您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
云上关键业务测试及性能调优
1、 负载均衡选型及性能指标
负载均衡推荐使用性能保障性实例,它于性能共享型实例相比较,共享型负载均衡的资源是共享的,所以不能保障实例的性能指标。因为车联网的行业特点就是高并发场景推荐使用性能保障性实例。性能保障型实例的三个关键指标如下:
• 最大连接数-Max Connection
最大连接数定义了一个负载均衡实例能够承载的最大连接数量。当实例上的连接超过规格定义的最大连接数时,新建连接请求将被丢弃。
• 每秒新建连接数-Connection Per Second (CPS)
每秒新建连接数定义了新建连接的速率。当新建连接的速率超过规格定义的每秒新建连接数时,新建连接请求将被丢弃。
• 每秒查询数-Query Per Second (QPS)
每秒请求数是七层监听特有的概念,指的是每秒可以完成的HTTP/HTTPS的查询(请求)的数量。当请求速率超过规格所定义的每秒查询数时,新建连接请求将被丢弃。
阿里云负载均衡性能保障型实例开放了如下六种实例规格(各地域因资源情况不同,开放的规格可能略有差异,请以控制台购买页为准)。
规格 最大连接数 每秒新建连接数 (CPS) 每秒查询数(QPS)
规格 1 简约型I (slb.s1.small) 5,000 3,000
规格 2 标准型I (slb.s2.small) 50,000 5,000
规格 3 标准型II (slb.s2.medium) 100,000 10,000
规格 4 高阶型I (slb.s3.small) 200,000 20,000
规格 5 高阶型II (slb.s3.medium) 500,000 50,000
规格 6 超强型I (slb.s3.large) 1,000,000 100,000
规格 最大连接数 每秒新建连接数 (CPS) 每秒查询数(QPS)
cdn.com/908cb96098bd26e223e490bb2a18bb4dad175335.png">
注意:以上规格是在控制台里可以购买的,可以发现最大规格也就只有100w连接。但如果千万级的车联网企业,它的负载均衡最大连接能力要求达到1000w的时候怎么办?在控制台买不到怎么办?别着急,阿里云虽然只在官网控制台里开放了6种规格实例给普通中小企业用户。但是针对有更大规格要求的企业用户可以通过联系阿里云客户经理来定制更高规格的负载均衡实例,最高可提供亿级别最大连接数能力。
因为性能保障性实例在最大连接数,每秒连接数,每秒查询数等指标官方都有明确的SLA,所以我们这里就不去测试了,平时的使用过程中可以通过云监控实时观察各项性能指标。
并发连接数监控
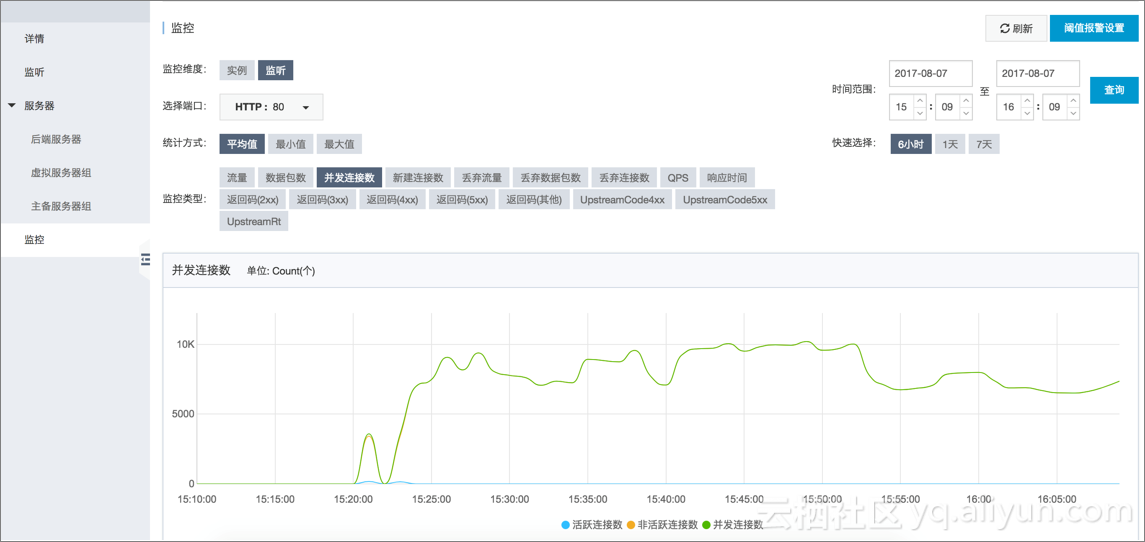
新建连接监控
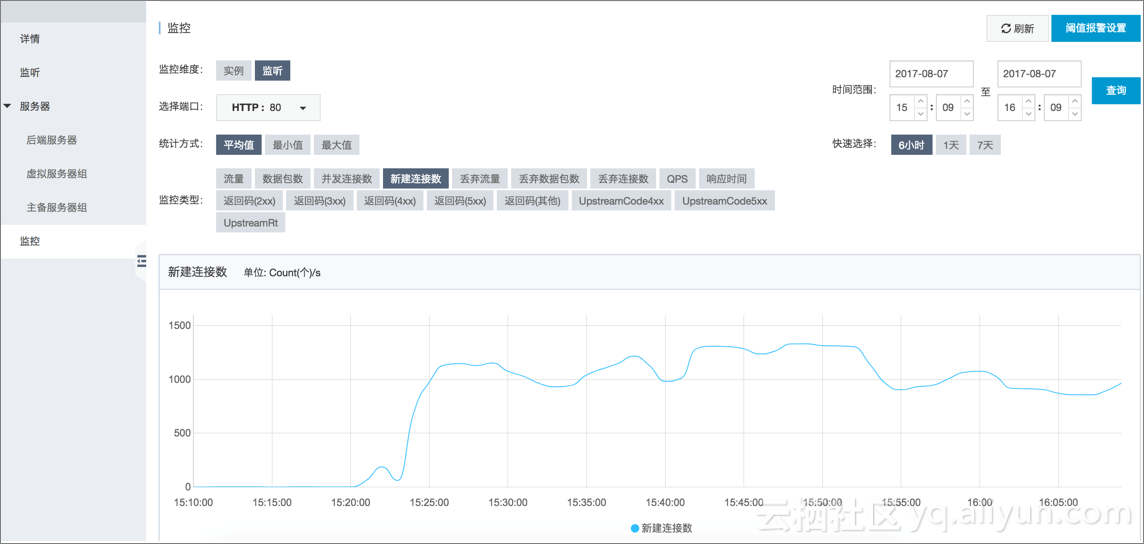
QPS监控
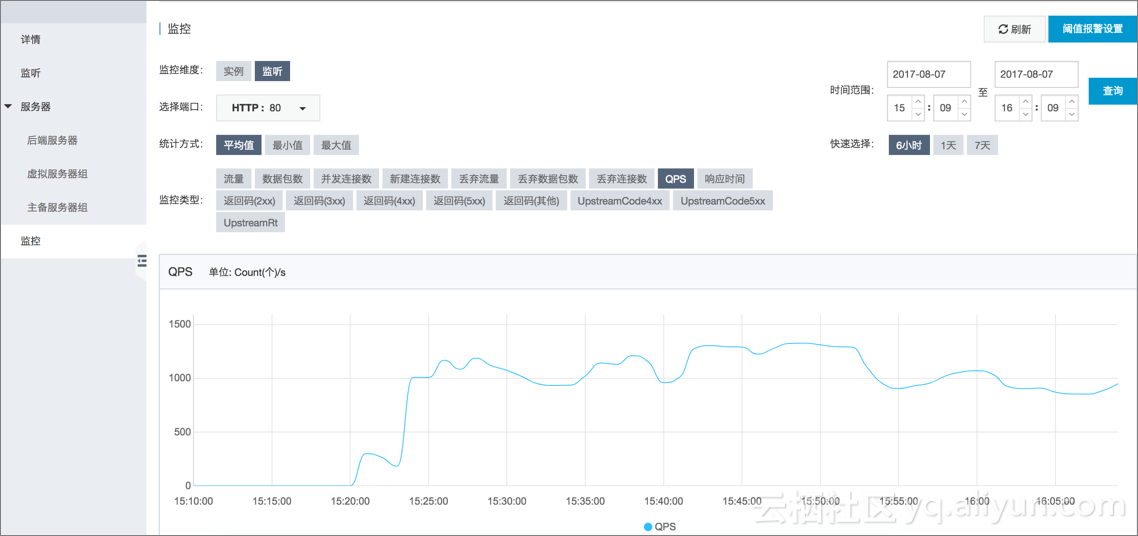
2、ECS选型及性能测试
云服务器Elastic Compute Service(ECS)是阿里云提供的一种基础云计算服务。使用云服务器ECS就像使用水、电、煤气等资源一样便捷、高效。无需提前采购硬件设备,而是根据业务需要,随时创建所需数量的云服务器ECS实例。在使用过程中,随着业务的扩展,可以随时扩容磁盘、增加带宽。如果不再需要云服务器,也能随时释放资源,节省费用。
ECS选型,可以根据不同应用场景来选择相应的ECS实例规格,如果不知怎么选择,可以参考官网的建议:
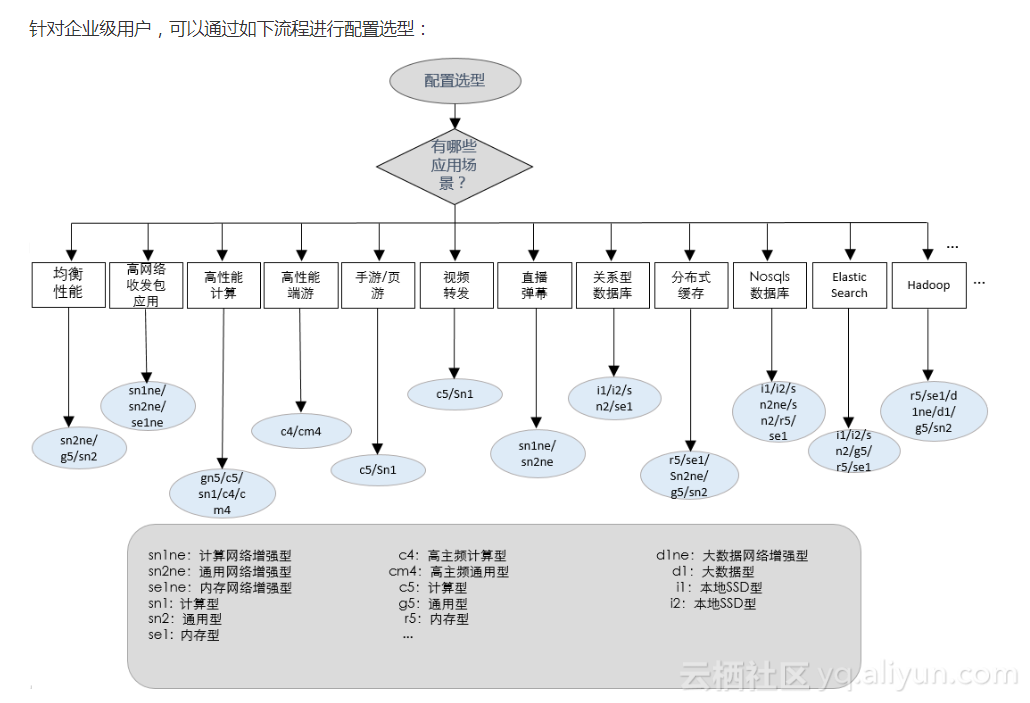
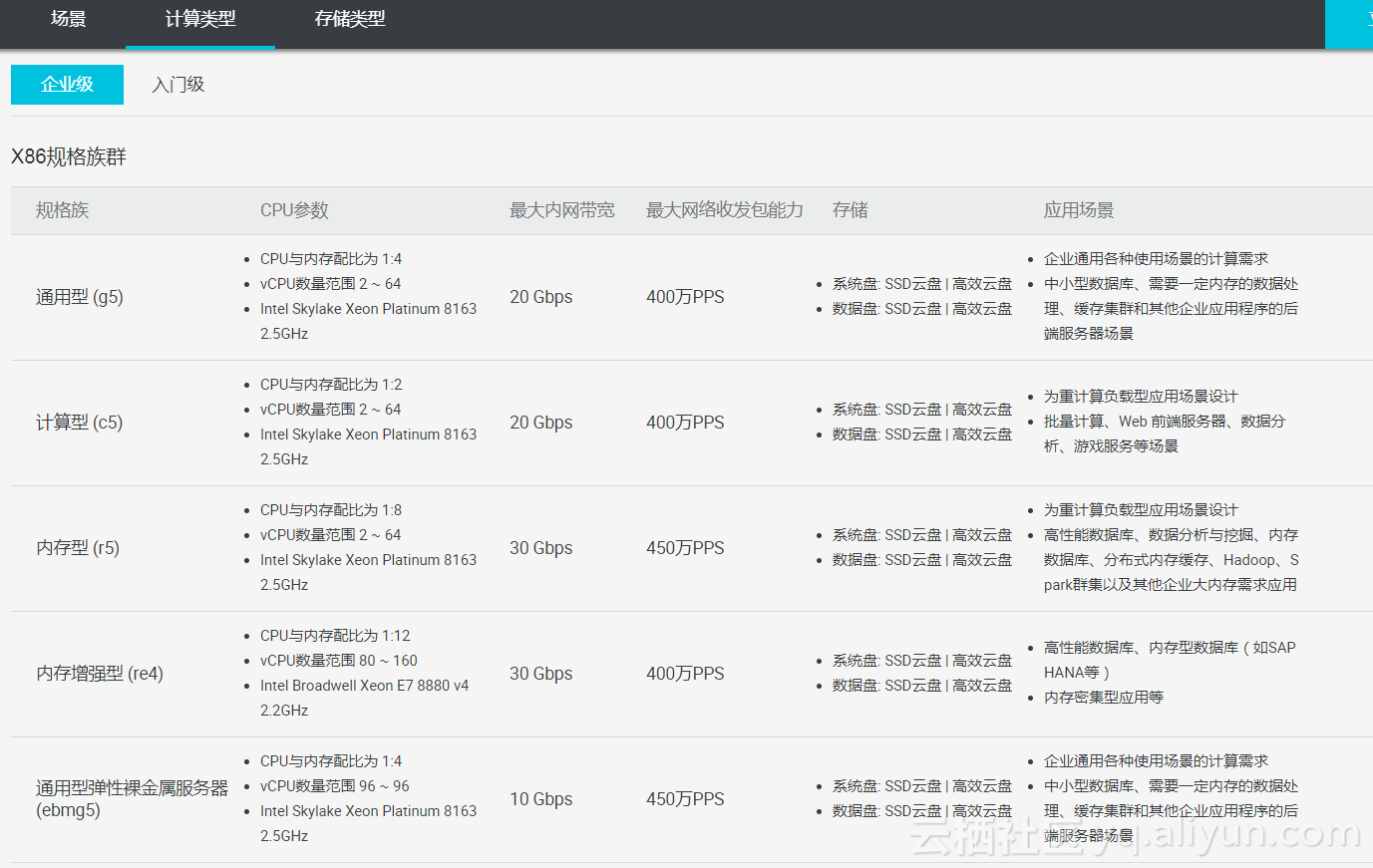
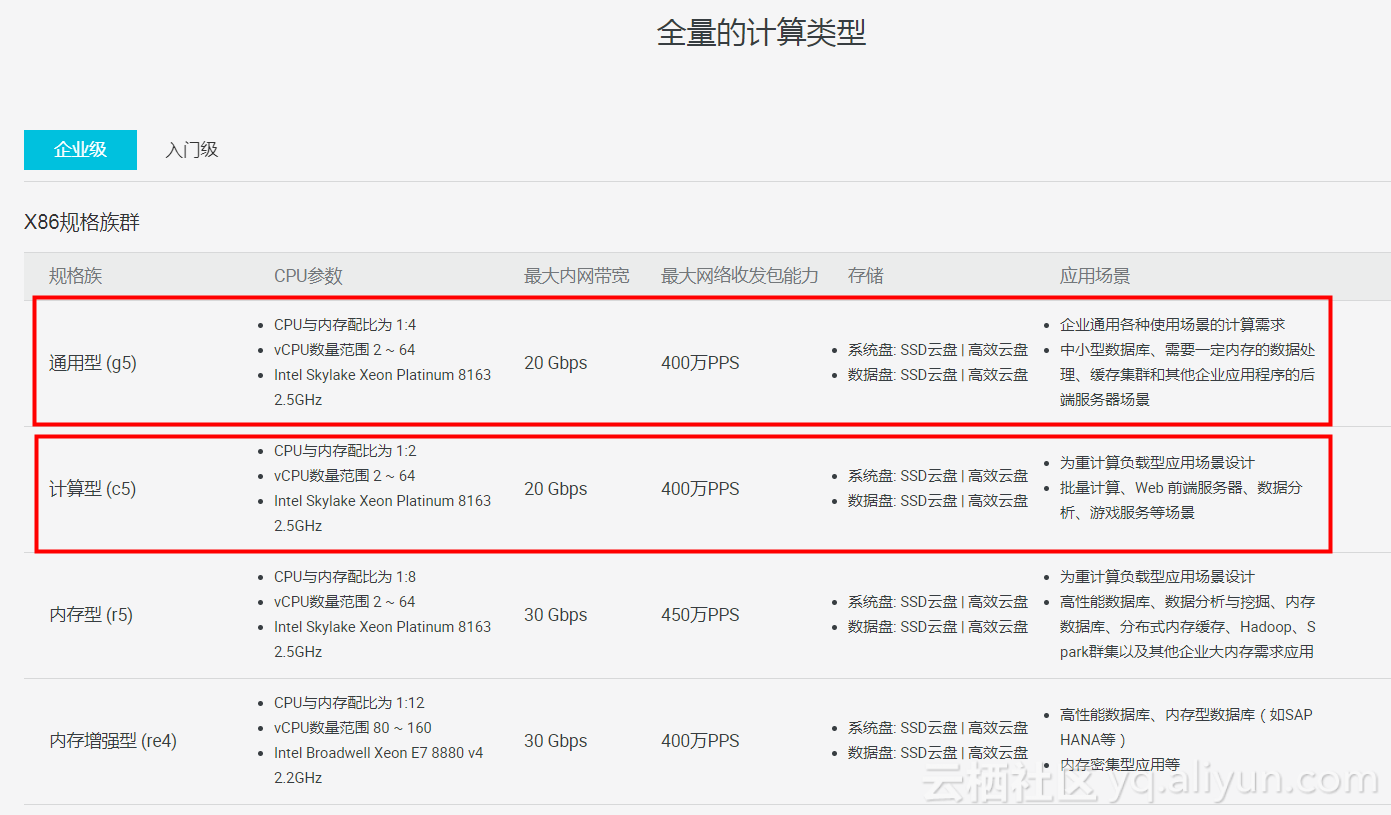
阿里云ECS针对不同的应用场景推出了不同实例规格,极大的丰富了用户多样化需求。
针对物联网行业特性,高并发,高吞吐等特点,建议web前端选择计算型(C5)机型,实例规格推荐4核8g,推荐系统盘SSD云盘;后端应用推荐使用通用型(g5)机型,实例规格推荐4核16g,推荐系统盘SSD云盘。
接下来我们测试一下其中一款实例的性能,例如通用型g5的4核16g SSD系统盘,操作系统为centos6.8
测试分为两部分,一是针对CPU 的跑分测试,另一个是针对SSD系统盘的IOPS测试。
1) 性能跑分测试
登录阿里云控制台,购买通用型g5,4核16gECS实例
登录服务器,验证下机器配置4核16G
安装测试工具Unixbench,安装过程如下
http://soft.laozuo.org/scripts/UnixBench6.1.3.tgz
tar xf UnixBench6.1.3.tgz
cd UnixBench
make
./Run 安装过程出错:
Can't locate Time/HiRes.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at ./Run line 6.
BEGIN failed--compilation aborted at ./Run line 6.
解决办法:yum install perl-Time-HiRes -y
如果出现bash: make: command not found问题
解决办法:yum -y install gcc automake autoconf libtool make
测试截图
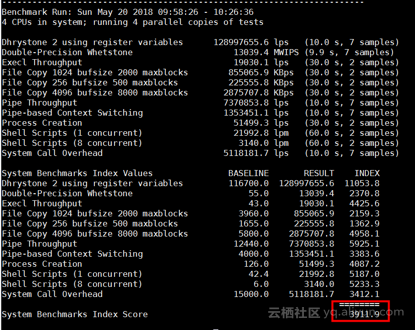
总结:最终跑分测试为3911.9,通常4核8G台式机这个分数为2100. 由此可见阿里云这款实例性能还是挺强的几乎是台式机的2倍。
2) SSD云盘性能测试
官网公布的SSD云盘SLA为:
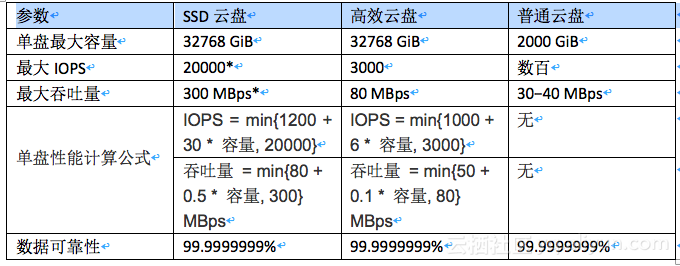
针对Linux操作系统可以使用DD、fio或sysbench等工具测试块存储性能。
下面用fio工具测试下通用型g5的4核16g系统盘为SSD云盘实例的IPOS能力:
警告:
测试裸盘可以获得真实的块存储盘性能,但直接测试裸盘会破坏文件系统结构,请在测试前提前做好数据备份。建议只在新购无数据的ECS实例上使用工具测试块存储性能,避免造成数据丢失。
登录服务器并安装测试命令fio
测试随机写IOPS,运行以下命令:
fio -direct=1 -iodepth=128 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=iotest -name=Rand_Write_Testing
测试随机读IOPS,运行以下命令:
fio -direct=1 -iodepth=128 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=iotest -name=Rand_Read_Testing
测试顺序写吞吐量,运行以下命令:
fio -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=1024k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=iotest -name=Write_PPS_Testing
测试顺序写吞吐量,运行以下命令:
fio -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=1024k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=iotest -name=Write_PPS_Testing
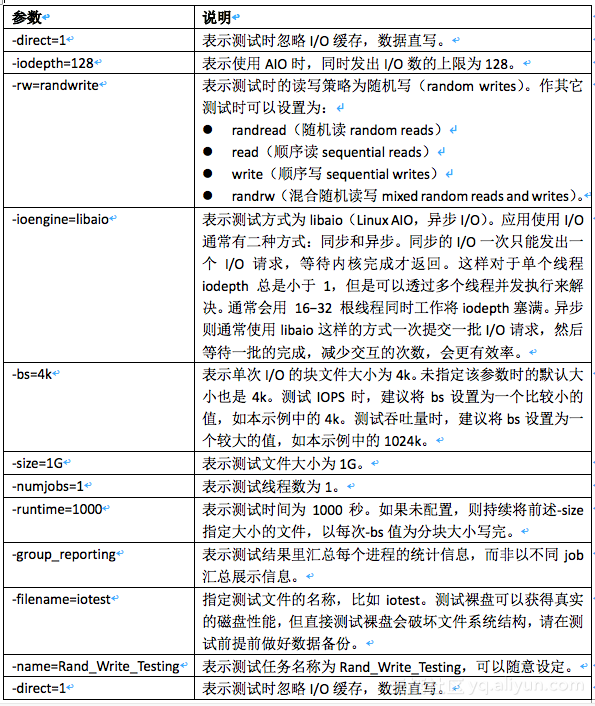
下表以测试随机写IOPS的命令为例,说明命令中各种参数的含义。
以下以一块SSD云盘随机读IOPS性能的测试结果为例,说明如何理解fio测试结果。
Rand_Read_Testing: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=128
fio-2.2.8
Starting 1 process
Jobs: 1 (f=1): [r(1)] [21.4% done] [80000KB/0KB/0KB /s] [20.0K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [28.6% done] [80000KB/0KB/0KB /s] [20.0K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [35.7% done] [80000KB/0KB/0KB /s] [20.0K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [42.9% done] [80004KB/0KB/0KB /s] [20.1K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [50.0% done] [80004KB/0KB/0KB /s] [20.1K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [57.1% done] [80000KB/0KB/0KB /s] [20.0K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [64.3% done] [80144KB/0KB/0KB /s] [20.4K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [71.4% done] [80388KB/0KB/0KB /s] [20.1K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [78.6% done] [80232KB/0KB/0KB /s] [20.6K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [85.7% done] [80260KB/0KB/0KB /s] [20.7K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [92.9% done] [80016KB/0KB/0KB /s] [20.4K/0/0 iops] [eta 00Jobs: 1 (f=1): [r(1)] [100.0% done] [80576KB/0KB/0KB /s] [20.2K/0/0 iops] [eta 00m:00s]
Rand_Read_Testing: (groupid=0, jobs=1): err= 0: pid=9845: Tue Sep 26 20:21:01 2017
read : io=1024.0MB, bw=80505KB/s, iops=20126, runt= 13025msec
slat (usec): min=1, max=674, avg= 4.09, stdev= 6.11
clat (usec): min=172, max=82992, avg=6353.90, stdev=19137.18
lat (usec): min=175, max=82994, avg=6358.28, stdev=19137.16
clat percentiles (usec):
| 1.00th=[ 454], 5.00th=[ 668], 10.00th=[ 812], 20.00th=[ 996],
| 30.00th=[ 1128], 40.00th=[ 1256], 50.00th=[ 1368], 60.00th=[ 1480],
| 70.00th=[ 1624], 80.00th=[ 1816], 90.00th=[ 2192], 95.00th=[79360],
| 99.00th=[81408], 99.50th=[81408], 99.90th=[82432], 99.95th=[82432],
| 99.99th=[82432]
bw (KB /s): min=79530, max=81840, per=99.45%, avg=80064.69, stdev=463.90
lat (usec) : 250=0.04%, 500=1.49%, 750=6.08%, 1000=12.81%
lat (msec) : 2=65.86%, 4=6.84%, 10=0.49%, 20=0.04%, 100=6.35%
cpu : usr=3.19%, sys=10.95%, ctx=23746, majf=0, minf=160
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1%
issued : total=r=262144/w=0/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs):
READ: io=1024.0MB, aggrb=80504KB/s, minb=80504KB/s, maxb=80504KB/s, mint=13025msec, maxt=13025msec
Disk stats (read/write):
vdb: ios=258422/0, merge=0/0, ticks=1625844/0, in_queue=1625990, util=99.30%
输出结果中,主要关注以下这行内容:
read : io=1024.0MB, bw=80505KB/s, iops=20126, runt= 13025msec
min{1200+30
容量, 20000} = min{1200+30
800, 20000} = 20000
测试结果与公式计算结果相近。
3、数据库RDS测试及调优
1) RDS MySQL 版测试
今天我们基于阿里云RDS MySQL5.6版本进行一个性能测试。
a) 测试环境
所有测试均在华东2(上海)地域的可用区B完成。
测试用的ECS为系列II实例。
实例配置为8核16GB。
网络类型为经典网络。
压测用的镜像为CentOS 7.0 64位。
b) 测试工具
SysBench是一个跨平台且支持多线程的模块化基准测试工具,用于评估系统在运行高负载的数据库时相关核心参数的性能表现。它目的是为了绕过复杂的数据库基准设置,甚至在没有安装数据库的前提下,快速了解数据库系统的性能。
安装方法
本文用的SysBench版本为0.5
执行如下命令安装SysBench
c) 测试
准备数据
压测性能
sysbench --num-threads=32 --max-time=3600 --max-requests=999999999 --test= oltp.lua --oltp-table-size=10000000 --oltp-tables-count=64 --db-driver=mysql --mysql-table-engine=innodb --mysql-host= XXXX --mysql-port=3306 --mysql-user= XXXX --mysql-password= XXXX run
清理环境
sysbench --num-threads=32 --max-time=3600 --max-requests=999999999 --test= oltp.lua --oltp-table-size=10000000 --oltp-tables-count=64 --db-driver=mysql --mysql-table-engine=innodb --mysql-host= XXXX --mysql-port=3306 --mysql-user= XXXX --mysql-password= XXXX cleanup
d) 测试模型
库表结构
CREATE TABLE
sbtest
(
id
int(10) unsigned NOT NULL AUTO_INCREMENT,
k
int(10) unsigned NOT NULL DEFAULT '0',
c
char(120) NOT NULL DEFAULT '',
pad
char(60) NOT NULL DEFAULT '',
PRIMARY KEY (
id
),
KEY
k_1
(
k
)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
数据格式
id: 1
k: 3718516
c:08566691963-88624912351-16662227201-46648573979-64646226163-77505759394-75470094713-41097360717-15161106334-50535565977
pad: 63188288836-92351140030-06390587585-66802097351-49282961843
SQL样式
查询:
SELECT c FROM sbtest64 WHERE id=4957216
SELECT c FROM sbtest43 WHERE id BETWEEN 4573346 AND 4573346+99
SELECT SUM(K) FROM sbtest57 WHERE id BETWEEN 5034894 AND 5034894+99
SELECT DISTINCT c FROM sbtest50 WHERE id BETWEEN 4959831 AND 4959831+99 ORDER BY c
写入:
INSERT INTO sbtest3 (id, k, c, pad) VALUES (4974042, 4963580, '33958272865-80411528812-36334179010-84793024318-25708692091-43736213170-37853797624-40480626242-32131452190-24509204411','07716658989-39745043214-17284860193-80004426880-14154945098')
更新:
UPDATE sbtest11 SET k=k+1 WHERE id=5013989
UPDATE sbtest14 SET c='10695174948-02130015518-68664370682-70336600207-55943744221-72419172189-36252607855-75106351226-86920614936-86254476316' WHERE id=5299388
e) 测试指标
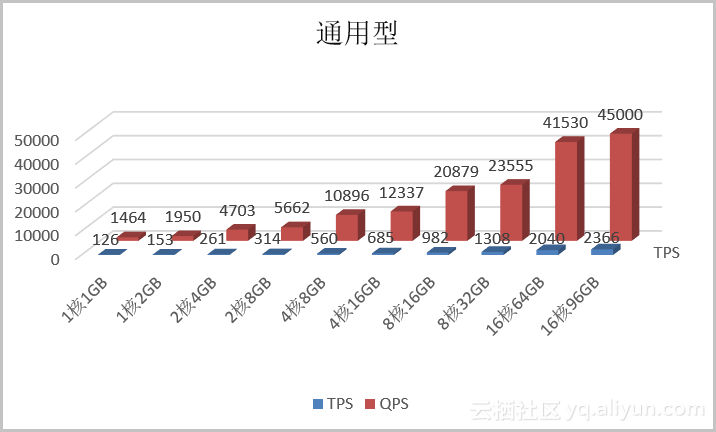
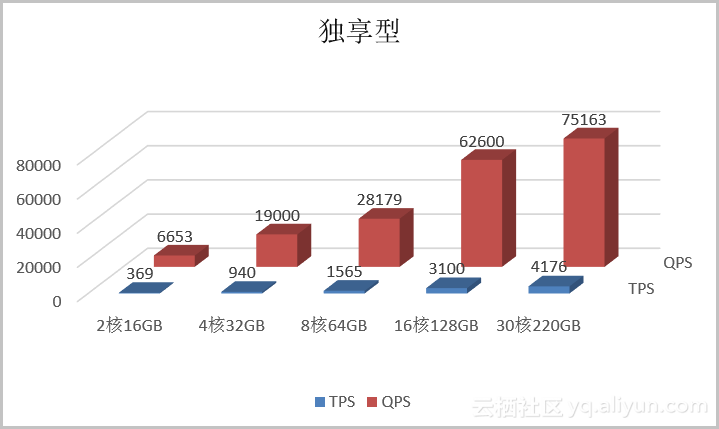
TPS
Transactions Per Second,即数据库每秒执行的事务数,以commit成功次数为准。
QPS
Queries Per Second,即数据库每秒执行的SQL数(含insert、select、update、delete等)。
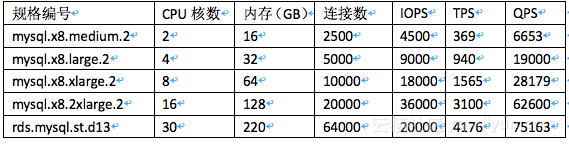
f) 测试结果
通用型
独享型
2) MySQL实例参数调优建议
对于云数据库MySQL版的实例,可以通过控制台上修改一些参数。对于某些重要参数而言,不恰当的参数值会导致实例性能问题或应用报错,所以本文将介绍一些重要参数的最优值建议以减少在设置参数时的疑虑。其中红色标注的是针对车联网场景的调优建议,车联网场景的特点是高并发,数据量大,读多写多。
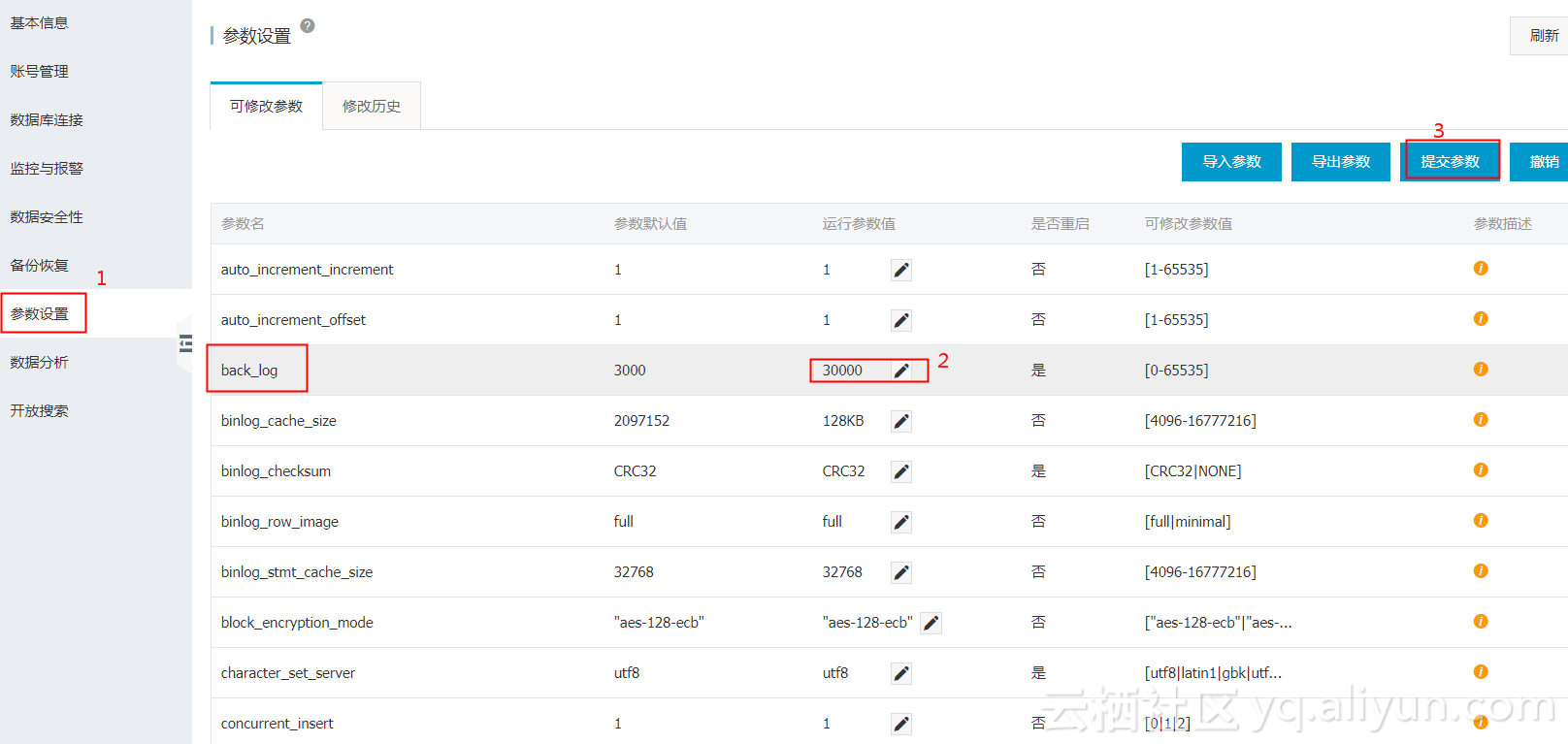
back_log(高并发场景需要提高此参数值)
默认值:3000
修改完后是否需要重启:是
作用:MySQL每处理一个连接请求时都会创建一个新线程与之对应。在主线程创建新线程期间,如果前端应用有大量的短连接请求到达数据库,MySQL会限制这些新的连接进入请求队列,由参数back_log控制。如果等待的连接数量超过back_log的值,则将不会接受新的连接请求,所以如果需要MySQL能够处理大量的短连接,需要提高此参数的大小。
现象:如果参数过小,应用可能出现如下错误。
SQLSTATE[HY000] [2002] Connection timed out;
修改建议:提高此参数值的大小。
innodb_autoinc_lock_mode(有助于避免死锁,提升性能)
默认值:1
修改完后是否需要重启:是
作用:在MySQL 5.1.22后,InnoDB为了解决自增主键锁表的问题,引入了参数innodb_autoinc_lock_mode,用于控制自增主键的锁机制。该参数可以设置的值为0、1、2,RDS默认的参数值为1,表示InnoDB使用轻量级别的mutex锁来获取自增锁,替代最原始的表级锁。但是在load data(包括INSERT … SELECT和REPLACE … SELECT)场景下若使用自增表锁,则可能导致应用在并发导入数据时出现死锁。
现象:在load data(包括INSERT … SELECT和REPLACE … SELECT)场景下若使用自增表锁,在并发导入数据时出现如下死锁。
RECORD LOCKS space id xx page no xx n bits xx index PRIMARY of table xx.xx trx id xxx lock_mode X insert intention waiting. TABLE LOCK table xxx.xxx trx id xxxx lock mode AUTO-INC waiting;
修改建议:建议将该参数值改为2,表示所有情况插入都使用轻量级别的mutex锁(只针对row模式),这样就可以避免auto_inc的死锁,同时在INSERT … SELECT的场景下性能会有很大提升。
说明:当该参数值为2时,binlog的格式需要被设置为row。
query_cache_size(车辆网的特点是读多写多的场景,此参数建议关闭)
默认值:3145728
修改完后是否需要重启:否
作用:该参数用于控制MySQL query cache的内存大小。如果MySQL开启query cache,在执行每一个query的时候会先锁住query cache,然后判断是否存在于query cache中,如果存在则直接返回结果,如果不存在,则再进行引擎查询等操作。同时,insert、update和delete这样的操作都会将query cahce失效掉,这种失效还包括结构或者索引的任何变化。但是cache失效的维护代价较高,会给MySQL带来较大的压力。所以,当数据库不会频繁更新时,query cache是很有用的,但如果写入操作非常频繁并集中在某几张表上,那么query cache lock的锁机制就会造成很频繁的锁冲突,对于这一张表的写和读会互相等待query cache lock解锁,从而导致select的查询效率下降。
现象:数据库中有大量的连接状态为checking query cache for query、Waiting for query cache lock、storing result in query cache。
修改建议:RDS默认是关闭query cache功能的,如果实例打开了query cache,当出现上述情况后可以关闭query cache。
net_write_timeout (可避免汽车数据因超时而导致数据写入失败)
默认值:60
修改完后是否需要重启:否
作用:等待将一个block发送给客户端的超时时间。
现象:若参数设置过小,可能会导致客户端出现错误the last packet successfully received from the server was milliseconds ago或the last packet sent successfully to the server was milliseconds ago。
修改建议:该参数在RDS中默认设置为60秒,一般在网络条件比较差时或者客户端处理每个block耗时较长时,由于net_write_timeout设置过小导致的连接中断很容易发生,建议增加该参数的大小。
tmp_table_size(大内存建议开启,提升查询性能)
默认值:2097152
修改完后是否需要重启:否
作用:该参数用于决定内部内存临时表的最大值,每个线程都要分配,实际起限制作用的是tmp_table_size和max_heap_table_size的最小值。如果内存临时表超出了限制,MySQL就会自动地把它转化为基于磁盘的MyISAM表。优化查询语句的时候,要避免使用临时表,如果实在避免不了的话,要保证这些临时表是存在内存中的。
现象:如果复杂的SQL语句中包含了group by、distinct等不能通过索引进行优化而使用了临时表,则会导致SQL执行时间加长。
修改建议:如果应用中有很多group by、distinct等语句,同时数据库有足够的内存,可以增大tmp_table_size(max_heap_table_size)的值,以此来提升查询性能。
loose_rds_max_tmp_disk_space
默认值:10737418240
修改完后是否需要重启:否
作用:用于控制MySQL能够使用的临时文件的大小。
现象:如果临时文件超出loose_rds_max_tmp_disk_space的取值,则会导致应用出现如下错误。
The table ‘/home/mysql/dataxxx/tmp/#sql_2db3_1’ is full
修改建议:首先,需要分析一下导致临时文件增加的SQL语句是否能够通过索引或者其它方式进行优化。其次,如果确定实例的空间足够,则可以提升此参数的值,以保证SQL能够正常执行。
loose_tokudb_buffer_pool_ratio
默认值:0
修改完后是否需要重启:是
作用:用于控制TokuDB引擎能够使用的buffer内存大小,比如innodb_buffer_pool_size设置为1000MB,tokudb_buffer_pool_ratio设置为50(代表50%),那么TokuDB引擎的表能够使用的buffer内存大小则为500MB。
修改建议:如果RDS中使用TokuDB引擎,建议调大该参数,以此来提升TokuDB引擎表的访问性能。
loose_max_statement_time
默认值:0
修改完后是否需要重启:否
作用:用于控制查询在MySQL的最长执行时间。如果超过该参数设置的时间,查询将会自动失败,默认是不限制。
现象:若查询时间超过了该参数的值,则会出现如下错误。
ERROR 3006 (HY000): Query execution was interrupted, max_statement_time exceeded
修改建议:如果想要控制数据库中SQL的执行时间,则可以开启该参数,单位是毫秒。
loose_rds_threads_running_high_watermark(高并发场景下有保护作用)
默认值:50000
修改完后是否需要重启:否
作用:用于控制MySQL并发的查询数目,比如将rds_threads_running_high_watermark的值设置为100,则允许MySQL同时进行的并发查询为100个,超过限制数量的查询将会被拒绝掉。该参数与rds_threads_running_ctl_mode配合使用(默认值为select)。
修改建议:该参数常常在秒杀或者大并发的场景下使用,对数据库具有较好的保护作用。
参数设置步骤
进入RDS控制台找到RDS实例—》点击管理---》点击参数设置---》设置完成参数---点击提交参数—》点击确定
4、Elasticsearch性能测试及调优
Elasticsearch是一个基于Lucene的搜索和数据分析工具,它提供了一个分布式服务。Elasticsearch是遵从Apache开源条款的一款开源产品,是当前主流的企业级搜索引擎。
阿里云Elasticsearch提供Elasticsearch 5.5.3版本及商业插件X-pack服务,致力于数据分析、数据搜索等场景服务。在开源Elasticsearch基础上提供企业级权限管控、安全监控告警、自动报表生成等功能. 今天我们对阿里云的Elasticsearch的读写性能分别做个测试。
写性能
测试环境
本次测试的Elasticsearch版本为5.5.3,3个节点,压测了三种规格的集群分别为2核4G 、4核16G、16核64G磁盘规格均为1T SSD云盘。
采⽤用 esrally 压测
rest api
压测数据集有以下两种
esrally官⽅方数据 geonames 3.3 GB,单⽂文档⼤大⼩小 311B
模拟某业务⽇日志数据 log 80GB 单⽂文档⼤大⼩小 1432B
测试结果
分⽚片数均为6
以下cpu 、load、ioutil 均为近似值
log 指标已针对批量量⽇日志写⼊入场景做了了异步translog/Merge策略略调整等优化
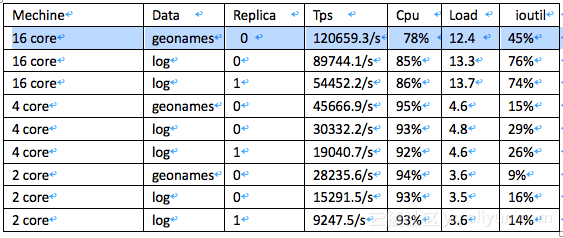
写性能指标对比
机器对写性能的影响
分⽚片数均为6
副本数均为0
磁盘容量量均为1T SSD云盘
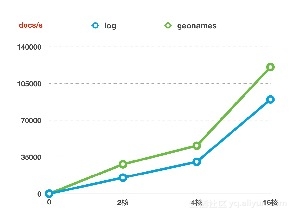
副本数对性能指标的影响
分⽚片数均为6
数据样本均为log
磁盘容量量均为1T SSD云盘
查询性能
测试环境
本次测试的Elasticsearch版本为5.5.3,3个节点,压测了三种规格的集群分别为2核4G 、4核16G磁盘规格均为1T SSD云盘
采⽤ esrally 压测
压测数据为esrally官方数据 geonames 3.3 GB,单⽂文档⼤大⼩小 311B
测试结果
分⽚片数均为6
副本数均为0
查询类型为term和phrase

Mechine Qps Cpu Load JVM Memory 90th percentile service time
2 core 12378 89% 3.98 47% 17.6141ms
4 core 23498 93% 4.63 48% 20.3789ms
5、云数据库 HBase性能测试及调优
云数据库ApsaraDB for HBase是一种稳定可靠、可弹性伸缩的分布式Nosql数据库,兼容开源HBase协议。现有以及即将提供的功能包括:安全,公网访问,HBase on oss, 备份恢复,冷热分离,可选择的存储介质包括,高效云盘,云ssd盘,本地磁盘,产品形态包括:单机版HBase以及分布式版本。
1) ApsaraDB for HBase测试
今天我们基于阿里云ApsaraDB for HBase进行一个性能测试。
a) 测试环境
所有测试均在华东2(上海)地域的可用区B完成。
实例配置为8核32G,独享。
网络类型为经典网络。
压测用的镜像为CentOS 6.8 64位。
单条数据value大小1KB,100线程进行数据压测
b) 测试工具
测试工具使用开源HBase 自带的PerformanceEvaluation工具进行测试,因为该工具提供了较为丰富的测试场景,包括随机key读写,构造顺序key读写,自定义的scan操作,且该工具完美兼容ApsaraDB for HBase的访问API,除此之外,对于测试需要的输出数据也是能够比较详细的展示出来。
安装方法
不需要安装,该二进制文件在HBase的安装包里面自带,不需要人工安装,直接执行命令进行操作即可;
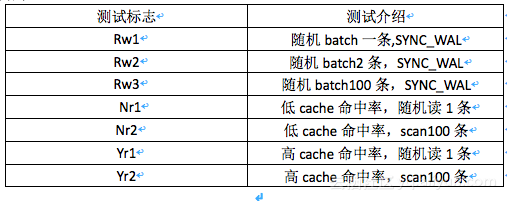
c) 测试方法
准备数据
在进行实际测试的时候,需要在HBase内部灌入一定量数据,以可以达到模拟线上的真实场景,写入数据的语句是:
sh hbase org.apache.hadoop.hbase.PerformanceEvaluation –nomapred –writeToWAL=
true –table=test –rows=5000 randomWrite 100
上述语句表示启动100线程,每一个线程往test表里写入5000条数据,每次写入操作需要记录WAL log。
压测性能
压测的操作包括读,写,scan操作;
写入操作:
sh hbase org.apache.hadoop.hbase.PerformanceEvaluation –nomapred –writeToWAL=
true –table=test –rows=5000 randomWrite 100
上述是写入操作的命令,其中可以通过调整配置文件writerbuffer进行修改每次批量写入的条数,我们测试写入1条,2条和100条的数据信息。
读取操作:
sh hbase org.apache.hadoop.hbase.PerformanceEvaluation –nomapred –table=test –rows=5000 randomRead 100
上述为读取操作的命令,对于读取而言,我们可以分别测试读取命中内存很高的情况下的数据,以及对于没有命中内存缓存情况下的数据。对于命中率高的情况,开启blockcahe,然后多次进行预读观测监控页面的命中率信息即可得到,对于无名中的话,只需要关闭cache即可;
scan数据操作:
sh hbase org.apache.hadoop.hbase.PerformanceEvaluation –nomapred –table=test –rows=5000 --caching=100 scanRange100 100
对于这种scan的话,我们观测的是命中率较高以及基本没有内存cache命中率的情况的数据。命中率高低的判断以及条件达到参考读取的情况。
d) 测试模型
库表结构
hbase(main):001:0> describe test'
Table test is ENABLED
test
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY =
'false', KEEP_DELETED_DATA => 'FALSE', DATA_BLOCK_ENCODING => 'NO
NE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0',
BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0
'}
数据格式
row: 00000000000000000000000428
column=info:0,
timestamp=1526367336121, value=NNNNNNNNLLLLLLLLCCCCCCCCJJJJJJJJGGGGGGGGZZZZZZZZPPP
PPPPPQQQQQQQQNNNNNNNNEEEEEEEEGGGGGGGGYYYYYYYYBBBBBBBBLLLLLLLLN NNNNNNNGGGGGGGGNNNNNNNNRRRRRRRREEEE EEEEQQQQQQQQXXXXXXXXTTTTTTTTJJJJJJJJYYYYYYYYXXXXXXXXMMMMMMMMJJJJJJJJMMMMMMMMFFFFFFFFHHHHHHHHDDDDD
DDDOOOOOOOOSSSSSSSSYYYYYYYYRRRRRRRRPPPPPPPPBBBBBBBBHHHHHHHHXXXXXXXXVVVVVVVVEEEEEEEEMMMMMMMMEEEEEE
EEMMMMMMMMDDDDDDDDLLLLLLLLKKKKKKKKSSSSSSSSWWWWWWWWVVVVVVVVXXXXXXXXVVVVVVVVJJJJJJJJAAAAAAAANNNNNNN
NDDDDDDDDLLLLLLLLAAAAAAAAOOOOOOOOKKKKKKKKFFFFFFFFHHHHHHHHIIIIIIIIZZZZZZZZQQQQQQQQAAAAAAAAKKKKKKKK
VVVVVVVVTTTTTTTTXXXXXXXXTTTTTTTTNNNNNNNNYYYYYYYYRRRRRRRRPPPPPPPPMMMMMMMMRRRRRRRRHHHHHHHHKKKKKKKKG
GGGGGGGBBBBBBBBMMMMMMMMBBBBBBBBTTTTTTTTFFFFFFFFSSSSSSSSQQQQQQQQCCCCCCCCSSSSSSSSVVVVVVVVBBBBBBBBFF
FFFFFFZZZZZZZZLLLLLLLLAAAAAAAAIIIIIIIIDDDDDDDDCCCCCCCCEEEEEEEESSSSSSSSOOOOOOOOFFFFFFFFKKKKKKKKHHH
HHHHHVVVVVVVVXXXXXXXXKKKKKKKKKKKKKKKKPPPPPPPPCCCCCCCCMMMMMMMMRRRRRRRREEEEEEEEGGGGGGGGGGGGGGGGPPPP
PPPPUUUUUUUUAAAAAAAAKKKKKKKKAAAAAAAAKKKKKKKKXXXXXXXXCCCCCCCCUU
e) 测试指标
RPS
Request Per Second,即数据库每秒执行的请求(含put,read,scan等)。
单条延时
平均单条请求的时延
f) 测试结果
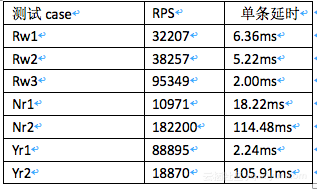
2) HBaseclient实例参数调优建议
对于hbase client做Htable封装,然后请求hbase的时候,Htable可以配置AutoFlush这个参数,默认是true,可以设置为false,表示当Htable的本地缓存打满以后才进行flush,开启false可以提高客户端感知的写入速度。
修改完后是否需要重启client:是
在HBase client做封装的时候,同样可以设置scan caching这个参数的个数,表示每次从服务端缓存多少条数据用户scan。默认的值是1,但是如果单条value很大的话,这个值建议不要设置很大。
Scan Attribute Selection,在做scan的时候,建议加上一些相应的表属性相关的过滤,如果添加只scan某一个列族的话,那么返回的时候只会操作该cf下面的数据,反之就会有很多不必要的列族返回,降低不必要的通信量。
WAL标志,对于非重要的数据,即,如果为了图性能,对数据如果是允许不一致以及数据安全性要求不高的话,那么在进行put操作的时候,可以将是否写WAL 的标志置为false,这样的话,就是数据在写入的时候不会先写WAL,那么对写操作会有很好的性能体现。
启用bloomfilter,对于读操作的话,如果开启bloomfilter的话,对读的性能有一定的提高,因为这是拿空间换读操作的时间。
6、HiTSDB性能测试及调优
HiTSDB Edge是一款运行在近客户端的高性能时序数据库。
6.1测试模型
测试采用的数据模型来源于随机生成的metric, tags组成的时间线metric和tagKey,tagValue分别由固定长度(10 bytes字符串) + 索引,不采用具有真实意义的metric和tagKey,tagValue是因为无法覆盖各种真实场景,且测试目的是为了将HiTSDB横向与其他时序数据库进行比较,因此在保证测试数据,软硬件条件一致的情况下,也可取得可信度较高的结果。时间戳(8bytes 长整型),value(8bytes双精度整数)。数据样例如下:

6.2统计结果说明
每次测试进行之前重启数据库服务,避免缓存对于之前执行获得的结果产生影响。
吞吐量(TPS)是单位时间内完成的数据点操作数量。
每次写入之后,会手动随机选择时间线进行数据查询,粗粒度校验数据写入一致性。同时对于HiTSDB写入,会注册SDK回调,失败或成功都能够感知。
同时为了避免测试数据产生影响,每次测试之前都会清理数据。
关于时间线数量,每次测试运行时,会通过HiTSDB内部接口/api/tscount校验时间线数量,每次增长均符合预期。HiTSDB与其他数据库单节点对比测试
6.3测试环境及步骤说明
所有数据库的对比测试是在同一台服务器上进行,基于阿里云ECS进行测试,该服务器的详细配置如下:
CPUs: 4
Memory(GiB): 8
Network Performance: High
Disk Capacity(GiB):60
在测试时,HiTSDB采用客户端版本号1.4.9。在本次测试中,InfluxDB默认设置。
本测试测试了各个数据库在不同时间线数量级场景下的写入和读取的表现。
6.4写入性能
数据库的一个写入请求可以包含一个或者多个数据点。总的而言,一次请求里包含的数据点越多,写入性能就会相应提升。在以下测试中,P/R表示Points/Request(一次请求中的数据点数)。
6.4.1 HiTSDB测试结果
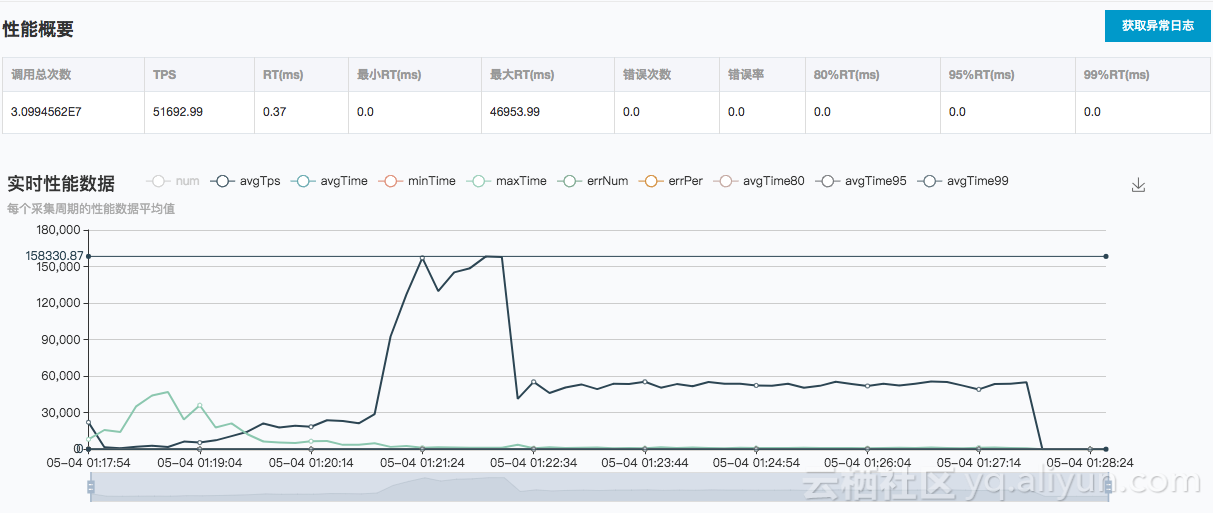
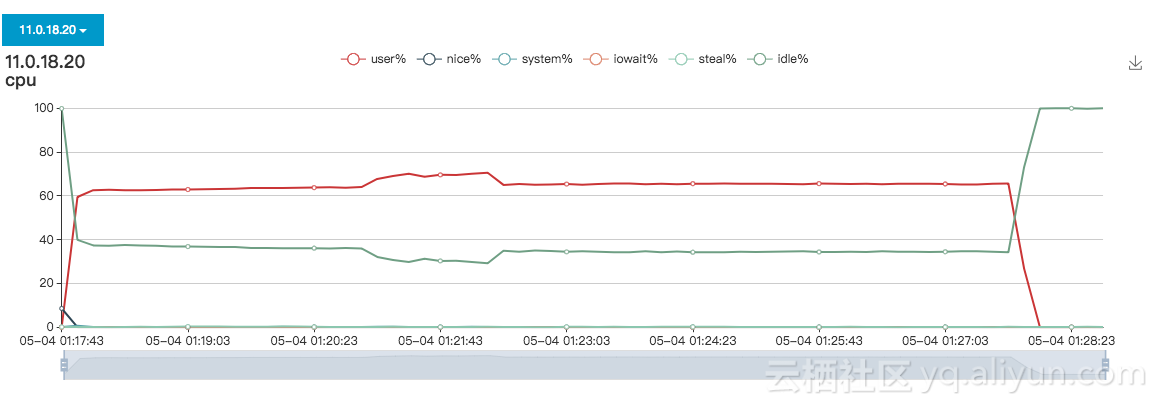
从下面表格结果来分析,HiTSDB在时间线增长时,写入TPS会有一定下降,最终在6xlarge规格指定的100万时间线时,写入TPS约为5万左右,这与阿里云官网宣传的性能60000点每秒,基本上差距不大。
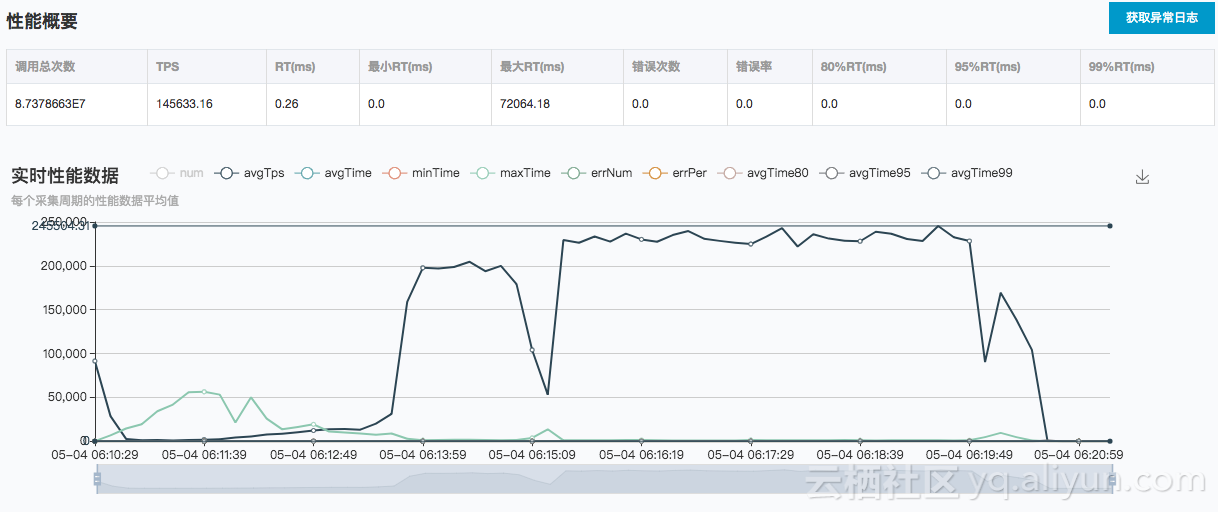
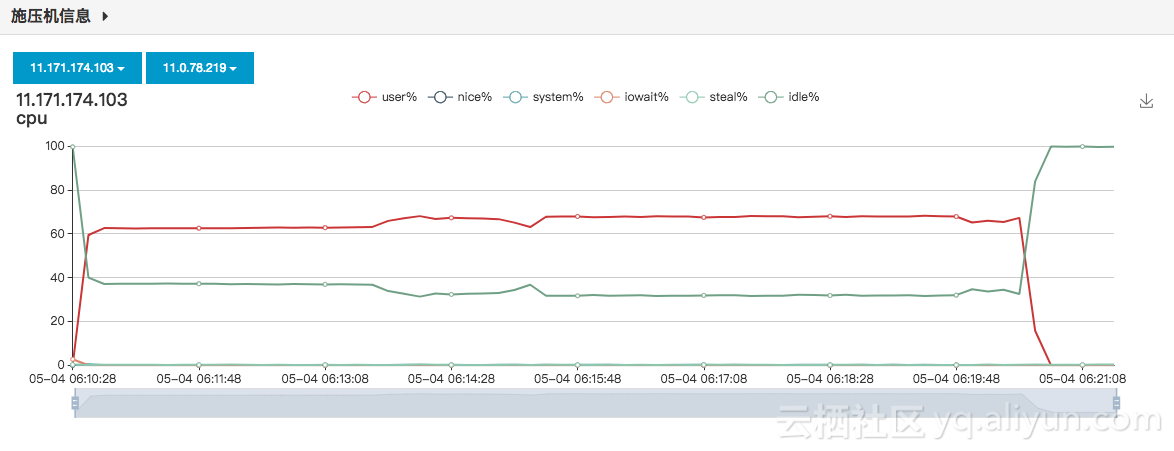
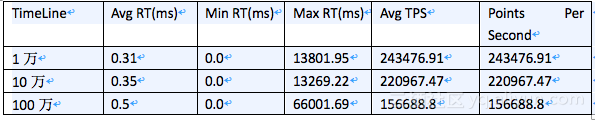
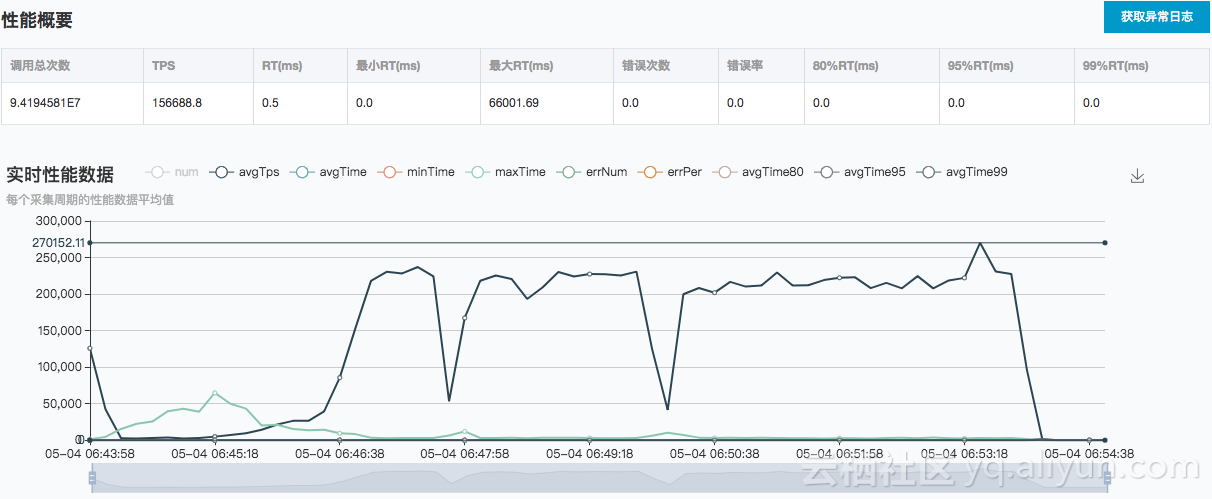
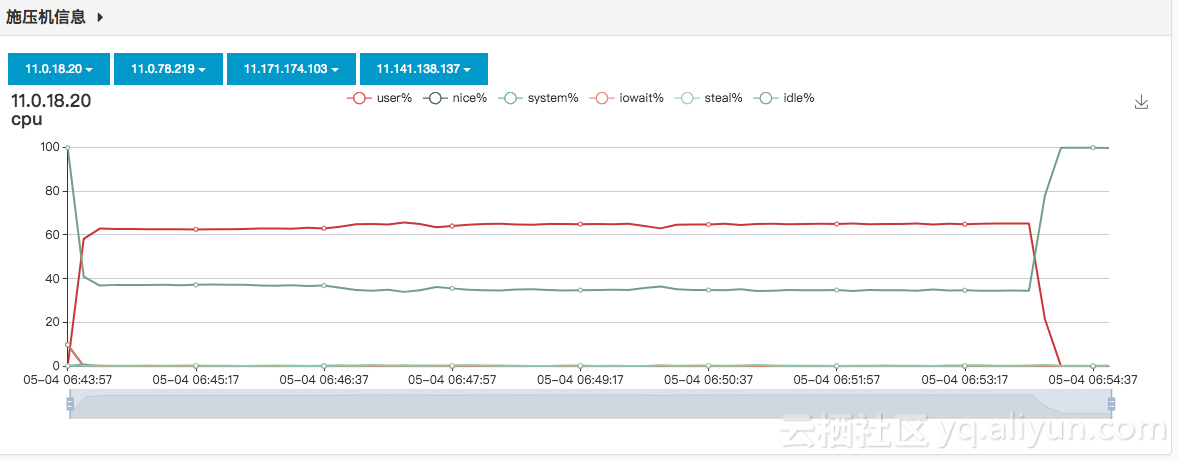
根据三组测试的结果分析可知,HiTSDB的写入TPS随着时间线的增长呈下降趋势,同时,1万和10万时间线量级下,即使增加客户端数量,TPS也基本变化不大,100万时间线数量级,从1台客户端增涨到2台时,TPS有所增涨;而2台增长到4台时,没有增涨。因此可以认为在6xlarge硬件下100万时间线HiTSDB的峰值写入TPS是在15万这个数量级,注意之所以说峰值,是因为需要注意的是本次测试的前置条件是清除数据,随着环境中时间线的增加,写入TPS会降下来,测试过,差不多是在5-6万TPS。
6.5 优化建议
1) 写入优化
一次批量写多个数据
2) 查询优化
如果需要一次性查询很长时间范围的数据,建议拆分为多个小时的数据来查询。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。