жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңHadoopзҡ„з”ҹжҖҒзі»з»ҹжҳҜд»Җд№ҲвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңHadoopзҡ„з”ҹжҖҒзі»з»ҹжҳҜд»Җд№ҲвҖқеҗ§пјҒ
hadoopз”ҹжҖҒзі»з»ҹпјҢж„ҸжҖқе°ұжҳҜд»Ҙhadoopдёәе№іеҸ°зҡ„еҗ„з§Қеә”з”ЁжЎҶжһ¶пјҢзӣёдә’е…је®№пјҢз»„жҲҗдәҶдёҖдёӘзӢ¬з«Ӣзҡ„еә”з”ЁдҪ“зі»пјҢд№ҹеҸҜд»Ҙз§°д№Ӣдёәз”ҹжҖҒеңҲгҖӮ
йҖҡиҝҮд»ҘдёӢзҡ„еӣҫпјҡ
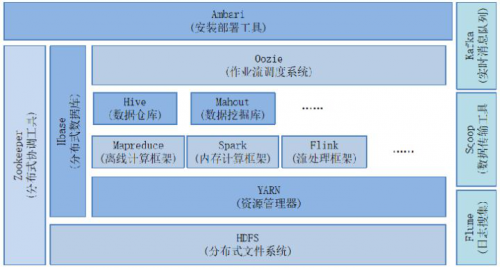
hadoopз”ҹжҖҒзі»з»ҹ
жҲ‘们еҸҜд»ҘеҸҜд»ҘжҖ»з»“еҰӮдёӢеёёз”Ёзҡ„еә”з”ЁжЎҶжһ¶пјҲеӣҫдёӯжІЎжңүзҡ„пјҢжҲ‘д№ҹеҲ—еҮәдәҶеҮ дёӘпјүпјҡ
1пјҢHDFSпјҲhadoopеҲҶеёғејҸж–Ү件系з»ҹпјү
жҳҜhadoopдҪ“зі»дёӯж•°жҚ®еӯҳеӮЁз®ЎзҗҶзҡ„еҹәзЎҖгҖӮд»–жҳҜдёҖдёӘй«ҳеәҰе®№й”ҷзҡ„зі»з»ҹпјҢиғҪжЈҖжөӢе’Ңеә”еҜ№зЎ¬д»¶ж•…йҡңгҖӮ
clientпјҡеҲҮеҲҶж–Ү件пјҢи®ҝй—®HDFSпјҢдёҺйӮЈд№Ҳеј„еҫ—дәӨдә’пјҢиҺ·еҸ–ж–Ү件дҪҚзҪ®дҝЎжҒҜпјҢдёҺDataNodeдәӨдә’пјҢиҜ»еҸ–е’ҢеҶҷе…Ҙж•°жҚ®гҖӮ
namenodeпјҡmasterиҠӮзӮ№пјҢеңЁhadoop1.xдёӯеҸӘжңүдёҖдёӘпјҢз®ЎзҗҶHDFSзҡ„еҗҚз§°з©әй—ҙе’Ңж•°жҚ®еқ—жҳ е°„дҝЎжҒҜпјҢй…ҚзҪ®еүҜжң¬зӯ–з•ҘпјҢеӨ„зҗҶе®ўжҲ· з«ҜиҜ·жұӮгҖӮ
DataNodeпјҡslaveиҠӮзӮ№пјҢеӯҳеӮЁе®һйҷ…зҡ„ж•°жҚ®пјҢжұҮжҠҘеӯҳеӮЁдҝЎжҒҜз»ҷnamenodeгҖӮ
secondary namenodeпјҡиҫ…еҠ©namenodeпјҢеҲҶжӢ…е…¶е·ҘдҪңйҮҸпјҡе®ҡжңҹеҗҲ并fsimageе’ҢfseditsпјҢжҺЁйҖҒз»ҷnamenodeпјӣзҙ§жҖҘжғ…еҶөдёӢе’Ңиҫ…еҠ©жҒўеӨҚnamenodeпјҢдҪҶ其并йқһnamenodeзҡ„зғӯеӨҮгҖӮ
2пјҢmapreduceпјҲеҲҶеёғејҸи®Ўз®—жЎҶжһ¶пјү
mapreduceжҳҜдёҖз§Қи®Ўз®—жЁЎеһӢпјҢз”ЁдәҺеӨ„зҗҶеӨ§ж•°жҚ®йҮҸзҡ„и®Ўз®—гҖӮе…¶дёӯmapеҜ№еә”ж•°жҚ®йӣҶдёҠзҡ„зӢ¬з«Ӣе…ғзҙ иҝӣиЎҢжҢҮе®ҡзҡ„ж“ҚдҪңпјҢз”ҹжҲҗй”®-еҖјеҜ№еҪўејҸдёӯй—ҙпјҢreduceеҲҷеҜ№дёӯй—ҙз»“жһңдёӯзӣёеҗҢзҡ„й”®зҡ„жүҖжңүеҖјиҝӣиЎҢ规зәҰпјҢд»Ҙеҫ—еҲ°жңҖз»Ҳз»“жһңгҖӮ
jobtrackerпјҡmasterиҠӮзӮ№пјҢеҸӘжңүдёҖдёӘпјҢз®ЎзҗҶжүҖжңүдҪңдёҡпјҢд»»еҠЎ/дҪңдёҡзҡ„зӣ‘жҺ§пјҢй”ҷиҜҜеӨ„зҗҶзӯүпјҢе°Ҷд»»еҠЎеҲҶи§ЈжҲҗдёҖзі»еҲ—д»»еҠЎпјҢ并еҲҶжҙҫз»ҷtasktrackerгҖӮ
tacktrackerпјҡslaveиҠӮзӮ№пјҢиҝҗиЎҢ map taskе’Ңreducetaskпјӣ并дёҺjobtrackerдәӨдә’пјҢжұҮжҠҘд»»еҠЎзҠ¶жҖҒгҖӮ
map taskпјҡи§ЈжһҗжҜҸжқЎж•°жҚ®и®°еҪ•пјҢдј йҖ’з»ҷз”ЁжҲ·зј–еҶҷзҡ„mapпјҲпјү并жү§иЎҢпјҢе°Ҷиҫ“еҮәз»“жһңеҶҷе…ҘеҲ°жң¬ең°зЈҒзӣҳпјҲеҰӮжһңдёәmapвҖ”onlyдҪңдёҡпјҢеҲҷзӣҙжҺҘеҶҷе…ҘHDFSпјүгҖӮ
reduce taskпјҡд»Һmap е®ғж·ұеҲ»ең°жү§иЎҢз»“жһңдёӯпјҢиҝңзЁӢиҜ»еҸ–иҫ“е…Ҙж•°жҚ®пјҢеҜ№ж•°жҚ®иҝӣиЎҢжҺ’еәҸпјҢе°Ҷж•°жҚ®еҲҶз»„дј йҖ’з»ҷз”ЁжҲ·зј–еҶҷзҡ„reduceеҮҪж•°жү§иЎҢгҖӮ
3пјҢ hiveпјҲеҹәдәҺhadoopзҡ„ж•°жҚ®д»“еә“пјү
з”ұFacebookејҖжәҗпјҢжңҖеҲқз”ЁдәҺи§ЈеҶіжө·йҮҸз»“жһ„еҢ–зҡ„ж—Ҙеҝ—ж•°жҚ®з»ҹи®Ўй—®йўҳгҖӮ
hiveе®ҡдәҺдәҶдёҖз§Қзұ»дјјsqlзҡ„жҹҘиҜўиҜӯиЁҖпјҲhqlпјүе°ҶsqlиҪ¬еҢ–дёәmapreduceд»»еҠЎеңЁhadoopдёҠжү§иЎҢгҖӮ
4пјҢhbaseпјҲеҲҶеёғејҸеҲ—еӯҳж•°жҚ®еә“пјү
hbaseжҳҜдёҖдёӘй’ҲеҜ№з»“жһ„еҢ–ж•°жҚ®зҡ„еҸҜдјёзј©пјҢй«ҳеҸҜйқ пјҢй«ҳжҖ§иғҪпјҢеҲҶеёғејҸе’Ңйқўеҗ‘еҲ—зҡ„еҠЁжҖҒжЁЎејҸж•°жҚ®еә“гҖӮе’Ңдј з»ҹе…ізі»еһӢж•°жҚ®еә“дёҚеҗҢпјҢhbaseйҮҮз”ЁдәҶbigtableзҡ„ж•°жҚ®жЁЎеһӢпјҡеўһејәдәҶзЁҖз–ҸжҺ’еәҸжҳ е°„иЎЁпјҲkey/valueпјүгҖӮе…¶дёӯпјҢй”®з”ұиЎҢе…ій”®еӯ—пјҢеҲ—е…ій”®еӯ—е’Ңж—¶й—ҙжҲіжһ„жҲҗпјҢhbaseжҸҗдҫӣдәҶеҜ№еӨ§и§„жЁЎж•°жҚ®зҡ„йҡҸжңәпјҢе®һж—¶иҜ»еҶҷи®ҝй—®пјҢеҗҢж—¶пјҢhbaseдёӯдҝқеӯҳзҡ„ж•°жҚ®еҸҜд»ҘдҪҝз”ЁmapreduceжқҘеӨ„зҗҶпјҢе®ғе°Ҷж•°жҚ®еӯҳеӮЁе’Ң并иЎҢи®Ўз®—е®ҢзҫҺз»“еҗҲеңЁдёҖиө·гҖӮ
5пјҢzookeeperпјҲеҲҶеёғејҸеҚҸдҪңжңҚеҠЎпјү
и§ЈеҶіеҲҶеёғејҸзҺҜеўғдёӢзҡ„ж•°жҚ®з®ЎзҗҶй—®йўҳпјҡз»ҹдёҖе‘ҪеҗҚпјҢзҠ¶жҖҒеҗҢжӯҘпјҢйӣҶзҫӨз®ЎзҗҶпјҢй…ҚзҪ®еҗҢжӯҘзӯүгҖӮ
6пјҢsqoopпјҲж•°жҚ®еҗҢжӯҘе·Ҙе…·пјү
sqoopжҳҜsql-to-hadoopзҡ„зј©еҶҷпјҢдё»иҰҒз”ЁдәҺдј з»ҹж•°жҚ®еә“е’Ңhadoopд№Ӣй—ҙдј иҫ“ж•°жҚ®гҖӮж•°жҚ®зҡ„еҜје…Ҙе’ҢеҜјеҮәжң¬иҙЁдёҠжҳҜmapreduceзЁӢеәҸпјҢе……еҲҶеҲ©з”ЁдәҶMRзҡ„并иЎҢеҢ–е’Ңе®№й”ҷжҖ§гҖӮ
7пјҢpigпјҲеҹәдәҺhadoopзҡ„ж•°жҚ®жөҒзі»з»ҹпјү
е®ҡд№үдәҶдёҖз§Қж•°жҚ®жөҒиҜӯиЁҖ-pig latinпјҢе°Ҷи„ҡжң¬иҪ¬жҚўдёәmapreduceд»»еҠЎеңЁhadoopдёҠжү§иЎҢгҖӮйҖҡеёёз”ЁдәҺзҰ»зәҝеҲҶжһҗгҖӮ
8пјҢmahoutпјҲж•°жҚ®жҢ–жҺҳз®—жі•еә“пјү
mahoutзҡ„дё»иҰҒзӣ®ж ҮжҳҜеҲӣе»әдёҖдәӣеҸҜжү©еұ•зҡ„жңәеҷЁеӯҰд№ йўҶеҹҹз»Ҹе…ёз®—жі•зҡ„е®һзҺ°пјҢж—ЁеңЁеё®еҠ©ејҖеҸ‘дәәе‘ҳжӣҙеҠ ж–№дҫҝеҝ«жҚ·ең°еҲӣе»әеҸӘиғҪеә”з”ЁзЁӢеәҸгҖӮmahoutзҺ°еңЁе·Із»ҸеҢ…еҗ«дәҶиҒҡзұ»пјҢеҲҶзұ»пјҢжҺЁиҚҗеј•ж“ҺпјҲеҚҸеҗҢиҝҮж»Өпјүе’Ңйў‘з№ҒйӣҶжҢ–жҺҳзӯүе№ҝжіӣдҪҝз”Ёзҡ„ж•°жҚ®жҢ–жҺҳж–№жі•гҖӮйҷӨдәҶз®—жі•жҳҜпјҢmahoutиҝҳеҢ…еҗ«дәҶж•°жҚ®зҡ„иҫ“е…Ҙ/иҫ“еҮәе·Ҙе…·пјҢдёҺе…¶д»–еӯҳеӮЁзі»з»ҹпјҲеҰӮж•°жҚ®еә“пјҢmongoDBжҲ–CassandraпјүйӣҶжҲҗзӯүж•°жҚ®жҢ–жҺҳж”ҜжҢҒжһ¶жһ„гҖӮ
9пјҢflumeпјҲж—Ҙеҝ—收йӣҶе·Ҙе…·пјү
clouderaејҖжәҗзҡ„ж—Ҙеҝ—收йӣҶзі»з»ҹпјҢе…·жңүеҲҶеёғејҸпјҢй«ҳеҸҜйқ пјҢй«ҳе®№й”ҷпјҢжҳ“дәҺе®ҡеҲ¶е’Ңжү©еұ•зҡ„зү№зӮ№гҖӮд»–е°Ҷж•°жҚ®д»Һдә§з”ҹпјҢдј иҫ“пјҢеӨ„зҗҶ并еҶҷе…Ҙзӣ®ж Үзҡ„и·Ҝеҫ„зҡ„иҝҮзЁӢжҠҪиұЎдёәж•°жҚ®жөҒпјҢеңЁе…·дҪ“зҡ„ж•°жҚ®жөҒдёӯпјҢж•°жҚ®жәҗж”ҜжҢҒеңЁflumeдёӯе®ҡеҲ¶ж•°жҚ®еҸ‘йҖҒж–№пјҢд»ҺиҖҢж”ҜжҢҒ收йӣҶеҗ„з§ҚдёҚеҗҢеҚҸи®®ж•°жҚ®гҖӮ
10пјҢиө„жәҗз®ЎзҗҶеҷЁзҡ„з®ҖеҚ•д»Ӣз»ҚпјҲYARNе’Ңmesosпјү
йҡҸзқҖдә’иҒ”зҪ‘зҡ„й«ҳйҖҹеҸ‘еұ•пјҢеҹәдәҺж•°жҚ® еҜҶйӣҶеһӢеә”з”Ё зҡ„и®Ўз®—жЎҶжһ¶дёҚж–ӯеҮәзҺ°пјҢд»Һж”ҜжҢҒзҰ»зәҝеӨ„зҗҶзҡ„mapreduceпјҢеҲ°ж”ҜжҢҒеңЁзәҝеӨ„зҗҶзҡ„stormпјҢд»Һиҝӯд»ЈејҸи®Ўз®—жЎҶжһ¶еҲ° жөҒејҸеӨ„зҗҶжЎҶжһ¶s4пјҢ...пјҢеңЁеӨ§йғЁеҲҶдә’иҒ”зҪ‘е…¬еҸёдёӯпјҢиҝҷеҮ з§ҚжЎҶжһ¶еҸҜиғҪйғҪдјҡйҮҮз”ЁпјҢжҜ”еҰӮеҜ№дәҺжҗңзҙўеј•ж“Һе…¬еҸёпјҢеҸҜиғҪзҡ„жҠҖжңҜж–№жі•еҰӮдёӢпјҡзҪ‘йЎөе»әзҙўеј•йҮҮз”ЁmapreduceжЎҶжһ¶пјҢиҮӘ然иҜӯиЁҖеӨ„зҗҶ/ж•°жҚ®жҢ–жҺҳйҮҮз”ЁsparkпјҢеҜ№жҖ§иғҪиҰҒжұӮеҲ°зҡ„ж•°жҚ®жҢ–жҺҳз®—жі•з”ЁmpiзӯүгҖӮе…¬еҸёдёҖиҲ¬е°ҶжүҖжңүзҡ„иҝҷдәӣжЎҶжһ¶йғЁзҪІеҲ°дёҖдёӘе…¬е…ұзҡ„йӣҶзҫӨдёӯпјҢи®©е®ғ们е…ұдә«йӣҶзҫӨзҡ„иө„жәҗпјҢ并еҜ№иө„жәҗиҝӣиЎҢз»ҹдёҖдҪҝз”ЁпјҢиҝҷж ·дҫҝиҜһз”ҹдәҶиө„жәҗз»ҹдёҖз®ЎзҗҶдёҺи°ғеәҰе№іеҸ°пјҢе…ёеһӢзҡ„д»ЈиЎЁжҳҜmesosе’ҢyarnгҖӮ
11пјҢе…¶д»–зҡ„дёҖдәӣејҖжәҗ组件пјҡ
1пјүcloudrea impalaпјҡ
дёҖдёӘејҖжәҗзҡ„жҹҘиҜўеј•ж“ҺгҖӮдёҺhiveзӣёеҗҢзҡ„е…ғж•°жҚ®пјҢSQLиҜӯжі•пјҢODBCй©ұеҠЁзЁӢеәҸе’Ңз”ЁжҲ·жҺҘеҸЈпјҢеҸҜд»ҘзӣҙжҺҘеңЁHDFSдёҠжҸҗдҫӣеҝ«йҖҹпјҢдәӨдә’ејҸSQLжҹҘиҜўгҖӮimpalaдёҚеҶҚдҪҝз”Ёзј“ж…ўзҡ„hive+mapreduceжү№еӨ„зҗҶпјҢиҖҢжҳҜйҖҡиҝҮдёҺе•Ҷ用并иЎҢе…ізі»ж•°жҚ®еә“дёӯзұ»дјјзҡ„еҲҶеёғејҸжҹҘиҜўеј•ж“ҺгҖӮеҸҜд»ҘзӣҙжҺҘд»ҺHDFSжҲ–иҖ…Hbaseдёӯз”ЁselectпјҢjoinе’Ңз»ҹи®ЎеҮҪж•°жҹҘиҜўж•°жҚ®пјҢд»ҺиҖҢеӨ§еӨ§йҷҚдҪҺ延иҝҹгҖӮ
2пјүsparkпјҡ
sparkжҳҜдёӘејҖжәҗзҡ„ж•°жҚ® еҲҶжһҗйӣҶзҫӨи®Ўз®—жЎҶжһ¶пјҢжңҖеҲқз”ұеҠ е·һеӨ§еӯҰдјҜе…ӢеҲ©еҲҶж ЎAMPLabпјҢе»әз«ӢдәҺHDFSд№ӢдёҠгҖӮsparkдёҺhadoopдёҖж ·пјҢз”ЁдәҺжһ„е»әеӨ§и§„жЁЎпјҢ延иҝҹдҪҺзҡ„ж•°жҚ®еҲҶжһҗеә”з”ЁгҖӮsparkйҮҮз”ЁScalaиҜӯиЁҖе®һзҺ°пјҢдҪҝз”ЁScalaдҪңдёәеә”з”ЁжЎҶжһ¶гҖӮ
sparkйҮҮз”ЁеҹәдәҺеҶ…еӯҳзҡ„еҲҶеёғејҸж•°жҚ®йӣҶпјҢдјҳеҢ–дәҶиҝӯд»ЈејҸзҡ„е·ҘдҪңиҙҹиҪҪд»ҘеҸҠдәӨдә’ејҸжҹҘиҜўгҖӮ
дёҺhadoopдёҚеҗҢзҡ„жҳҜпјҢsparkдёҺScalaзҙ§еҜҶйӣҶжҲҗпјҢScalaиұЎз®ЎзҗҶжң¬ең°collectiveеҜ№иұЎйӮЈж ·з®ЎзҗҶеҲҶеёғејҸж•°жҚ®йӣҶгҖӮsparkж”ҜжҢҒеҲҶеёғејҸж•°жҚ®йӣҶдёҠзҡ„иҝӯд»ЈејҸд»»еҠЎпјҢе®һйҷ…дёҠеҸҜд»ҘеңЁhadoopж–Ү件系з»ҹдёҠдёҺhadoopдёҖиө·иҝҗиЎҢпјҲйҖҡиҝҮYARN,MESOSзӯүе®һзҺ°пјүгҖӮ
3пјүstorm
stormжҳҜдёҖдёӘеҲҶеёғејҸзҡ„пјҢе®№й”ҷзҡ„и®Ўз®—зі»з»ҹпјҢstormеұһдәҺжөҒеӨ„зҗҶе№іеҸ°пјҢеӨҡз”ЁдәҺе®һ时计算并жӣҙж–°ж•°жҚ®еә“гҖӮstormд№ҹеҸҜиў«з”ЁдәҺвҖңиҝһз»ӯи®Ўз®—вҖқпјҢеҜ№ж•°жҚ®жөҒеҒҡиҝһз»ӯжҹҘиҜўпјҢеңЁи®Ўз®—ж—¶е°Ҷз»“жһңдёҖжөҒзҡ„еҪўејҸиҫ“еҮәз»ҷз”ЁжҲ·гҖӮд»–иҝҳеҸҜиў«з”ЁдәҺвҖңеҲҶеёғејҸRPCвҖқ,д»Ҙ并иЎҢзҡ„ж–№ејҸиҝҗиЎҢжҳӮиҙөзҡ„иҝҗз®—гҖӮ
4)kafka
kafkaжҳҜз”ұApacheиҪҜ件еҹәйҮ‘дјҡејҖеҸ‘зҡ„дёҖдёӘејҖжәҗжөҒеӨ„зҗҶе№іеҸ°пјҢз”ұScalaе’ҢJavaзј–еҶҷгҖӮKafkaжҳҜдёҖз§Қй«ҳеҗһеҗҗйҮҸзҡ„еҲҶеёғејҸеҸ‘еёғи®ўйҳ…ж¶ҲжҒҜзі»з»ҹпјҢе®ғеҸҜд»ҘеӨ„зҗҶж¶Ҳиҙ№иҖ…规模зҡ„зҪ‘з«ҷдёӯзҡ„жүҖжңүеҠЁдҪңжөҒж•°жҚ®гҖӮ иҝҷз§ҚеҠЁдҪңпјҲзҪ‘йЎөжөҸи§ҲпјҢжҗңзҙўе’Ңе…¶д»–з”ЁжҲ·зҡ„иЎҢеҠЁпјүжҳҜеңЁзҺ°д»ЈзҪ‘з»ңдёҠзҡ„и®ёеӨҡзӨҫдјҡеҠҹиғҪзҡ„дёҖдёӘе…ій”®еӣ зҙ гҖӮ иҝҷдәӣж•°жҚ®йҖҡеёёжҳҜз”ұдәҺеҗһеҗҗйҮҸзҡ„иҰҒжұӮиҖҢйҖҡиҝҮеӨ„зҗҶж—Ҙеҝ—е’Ңж—Ҙеҝ—иҒҡеҗҲжқҘи§ЈеҶігҖӮ еҜ№дәҺеғҸHadoopзҡ„дёҖж ·зҡ„ж—Ҙеҝ—ж•°жҚ®е’ҢзҰ»зәҝеҲҶжһҗзі»з»ҹпјҢдҪҶеҸҲиҰҒжұӮе®һж—¶еӨ„зҗҶзҡ„йҷҗеҲ¶пјҢиҝҷжҳҜдёҖдёӘеҸҜиЎҢзҡ„и§ЈеҶіж–№жЎҲгҖӮKafkaзҡ„зӣ®зҡ„жҳҜйҖҡиҝҮHadoopзҡ„并иЎҢеҠ иҪҪжңәеҲ¶жқҘз»ҹдёҖзәҝдёҠе’ҢзҰ»зәҝзҡ„ж¶ҲжҒҜеӨ„зҗҶпјҢд№ҹжҳҜдёәдәҶйҖҡиҝҮйӣҶзҫӨжқҘжҸҗдҫӣе®һж—¶зҡ„ж¶ҲжҒҜ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңHadoopзҡ„з”ҹжҖҒзі»з»ҹжҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№Hadoopзҡ„з”ҹжҖҒзі»з»ҹжҳҜд»Җд№ҲиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ