您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“TextFile分区问题怎么理解”,在日常操作中,相信很多人在TextFile分区问题怎么理解问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”TextFile分区问题怎么理解”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
val rdd1 = sc.parallelize(List(2,3,4,1,7,5,6,9,8))
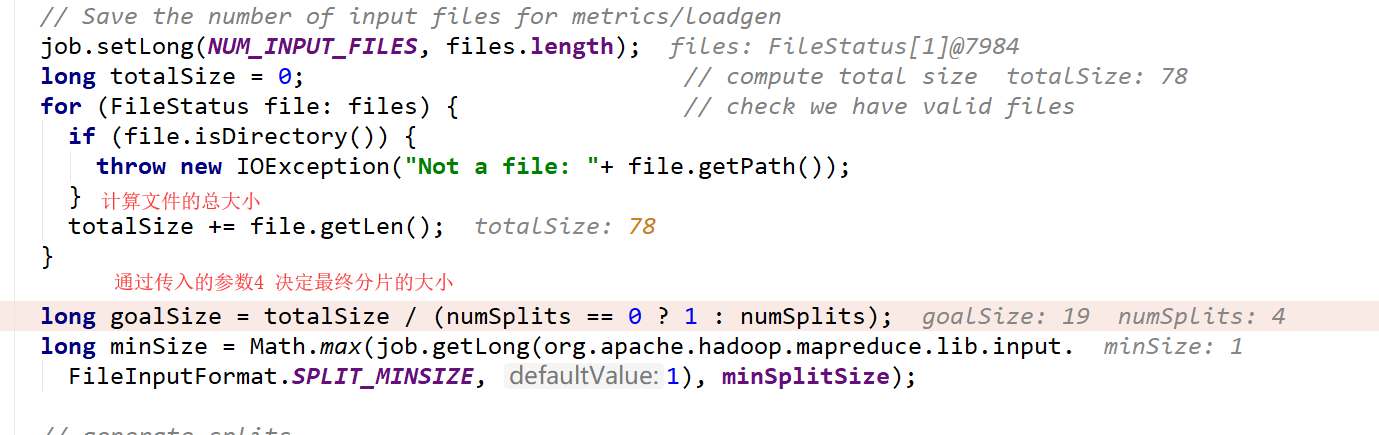
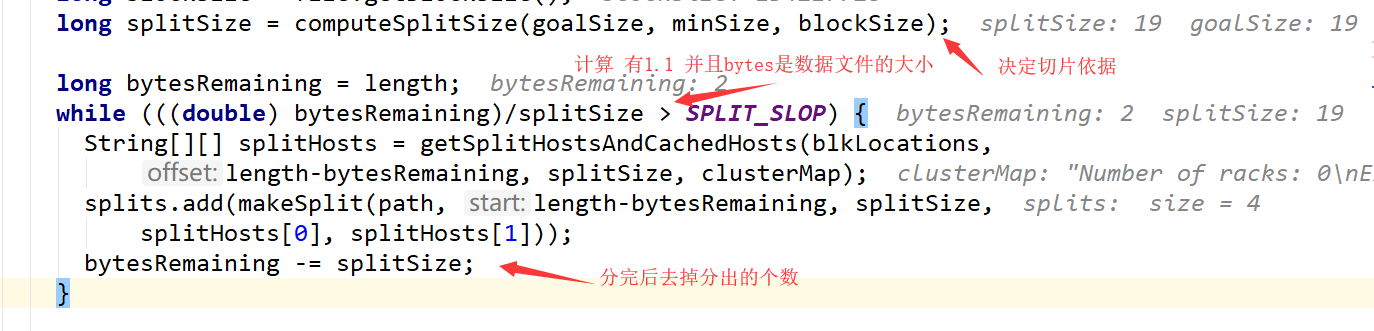
获取分区的个数:rdd1.partitions.length,在spark-shell中没有指定分区的个数获取的是默认分区数,除了这个外parallelize方法可以使用,指定几个分区就会有几个分区出现
val rdd1 = sc.textFile("hdfs://hadoop02:8020/word.txt",3).flatMap _.split('')).map((_,1)).reduceByKey(_+_)
textFile这个方法是有默认值就是2 除非改变loacl中的即默认值这个只要这个默认值小于2的话会使用小于默认的值
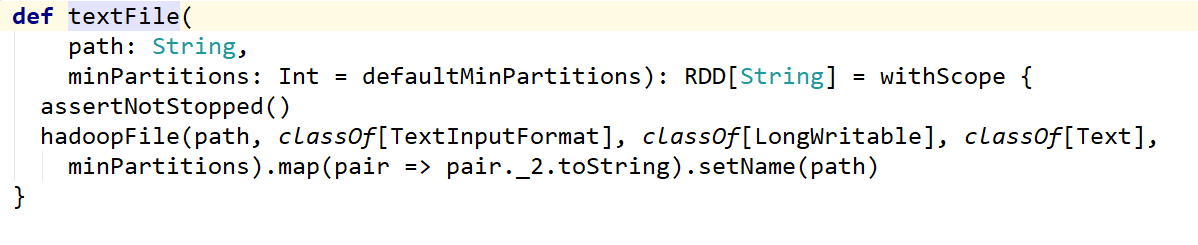
这个默认属性是有值的defaultMinPartitions

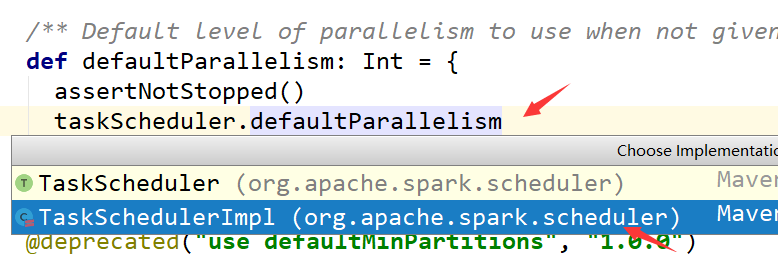


如果在textfile中传入了分区数,那么这个分区数可能相同也可能不同需要看底层计算!



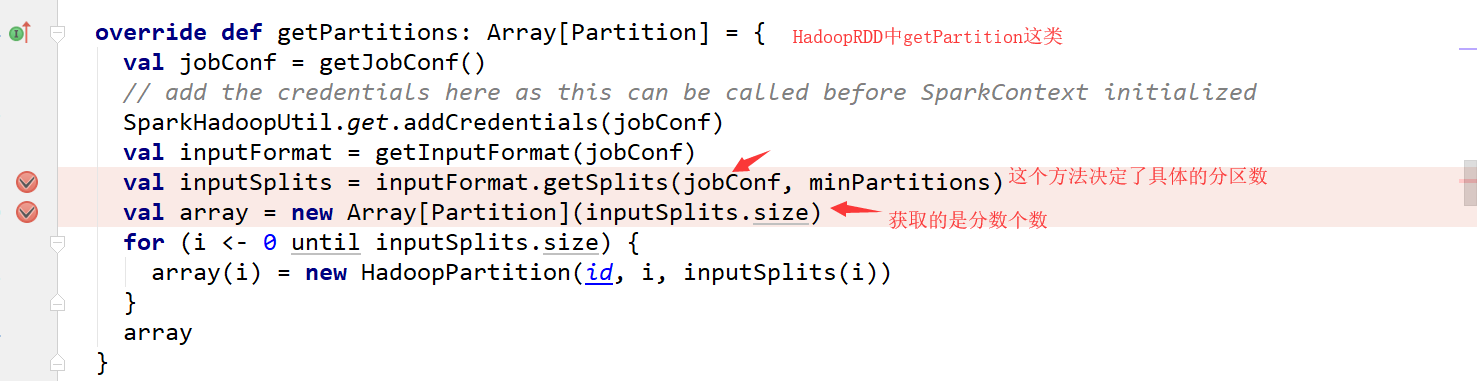
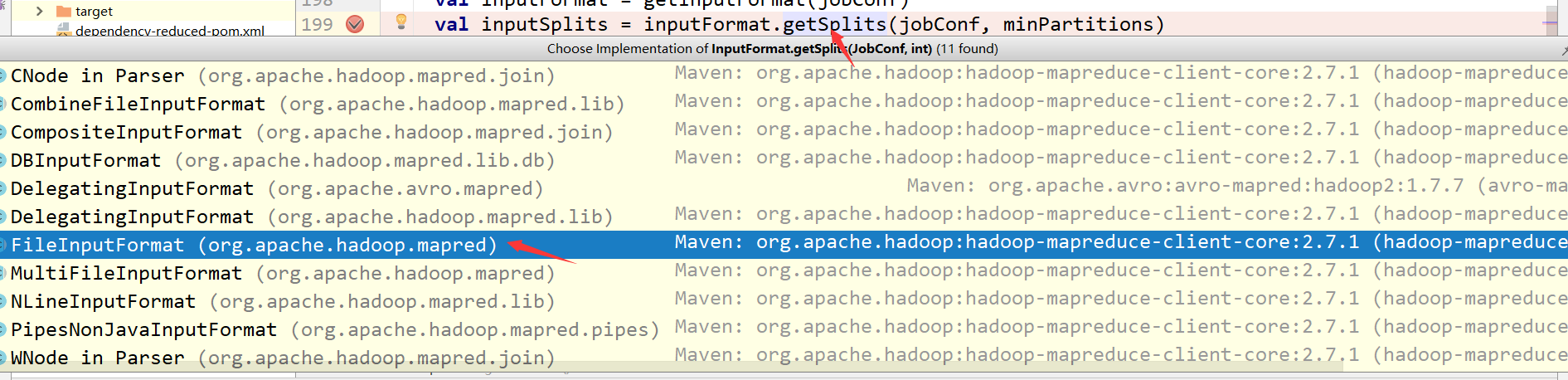
到此,关于“TextFile分区问题怎么理解”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。