您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“如何搭建Hadoop的环境”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何搭建Hadoop的环境”吧!
说明:这里我们以本地模式和伪分布模式伪列,为大家介绍如何搭建Hadoop环境。有了这个基础,大家可以自行搭建Hadoop的全分布模式。
需要使用的安装介质:
hadoop-2.7.3.tar.gz
jdk-8u181-linux-x64.tar.gz
rhel-server-7.4-x86_64-dvd.iso
安装好Redhat Linux 7.4(安装包rhel-server-7.4-x86_64-dvd.iso),并在Linux上创建tools和training两个目录

关闭防火墙,执行下面的命令
1 2 | systemctl stop firewalld.servicesystemctl disable firewalld.service |
配置主机名,使用vi编辑器编辑文件/etc/hosts,输入以下内容
1 | bigdata111 192.168.157.111 |
配置免密码登录,在命令行中输入下面的命令
1 2 | ssh-keygen -t rsassh-copy-id -i .ssh/id_rsa.pub root@bigdata111 |
通过FTP工具将jdk-8u181-linux-x64.tar.gz和hadoop-2.7.3.tar.gz上传到Linux的/root/tools目录
在xshell中,解压jdk-8u181-linux-x64.tar.gz,执行下面的命令
1 | tar -zxvf jdk-8u181-linux-x64.tar.gz -C /root/training/ |
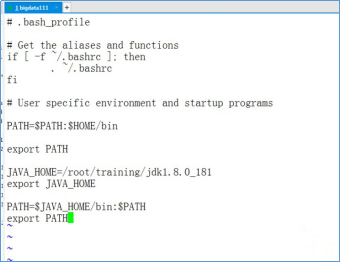
设置Java的环境变量,使用vi编辑器编辑~/.bash_profile文件。执行下面的命令
1 | vi /root/.bash_profile |
在vi编辑器中,输入以下内容
1 2 3 4 5 | JAVA_HOME=/root/training/jdk1.8.0_181export JAVA_HOMEPATH=$JAVA_HOME/bin:$PATHexport PATH |
生效环境变量,执行下面的命令
1 | source /root/.bash_profile |

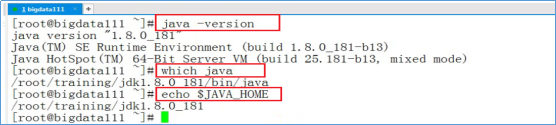
输入下图中,红框中的命令验证Java环境
执行下面的命令,解压hadoop-2.7.3.tar.gz
1 | tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/ |
设置Hadoop的环境变量,编辑~/.bash_profile文件,并输入以下内容
1 2 3 4 5 | HADOOP_HOME=/root/training/hadoop-2.7.3export HADOOP_HOMEPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport PATH |

生效环境变量
1 | source ~/.bash_profile |
进入目录/root/training/hadoop-2.7.3/etc/hadoop
使用vi编辑器编辑文件:hadoop-env.sh
修改JAVA_HOME
1 | export JAVA_HOME=/root/training/jdk1.8.0_181 |

测试Hadoop的本地模式,执行MapReduce程序。准备测试数据:vi ~/temp/data.txt
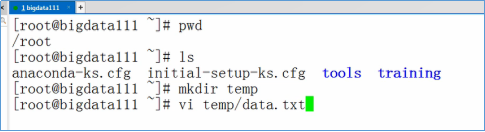
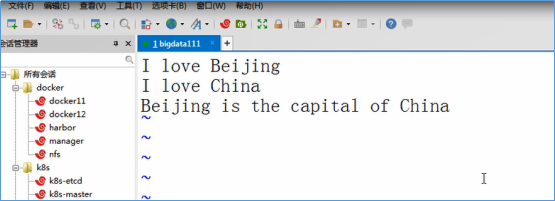
输入下面的数据,并保存退出
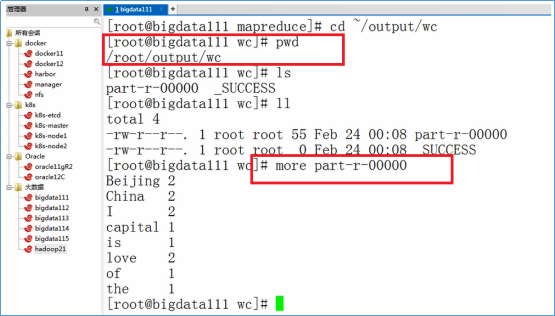
进入目录:/root/training/hadoop-2.7.3/share/hadoop/mapreduce

执行WordCount任务
1 | hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /root/temp /root/output/wc |
根据下图的命令,查看输出结果
首先,搭建好Hadoop的本地模式
创建目录:/root/training/hadoop-2.7.3/tmp
1 | mkdir /root/training/hadoop-2.7.3/tmp |
进入目录:/root/training/hadoop-2.7.3/etc/hadoop
1 | cd /root/training/hadoop-2.7.3/etc/hadoop |
修改hdfs-site.xml
1 2 3 4 | <property> <name>dfs.replication</name> <value>1</value></property> |
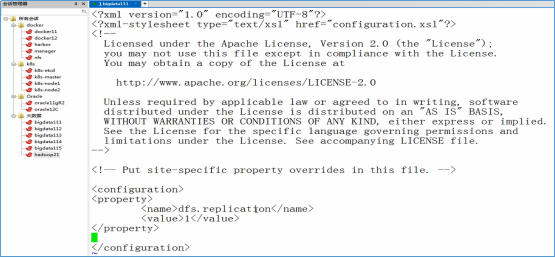
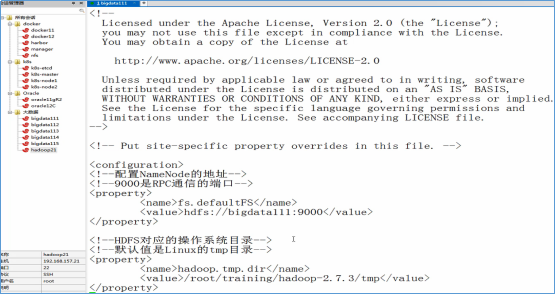
修改core-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 | <!--配置NameNode的地址--><!--9000是RPC通信的端口--><property> <name>fs.defaultFS</name> <value>hdfs://bigdata111:9000</value></property><!--HDFS对应的操作系统目录--><!--默认值是Linux的tmp目录--><property> <name>hadoop.tmp.dir</name> <value>/root/training/hadoop-2.7.3/tmp</value></property> |
修改mapred-site.xml(注意:这个文件默认没有)
1 2 3 4 | <property> <name>mapreduce.framework.name</name> <value>yarn</value></property> |
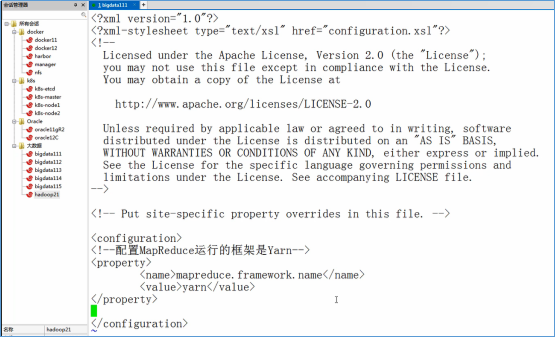
修改yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 | <!--配置ResourceManager的地址--><property> <name>yarn.resourcemanager.hostname</name> <value>bigdata111</value></property><!--MapReduce运行的方式是洗牌--><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property> |

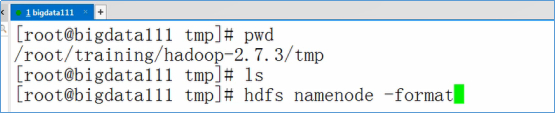
格式化NameNode
1 | hdfs namenode -format |
启动Hadoop
1 | start-all.sh |

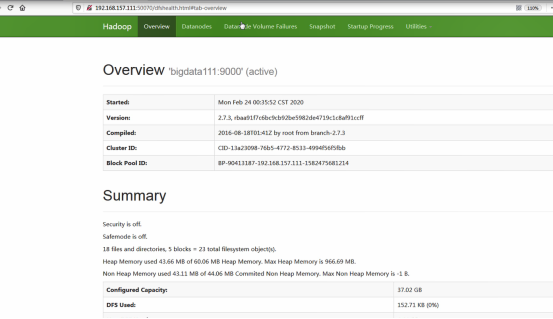
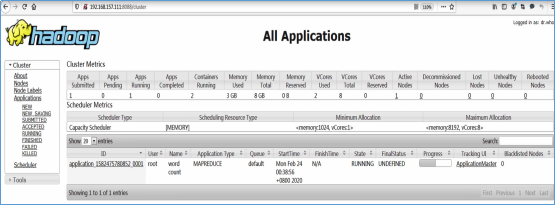
访问Web Console
1 2 | http://192.168.157.111:50070http://192.168.157.111:8088 |
到此,相信大家对“如何搭建Hadoop的环境”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。