жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңжңәеҷЁеӯҰд№ дёӯж„ҹзҹҘеҷЁжҳҜжҖҺд№Ҳдә§з”ҹзҡ„вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
ж„ҹзҹҘеҷЁзҡ„иҜһз”ҹвҖ”вҖ”д»Һж ·жң¬дёӯеӯҰд№
зҘһз»ҸзҪ‘з»ңзҡ„AIе…Ҳй©ұ们дёҖзӣҙдҫқйқ зқҖзҘһз»Ҹе…ғзҡ„з»ҳеӣҫд»ҘеҸҠе®ғ们зӣёдә’иҝһжҺҘзҡ„ж–№ејҸпјҢиҝӣиЎҢзқҖиү°йҡҫзҡ„ж‘ёзҙўгҖӮеә·еҘҲе°”еӨ§еӯҰзҡ„еј—е…°е…ӢВ·зҪ—жЈ®еёғжӢүзү№жҳҜжңҖж—©жЁЎд»ҝдәәдҪ“иҮӘеҠЁеӣҫжЎҲиҜҶеҲ«и§Ҷи§үзі»з»ҹжһ¶жһ„зҡ„дәәд№ӢдёҖгҖӮ
д»–еҸ‘жҳҺдәҶдёҖз§ҚзңӢдјјз®ҖеҚ•зҡ„зҪ‘з»ңж„ҹзҹҘеҷЁпјҲperceptronпјүпјҢиҝҷз§ҚеӯҰд№ з®—жі•еҸҜд»ҘеӯҰд№ еҰӮдҪ•е°ҶеӣҫжЎҲиҝӣиЎҢеҲҶзұ»пјҢдҫӢеҰӮиҜҶеҲ«еӯ—жҜҚиЎЁдёӯзҡ„дёҚеҗҢеӯ—жҜҚгҖӮ**з®—жі•жҳҜдёәдәҶе®һзҺ°зү№е®ҡзӣ®ж ҮиҖҢжҢүжӯҘйӘӨжү§иЎҢзҡ„иҝҮзЁӢпјҢ**е°ұеғҸзғҳз„ҷиӣӢзі•зҡ„йЈҹи°ұдёҖж ·гҖӮ
еҰӮжһңжҲ‘们дәҶи§ЈдәҶж„ҹзҹҘеҷЁеҰӮдҪ•еӯҰд№ еӣҫжЎҲиҜҶеҲ«зҡ„еҹәжң¬еҺҹеҲҷпјҢйӮЈд№ҲеңЁзҗҶи§Јж·ұеәҰеӯҰд№ е·ҘдҪңеҺҹзҗҶзҡ„и·ҜдёҠе·Із»ҸжҲҗеҠҹдәҶдёҖеҚҠгҖӮж„ҹзҹҘеҷЁзҡ„зӣ®ж ҮжҳҜзЎ®е®ҡиҫ“е…Ҙзҡ„еӣҫжЎҲжҳҜеҗҰеұһдәҺеӣҫеғҸдёӯзҡ„жҹҗдёҖзұ»еҲ«пјҲжҜ”еҰӮзҢ«пјүгҖӮ
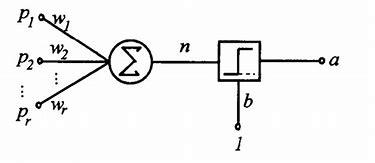
дёҠеӣҫи§ЈйҮҠдәҶж„ҹзҹҘеҷЁзҡ„иҫ“е…ҘеҰӮдҪ•йҖҡиҝҮдёҖз»„жқғйҮҚпјҢжқҘе®һзҺ°иҫ“е…ҘеҚ•е…ғеҲ°иҫ“еҮәеҚ•е…ғзҡ„иҪ¬жҚўгҖӮжқғйҮҚжҳҜеҜ№жҜҸдёҖж¬Ўиҫ“е…ҘеҜ№иҫ“еҮәеҚ•е…ғеҒҡеҮәзҡ„жңҖз»ҲеҶіе®ҡжүҖдә§з”ҹеҪұе“Қзҡ„еәҰйҮҸпјҢдҪҶжҳҜжҲ‘们еҰӮдҪ•жүҫеҲ°дёҖз»„еҸҜд»Ҙе°Ҷиҫ“е…ҘиҝӣиЎҢжӯЈзЎ®еҲҶзұ»зҡ„жқғйҮҚе‘ўпјҹ
и§ЈеҶіиҝҷдёӘй—®йўҳзҡ„дј з»ҹж–№жі•пјҢжҳҜж №жҚ®еҲҶжһҗжҲ–зү№е®ҡзЁӢеәҸжқҘжүӢеҠЁи®ҫе®ҡжқғйҮҚгҖӮиҝҷйңҖиҰҒиҖ—иҙ№еӨ§йҮҸдәәеҠӣпјҢиҖҢдё”еҫҖеҫҖдҫқиө–дәҺзӣҙи§үе’Ңе·ҘзЁӢж–№жі•гҖӮеҸҰдёҖз§Қж–№жі•еҲҷжҳҜдҪҝз”ЁдёҖз§Қд»Һж ·жң¬дёӯеӯҰд№ зҡ„иҮӘеҠЁиҝҮзЁӢпјҢе’ҢжҲ‘们и®ӨиҜҶдё–з•ҢдёҠзҡ„еҜ№иұЎзҡ„ж–№жі•дёҖж ·гҖӮйңҖиҰҒеҫҲеӨҡж ·жң¬жқҘи®ӯз»ғж„ҹзҹҘеҷЁпјҢеҢ…жӢ¬дёҚеұһдәҺиҜҘзұ»еҲ«зҡ„еҸҚйқўж ·жң¬пјҢзү№еҲ«жҳҜе’Ңзӣ®ж Үзү№еҫҒзӣёдјјзҡ„пјҢдҫӢеҰӮпјҢеҰӮжһңиҜҶеҲ«зӣ®ж ҮжҳҜзҢ«пјҢйӮЈд№ҲзӢ—е°ұжҳҜдёҖдёӘзӣёдјјзҡ„еҸҚйқўж ·жң¬гҖӮиҝҷдәӣж ·жң¬иў«йҖҗдёӘдј йҖ’з»ҷж„ҹзҹҘеҷЁпјҢеҰӮжһңеҮәзҺ°еҲҶзұ»й”ҷиҜҜпјҢз®—жі•е°ұдјҡиҮӘеҠЁеҜ№жқғйҮҚиҝӣиЎҢж ЎжӯЈгҖӮ
ж„ҹзҹҘеҷЁе…·дҪ“з®—жі•
иҝҷз§Қж„ҹзҹҘеҷЁеӯҰд№ з®—жі•зҡ„зҫҺеҰҷд№ӢеӨ„еңЁдәҺпјҢеҰӮжһңе·Із»ҸеӯҳеңЁиҝҷж ·дёҖз»„жқғйҮҚпјҢ并且жңүи¶іеӨҹж•°йҮҸзҡ„ж ·жң¬пјҢйӮЈд№Ҳе®ғиӮҜе®ҡиғҪиҮӘеҠЁең°жүҫеҲ°дёҖз»„еҗҲйҖӮзҡ„жқғйҮҚгҖӮеңЁжҸҗдҫӣдәҶи®ӯз»ғйӣҶдёӯзҡ„жҜҸдёӘж ·жң¬пјҢ并且е°Ҷиҫ“еҮәдёҺжӯЈзЎ®зӯ”жЎҲиҝӣиЎҢжҜ”иҫғеҗҺпјҢж„ҹзҹҘеҷЁдјҡиҝӣиЎҢйҖ’иҝӣејҸзҡ„еӯҰд№ гҖӮеҰӮжһңзӯ”жЎҲжҳҜжӯЈзЎ®зҡ„пјҢйӮЈд№ҲжқғйҮҚе°ұдёҚдјҡеҸ‘з”ҹеҸҳеҢ–гҖӮдҪҶеҰӮжһңзӯ”жЎҲдёҚжӯЈзЎ®пјҲ0иў«иҜҜеҲӨжҲҗдәҶ1пјҢжҲ–1иў«иҜҜеҲӨжҲҗдәҶ0пјүпјҢжқғйҮҚе°ұдјҡиў«з•Ҙеҫ®и°ғж•ҙпјҢд»ҘдҫҝдёӢдёҖ次收еҲ°зӣёеҗҢзҡ„иҫ“е…Ҙж—¶пјҢе®ғдјҡжӣҙжҺҘиҝ‘жӯЈзЎ®зӯ”гҖӮиҝҷз§Қжёҗиҝӣзҡ„еҸҳеҢ–еҫҲйҮҚиҰҒпјҢиҝҷж ·дёҖжқҘпјҢжқғйҮҚе°ұиғҪжҺҘ收жқҘиҮӘжүҖжңүи®ӯз»ғж ·жң¬зҡ„еҪұе“ҚпјҢиҖҢдёҚд»…д»…жҳҜжңҖеҗҺдёҖдёӘгҖӮ

ж„ҹзҹҘеҷЁжҳҜе…·жңүеҚ•дёҖдәәйҖ shenз»Ҹе…ғзҡ„зҘһз»ҸзҪ‘з»ңпјҢе®ғжңүдёҖдёӘиҫ“е…ҘеұӮпјҢе’Ңе°Ҷиҫ“е…ҘеҚ•е…ғе’Ңиҫ“еҮәеҚ•е…ғзӣёиҝһзҡ„дёҖз»„иҝһжҺҘгҖӮж„ҹзҹҘеҷЁзҡ„зӣ®ж ҮжҳҜеҜ№жҸҗдҫӣз»ҷиҫ“е…ҘеҚ•е…ғзҡ„еӣҫжЎҲиҝӣиЎҢеҲҶзұ»гҖӮиҫ“еҮәеҚ•е…ғжү§иЎҢзҡ„еҹәжң¬ж“ҚдҪңжҳҜпјҢжҠҠжҜҸдёӘиҫ“е…ҘпјҲxnпјүдёҺе…¶иҝһжҺҘејәеәҰжҲ–жқғйҮҚпјҲwnпјүзӣёд№ҳпјҢ并е°Ҷд№ҳз§Ҝзҡ„жҖ»е’Ңдј йҖ’з»ҷиҫ“еҮәеҚ•е…ғгҖӮдёҠеӣҫдёӯпјҢиҫ“е…Ҙзҡ„еҠ жқғе’ҢпјҲвҲ‘i=1,вҖҰ,n wi xiпјүдёҺйҳҲеҖјОёиҝӣиЎҢжҜ”иҫғеҗҺзҡ„з»“жһңиў«дј йҖ’з»ҷйҳ¶и·ғеҮҪж•°гҖӮеҰӮжһңжҖ»е’Ңи¶…иҝҮйҳҲеҖјпјҢеҲҷйҳ¶и·ғеҮҪж•°иҫ“еҮәвҖң1вҖқпјҢеҗҰеҲҷиҫ“еҮәвҖң0вҖқгҖӮдҫӢеҰӮпјҢиҫ“е…ҘеҸҜд»ҘжҳҜеӣҫеғҸдёӯеғҸзҙ зҡ„ејәеәҰпјҢжҲ–иҖ…жӣҙеёёи§Ғзҡ„жғ…еҶөжҳҜпјҢд»ҺеҺҹе§ӢеӣҫеғҸдёӯжҸҗеҸ–зҡ„зү№еҫҒпјҢдҫӢеҰӮеӣҫеғҸдёӯеҜ№иұЎзҡ„иҪ®е»“гҖӮжҜҸж¬Ўиҫ“е…ҘдёҖдёӘеӣҫеғҸпјҢж„ҹзҹҘеҷЁдјҡеҲӨе®ҡиҜҘеӣҫеғҸжҳҜеҗҰдёәжҹҗзұ»еҲ«зҡ„жҲҗе‘ҳпјҢдҫӢеҰӮзҢ«зұ»гҖӮиҫ“еҮәеҸӘиғҪжҳҜдёӨз§ҚзҠ¶жҖҒд№ӢдёҖпјҢеҰӮжһңеӣҫеғҸеӨ„дәҺзұ»еҲ«дёӯпјҢеҲҷдёәвҖңејҖвҖқпјҢеҗҰеҲҷдёәвҖңе…івҖқгҖӮвҖңејҖвҖқе’ҢвҖңе…івҖқеҲҶеҲ«еҜ№еә”дәҢиҝӣеҲ¶еҖјдёӯзҡ„1е’Ң0гҖӮ
ж„ҹзҹҘеҷЁеӯҰд№ з®—жі•еҸҜд»ҘиЎЁиҫҫдёәпјҡ
ж„ҹзҹҘеҷЁеҰӮдҪ•еҢәеҲҶдёӨдёӘеҜ№иұЎзұ»еҲ«зҡ„еҮ дҪ•и§ЈйҮҠ
еҰӮжһңеҜ№ж„ҹзҹҘеҷЁеӯҰд№ зҡ„иҝҷз§Қи§ЈйҮҠиҝҳдёҚеӨҹжё…жҘҡпјҢжҲ‘们иҝҳеҸҜд»ҘйҖҡиҝҮеҸҰдёҖз§Қжӣҙз®ҖжҙҒзҡ„еҮ дҪ•ж–№жі•пјҢжқҘзҗҶи§Јж„ҹзҹҘеҷЁеҰӮдҪ•еӯҰд№ еҜ№иҫ“е…ҘиҝӣиЎҢеҲҶзұ»гҖӮеҜ№дәҺеҸӘжңүдёӨдёӘиҫ“е…ҘеҚ•е…ғзҡ„зү№ж®Ҡжғ…еҶөпјҢеҸҜд»ҘеңЁдәҢз»ҙеӣҫдёҠз”ЁзӮ№жқҘиЎЁзӨәиҫ“е…Ҙж ·жң¬гҖӮжҜҸдёӘиҫ“е…ҘйғҪжҳҜеӣҫдёӯзҡ„дёҖдёӘзӮ№пјҢиҖҢзҪ‘з»ңдёӯзҡ„дёӨдёӘжқғйҮҚеҲҷзЎ®е®ҡдәҶдёҖжқЎзӣҙзәҝгҖӮж„ҹзҹҘеҷЁеӯҰд№ зҡ„зӣ®ж ҮжҳҜ移еҠЁиҝҷжқЎзәҝпјҢд»Ҙдҫҝжё…жҘҡең°еҢәеҲҶжӯЈиҙҹж ·жң¬гҖӮеҜ№дәҺжңүдёүдёӘиҫ“е…ҘеҚ•е…ғзҡ„жғ…еҶөпјҢиҫ“е…Ҙз©әй—ҙжҳҜдёүз»ҙзҡ„пјҢж„ҹзҹҘеҷЁдјҡжҢҮе®ҡдёҖдёӘе№ійқўжқҘеҲҶйҡ”жӯЈиҙҹи®ӯз»ғж ·жң¬гҖӮеңЁдёҖиҲ¬зҡ„жғ…еҶөдёӢпјҢеҚідҪҝиҫ“е…Ҙз©әй—ҙзҡ„з»ҙеәҰеҸҜиғҪзӣёеҪ“й«ҳдё”ж— жі•еҸҜи§ҶеҢ–пјҢеҗҢж ·зҡ„еҺҹеҲҷдҫқ然жҲҗз«ӢгҖӮ
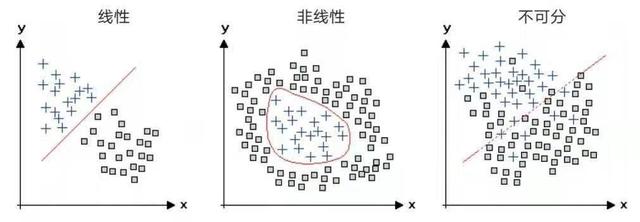
иҝҷдәӣеҜ№иұЎжңүдёӨдёӘзү№еҫҒпјҢдҫӢеҰӮе°әеҜёе’Ңдә®еәҰпјҢе®ғ们дҫқжҚ®еҗ„иҮӘзҡ„еқҗж ҮеҖјпјҲxпјҢyпјүиў«з»ҳеҲ¶еңЁжҜҸеј еӣҫдёҠгҖӮе·Ұиҫ№еӣҫдёӯзҡ„дёӨз§ҚеҜ№иұЎпјҲеҠ еҸ·е’ҢжӯЈж–№еҪўпјүеҸҜд»ҘйҖҡиҝҮе®ғ们д№Ӣй—ҙзҡ„зӣҙзәҝеҲҶйҡ”ејҖпјӣж„ҹзҹҘеҷЁиғҪеӨҹеӯҰд№ еҰӮдҪ•иҝӣиЎҢиҝҷз§ҚеҢәеҲҶгҖӮе…¶д»–дёӨдёӘеӣҫдёӯзҡ„дёӨз§ҚеҜ№иұЎдёҚиғҪз”Ёзӣҙзәҝйҡ”ејҖпјҢдҪҶеңЁдёӯй—ҙзҡ„еӣҫдёӯпјҢдёӨз§ҚеҜ№иұЎеҸҜд»Ҙз”ЁжӣІзәҝеҲҶејҖгҖӮиҖҢеҸідҫ§еӣҫдёӯзҡ„еҜ№иұЎеҝ…йЎ»иҲҚејғдёҖдәӣж ·жң¬жүҚиғҪеҲҶйҡ”жҲҗдёӨз§Қзұ»еһӢгҖӮеҰӮжһңжңүи¶іеӨҹзҡ„и®ӯз»ғж•°жҚ®пјҢж·ұеәҰеӯҰд№ зҪ‘з»ңе°ұиғҪеӨҹеӯҰд№ еҰӮдҪ•еҜ№иҝҷдёүдёӘеӣҫдёӯзҡ„зұ»еһӢиҝӣиЎҢеҢәеҲҶгҖӮ
жңҖз»ҲпјҢеҰӮжһңи§ЈеҶіж–№жЎҲжҳҜеҸҜиЎҢзҡ„пјҢжқғйҮҚе°ҶдёҚеҶҚеҸҳеҢ–пјҢиҝҷж„Ҹе‘ізқҖж„ҹзҹҘеҷЁе·Із»ҸжӯЈзЎ®ең°е°Ҷи®ӯз»ғйӣҶдёӯзҡ„жүҖжңүж ·жң¬иҝӣиЎҢдәҶеҲҶзұ»гҖӮ
дҪҶжҳҜпјҢеңЁжүҖи°“зҡ„вҖңиҝҮеәҰжӢҹеҗҲвҖқпјҲoverfittingпјүдёӯпјҢд№ҹеҸҜиғҪжІЎжңүи¶іеӨҹзҡ„ж ·жң¬пјҢзҪ‘з»ңд»…д»…и®°дҪҸдәҶзү№е®ҡзҡ„ж ·жң¬пјҢиҖҢдёҚиғҪе°Ҷз»“и®әжҺЁе№ҝеҲ°ж–°зҡ„ж ·жң¬гҖӮдёәдәҶйҒҝе…ҚиҝҮеәҰжӢҹеҗҲпјҢе…ій”®жҳҜиҰҒжңүеҸҰдёҖеҘ—ж ·жң¬пјҢз§°дёәвҖңжөӢиҜ•йӣҶвҖқпјҲtest setпјүпјҢе®ғжІЎжңүиў«з”ЁдәҺи®ӯз»ғзҪ‘з»ңгҖӮи®ӯз»ғз»“жқҹж—¶пјҢеңЁжөӢиҜ•йӣҶдёҠзҡ„еҲҶзұ»иЎЁзҺ°пјҢе°ұжҳҜеҜ№ж„ҹзҹҘеҷЁжҳҜеҗҰиғҪеӨҹжҺЁе№ҝеҲ°зұ»еҲ«жңӘзҹҘзҡ„ж–°ж ·жң¬зҡ„зңҹе®һеәҰйҮҸгҖӮжіӣеҢ–пјҲgeneralizationпјүжҳҜиҝҷйҮҢзҡ„е…ій”®жҰӮеҝөгҖӮеңЁзҺ°е®һз”ҹжҙ»дёӯпјҢжҲ‘们еҮ д№ҺдёҚдјҡеңЁеҗҢж ·зҡ„и§Ҷи§’зңӢеҲ°еҗҢдёҖдёӘеҜ№иұЎпјҢжҲ–иҖ…еҸҚеӨҚйҒҮеҲ°еҗҢж ·зҡ„еңәжҷҜпјҢдҪҶеҰӮжһңжҲ‘们иғҪеӨҹе°Ҷд»ҘеүҚзҡ„з»ҸйӘҢжіӣеҢ–еҲ°ж–°зҡ„и§Ҷи§’жҲ–еңәжҷҜдёӯпјҢжҲ‘们е°ұеҸҜд»ҘеӨ„зҗҶжӣҙеӨҡзҺ°е®һдё–з•Ңзҡ„й—®йўҳгҖӮ
еҲ©з”Ёж„ҹзҹҘеҷЁеҢәеҲҶжҖ§еҲ«
дёҫдёҖдёӘз”Ёж„ҹзҹҘеҷЁи§ЈеҶізҺ°е®һдё–з•Ңй—®йўҳзҡ„дҫӢеӯҗгҖӮжғіжғіеҰӮжһңеҺ»жҺүеӨҙеҸ‘гҖҒйҰ–йҘ°е’Ң第дәҢжҖ§еҫҒпјҢжҜ”еҰӮз”·жҖ§жҜ”еҘіжҖ§жӣҙдёәзӘҒиө·зҡ„е–үз»“пјҢиҜҘеҰӮдҪ•еҢәеҲҶз”·жҖ§е’ҢеҘіжҖ§зҡ„йқўйғЁгҖӮ
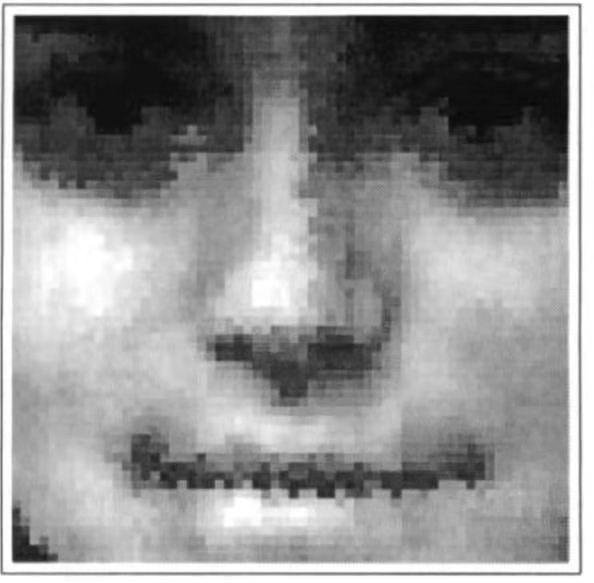
иҝҷеј и„ёеұһдәҺз”·жҖ§иҝҳжҳҜеҘіжҖ§пјҹдәә们йҖҡиҝҮи®ӯз»ғж„ҹзҹҘеҷЁжқҘиҫЁеҲ«з”·жҖ§е’ҢеҘіжҖ§зҡ„йқўеӯ”гҖӮжқҘиҮӘйқўйғЁеӣҫеғҸпјҲдёҠеӣҫпјүзҡ„еғҸзҙ д№ҳд»Ҙзӣёеә”зҡ„жқғйҮҚпјҲдёӢеӣҫпјүпјҢ并е°ҶиҜҘд№ҳз§Ҝзҡ„жҖ»е’ҢдёҺйҳҲеҖјиҝӣиЎҢжҜ”иҫғгҖӮжҜҸдёӘжқғйҮҚзҡ„еӨ§е°Ҹиў«жҸҸз»ҳдёәдёҚеҗҢйўңиүІеғҸзҙ зҡ„йқўз§ҜгҖӮжӯЈеҖјзҡ„жқғйҮҚпјҲзҷҪиүІпјүиЎЁзҺ°дёәз”·жҖ§пјҢиҙҹеҖјзҡ„жқғйҮҚпјҲй»‘иүІпјүеҖҫеҗ‘дәҺеҘіжҖ§гҖӮйј»еӯҗе®ҪеәҰпјҢйј»еӯҗе’Ңеҳҙд№Ӣй—ҙеҢәеҹҹзҡ„еӨ§е°ҸпјҢд»ҘеҸҠзңјзқӣеҢәеҹҹе‘Ёеӣҙзҡ„еӣҫеғҸејәеәҰеҜ№дәҺеҢәеҲҶз”·жҖ§еҫҲйҮҚиҰҒпјҢиҖҢеҳҙе’Ңйў§йӘЁе‘Ёеӣҙзҡ„еӣҫеғҸејәеәҰеҜ№дәҺеҢәеҲҶеҘіжҖ§жӣҙйҮҚиҰҒгҖӮ

еҢәеҲҶз”·жҖ§дёҺеҘіжҖ§йқўйғЁзҡ„е·ҘдҪңжңүи¶Јзҡ„дёҖзӮ№жҳҜпјҢиҷҪ然жҲ‘们еҫҲж“…й•ҝеҒҡиҝҷз§ҚеҢәеҲҶпјҢеҚҙж— жі•зЎ®еҲҮең°иЎЁиҝ°з”·еҘійқўйғЁд№Ӣй—ҙзҡ„е·®ејӮгҖӮз”ұдәҺжІЎжңүеҚ•дёҖзү№еҫҒжҳҜеҶіе®ҡжҖ§зҡ„пјҢеӣ жӯӨиҝҷз§ҚжЁЎејҸиҜҶеҲ«й—®йўҳиҰҒдҫқиө–дәҺе°ҶеӨ§йҮҸдҪҺзә§зү№еҫҒзҡ„иҜҒжҚ®з»“еҗҲиө·жқҘгҖӮж„ҹзҹҘеҷЁзҡ„дјҳзӮ№еңЁдәҺпјҢжқғйҮҚжҸҗдҫӣдәҶеҜ№жҖ§еҲ«еҢәеҲҶжңҖжңүеё®еҠ©зҡ„йқўйғЁзҡ„зәҝзҙўгҖӮд»ӨдәәжғҠ讶зҡ„жҳҜпјҢдәәдёӯпјҲеҚійј»еӯҗе’Ңеҳҙе”Үд№Ӣй—ҙзҡ„йғЁеҲҶпјүжҳҜжңҖжҳҫи‘—зҡ„зү№еҫҒпјҢеӨ§еӨҡж•°з”·жҖ§дәәдёӯзҡ„йқўз§ҜжӣҙеӨ§гҖӮзңјзқӣе‘Ёеӣҙзҡ„еҢәеҹҹпјҲз”·жҖ§иҫғеӨ§пјүе’ҢдёҠйўҠпјҲеҘіжҖ§иҫғеӨ§пјүеҜ№дәҺжҖ§еҲ«еҲҶзұ»д№ҹжңүзқҖеҫҲй«ҳзҡ„дҝЎжҒҜд»·еҖјгҖӮж„ҹзҹҘеҷЁдјҡжқғиЎЎжқҘиҮӘжүҖжңүиҝҷдәӣдҪҚзҪ®зҡ„иҜҒжҚ®жқҘеҒҡеҮәеҶіе®ҡпјҢжҲ‘们д№ҹжҳҜиҝҷж ·жқҘеҒҡеҲӨе®ҡзҡ„пјҢе°Ҫз®ЎжҲ‘们еҸҜиғҪж— жі•жҸҸиҝ°еҮәеҲ°еә•жҳҜжҖҺд№ҲеҒҡеҲ°зҡ„гҖӮ
ж„ҹзҹҘеҷЁзҡ„жү©еұ•
ж„ҹзҹҘеҷЁжҝҖеҸ‘дәҶеҜ№й«ҳз»ҙз©әй—ҙдёӯжЁЎејҸеҲҶзҰ»зҡ„зҫҺеҰҷзҡ„ж•°еӯҰеҲҶжһҗгҖӮеҪ“йӮЈдәӣзӮ№еӯҳеңЁдәҺжңүж•°еҚғдёӘз»ҙеәҰзҡ„з©әй—ҙдёӯж—¶пјҢжҲ‘们е°ұж— жі•дҫқиө–еңЁз”ҹжҙ»зҡ„дёүз»ҙз©әй—ҙйҮҢеҜ№зӮ№е’ҢзӮ№д№Ӣй—ҙи·қзҰ»зҡ„зӣҙи§үгҖӮдҝ„зҪ—ж–Ҝж•°еӯҰ家弗жӢүеҹәзұіе°”В·з“Ұжҷ®е°је…ӢпјҲVladimir VapnikпјүеңЁиҝҷз§ҚеҲҶжһҗзҡ„еҹәзЎҖдёҠеј•е…ҘдәҶдёҖдёӘеҲҶзұ»еҷЁпјҢз§°дёәвҖңж”ҜжҢҒеҗ‘йҮҸжңәвҖқпјҲSupport Vector MachineпјүгҖӮ
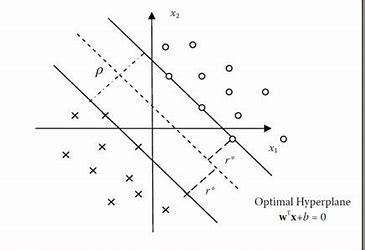
е®ғе°Ҷж„ҹзҹҘеҷЁжіӣеҢ–пјҢ并被еӨ§йҮҸз”ЁдәҺжңәеҷЁеӯҰд№ гҖӮд»–жүҫеҲ°дәҶдёҖз§ҚиҮӘеҠЁеҜ»жүҫе№ійқўзҡ„ж–№жі•пјҢиғҪеӨҹжңҖеӨ§йҷҗеәҰең°е°ҶдёӨдёӘзұ»еҲ«зҡ„зӮ№еҲҶејҖпјҲзәҝжҖ§пјүгҖӮиҝҷи®©жіӣеҢ–еҜ№з©әй—ҙдёӯж•°жҚ®зӮ№зҡ„жөӢйҮҸиҜҜе·®е®№еҝҚеәҰжӣҙеӨ§пјҢеҶҚз»“еҗҲдҪңдёәйқһзәҝжҖ§жү©е……зҡ„вҖңеҶ…ж ёжҠҖе·§вҖқпјҲkernel trickпјүпјҢж”ҜжҢҒеҗ‘йҮҸжңәз®—жі•е°ұжҲҗдәҶжңәеҷЁеӯҰд№ дёӯзҡ„йҮҚиҰҒж”ҜжҹұгҖӮ
вҖңжңәеҷЁеӯҰд№ дёӯж„ҹзҹҘеҷЁжҳҜжҖҺд№Ҳдә§з”ҹзҡ„вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ