҜз”ЁTRIMйҖҡзҹҘзЎ¬зӣҳжё…йҷӨж•°жҚ®пјҢеҗҰеҲҷдёәдәҶж•ҲзҺҮпјҢеҲ йҷӨж•°жҚ®пјҢ并дёҚдјҡжё…йҷӨж•°жҚ®еҢәпјҢеҸӘдјҡжү“дёҠеҸҜйҮҚз”Ёзҡ„ж ҮзӯҫпјҢиҝҷжҳҜж–Ү件жҒўеӨҚзҡ„еҺҹзҗҶжүҖеңЁгҖӮ
йҮҚзӮ№1пјҡеҲ йҷӨж–Ү件жҒўеӨҚзҡ„第дёҖдёӘжңүеҸҜиғҪзү№еҲ«еҘҪз”Ёзҡ„ж–№жі•жҳҜlsofгҖӮ
Linuxзі»з»ҹдёӯдҪҝз”Ёrm -rfеҲ йҷӨж–Ү件еҗҺпјҢе…¶е®һж–Ү件иҠӮзӮ№еҸӘжҳҜд»Һзӣ®еҪ•ж ‘дёӯ移йҷӨпјҢж–Ү件еҶ…е®№иҝҳжҳҜеңЁзі»з»ҹеҗҺеҸ°зӯүеҫ…еӣһ收пјҢжӯӨж—¶жңүжңәдјҡдҪҝз”Ёзі»з»ҹиҝӣзЁӢеҸ·е°Ҷж–Ү件жӢ·иҙқеҮәжқҘгҖӮ
# lsof |grep data.file1
# cp /proc/xxx/xxx/xx ?/dir/data.file1
иҝҷдёӘж–№жі•е’ҢжҲ‘зҡ„дё“дёҡе…ізі»дёҚеӨ§пјҢиҜҰжғ…жҹҘgoogleгҖӮ
еҰӮжһңlsofжүҫдёҚеҮәжқҘпјҢйӮЈе°ұеҸҜд»ҘиҖғиҷ‘д»Һж–Ү件系з»ҹи§’еәҰиҝӣиЎҢеҲ йҷӨжҒўеӨҚдәҶгҖӮ
жҢүжҒўеӨҚзҡ„ж–№жі•пјҢж–Ү件系з»ҹеӨ§иҮҙеҲҶдёәдёүзұ»пјҡ
UFSпјҲSolarisгҖҒBSDзӯүдҪҝз”ЁпјүпјҢExt2/3/4(LinuxжңҖйҖҡз”Ёзҡ„ж–Ү件系з»ҹ)пјҢJFS(AixжңҖж—©дҪҝз”Ё)пјҢOCFS1/2пјҢHTFSпјҲSCOпјүгҖӮ
иҝҷзұ»ж–Ү件系з»ҹпјҢдҪҝз”Ёеӣәе®ҡзҡ„иҠӮзӮ№й•ҝеәҰпјҢе’Ңеӣәе®ҡзҡ„иҠӮзӮ№еҢәеҹҹгҖӮж–Ү件系з»ҹдёҠзҡ„жүҖжңүж–Ү件пјҲжҲ–зӣ®еҪ•пјүйғҪдјҡеңЁиҠӮзӮ№иЎЁдёӯжңүе”ҜдёҖдёҖдёӘзј–еҪ•еҜ№еә”пјҢз”ЁжқҘеҒҡеҜ»еқҖж–Ү件зҡ„иө·зӮ№гҖӮиҝҷзұ»ж–Ү件系з»ҹеңЁеҲ йҷӨж–Ү件时пјҢдёҖиҲ¬дјҡе°ҶиҠӮзӮ№иҝӣиЎҢжё…0ж“ҚдҪң(еӣ дёәиҠӮзӮ№зј–еҸ·е’ҢдҪҚзҪ®жҳҜзү©зҗҶдёҠеӣәе®ҡзҡ„пјҢеҲ йҷӨж–Ү件еҗҺеҝ…йЎ»еҸҜд»ҘйҮҚз”ЁпјҢиҠӮзӮ№еҢәж“ҚдҪңд№ҹиҫғдёәйӣҶдёӯе’Ңйў‘з№ҒпјҢдёҖиҲ¬и®ҫи®Ўж—¶дјҡеңЁеҲ йҷӨж—¶йЎәжүӢжё…0)пјҢжё…0еҗҺпјҢиҠӮзӮ№еҲ°ж•°жҚ®еқ—зҙўеј•д№Ӣй—ҙзҡ„зәҪеёҰе°ұж–ӯејҖдәҶпјҢеҺҹжң¬дёҖеҜ№дёҖзҡ„жҳ е°„е…ізі»пјҢеҸҳжҲҗдәҶNеҜ№NпјҢNжҳҜж–Ү件жҖ»ж•°гҖӮ
жүҖд»ҘпјҢиҝҷзұ»ж–Ү件系з»ҹеңЁеҲ йҷӨж–Ү件еҗҺжҒўеӨҚж—¶пјҢеҫҖеҫҖеҗҚз§°е’Ңзӣ®еҪ•еҜ№еә”иҫғдёәеӣ°йҡҫпјҢеғҸеҢ»йҷўзҡ„PACSгҖҒOAгҖҒйӮ®д»¶зі»з»ҹгҖҒиҜӯйҹіеә“гҖҒең°иҙЁйҮҮж ·гҖҒеӨҡеӘ’дҪ“зҙ жқҗпјҢд№ҹеҢ…жӢ¬ж•°жҚ®еә“ж–Ү件зӯүзҡ„еҜ№еә”гҖӮ(жҸ’ж’ӯе№ҝе‘ҠпјҡжҲ‘们пјҢд№ҹе°ұжҳҜеҢ—дәҡж•°жҚ®жҒўеӨҚдёӯеҝғпјҢwww.frombyte.comпјҢи§Ҷй’ұеҰӮе‘ҪпјҢиҝҷз§ҚжІЎдәәеҒҡзҡ„жҙ»пјҢжҲ‘们жҺҘ)гҖӮ
зү№ж®Ҡең°пјҢдёҖдәӣlinuxдёҠзҡ„ејҖжәҗж•°жҚ®жҒўеӨҚиҪҜ件пјҢext3grepд№Ӣзұ»зҡ„пјҢдёәдҪ•иғҪжҒўеӨҚExt3/4дёҠеҲ йҷӨзҡ„ж–Ү件呢пјҹ
жҳҜеӣ дёәпјҢExt3/4ж–Ү件系з»ҹж”ҜжҢҒж—Ҙеҝ—еӣһж»ҡпјҢзі»з»ҹдјҡеңЁж јејҸеҢ–ж—¶еҲӣз«ӢдёҖдёӘж—Ҙеҝ—ж–Ү件(з”ЁжҲ·дёҚеҸҜи§Ғ)пјҢе…ёеһӢзҡ„еӨ§е°Ҹжңү32M~128Mд№Ӣй—ҙпјҢеңЁеҲ йҷӨж–Ү件时пјҢиҠӮзӮ№дјҡе…ҲиЎҢеӨҚеҲ¶еҲ°ж—Ҙеҝ—ж–Ү件дёӯпјҢеҶҚиҝӣиЎҢеҲ йҷӨпјҢд»ҘзЎ®дҝқж“ҚдҪңж„ҸеӨ–дёӯж–ӯж—¶пјҢеҸҜеӣһеҲ°дёҠдёҖдёӘе№ІеҮҖзҡ„зЁіе®ҡзҠ¶жҖҒгҖӮ
дҪҶзјәзӮ№д№ҹжҳҫиҖҢжҳ“и§ҒпјҢж—Ҙеҝ—жҳҜдёҚж–ӯеҫӘзҺҜеӣһж»ҡзҡ„пјҢеҰӮжһңж—¶й—ҙеӨӘд№…пјҢжҲ–ж–Ү件系з»ҹж“ҚдҪңйў‘з№ҒпјҢе°ұжІЎйӮЈд№Ҳе®№жҳ“дәҶгҖӮе…ёеһӢең°пјҢеҰӮжһңеҲ йҷӨеӨ§йҮҸж–Ү件пјҢйқ иҝҷдёӘж–№жі•пјҢеҸӘиғҪжҒўеӨҚдёҖйғЁеҲҶгҖӮ
еҪ“然пјҢеҸҜд»ҘеҶҚз»ҷдёҖи®ЎдәҶгҖӮйҮҚзӮ№2пјҡеҲ йҷӨеҗҺпјҢеҰӮжһңlsofжҗһдёҚе®ҡпјҢжңүеҸҜиғҪзҡ„иҜқпјҢ第дёҖж—¶й—ҙddж–Ү件系з»ҹиҝӣиЎҢеҪ’жЎЈдҝқжҠӨгҖӮеҲ«д»ҘдёәдёҚж–ӯең°lsпјҢfindдјҡжңүеҘҮиҝ№еҮәзҺ°пјҢдјҡйӣӘдёҠеҠ йңңзҡ„гҖӮ
XFSгҖҒReiserFSгҖҒJFS2(for AIX)гҖҒZFSгҖҒNetApp WALFгҖҒEMC IsilonгҖҒStorNextгҖҒNTFSгҖӮ
иҝҷзұ»ж–Ү件系з»ҹпјҢиҠӮзӮ№еҢәеҹҹдёәеҸҜеҸҳеҢәеҹҹпјҢеҲ йҷӨж•°жҚ®ж—¶еҫҲеӨҡж—¶еҖҷдёҚдјҡжё…йҷӨж•°жҚ®гҖӮ
еҺҹеӣ еӨ§жҰӮжҳҜпјҡ
1гҖҒеҢәеҹҹеҸҜеҸҳпјҢиҠӮзӮ№еӨ§е°Ҹе°ұеҸҜд»Ҙи®ҫеӨ§дёҖдәӣпјҢжё…йҷӨеӨӘжөӘиҙ№жҖ§иғҪпјӣ
2гҖҒеҢәеҹҹеҸҜеҸҳпјҢзј“еҶІеҢәе°ұдёҚдёҖе®ҡеҫҲеҘҪе‘ҪдёӯпјҢжё…йҷӨиҠӮзӮ№ж—¶еҸӘйңҖеңЁдҪҚеӣҫдёҠеҒҡжүӢи„ҡе°ұиЎҢдәҶпјӣ
3гҖҒеҢәеҹҹеҸҜеҸҳпјҢеҸҜиҖғиҷ‘еҢәеҹҹйҮҚе®ҡеҗ‘пјҢеҺҹеҢәеҹҹд№ҹе°ұжІЎеҝ…иҰҒзҗҶдјҡдәҶгҖӮ
иҠӮзӮ№дёҚеҒҡжё…йҷӨпјҢж„Ҹе‘ізқҖвҖңиҠӮзӮ№->ж•°жҚ®еқ—зҙўеј•->ж•°жҚ®еқ—вҖқзҡ„й“ҫжқЎдёҚдјҡиў«жү“ж–ӯпјҢиҮӘ然д№ҹе°ұе®№жҳ“жҒўеӨҚж•°жҚ®дәҶгҖӮ
е…¶е®һд№ҹжҳҜжңүйҡҫеәҰзҡ„пјҢеҲ йҷӨдёҖдёӘж–Ү件пјҢеҝ…然иҰҒиЎЁзҺ°еңЁж–Ү件系з»ҹеұӮйқўйҮҠж”ҫпјҢжүҖд»ҘпјҢеҸҜиғҪвҖңиҠӮзӮ№->ж•°жҚ®еқ—зҙўеј•->ж•°жҚ®еқ—вҖқж•ҙдёӘй“ҫжқЎдјҡжҲҗдёәжёёзҰ»жҖҒпјҢд№ҹеҸҜиғҪиұЎzfsдёҖж ·пјҢдјҡеҮәзҺ°йқһеёёеӨҡзҡ„еүҜжң¬пјҢеҲҶжӢЈд№ҹдјҡжңүйҡҫеәҰгҖӮдёҚеҗҢзҡ„ж–Ү件系з»ҹпјҢдјҡжңүеҫҲеӨҡдҝЎжҒҜд№Ӣй—ҙеӯҳеңЁе…іиҒ”пјҢжҜ”еҰӮJFS2дёӯзҙўеј•еқ—дјҡи®°еҪ•дёҠдёҖйЎ№гҖҒдёӢдёҖйЎ№пјӣZFSдјҡеңЁиҠӮзӮ№дёӯи®°еҪ•дёӢдёҖйЎ№ж•°жҚ®зҡ„HASHзӯүпјҢж №жҚ®иҝҷдәӣеҢ№й…ҚзӮ№пјҢе°ұеҸҜд»ҘеҢ№й…ҚгҖҒжӢ©дјҳжүҫеҲ°жңҖжҒ°еҪ“зҡ„ж•°жҚ®жҒўеӨҚиө·зӮ№гҖӮеӣ дёҚеҗҢзҡ„ж–Ү件系з»ҹпјҢжңүдёҚеҗҢзҡ„й’ҲеҜ№жҖ§зҡ„ж–№жі•гҖӮ
жҜ”еҰӮVxfsгҖҒHFS+з»“жһ„дёҠеғҸIIзұ»пјҢдҪҶеӣ дёәиҠӮзӮ№еҢәеҹҹеҫҖеҫҖйӣҶдёӯеңЁеүҚйғЁпјҢе‘ҪдёӯзҺҮиҫғй«ҳпјҢеңЁи®ҫи®ЎдёҠпјҢеҲ йҷӨж–Ү件е°ұдјҡеҒҡжё…0жҲ–йҮҚжһ„ж ‘ж“ҚдҪңпјҢж•°жҚ®жҒўеӨҚзҡ„йҡҫеәҰеҸҲеҰӮеҗҢIзұ»гҖӮ
жҜ”еҰӮASMпјҢдёҘж јжқҘиҜҙпјҢд№ҹдёҚеӨӘеғҸж–Ү件系з»ҹдәҶпјҢеҸҚжӯЈз»“и®әжҳҜж–Ү件系з»ҹжң¬иә«жІЎжңүеӨӘеҘҪзҡ„з®—жі•пјҢдҝқиҜҒеҲ йҷӨеҗҺеҸҜжҒўеӨҚ(дҪҶдҫқйқ ж–Ү件еҶ…йғЁз»“жһ„пјҢжҒўеӨҚзҡ„еҸҜйқ жҖ§йқһеёёй«ҳ)
жҜ”еҰӮVMFSпјҢеҹәжң¬жҳҜдёӘеӨ§еқ—еҲҶй…Қзҡ„ж–Ү件系з»ҹпјҢжҒўеӨҚж–№жі•е’Ңж–№жЎҲе’Ңжң¬ж–ҮеӨҡжңүдёҚеҗҢпјҢдёҖжүҜеҶ…е®№жңүзӮ№еӨҡпјҢжңүз©әдё“й—ЁжүҜгҖӮ
дёҠиҝ°пјҢжҳҜй’ҲеҜ№е®Ңж•ҙжҒўеӨҚж–Ү件зҡ„жҖқи·ҜиҝӣиЎҢжҸҸиҝ°зҡ„пјҢдҪҶд№ҹеҰӮдёҠж–ҮжүҖиҝ°пјҢжңүж—¶ж–Ү件жҳҜж— жі•жҒўеӨҚзҡ„пјҢд№ҹеҸҜиғҪж–Ү件йғЁеҲҶиў«з ҙеқҸгҖҒиҰҶзӣ–гҖӮ
еҰӮжһңж–Ү件еҶ…е®№йғҪиҝҳеңЁпјҢдҪҶж–Ү件系з»ҹе…ғж•°жҚ®йғЁеҲҶе·Із»Ҹж— жі•ж”Ҝж’‘еҜ№ж–Ү件дҝЎжҒҜзҡ„иҝҳеҺҹпјҢйӮЈе°ұеҸҜд»ҘиҖғиҷ‘д»Һж–Ү件еҶ…е®№зҡ„е…іиҒ”жҖ§дёҠеҒҡж–Үз« гҖӮ
жҜ”еҰӮOracleж•°жҚ®ж–Ү件пјҢеӨҡж•°жғ…еҶөдёӢпјҢжҢү8KдёәйЎөеӨ§е°ҸпјҢеҸҜе–ңзҡ„жҳҜпјҢжҜҸдёҖйЎөзҡ„еӨҙйғЁйғҪжңүйЎөж ЎйӘҢгҖҒйЎөзј–еҸ·е’ҢеҸҜиғҪзҡ„ж–Ү件编еҸ·гҖӮжҢүйЎөж ЎйӘҢд»ҺзЈҒзӣҳеә•еұӮжү«жҸҸеҮәжүҖжңүж•°жҚ®йЎөеҗҺпјҢз»ҹи®Ўж–Ү件编еҸ·е’ҢйЎөзј–еҸ·пјҢе№ёиҝҗзҡ„иҜқпјҢе°ұеҸҜиғҪжҠҠж–Ү件жӢјжҺҘиө·жқҘгҖӮ
Oracleзҡ„жҺ§еҲ¶ж–Ү件дјҡи®°еҪ•ж•°жҚ®ж–Ү件йҖ»иҫ‘гҖҒзү©зҗҶд№Ӣй—ҙзҡ„е…іиҒ”пјҢеҲҶжһҗеҗҺпјҢж–Ү件еҗҚз§°гҖҒи·Ҝеҫ„е°ұдёҚйҡҫиҝҳеҺҹдәҶгҖӮ
еҗҢж ·зҡ„ж–№жі•пјҢеҸҜеӨ§иҮҙйҖӮеә”дәҺSql ServerгҖҒMySQL InnoDBгҖӮжҖқз»ҙзЁҚеҒҡеҸҳйҖҡпјҢеҸҜйҖӮеә”SybaseгҖҒDB2зӯүгҖӮ
еҰӮжһңжҳҜMySQL MyISAMеј•ж“ҺпјҢд№ҹжңүеҠһжі•гҖӮи®°еҪ•жҳҜдёҖиЎҢдёҖиЎҢдҫқж¬ЎеҺӢе…Ҙж–Ү件дёӯзҡ„пјҢеҰӮжһңжҹҗдёӘиЎЁжңүдё»й”®пјҢжҲ–зү№ж®Ҡзҡ„еӯ—ж®өпјҢжҲ–зү№ж®Ҡзҡ„иЎЁз»“жһ„пјҢе°ұиғҪеҜ№жүҖжңүзЈҒзӣҳдёҠз¬ҰеҗҲжқЎд»¶зҡ„еқ—иҝӣиЎҢеҪ’зұ»гҖӮMyISAMиҝҳдјҡжңүиЎҢжәўеҮәгҖҒиЎҢиҝҒ移зҡ„жғ…еҶөпјҢеҚіеӯҳеңЁAжҢҮеҗ‘Bзҡ„ж•°жҚ®е…іиҒ”е…ізі»пјҢж №жҚ®иҝҷдёӘе…ізі»пјҢд№ҹеҸҜд»ҘиҝӣдёҖжӯҘеҢ№й…Қеқ—и®°еҪ•зҡ„жҺ’еҲ—йҖ»иҫ‘пјҢд»ҺиҖҢз»„еҗҲж•°жҚ®ж–Ү件гҖӮеҜ№дәҺMyISAMпјҢиҝҷе…¶е®һд№ҹжҳҜжҒўеӨҚиЎЁжҲ–жҒўеӨҚи®°еҪ•зҡ„ж–№жі•гҖӮ
иҝҷжҳҜж №жҚ®ж–Ү件еҶ…е®№пјҢжҒўеӨҚе®Ңж•ҙж–Ү件зҡ„жҖқи·ҜгҖӮеҰӮжһңж–Ү件еҶ…е®№дёҚе®Ңж•ҙпјҢжҲ–еүҜжң¬еӨӘеӨҡеҜјиҮҙжҺ’йҮҚйҡҫеәҰеӨӘеӨ§е‘ўпјҹ---жҒўеӨҚиЎЁжҲ–иЎЁи®°еҪ•гҖӮ
ж №жҚ®иЎЁдёҺиЎЁд№Ӣй—ҙзҡ„е·®ејӮпјҢдёҖиҲ¬жғ…еҶөдёӢпјҢеҸҜд»Ҙе®№жҳ“еҜ№жүҫеҮәзҡ„жүҖжңүеҸҜиғҪжҳҜж•°жҚ®еә“зҡ„зүҮж–ӯиҝӣиЎҢеҪ’зұ»пјҢеҪ’зұ»зҡ„жңҖзӣҙжҺҘж–№жЎҲжҳҜжҢүиЎЁиҝӣиЎҢгҖӮ
жҢүиЎЁеҪ’зәідёәзӣёеҗҢдёҖз»„еҚ•е…ғеҗҺпјҢе°ұеҸҜд»Ҙд»Һи®°еҪ•и§’еәҰиҝӣиЎҢеҲҶжӢЈе’ҢжҺ’й”ҷдәҶпјҢеҰӮжһңеҸҜд»ҘеҖҹеҠ©дәҺзҙўеј•гҖҒз©әй—ҙеҲҶй…ҚгҖҒе…¶д»–е…іиҒ”иЎЁзӯүдҝЎжҒҜпјҢеҸҜд»Ҙе®№жҳ“еҜ№жҒўеӨҚзҡ„иЎЁеҚ•е…ғиҝӣиЎҢж•°жҚ®жё…жҙ—пјҢе№ёиҝҗзҡ„иҜқпјҢж•°жҚ®еҸҜиғҪжҳҜе®Ңж•ҙзҡ„гҖӮ
еҰӮжһңиЎЁеҪ’зәідёәеҗҢдёҖеҚ•е…ғеҗҺпјҢдёҺзҙўеј•дёҚеҜ№еә”гҖҒжңүй”ҷиҜҜи®°еҪ•зӯүпјҢеҜјиҮҙж•°жҚ®еә“ж— жі•дҝ®еӨҚеҗҜеҠЁпјҢе°ұеҸҜд»ҘжҢүиЎЁз»“жһ„пјҢеҜ№иЎЁеҚ•е…ғпјҢд»Ҙи®°еҪ•зҡ„ж–№ејҸиҝӣиЎҢжҠҪеҸ–->жҸ’е…Ҙж–°еә“->ж•°жҚ®е®ҡеҗ‘жё…жҙ—гҖӮиҷҪ然结жһңеҸҜиғҪдёҚжҳҜе®ҢзҫҺзҡ„пјҢдҪҶеҫҲеӨҡжғ…еҶөдёӢпјҢжҖ»жҜ”жІЎжңүејәгҖӮ
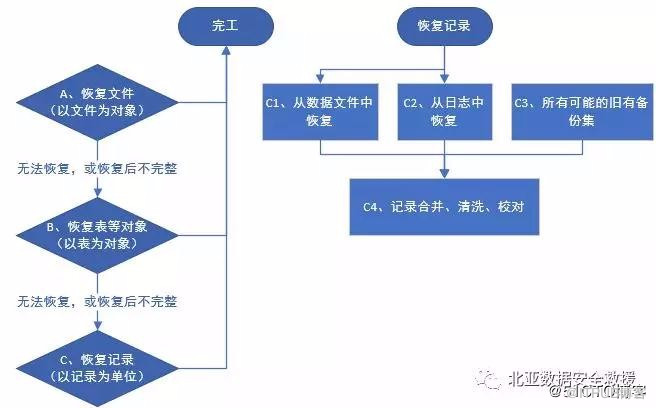
иҝҳжңүеӣҫ1дёӯж–№жі•C2пјҢд»Һж—Ҙеҝ—дёӯжҒўеӨҚи®°еҪ•гҖӮиҝҷдёӘж—Ҙеҝ—жҳҜе№ҝд№үзҡ„пјҢеҢ…жӢ¬еҪ’жЎЈгҖҒиҝҮзЁӢжҖ§иҜӯеҸҘиЎЁиҝ°зӯүдёҖеҲҮеҸҜиғҪжңүи®°еҪ•з—•иҝ№зҡ„ж•°жҚ®йӣҶгҖӮеңЁдё»ж•°жҚ®ж–Ү件жҳҜз ҙеқҸзҡ„жғ…еҶөдёӢпјҢиҝҷдәӣд»»дҪ•еҸҜиғҪеҢ…еҗ«и®°еҪ•зҡ„ж•°жҚ®йӣҶпјҢйғҪеә”иҜҘжҳҜеҲҶжһҗзҡ„еҜ№иұЎгҖӮд№ҹеҰӮеҗҢж•°жҚ®еә“ж–Ү件пјҢжҢүж–Ү件гҖҒз»“жһ„еқ—гҖҒи®°еҪ•зҡ„жҖқи·ҜиҝӣиЎҢжңҖеӨ§зЁӢеәҰзҡ„жҒўеӨҚгҖӮз»“еҗҲC1гҖҒC2гҖҒC3пјҢеҶҚеҒҡе®ҡеҗ‘жҖ§зҡ„ж•°жҚ®йӣҶеҗҲе’Ңж•°жҚ®жё…жҙ—пјҢж•°жҚ®жҒўеӨҚзҡ„жүӢж®өд№ҹе°ұеҲ°еӨҙдәҶгҖӮ
еҝҳдәҶиҒҠдёҖеҸҘHadoopдәҶпјҢHadoop,HbaseеңЁеҲ йҷӨж—¶и§ҰеҸ‘зҡ„жҳҜиҠӮзӮ№ж–Ү件系з»ҹдёҠзҡ„ж–Ү件еҲ йҷӨиЎҢдёәпјҢд»ҘжңҖеёёи§Ғзҡ„LinuxдёәдҫӢпјҢе…¶е®һе°ұжҳҜExt3/4дёҠеҲ йҷӨж–Ү件зҡ„жҒўеӨҚй—®йўҳпјҢеҰӮжһңж–Ү件жҒўеӨҚдёҚдәҶпјҢеҶҚеҸӮиҖғHadoopзҡ„HASHгҖҒfsimageд№Ӣзұ»зҡ„иҝӣиЎҢж•°жҚ®еқ—е…іиҒ”гҖӮеҰӮеҗҢдёҠиҝ°ж•°жҚ®еә“зҡ„жҖқи·ҜгҖӮ
жҳҫиҖҢжҳ“и§Ғзҡ„жҳҜпјҢжҒўеӨҚж–№жі•и¶Ҡеҗ‘еҗҺпјҢжұҮжҖ»зҡ„з”ҹдә§ж•°жҚ®й—®йўҳи¶ҠеӨҡпјҢж•°жҚ®йҖ»иҫ‘зҡ„жҺ’жҹҘе’Ңзә жӯЈе°Ҷдјҡи®©еӨӘеӨҡдәәеӨңдёҚиғҪеҜҗпјҢе’¬зүҷеҲҮйҪҝпјҢиҝҷж—¶еҖҷпјҢеҸҜиғҪи·‘и·ҜйғҪдјҡиў«еӨ§е®¶е өеӣһжқҘгҖӮеҫ—пјҢиҝҳжҳҜд№–д№–ең°з»ҷеӨ§е®¶д№°е’–е•ЎпјҢеҗ‘иҖҒжқҝиҙЎзҢ®е…Ёе№ҙе·Ҙиө„е’Ңиө„йҮ‘пјҢиЈ…зқҖ蓬еӨҙеһўйқўгҖҒж„ҒзңүдёҚеұ•зҡ„ж ·еӯҗеҗ§пјҢе…ҙи®ёеӨ§е®¶иҝҳиғҪзӯ”еә”жҜҸеӨ©и®©дҪ зқЎдёҠ2дёӘе°Ҹж—¶гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ