您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“Java IO模型与Java网络编程模型的对比”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Java IO模型与Java网络编程模型的对比”吧!
作者:cooffeelis
链接:
https://www.jianshu.com/p/511b9cffbdac
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
常用的5种IO模型:
blocking IO
nonblocking IO
IO multiplexing
signal driven IO
asynchronous IO
再说一下IO发生时涉及的对象和步骤:
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象:
一个是调用这个IO的process (or thread)
一个就是系统内核(kernel)
当一个read操作发生时,它会经历两个阶段:
等待数据准备,比如accept(), recv()等待数据
(Waiting for the data to be ready)
将数据从内核拷贝到进程中, 比如 accept()接受到请求,recv()接收连接发送的数据后需要复制到内核,再从内核复制到进程用户空间(Copying the data from the kernel to the process)
对于socket流而言,数据的流向经历两个阶段:
第一步通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。
第二步把数据从内核缓冲区复制到应用进程缓冲区。
记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:

阻塞IO流程
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:

非阻塞 I/O 流程
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
值得注意的是,此时的非阻塞IO只是应用到等待数据上,当真正有数据到达执行recvfrom的时候,还是同步阻塞IO来的, 从图中的copy data from kernel to user可以看出
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。

I/O 多路复用流程
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
IO复用的实现方式目前主要有select、poll和epoll。
select和poll的原理基本相同:
注册待侦听的fd(这里的fd创建时最好使用非阻塞)
每次调用都去检查这些fd的状态,当有一个或者多个fd就绪的时候返回
返回结果中包括已就绪和未就绪的fd
相比select,poll解决了单个进程能够打开的文件描述符数量有限制这个问题:select受限于FD_SIZE的限制,如果修改则需要修改这个宏重新编译内核;而poll通过一个pollfd数组向内核传递需要关注的事件,避开了文件描述符数量限制。
此外,select和poll共同具有的一个很大的缺点就是包含大量fd的数组被整体复制于用户态和内核态地址空间之间,开销会随着fd数量增多而线性增大。
select和poll就类似于上面说的就餐方式。但当你每次都去询问时,老板会把所有你点的饭菜都轮询一遍再告诉你情况,当大量饭菜很长时间都不能准备好的情况下是很低效的。于是,老板有些不耐烦了,就让厨师每做好一个菜就通知他。这样每次你再去问的时候,他会直接把已经准备好的菜告诉你,你再去端。这就是事件驱动IO就绪通知的方式-epoll。
epoll的出现,解决了select、poll的缺点:
基于事件驱动的方式,避免了每次都要把所有fd都扫描一遍。
epoll_wait只返回就绪的fd。
epoll使用nmap内存映射技术避免了内存复制的开销。
epoll的fd数量上限是操作系统的最大文件句柄数目,这个数目一般和内存有关,通常远大于1024。
目前,epoll是Linux2.6下最高效的IO复用方式,也是Nginx、Node的IO实现方式。而在freeBSD下,kqueue是另一种类似于epoll的IO复用方式。
此外,对于IO复用还有一个水平触发和边缘触发的概念:
水平触发:当就绪的fd未被用户进程处理后,下一次查询依旧会返回,这是select和poll的触发方式。
边缘触发:无论就绪的fd是否被处理,下一次不再返回。理论上性能更高,但是实现相当复杂,并且任何意外的丢失事件都会造成请求处理错误。epoll默认使用水平触发,通过相应选项可以使用边缘触发。
点评:
I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
所以, IO多路复用,本质上不会有并发的功能,因为任何时候还是只有一个进程或线程进行工作,它之所以能提高效率是因为select\epoll 把进来的socket放到他们的 ‘监视’ 列表里面,当任何socket有可读可写数据立马处理,那如果select\epoll 手里同时检测着很多socket, 一有动静马上返回给进程处理,总比一个一个socket过来,阻塞等待,处理高效率。
当然也可以多线程/多进程方式,一个连接过来开一个进程/线程处理,这样消耗的内存和进程切换页会耗掉更多的系统资源。
所以我们可以结合IO多路复用和多进程/多线程 来高性能并发,IO复用负责提高接受socket的通知效率,收到请求后,交给进程池/线程池来处理逻辑。信号驱动
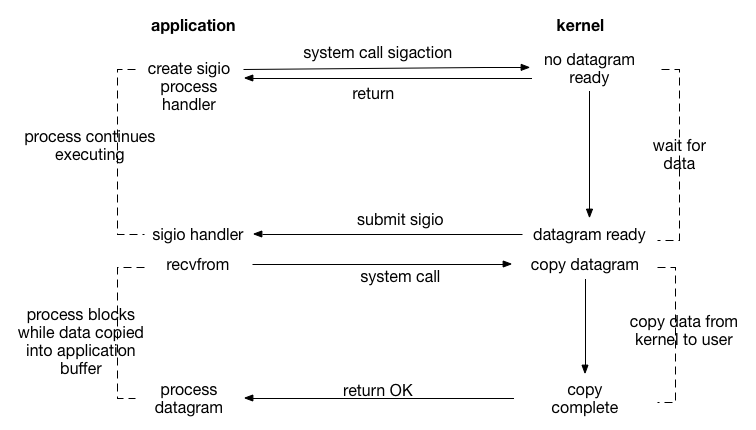
上文的就餐方式还是需要你每次都去问一下饭菜状况。于是,你再次不耐烦了,就跟老板说,哪个饭菜好了就通知我一声吧。然后就自己坐在桌子那里干自己的事情。更甚者,你可以把手机号留给老板,自己出门,等饭菜好了直接发条短信给你。这就类似信号驱动的IO模型。
流程如下:
开启套接字信号驱动IO功能
系统调用sigaction执行信号处理函数(非阻塞,立刻返回)
数据就绪,生成sigio信号,通过信号回调通知应用来读取数据。
此种io方式存在的一个很大的问题:Linux中信号队列是有限制的,如果超过这个数字问题就无法读取数据。
异步非阻塞
linux下的asynchronous IO其实用得很少。先看一下它的流程:

异步IO 流程
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
阻塞IO VS 非阻塞IO:
概念:
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
例子:你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
分析:
阻塞IO会一直block住对应的进程直到操作完成,而非阻塞IO在kernel还准备数据的情况下会立刻返回。
同步IO VS 异步IO:
概念:
同步与异步同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用的结果。而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
典型的异步编程模型比如Node.js举个通俗的例子:你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下”,然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
分析:
在说明同步IO和异步IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于同步IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的阻塞IO,非阻塞IO ,IO复用都属于同步IO。
有人可能会说,非阻塞IO 并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。非阻塞IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。
而异步IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆;
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。
select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的
Select/Poll/Epoll 都是IO复用的实现方式, 上面说了使用IO复用,会把socket设置成non-blocking,然后放进Select/Poll/Epoll 各自的监视列表里面,那么,他们的对socket是否有数据到达的监视机制分别是怎样的?效率又如何?我们应该使用哪种方式实现IO复用比较好?下面列出他们各自的实现方式,效率,优缺点:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
上文讲述了UNIX环境的五种IO模型。基于这五种模型,在Java中,随着NIO和NIO2.0(AIO)的引入,一般具有以下几种网络编程模型:
BIO
NIO
AIO
BIO是一个典型的网络编程模型,是通常我们实现一个服务端程序的过程,步骤如下:
主线程accept请求阻塞
请求到达,创建新的线程来处理这个套接字,完成对客户端的响应。
主线程继续accept下一个请求
这种模型有一个很大的问题是:当客户端连接增多时,服务端创建的线程也会暴涨,系统性能会急剧下降。因此,在此模型的基础上,类似于 tomcat的bio connector,采用的是线程池来避免对于每一个客户端都创建一个线程。有些地方把这种方式叫做伪异步IO(把请求抛到线程池中异步等待处理)。
JDK1.4开始引入了NIO类库,这里的NIO指的是New IO,主要是使用Selector多路复用器来实现。Selector在Linux等主流操作系统上是通过epoll实现的。
NIO的实现流程,类似于select:
创建ServerSocketChannel监听客户端连接并绑定监听端口,设置为非阻塞模式。
创建Reactor线程,创建多路复用器(Selector)并启动线程。
将ServerSocketChannel注册到Reactor线程的Selector上。监听accept事件。
Selector在线程run方法中无线循环轮询准备就绪的Key。
Selector监听到新的客户端接入,处理新的请求,完成tcp三次握手,建立物理连接。
将新的客户端连接注册到Selector上,监听读操作。读取客户端发送的网络消息。
客户端发送的数据就绪则读取客户端请求,进行处理。
相比BIO,NIO的编程非常复杂。
JDK1.7引入NIO2.0,提供了异步文件通道和异步套接字通道的实现。其底层在windows上是通过IOCP,在Linux上是通过epoll来实现的(LinuxAsynchronousChannelProvider.java,UnixAsynchronousServerSocketChannelImpl.java)。
创建AsynchronousServerSocketChannel,绑定监听端口
调用AsynchronousServerSocketChannel的accpet方法,传入自己实现的CompletionHandler。包括上一步,都是非阻塞的
连接传入,回调CompletionHandler的completed方法,在里面,调用AsynchronousSocketChannel的read方法,传入负责处理数据的CompletionHandler。
数据就绪,触发负责处理数据的CompletionHandler的completed方法。继续做下一步处理即可。
写入操作类似,也需要传入CompletionHandler。
其编程模型相比NIO有了不少的简化。
| . | 同步阻塞IO | 伪异步IO | NIO | AIO |
|---|---|---|---|---|
| 客户端数目 :IO线程 | 1 : 1 | m : n | m : 1 | m : 0 |
| IO模型 | 同步阻塞IO | 同步阻塞IO | 同步非阻塞IO | 异步非阻塞IO |
| 吞吐量 | 低 | 中 | 高 | 高 |
| 编程复杂度 | 简单 | 简单 | 非常复杂 | 复杂 |
到此,相信大家对“Java IO模型与Java网络编程模型的对比”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。