жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚжҖҺд№ҲзҗҶи§Јsparkзҡ„и®Ўз®—еҷЁдёҺе№ҝж’ӯеҸҳйҮҸпјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ

и®Ўж•°еҷЁеҸӘж”ҜжҢҒеҠ пјҢи®Ўз®—еҷЁеӯ—taskйҮҢйқў

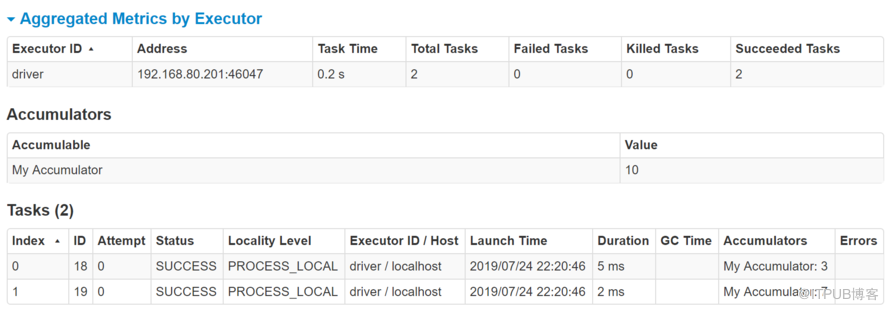
ж•°жҚ®еҫҲеӨҡжңүзҡ„ж•°жҚ®жҢӮдәҶпјҢеҒҡж•°жҚ®иҙЁйҮҸзӣ‘жҺ§з”Ё
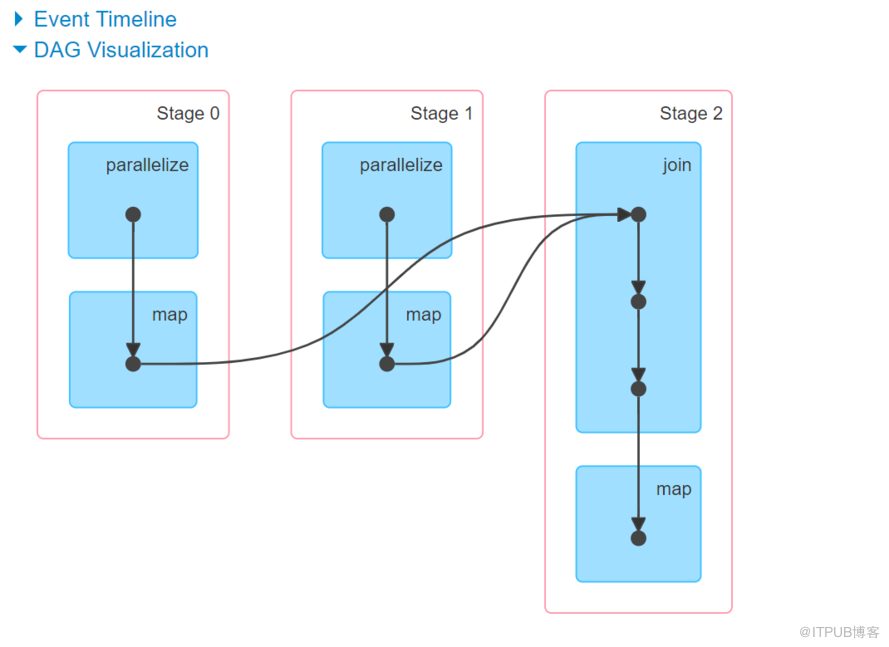
def commonJoin(sc:SparkContext): Unit = {
val peopleInfo = sc.parallelize(Array(("G301","зіҠж¶Ӯиҷ«"),("G302","жЈ®иҖҒ"),("G303","Gordon"))).map(x=>(x._1, x))
val peopleDetail = sc.parallelize(Array(("G301","жё…еҚҺеӨ§еӯҰ",18))).map(x=>(x._1,x))
// TODO... еӨ§иЎЁе…іиҒ”е°ҸиЎЁ join key from a join b on a.id=b.id
peopleInfo.join(peopleDetail).map(x=>{x._1 + "," + x._2._1._2 + "," + x._2._2._2+ "," + x._2._2._3})
}
е№ҝж’ӯеҸҳйҮҸзҡ„еүҚжҸҗжқЎд»¶жҳҜж•°жҚ®йҮҸе°‘пјҢдёҖеӨ§дёҖе°ҸпјҢдёҚиғҪи¶…иҝҮеҶ…еӯҳ ж•°жҚ®йҮҸеӨ§е°ҸиҝҳиҰҒзңӢеҶ…еӯҳпјҢдҪ еҶ…еӯҳеӨҹеӨ§е°ұеҸҜд»Ҙж”ҫ е№ҝж’ӯеҸҳйҮҸж”ҫеҲ°еҶ…еӯҳдёӯ
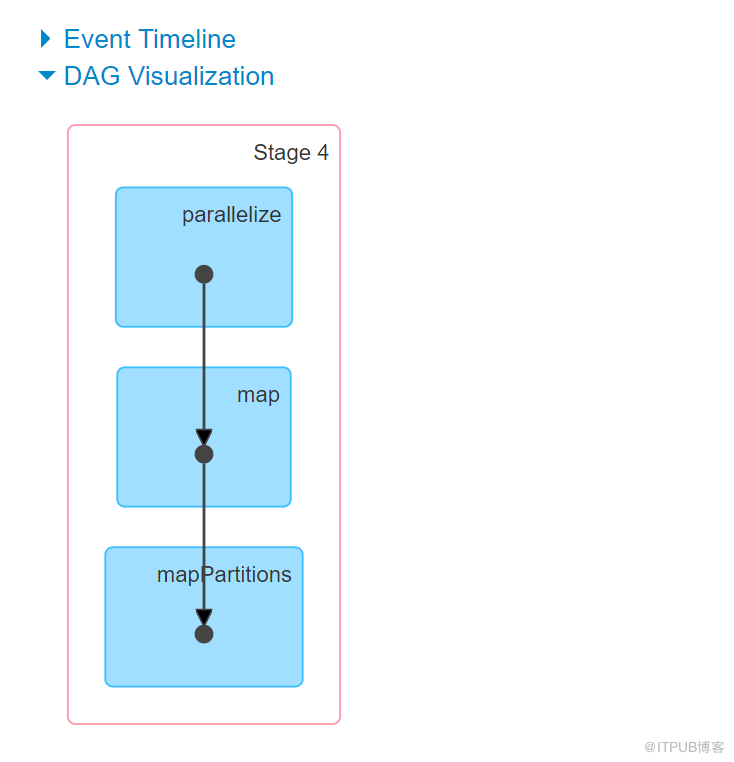
def broadcastJoin(sc:SparkContext): Unit = {
val peopleInfo = sc.parallelize(Array(("G301","зіҠж¶Ӯиҷ«"),("G302","жЈ®иҖҒ"),("G303","Gordon"))).collectAsMap()
val peopleDetail = sc.parallelize(Array(("G301","жё…еҚҺеӨ§еӯҰ",18))).map(x=>(x._1, x))
// йҖҡиҝҮscе°ҶеҸҳйҮҸе№ҝж’ӯеҮәеҺ»
val peopleBroadcast = sc.broadcast(peopleInfo)
// mappartition: еҸ–еҮәиЎЁдёӯзҡ„дёҖжқЎи®°еҪ•е’Ңе№ҝж’ӯеҸҳйҮҸдёӯзҡ„еҜ№жҜ”
peopleDetail.mapPartitions(x=>{
val map = peopleBroadcast.value // жҳҜдёҚжҳҜе°ұжҳҜеҶ…еӯҳзҡ„дёңиҘҝ
for((key,value)<-x if (map.contains(key)))
yield (key,map.get(key).getOrElse(""), value._2)
}).foreach(println)
}
е№ҝж’ӯеҸҳйҮҸзҡ„жІЎжңүдәҶshuffer жңүеүҚжҸҗж•°жҚ®йҮҸдёҚеҸҜд»ҘеӨҡ жҠҠе°ҸиЎЁе№ҝж’ӯеҲ°еҶ…еӯҳдёӯпјҢеӨ§иЎЁжҜҸдёӘж•°жҚ®дёҺе…¶еҜ№жҜ” жңүе°ұиҰҒпјҢжІЎжңүе°ұдёҚиҰҒгҖӮ е№ҝж’ӯеҸҳйҮҸдёҺjoinз»“еҗҲе·ҘдҪңдёӯеёёз”Ё
е…ідәҺжҖҺд№ҲзҗҶи§Јsparkзҡ„и®Ўз®—еҷЁдёҺе№ҝж’ӯеҸҳйҮҸе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ