您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“Python网络爬虫举例分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python网络爬虫举例分析”吧!
先来看一段简单的代码。
import requests #导入requests包 url = 'https://www.cnblogs.com/LexMoon/' strhtml = requests.get(url) #get方式获取网页数据 print(strhtml.text)
首先是import requests来导入网络请求相关的包,然后定义一个字符串url也就是目标网页,之后我们就要用导入的requests包来请求这个网页的内容。
这里用了requests.get(url),这个get并不是拿取的那个get,而是一种关于网络请求的方法。
网络请求的方法有很多,最常见的有get,post,其它如put,delete你几乎不会见到。
requests.get(url)就是向url这个网页发送get请求(request),然后会返回一个结果,也就是这次请求的响应信息。
响应信息中分为响应头和响应内容。
响应头就是你这次访问是不是成功了,返回给你的是什么类型的数据,还有很多一些。
响应内容中就是你获得的网页源码了。
好了,这样你就算是入门Python爬虫了,但是还是有很多问题。
1. get和post请求有什么区别?
2. 为什么有些网页我爬取到了,里面却没有我想要的数据?
3. 为什么有些网站我爬下来的内容和我真实看到的网站内容不一样?
get和post请求有什么区别?
get和post的区别主要在于参数的位置,比如说有一个需要登录用户的网站,当我们点击登录之后,账号密码应该放在哪里。
get请求最直观的体现就是请求的参数就放在了URL中。
比如说你百度Python这个关键字,就可以发现它的URL如下:
https://www.baidu.com/s?wd=Python&rsv_spt=1
这里面的dw=Python就是参数之一了,get请求的参数用?开始,用&分隔。
如果我们需要输入密码的网站用了get请求,我们的个人信息不是很容易暴露吗,所以就需要post请求了。
在post请求中,参数会放在请求体内。
比如说下面是我登录W3C网站时的请求,可以看到Request Method是post方式。
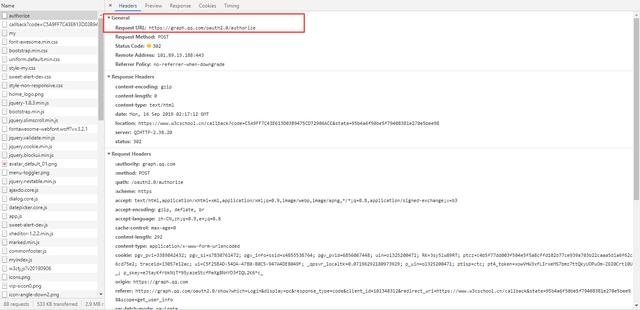
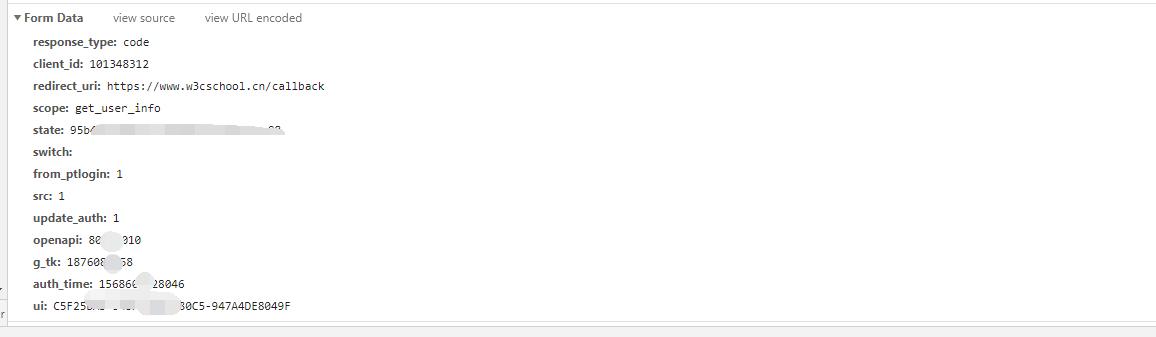
在请求的下面还有我们发送的登录信息,里面就是加密过后的账号密码,发送给对方服务器来检验的。
为什么有些网页我爬取到了,里面却没有我想要的数据?
我们的爬虫有时候可能爬下来一个网站,在查看里面数据的时候会发现,爬下来的是目标网页,但是里面我们想要的数据却没有。
这个问题大多数发生在目标数据是那些列表型的网页,比如说前几天班上一个同学问了我一个问题,他在爬携程的航班信息时,爬下来的网页除了获得不了航班的信息,其他地方都可以拿到。
如下图:
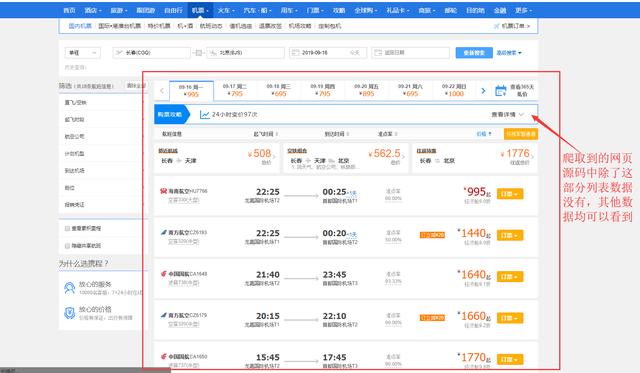
这是一个很常见的问题,因为他requests.get的时候,是去get的上面我放的那个URL地址,但是这个网页虽然是这个地址,但是他里面的数据却不是这个地址。
听起来很像很难,但是从携程这个网站的设计人的角度来说,加载的这部分航班列表信息可能很庞大,如果你是直接放在这个网页里面,我们用户打开这个网页可能需要很久,以至于认为网页挂了然后关闭,所以设计者在这个URL请求中只放了主体框架,让用户很快进入网页中,而主要的航班数据则是之后再加载,这样用户就不会因为等待很长时间而退出了。
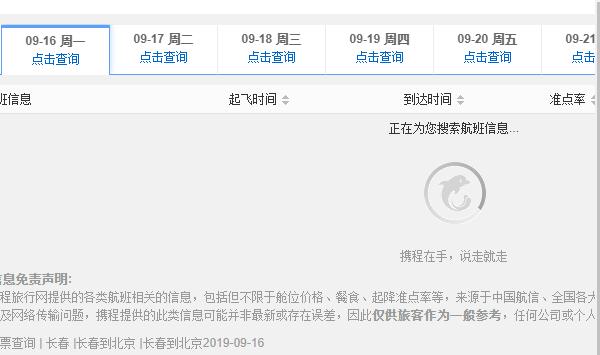
说到底怎么做是为了用户体验,那么我们应该怎么解决这个问题呢?
如果你学过前端,你应该知道Ajax异步请求,不知道也没事,毕竟我们这里不是在说前端技术。
我们只需要知道我们最开始请求的https://flights.ctrip.com/itinerary/oneway/cgq-bjs?date=2019-09-14这个网页中有一段js脚本,在这个网页请求到之后会去执行,而这段脚本的目的就是去请求我们要爬的航班信息。
这时候我们可以打开浏览器的控制台,推荐使用谷歌或者火狐浏览器,按F进入坦克,不,按F12进入浏览器控制台,然后点击NetWork。
在这里我们就可以看到这个网页中发生的所有网络请求和响应了。
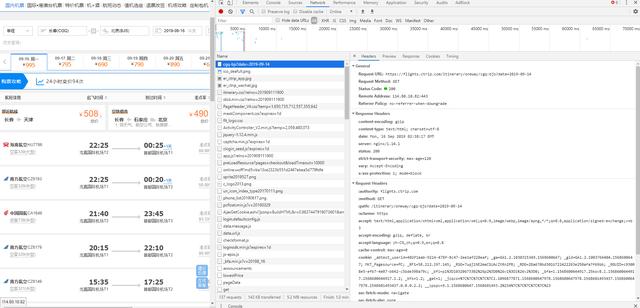
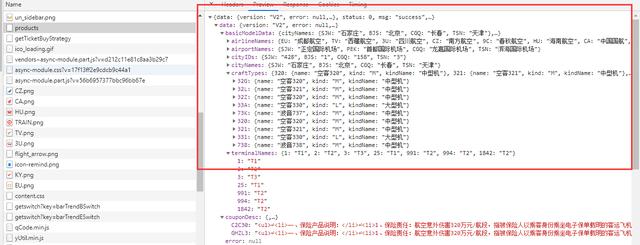
在这里面我们可以找到请求航班信息的其实是https://flights.ctrip.com/itinerary/api/12808/products这个URL。
为什么有些网站我爬下来的内容和我真实看到的网站内容不一样?
最后一个问题就是为什么有些网站我爬下来的内容和我真实看到的网站内容不一样?
这个的主要原因是,你的爬虫没有登录。
就像我们平常浏览网页,有些信息需要登录才能访问,爬虫也是如此。
这就涉及到了一个很重要的概念,我们的平常观看网页是基于Http请求的,而Http是一种无状态的请求。
什么是无状态? 你可以理解为它不认人,也就是说你的请求到了对方服务器那里,对方服务器是不知道你到底是谁。
既然如此,我们登录之后为什么还可以长时间继续访问这个网页呢?
这是因为Http虽然是无状态的,但是对方服务器却给我们安排了身份证,也就是cookie。
在我们第一次进入这个网页时,如果之前没有访问过,服务器就会给我们一个cookie,之后我们在这个网页上的任何请求操作,都要把cookie放进去。这样服务器就可以根据cookie来辨识我们是谁了。
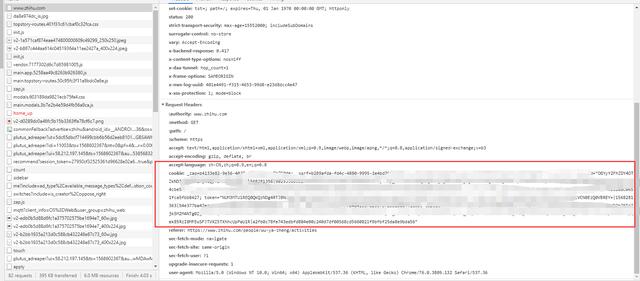
比如知乎里面就可以找到相关的cookie。
对于这类网站,我们直接从浏览器中拿到已有的cookie放进代码中使用,requests.get(url,cookies="aidnwinfawinf"),也可以让爬虫去模拟登录这个网站来拿到cookie。
感谢各位的阅读,以上就是“Python网络爬虫举例分析”的内容了,经过本文的学习后,相信大家对Python网络爬虫举例分析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。