您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家介绍python中怎么推导线性回归模型,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
首先,先看一张图:
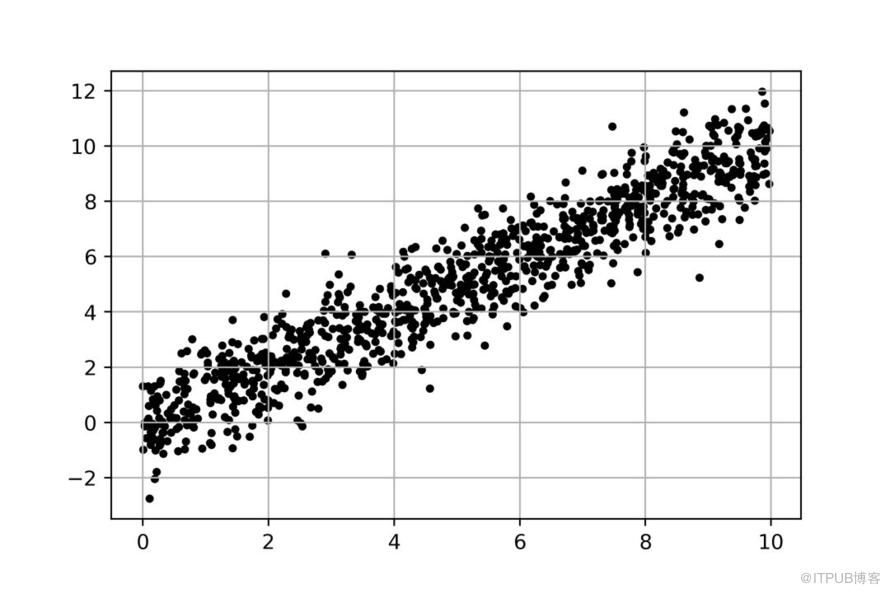
图是我们在初中学习过的直角坐标系二维平面,上面遍布着一些点。从整体趋势看,y随x的增大而增大。如果曾经你和我一样,数学每次考试都是90的话,那么接下来,我相信你会情不自禁地做一件事:
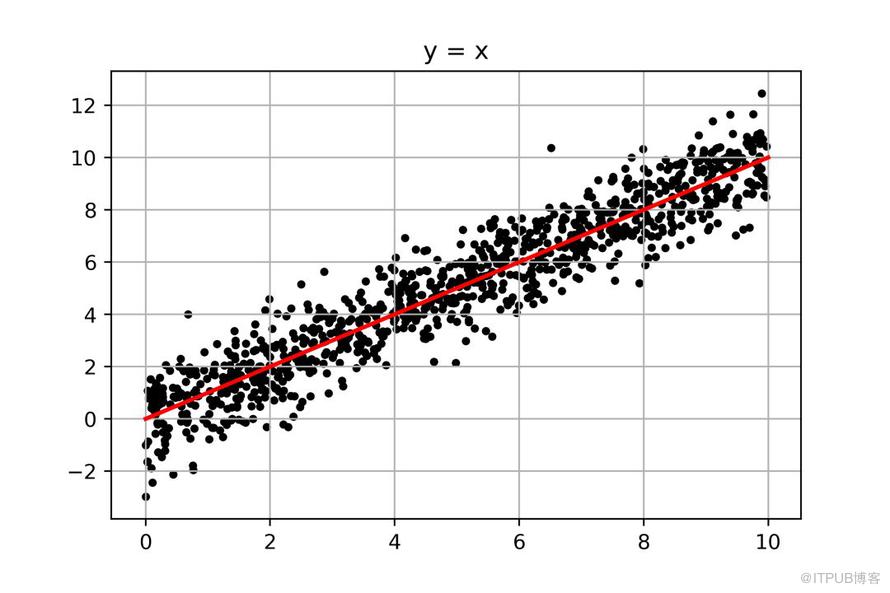
没错,我们会以(0,0)和(10,10)为两点,画出一条贯穿其中的线,从视觉上,这条红线正好把所有点一分为二,其对应的数学表达式为:
y=x
而这就是我们线性回归所要做的事:找到一组数学表达式(图中的红线),用来反映数据(图中的点)的变化规律。
目标有了,问题也来了:
贯穿图中密密麻麻点的线有无数条,为什么不是y=2x,y=x+1,偏偏是y=x呢?
我们又是通过何种方法去找到这条线呢?
先解决第一个问题,上天书:
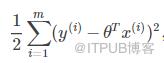
这个式子就是第一个问题的解,没见过的符号太多,看不懂是吧?那么我来翻译一下:
先求出(每个点的Y值-以每个点的X值通过函数求出的Y值)的平方
求和;
乘以1/2
再通俗点:
把每个点的实际y值与它通过某个函数求出的y值的差的平方加起来,再乘以1/2。
而文章开篇中的均方差损失,MSE,平方损失函数,二次代价函数其实都指的是它。这个式子其实计算的是真实值和用函数预测的值之间的误差之和。那么第一个问题就迎刃而解了:哪一个表达式所求出的误差和最小,就是我们要找的那条“红线”。
我们继续解决第二个问题,先上图:
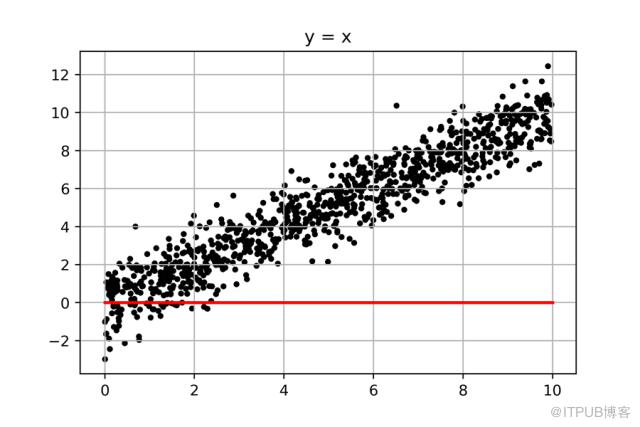
这个问题还要简单,我们只要从斜率为0的那条“红线”(y=0*X)开始画线,然后一点点增大斜率,每条线求一个误差值,找出其中误差值最小的那条线,就大功告成了。而中间有着巨大计算量的遍历过程,我们可以通过python,瞬间完成。
————————
线性回归的Python实现
————————
重点:梯度下降法!
导入一些包,待用:
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context('notebook')
sns.set_style('white')
导入案例数据:
model_data = pd.read_csv('model_data.csv',engine='python')
model_data.head()
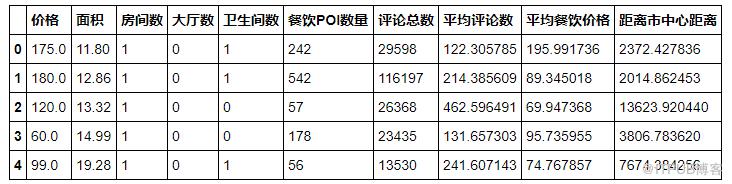
数据是一份上海的房价数据,我们要把房屋价格作为因变量y,房屋面积,房间数附近餐饮POI数量,评论,距离市中心距离等作为自变量,拟合一个线性回归模型,用于预测房价。
根据要求提取自变量和因变量:
feat_cols = model_data.columns.tolist()[1:]
print(feat_cols)
X = model_data[feat_cols].values
y = model_data['价格'].values
构建损失函数:
def Cost_Function(X,y,theta):
'''
需要传入的参数为
X:自变量
y:应变量
theta:权重
使用均方误差(MSE),作为损失函数
'''
m = y.size #求出y的个数(一共多少条数据)
t = X.dot(theta) #权重和变量点乘,计算出使用当前权重时的预测值
c = 0 #定义损失值
c = 1/(2*m) * (np.sum(np.square(t-y)))
#预测值与实际值的差值,平方后除以数据的条数,计算出均方误差。最后乘以1/2(无实际意义,方便以后计算)
return c #返回损失值
*θ为每个变量前的权重,什么是权重?比如y=2x,2就是自变量x的权重
求损失值我们就用先前说到的损失函数。如果你够仔细,可能会有一个问题,我们的损失函数前需要乘以一个1/2,似乎没有特别的意义。恭喜你很机智,1/2的确没有任何意义,只是为了接下来方便求导。
构建梯度下降法:
def GradientDescent(X, y, feat_cols, alpha=0.3, num_iters=10000):
'''
需传入参数为
X:自变量
y:应变量
feat_cols:变量列表
alpha:学习率,默认0.3
num_iters:迭代次数,默认10000次
使用梯度下降法迭代权重
'''
scaler = MinMaxScaler() #最大最小值归一化自变量
X = scaler.fit_transform(X) #归一化
m = y.size #求出y的个数(一共多少条数据)
J_history = np.zeros(num_iters) #创建容纳每次迭代后损失值得矩阵,初始值为0
theta = np.zeros(len(feat_cols)+1) #设置默认权重,0
for iter in np.arange(num_iters): #根据迭代次数,开始迭代
t = X.dot(theta) #权重和变量点乘,计算出使用当前权重时的预测值
theta = theta - alpha*(1/m)*(X.T.dot(t-y))
#对代价函数求导,算出下降最快的方向,乘以学习率(下降的速度),再用原来的权重相减,得到新的权重
J_history[iter] = Cost_Function(X, y, theta) #求出新的权重时的损失值,存入矩阵
return(theta, J_history) #返回最终的权重和历次迭代的损失值
这是构造模型最为核心的部分。我们不断迭代,寻找最优的那条“红线”的过程,其实是在不断调整每个自变量的权重。而每个权重每次到底怎么调整,增大还是减小(方向),这就需要我们对损失函数求导。
如果数学不好,不理解,我们用图来说明一下:
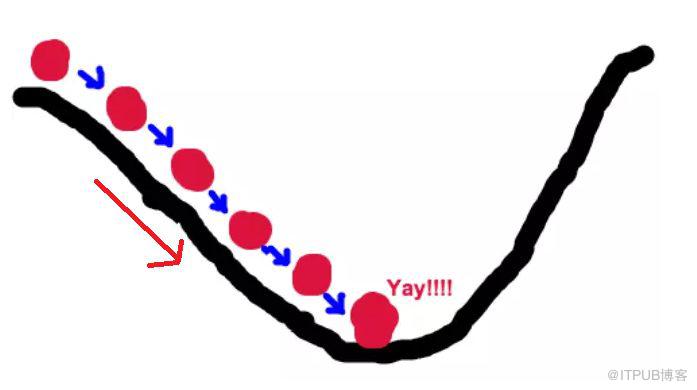
好比,我们站在悬崖顶端,要找到最快能达到悬崖底部的方向,那么显而易见,你所在位置最陡峭的方向,就是正确的方向,而求导就是找到最陡峭的方向(切线斜率绝对值最大的点)。
山坡是凹凸不平的,所以我们每走一步都需要重新寻找方向,这就是迭代的过程;其次,每次的步子也不能跨太大,万一跨错地方了,不好纠正,所以我们又需要设置一个步子的大小——学习率。
所以梯度下降法的公式就是:
每一次更新的权重= 前一次的权重-学习率*损失函数的导数。
在理解了下山这个场景以后,我们就能顺利的完成梯度下降法的构建,并且通过python函数求出最后每个变量的权重和每次迭代过后的损失值。
构建绘制损失值变化图的函数:
def plot_Cost(GD_result):
'''
绘制权重变化情况
需传入参数为
GD_result:梯度下降法结果
'''
theta , Cost = GD_result #得到权重和损失值
print('theta: ',theta.ravel()) #打印权重
plt.plot(Cost) #绘制损失值变化情况
plt.title('COST change')
plt.ylabel('Cost')
plt.xlabel('Iterations')
plt.grid()
plt.show()
这个很简单,就是通过前面梯度下降法求得的历次迭代后的损失值,画出变化曲线。
最后把所有函数汇总,就是我们的线性回归模型了:
def lr_function(X,y,feat_cols):
'''
需要输入的变量为
X:自变量
y:应变量
feat_cols:变量列表
'''
def score(y_p,y):
'''
y_p:预测值
y:真实值
dimension:样本数量
计算R^和调整R^
'''
aa=y_p.copy(); bb=y.copy()
if len(aa)!=len(bb):
print('not same length')
return np.nan
cc=aa-bb
wcpfh=sum(cc**2) #误差平方和
# RR means R_Square
RR=1-sum((bb-aa)**2)/sum((bb-np.mean(bb))**2)
return RR#返回R^
X = np.c_[np.ones(X.shape[0]),X]
GD_result = GradientDescent(X, y, feat_cols)
plot_Cost(GD_result)
y_p = np.dot(X,GD_result[0])
RR = score(y_p,y)
return RR,y_p,GD_result[0] #返回R^,预测值
一般对于每个机器学习模型,都需要有一个指标衡量其拟合程度,而线性模型我们使用的是我们所熟知的可决系数R^2。为了求出R^2,我在函数中又套用了一个简单的求解函数,具体过程不赘述了,通读代码就能明白。通常R^2越接近1,表示模型拟合程度越好。
模型封装完毕,下面是见证奇迹的时刻!
model_result = lr_function(X,y,feat_cols)
print('R^2为:{}'.format(round(model_result[0],4)))
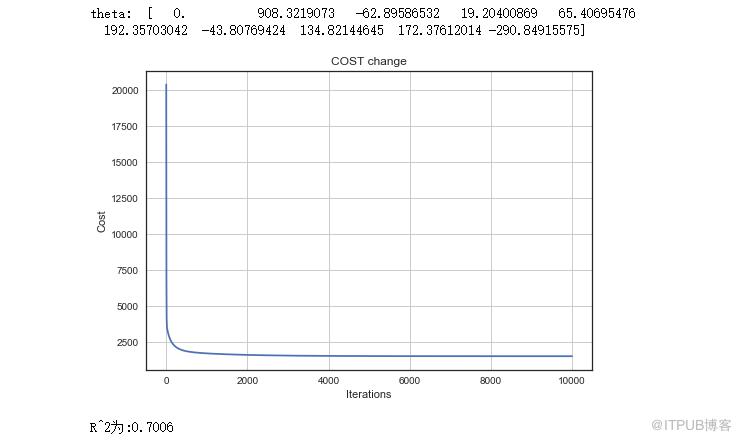
通过模型,我们求出了每个自变量的权重,图表反应了损失值由大变小的过程,在10000次迭代的过程中,一开始速度很快,越到后面越趋于平缓。
最后是R^2为0.70,有70%的拟合度,尚可。
————————
线性回归模型的验证
————————
为了验证我们自己编写的模型是否准确,我们也可以使用python机器学习工具包sklearn,对同样的数据,用线性回归模型拟合,查看最后的R^2是否一致。
先对变量标准化:
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
使用LinearRegression()进行拟合,并求出R^2:
lr = LinearRegression()
lr.fit(X,y)
R2 = lr.score(X,y)
print('R^2为:{}'.format(round(R2,4)))
R^2同样为0.7,代表我们自己编写的模型没有问题。
最后,我们绘制一张真实值与预测值对比图,可视化模型结果:
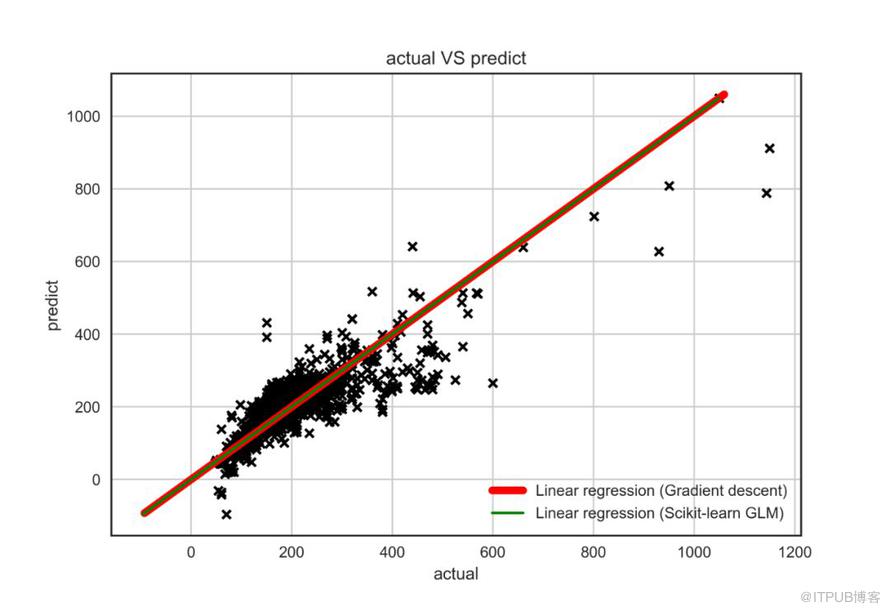
关于python中怎么推导线性回归模型就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。