жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңASCIIгҖҒUnicodeгҖҒUTF-8зј–з Ғй—®йўҳе®һдҫӢеҲҶжһҗвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
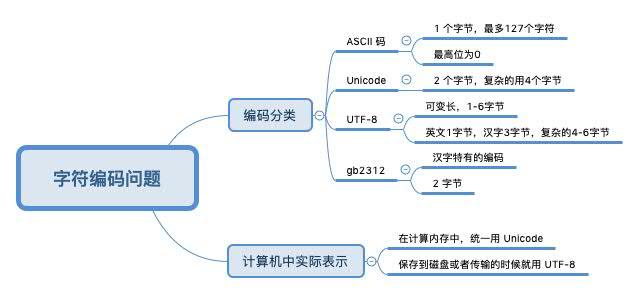
д»ҘеҫҖжҲ‘们еҸҜиғҪдәҶи§Јзҡ„йғҪжҳҜдёҖдәӣзҗҶи®әзҹҘйҒ“пјҢдёӢйқўжҲ‘们жқҘйҖҡиҝҮ Python3 жқҘйӘҢиҜҒдёҖдёӢгҖӮеҲҶеҲ«жқҘзңӢзңӢиӢұж–Үеӯ—з¬Ұ вҖҳAвҖҷ е’Ң вҖҳдёӯвҖҷ еҲҶеҲ«еңЁдёҚеҗҢзј–з ҒдёӢзҡ„е®һйҷ…жғ…еҶөгҖӮ
A зҡ„ ASCII гҖҒUTF-8гҖҒGB2312 зј–з Ғ
>>> 'A'.encode('ascii')
b'A'
>>> 'A'.encode('utf-8')
b'A'
>>> 'A'.encode('gb2312')
b'A'дёӯзҡ„ ASCII гҖҒUTF-8гҖҒGB2312 зј–з Ғ
>>> 'дёӯ'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\\u4e2d' in position 0: ordinal not in range(128)
>>> 'дёӯ'.encode('utf-8')
b'\\xe4\\xb8\\xad'
>>> 'дёӯ'.encode('gb2312')
b'\\xd6\\xd0'еҸҜд»ҘзңӢеҲ°дёӯж–ҮжҳҜдёҚиғҪиҝӣиЎҢ ASCII зј–з Ғзҡ„
вҖңASCIIгҖҒUnicodeгҖҒUTF-8зј–з Ғй—®йўҳе®һдҫӢеҲҶжһҗвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ