жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
PythonеӯҰд№ ж•ҷзЁӢпјҡжҲҗиҜӯжҹҘиҜўе·Ҙе…· - ж•°жҚ®иҺ·еҸ–
жҲ‘们д»ҺиҝҷдёӘзҪ‘з«ҷдёҠиҺ·еҸ–жғіиҰҒзҡ„еҶ…е®№пјҢдёҚз”ЁиҖғиҷ‘еӨӘеӨҡзҡ„жқҝеқ—пјҢзӣҙжҺҘжҢүз…§еӯ—жҜҚжЈҖзҙўеҚіеҸҜ
иҝӣеҺ»жҜҸдёӘеӯ—жҜҚзҡ„йЎөйқўдёӯиҺ·еҸ–ж•°жҚ®д»ҘеҸҠеҫӘзҺҜйЎөж•°пјҢеҖјеҫ—жіЁж„Ҹзҡ„жҳҜйЎөйқўдёӯжңүзӣёеҪ“еӨҡзҡ„йҮҚеӨҚйЎ№пјҢи®°еҫ—иҝӣиЎҢеҺ»йҮҚж“ҚдҪң
常规еҘ—и·ҜпјҢеӣ дёәиҝҷйҮҢйңҖиҰҒз”ЁеҲ°xpathпјҢжүҖд»ҘзӣҙжҺҘиҝ”еӣһhtmlеӯ—з¬ҰдёІпјҢиҝҷйҮҢеӣ дёәж•°жҚ®дёӯжңүеӨ§йҮҸдёӯж–Үз№ҒдҪ“еӯ—зҡ„еҺҹеӣ пјҢйҖүжӢ©еӯ—з¬Ұзј–з Ғдёәgbk
def get_html(url): r = requests.get(url, headers=headers) r.encoding = 'gbk' return r.text
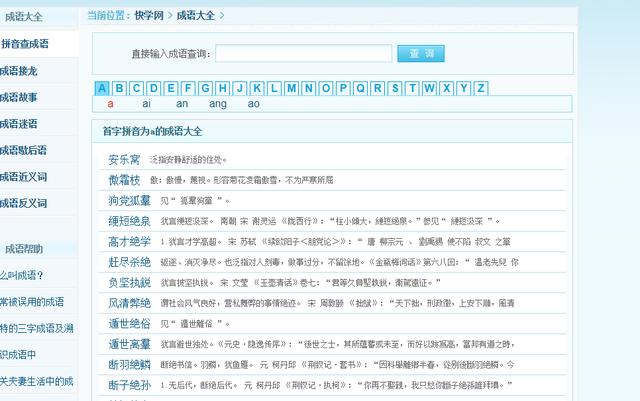
йЎөйқўдёӯзҡ„жҲҗиҜӯд»ҘеҸҠйҮҠд№үйғҪжҳҜдҝқеӯҳеңЁеҲ—иЎЁдёӯзҡ„пјҢзӣҙжҺҘеҜ№еҲ—иЎЁйҒҚеҺҶиҺ·еҸ–еҚіеҸҜ(д»…еҪ“еүҚйЎө)пјҢеҖјеҫ—жіЁж„Ҹзҡ„жҳҜйңҖиҰҒеҜ№йҮҚеӨҚйЎ№жё…жҙ—пјҢиҝҷйҮҢдҪҝз”ЁеҢҝеҗҚеҮҪж•°lambda z: dict([(x, y) for y, x in z.items()]),еҜ№еӯ—е…ёзҡ„й”®еҖјжү§иЎҢдёӨж¬Ўзҝ»иҪ¬
def get_curr(url):
html = etree.HTML(get_html(url))
lis = html.xpath('//li[@class="licontent"]')
context = {}
for li in lis:
if li.xpath('./span[@class="hz"]/a/text()') and li.xpath('./span[@class="js"]/text()'):
idiom = li.xpath('./span[@class="hz"]/a/text()')[0]
interpretation = li.xpath('./span[@class="js"]/text()')[0]
context[idiom] = interpretation
func = lambda z: dict([(x, y) for y, x in z.items()])
idiom_dict = func(func(context))
return idiom_dict
йЎөйқўеә•йғЁжңүйЎөж•°зҡ„ж ҮзӯҫпјҢеҢ…жӢ¬жҖ»йЎөж•°гҖҒеҪ“еүҚйЎөгҖҒжң«йЎөгҖҒдёӢдёҖйЎөзӯүпјҢдҪҶжҳҜеҰӮжһңжҖ»йЎөйқўд»…1йЎөзҡ„е°ұжІЎжңүд»»дҪ•жҳҫзӨәпјҢеҲ°иҫҫйЎ№зӣ®е°ҫйЎөж—¶е°ұжІЎжңүд»»дҪ•йЎөж•°ж ҮзӯҫжҳҫзӨәдәҶ(жҖӘдёҚжҖӘ?),жҲ‘们иҝҷйҮҢе°ұиҺ·еҸ–еҲ°жҖ»йЎөж•°е’ҢеҪ“еүҚзҡ„еӯ—жҜҚзҙўеј•еҚіеҸҜпјҢиҝҷйҮҢзҡ„write_dataе’ҢprintжҳҜдёәдәҶжҹҘзңӢдёҖдёӢжҜҸдёӘеӯ—жҜҚзҙўеј•зҡ„ж•°жҚ®жғ…еҶөпјҢеӣ дёәжңҖеҗҺзҡ„жү§иЎҢдјҡе°Ҷж•°жҚ®еҶҷе…ҘдёҖдёӘеҚ•зӢ¬зҡ„ж–Ү件пјҢеҰӮжһңдҪ жғіиҰҒзңӢеҲ°жҜҸдёӘеӯ—жҜҚзҡ„жҲҗиҜӯпјҢе°ұеҸҜд»ҘеҸ–ж¶ҲиҝҷйҮҢзҡ„жіЁйҮҠжҹҘзңӢ
def run(url, context):
html = etree.HTML(get_html(url))
if html.xpath('//a[contains(text(), "жң«йЎө")]/@href'):
text = html.xpath('//a[contains(text(), "жң«йЎө")]/@href')[0]
letter = re.search('\w', text).group(0) or url.split('/')[-1][0]
total = re.search('\d+', text).group(0) or 1
else:
letter = url.split('/')[-1][0]
total = 1
for num in range(1, int(total) + 1):
page_context = get_curr('http://chengyu.kxue.com/pinyin/' + letter + '_' + str(num) + '.html')
context.update(page_context)
print("е®ҢжҲҗ{}зҡ„ж·»еҠ ,е…ұ{}".format(letter + '_' + str(num), total))
#write_data('grandSon/' + url.split('/')[-1][0] + '.json', context)
#print("е®ҢжҲҗ{}зҡ„еҶҷе…Ҙ".format(url.split('/')[-1][0]))
return context
зӣҙжҺҘиҪ¬жҲҗjsonеҶҷе…Ҙж–Ү件пјҢеҸҜд»Ҙи°ғж•ҙдёҖдёӢж јејҸ
def write_data(file, context): with open(file, 'w', encoding='utf-8') as f: f.write(json.dumps(context, indent=2, ensure_ascii=False))
еҺ»зҪ‘йЎөдё»йЎөйҒҚеҺҶжүҖжңүеӯ—жҜҚзҡ„й“ҫжҺҘпјҢ然еҗҺеҜ№жҜҸдёӘй“ҫжҺҘи°ғз”Ёд»ҘдёҠж–№жі•еҚіеҸҜ
url = "http://chengyu.kxue.com/"
html = etree.HTML(get_html(url))
file = 'idiom.json'
context = {}
urls = html.xpath('//div[@class="content letter"]/li/a/@href')
for url in urls:
context.update(run("http://chengyu.kxue.com" + url, {}))
write_data(file, context)
дјҷдјҙ们жңүдёҚжё…жҘҡзҡ„ең°ж–№пјҢеҸҜд»Ҙз•ҷиЁҖпјҢжӣҙеӨҡзҡ„е…ідәҺ Pythonе®һжҲҳе’ҢеӯҰд№ ж•ҷзЁӢд№ҹдјҡ继з»ӯдёәеӨ§е®¶жӣҙж–°пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ