жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶеҰӮдҪ•зј–еҶҷй«ҳжҖ§иғҪзҡ„Javaд»Јз ҒпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
Unable to create new native thread вҖҰвҖҰ
й—®йўҳ1пјҡJavaдёӯеҲӣе»әдёҖдёӘзәҝзЁӢж¶ҲиҖ—еӨҡе°‘еҶ…еӯҳпјҹ
жҜҸдёӘзәҝзЁӢжңүзӢ¬иҮӘзҡ„ж ҲеҶ…еӯҳпјҢе…ұдә«е ҶеҶ…еӯҳ
й—®йўҳ2пјҡдёҖеҸ°жңәеҷЁеҸҜд»ҘеҲӣе»әеӨҡе°‘зәҝзЁӢпјҹ
CPUпјҢеҶ…еӯҳпјҢж“ҚдҪңзі»з»ҹпјҢJVMпјҢеә”з”ЁжңҚеҠЎеҷЁ
жҲ‘们编еҶҷдёҖж®өзӨәдҫӢд»Јз ҒпјҢжқҘйӘҢиҜҒдёӢзәҝзЁӢжұ дёҺйқһзәҝзЁӢжұ зҡ„еҢәеҲ«пјҡ
//зәҝзЁӢжұ е’ҢйқһзәҝзЁӢжұ зҡ„еҢәеҲ«
public class ThreadPool {
public static int times = 100;//100,1000,10000
public static ArrayBlockingQueue arrayWorkQueue = new ArrayBlockingQueue(1000);
public static ExecutorService threadPool = new ThreadPoolExecutor(5, //corePoolSizeзәҝзЁӢжұ дёӯж ёеҝғзәҝзЁӢж•°
10,
60,
TimeUnit.SECONDS,
arrayWorkQueue,
new ThreadPoolExecutor.DiscardOldestPolicy()
);
public static void useThreadPool() {
Long start = System.currentTimeMillis();
for (int i = 0; i < times; i++) {
threadPool.execute(new Runnable() {
public void run() {
System.out.println("иҜҙзӮ№д»Җд№Ҳеҗ§...");
}
});
}
threadPool.shutdown();
while (true) {
if (threadPool.isTerminated()) {
Long end = System.currentTimeMillis();
System.out.println(end - start);
break;
}
}
}
public static void createNewThread() {
Long start = System.currentTimeMillis();
for (int i = 0; i < times; i++) {
new Thread() {
public void run() {
System.out.println("иҜҙзӮ№д»Җд№Ҳеҗ§...");
}
}.start();
}
Long end = System.currentTimeMillis();
System.out.println(end - start);
}
public static void main(String args[]) {
createNewThread();
//useThreadPool();
}
}еҗҜеҠЁдёҚеҗҢж•°йҮҸзҡ„зәҝзЁӢпјҢ然еҗҺжҜ”иҫғзәҝзЁӢжұ е’ҢйқһзәҝзЁӢжұ зҡ„жү§иЎҢз»“жһңпјҡ
| йқһзәҝзЁӢжұ | зәҝзЁӢжұ | |
|---|---|---|
| 100ж¬Ў | 16жҜ«з§’ | 5msзҡ„ |
| 1000ж¬Ў | 90жҜ«з§’ | 28ms |
| 10000ж¬Ў | 1329ms | 164ms |
з»“и®әпјҡдёҚиҰҒnew Thread()пјҢйҮҮз”ЁзәҝзЁӢжұ
йқһзәҝзЁӢжұ зҡ„зјәзӮ№пјҡ
жҜҸж¬ЎеҲӣе»әжҖ§иғҪж¶ҲиҖ—еӨ§
ж— еәҸпјҢзјәд№Ҹз®ЎзҗҶгҖӮе®№жҳ“ж— йҷҗеҲ¶еҲӣе»әзәҝзЁӢпјҢеј•иө·OOMе’Ңжӯ»жңә
йҒҝе…Қжӯ»й”ҒпјҢиҜ·е°ҪйҮҸдҪҝз”ЁCAS
жҲ‘们编еҶҷдёҖдёӘд№җи§Ӯй”Ғзҡ„е®һзҺ°зӨәдҫӢпјҡ
public class CASLock {
public static int money = 2000;
public static boolean add2(int oldm, int newm) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (money == oldm) {
money = money + newm;
return true;
}
return false;
}
public synchronized static void add1(int newm) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
money = money + newm;
}
public static void add(int newm) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
money = money + newm;
}
public static void main(String args[]) {
Thread one = new Thread() {
public void run() {
//add(5000)
while (true) {
if (add2(money, 5000)) {
break;
}
}
}
};
Thread two = new Thread() {
public void run() {
//add(7000)
while (true) {
if (add2(money, 7000)) {
break;
}
}
}
};
one.start();
two.start();
try {
one.join();
two.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(money);
}
}дҪҝз”ЁThreadLocalиҰҒжіЁж„Ҹ
ThreadLocalMapдҪҝз”ЁThreadLocalзҡ„ејұеј•з”ЁдҪңдёәkeyпјҢеҰӮжһңдёҖдёӘThreadLocalжІЎжңүеӨ–йғЁејәеј•з”ЁжқҘеј•з”Ёе®ғпјҢйӮЈд№Ҳзі»з»ҹ GC зҡ„ж—¶еҖҷпјҢиҝҷдёӘThreadLocalеҠҝеҝ…дјҡиў«еӣһ收пјҢиҝҷж ·дёҖжқҘпјҢThreadLocalMapдёӯе°ұдјҡеҮәзҺ°keyдёәnullзҡ„EntryпјҢе°ұжІЎжңүеҠһжі•и®ҝй—®иҝҷдәӣkeyдёәnullзҡ„Entryзҡ„valueпјҢеҰӮжһңеҪ“еүҚзәҝзЁӢеҶҚиҝҹиҝҹдёҚз»“жқҹзҡ„иҜқпјҢиҝҷдәӣkeyдёәnullзҡ„Entryзҡ„valueе°ұдјҡдёҖзӣҙеӯҳеңЁдёҖжқЎејәеј•з”Ёй“ҫпјҡThread Ref -> Thread -> ThreaLocalMap -> Entry -> valueж°ёиҝңж— жі•еӣһ收пјҢйҖ жҲҗеҶ…еӯҳжі„жјҸгҖӮ
жҲ‘们编еҶҷдёҖдёӘThreadLocalMapжӯЈзЎ®дҪҝз”Ёзҡ„зӨәдҫӢпјҡ
//ThreadLocalеә”з”Ёе®һдҫӢ
public class ThreadLocalApp {
public static final ThreadLocal threadLocal = new ThreadLocal();
public static void muti2() {
int i[] = (int[]) threadLocal.get();
i[1] = i[0] * 2;
threadLocal.set(i);
}
public static void muti3() {
int i[] = (int[]) threadLocal.get();
i[2] = i[1] * 3;
threadLocal.set(i);
}
public static void muti5() {
int i[] = (int[]) threadLocal.get();
i[3] = i[2] * 5;
threadLocal.set(i);
}
public static void main(String args[]) {
for (int i = 0; i < 5; i++) {
new Thread() {
public void run() {
int start = new Random().nextInt(10);
int end[] = {0, 0, 0, 0};
end[0] = start;
threadLocal.set(end);
ThreadLocalApp.muti2();
ThreadLocalApp.muti3();
ThreadLocalApp.muti5();
//int end = (int) threadLocal.get();
System.out.println(end[0] + " " + end[1] + " " + end[2] + " " + end[3]);
threadLocal.remove();
}
}.start();
}
}
}з»Ҹе…ёзҡ„HashMapжӯ»еҫӘзҺҜйҖ жҲҗCPU100%й—®йўҳ
жҲ‘们模жӢҹдёҖдёӘHashMapжӯ»еҫӘзҺҜзҡ„зӨәдҫӢпјҡ
//HashMapжӯ»еҫӘзҺҜзӨәдҫӢ
public class HashMapDeadLoop {
private HashMap hash = new HashMap();
public HashMapDeadLoop() {
Thread t1 = new Thread() {
public void run() {
for (int i = 0; i < 100000; i++) {
hash.put(new Integer(i), i);
}
System.out.println("t1 over");
}
};
Thread t2 = new Thread() {
public void run() {
for (int i = 0; i < 100000; i++) {
hash.put(new Integer(i), i);
}
System.out.println("t2 over");
}
};
t1.start();
t2.start();
}
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
new HashMapDeadLoop();
}
System.out.println("end");
}
}
https://coolshell.cn/articles/9606.htmlHashMapжӯ»еҫӘзҺҜеҸ‘з”ҹеҗҺпјҢжҲ‘们еҸҜд»ҘеңЁзәҝзЁӢж Ҳдёӯи§ӮжөӢеҲ°еҰӮдёӢдҝЎжҒҜпјҡ
/HashMapжӯ»еҫӘзҺҜдә§з”ҹзҡ„зәҝзЁӢж Ҳ Thread-281" #291 prio=5 os_prio=31 tid=0x00007f9f5f8de000 nid=0x5a37 runnable [0x0000700006349000] java.lang.Thread.State: RUNNABLE at java.util.HashMap$TreeNode.split(HashMap.java:2134) at java.util.HashMap.resize(HashMap.java:713) at java.util.HashMap.putVal(HashMap.java:662) at java.util.HashMap.put(HashMap.java:611) at com.example.demo.HashMapDeadLoop$2.run(HashMapDeadLoop.java:26)
еә”з”ЁеҒңж»һзҡ„жӯ»й”ҒпјҢSpring3.1зҡ„deadlock й—®йўҳ
жҲ‘们模жӢҹдёҖдёӘжӯ»й”Ғзҡ„зӨәдҫӢпјҡ
//жӯ»й”Ғзҡ„зӨәдҫӢ
public class DeadLock {
public static Integer i1 = 2000;
public static Integer i2 = 3000;
public static synchronized Integer getI2() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return i2;
}
public static void main(String args[]) {
Thread one = new Thread() {
public void run() {
synchronized (i1) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (i2) {
System.out.println(i1 + i2);
}
}
}
};
one.start();
Thread two = new Thread() {
public void run() {
synchronized (i2) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (i1) {
System.out.println(i1 + i2);
}
}
}
};
two.start();
}
}жӯ»й”ҒеҸ‘з”ҹеҗҺпјҢжҲ‘们еҸҜд»ҘеңЁзәҝзЁӢж Ҳдёӯи§ӮжөӢеҲ°еҰӮдёӢдҝЎжҒҜпјҡ
//жӯ»й”Ғж—¶дә§з”ҹе Ҷж Ҳ "Thread-1": at com.example.demo.DeadLock$2.run(DeadLock.java:47) - waiting to lock (a java.lang.Integer) - locked (a java.lang.Integer) "Thread-0": at com.example.demo.DeadLock$1.run(DeadLock.java:31) - waiting to lock (a java.lang.Integer) - locked (a java.lang.Integer) Found 1 deadlock.
дёҖдёӘи®Ўж•°еҷЁзҡ„дјҳеҢ–пјҢжҲ‘们еҲҶеҲ«з”ЁSynchronizedпјҢReentrantLockпјҢAtomicдёүз§ҚдёҚеҗҢзҡ„ж–№ејҸжқҘе®һзҺ°дёҖдёӘи®Ўж•°еҷЁпјҢдҪ“дјҡе…¶дёӯзҡ„жҖ§иғҪе·®ејӮ
//зӨәдҫӢд»Јз Ғ
public class SynchronizedTest {
public static int threadNum = 100;
public static int loopTimes = 10000000;
public static void userSyn() {
//зәҝзЁӢж•°
Syn syn = new Syn();
Thread[] threads = new Thread[threadNum];
//и®°еҪ•иҝҗиЎҢж—¶й—ҙ
long l = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < loopTimes; j++) {
//syn.increaseLock();
syn.increase();
}
}
});
threads[i].start();
}
//зӯүеҫ…жүҖжңүзәҝзЁӢз»“жқҹ
try {
for (int i = 0; i < threadNum; i++)
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("userSyn" + "-" + syn + " : " + (System.currentTimeMillis() - l) + "ms");
}
public static void useRea() {
//зәҝзЁӢж•°
Syn syn = new Syn();
Thread[] threads = new Thread[threadNum];
//и®°еҪ•иҝҗиЎҢж—¶й—ҙ
long l = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < loopTimes; j++) {
syn.increaseLock();
//syn.increase();
}
}
});
threads[i].start();
}
//зӯүеҫ…жүҖжңүзәҝзЁӢз»“жқҹ
try {
for (int i = 0; i < threadNum; i++)
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("userRea" + "-" + syn + " : " + (System.currentTimeMillis() - l) + "ms");
}
public static void useAto() {
//зәҝзЁӢж•°
Thread[] threads = new Thread[threadNum];
//и®°еҪ•иҝҗиЎҢж—¶й—ҙ
long l = System.currentTimeMillis();
for (int i = 0; i < threadNum; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < loopTimes; j++) {
Syn.ai.incrementAndGet();
}
}
});
threads[i].start();
}
//зӯүеҫ…жүҖжңүзәҝзЁӢз»“жқҹ
try {
for (int i = 0; i < threadNum; i++)
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("userAto" + "-" + Syn.ai + " : " + (System.currentTimeMillis() - l) + "ms");
}
public static void main(String[] args) {
SynchronizedTest.userSyn();
SynchronizedTest.useRea();
SynchronizedTest.useAto();
}
}
class Syn {
private int count = 0;
public final static AtomicInteger ai = new AtomicInteger(0);
private Lock lock = new ReentrantLock();
public synchronized void increase() {
count++;
}
public void increaseLock() {
lock.lock();
count++;
lock.unlock();
}
@Override
public String toString() {
return String.valueOf(count);
}
}з»“и®әпјҢеңЁе№¶еҸ‘йҮҸй«ҳпјҢеҫӘзҺҜж¬Ўж•°еӨҡзҡ„жғ…еҶөпјҢеҸҜйҮҚе…Ҙй”Ғзҡ„ж•ҲзҺҮй«ҳдәҺSynchronizedпјҢдҪҶжңҖз»ҲAtomicжҖ§иғҪжңҖеҘҪгҖӮ
дёҖе®ҡиҰҒеңЁfinallyдёӯcloseиҝһжҺҘ
дёҖе®ҡиҰҒеңЁfinallyдёӯreleaseиҝһжҺҘ
| OIO | NIO | AIO | |
|---|---|---|---|
| зұ»еһӢ | йҳ»еЎһ | йқһйҳ»еЎһ | йқһйҳ»еЎһ |
| дҪҝз”ЁйҡҫеәҰ | з®ҖеҚ• | еӨҚжқӮ | еӨҚжқӮ |
| еҸҜйқ жҖ§ | е·® | й«ҳ | й«ҳ |
| еҗһеҗҗйҮҸ | дҪҺ | й«ҳ | й«ҳ |
з»“и®әпјҡжҲ‘жҖ§иғҪжңүдёҘиӢӣиҰҒжұӮдёӢпјҢе°ҪйҮҸеә”иҜҘйҮҮз”ЁNIOзҡ„ж–№ејҸиҝӣиЎҢйҖҡдҝЎгҖӮ
еҸҚеә”пјҡз»ҸеёёжҖ§зҡ„иҜ·жұӮеӨұиҙҘ
иҺ·еҸ–иҝһжҺҘжғ…еҶө netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TIME_WAITпјҡиЎЁзӨәдё»еҠЁе…ій—ӯпјҢдјҳеҢ–зі»з»ҹеҶ…ж ёеҸӮж•°еҸҜгҖӮ
CLOSE_WAITпјҡиЎЁзӨәиў«еҠЁе…ій—ӯгҖӮ
ESTABLISHEDпјҡиЎЁзӨәжӯЈеңЁйҖҡдҝЎ
и§ЈеҶіж–№жЎҲпјҡдәҢйҳ¶ж®өе®ҢжҲҗеҗҺејәеҲ¶е…ій—ӯ
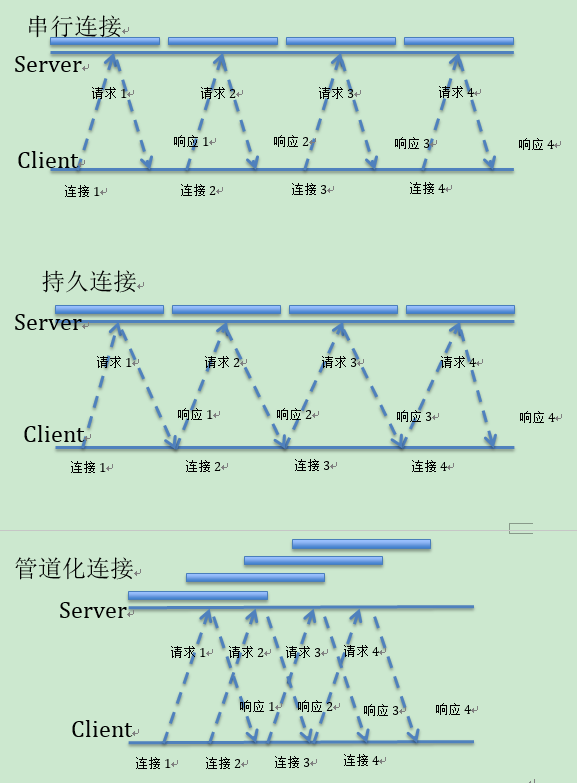
з»“и®әпјҡ
з®ЎйҒ“иҝһжҺҘзҡ„жҖ§иғҪжңҖдјҳејӮпјҢжҢҒд№…еҢ–жҳҜеңЁдёІиЎҢиҝһжҺҘзҡ„еҹәзЎҖдёҠеҮҸе°‘дәҶжү“ејҖ/е…ій—ӯиҝһжҺҘзҡ„ж—¶й—ҙгҖӮ
з®ЎйҒ“еҢ–иҝһжҺҘдҪҝз”ЁйҷҗеҲ¶пјҡ
1гҖҒHTTPе®ўжҲ·з«Ҝж— жі•зЎ®и®ӨжҢҒд№…еҢ–пјҲдёҖиҲ¬жҳҜжңҚеҠЎеҷЁеҲ°жңҚеҠЎеҷЁпјҢйқһз»Ҳз«ҜдҪҝз”Ёпјүпјӣ
2гҖҒе“Қеә”дҝЎжҒҜйЎәеәҸеҝ…йЎ»дёҺиҜ·жұӮдҝЎжҒҜйЎәеәҸдёҖиҮҙпјӣ
3гҖҒеҝ…йЎ»ж”ҜжҢҒе№Ӯзӯүж“ҚдҪңжүҚеҸҜд»ҘдҪҝз”Ёз®ЎйҒ“еҢ–иҝһжҺҘ.
еҝ…йЎ»иҰҒжңүзҙўеј•пјҲзү№еҲ«жіЁж„ҸжҢүж—¶й—ҙжҹҘиҜўпјү
еҚ•жқЎж“ҚдҪңorжү№йҮҸж“ҚдҪң
жіЁпјҡеҫҲеӨҡзЁӢеәҸе‘ҳеңЁеҶҷд»Јз Ғзҡ„ж—¶еҖҷйҡҸж„ҸйҮҮз”ЁдәҶеҚ•жқЎж“ҚдҪңзҡ„ж–№ејҸпјҢдҪҶеңЁжҖ§иғҪиҰҒжұӮеүҚжҸҗдёӢпјҢиҰҒжұӮйҮҮз”Ёжү№йҮҸж“ҚдҪңж–№ејҸгҖӮ
topжҹҘжүҫеҮәе“ӘдёӘиҝӣзЁӢж¶ҲиҖ—зҡ„cpuй«ҳ
top вҖ“H вҖ“pжҹҘжүҫеҮәе“ӘдёӘзәҝзЁӢж¶ҲиҖ—зҡ„cpuй«ҳ
и®°еҪ•ж¶ҲиҖ—cpuжңҖй«ҳзҡ„еҮ дёӘзәҝзЁӢ
printf %x иҝӣиЎҢpidзҡ„иҝӣеҲ¶иҪ¬жҚў
jstackи®°еҪ•иҝӣзЁӢзҡ„е Ҷж ҲдҝЎжҒҜ
жүҫеҮәж¶ҲиҖ—cpuжңҖй«ҳзҡ„зәҝзЁӢдҝЎжҒҜ
jstatе‘Ҫд»ӨжҹҘзңӢFGCеҸ‘з”ҹзҡ„ж¬Ўж•°е’Ңж¶ҲиҖ—зҡ„ж—¶й—ҙпјҢж¬Ўж•°и¶ҠеӨҡпјҢиҖ—ж—¶и¶Ҡй•ҝиҜҙжҳҺеӯҳеңЁй—®йўҳпјӣ
иҝһз»ӯжҹҘзңӢjmap вҖ“heap жҹҘзңӢиҖҒз”ҹд»Јзҡ„еҚ з”Ёжғ…еҶөпјҢеҸҳеҢ–и¶ҠеӨ§иҜҙжҳҺзЁӢеәҸеӯҳеңЁй—®йўҳпјӣ
дҪҝз”Ёиҝһз»ӯзҡ„jmap вҖ“histo:live е‘Ҫд»ӨеҜјеҮәж–Ү件пјҢжҜ”еҜ№еҠ иҪҪеҜ№иұЎзҡ„е·®ејӮпјҢе·®ејӮйғЁеҲҶдёҖиҲ¬жҳҜеҸ‘з”ҹй—®йўҳзҡ„ең°ж–№гҖӮ
еҚ•дёӘCPUеҚ з”ЁзҺҮй«ҳпјҢйҰ–е…Ҳд»ҺGCжҹҘиө·гҖӮ
зәҝзЁӢдёҠдёӢж–ҮеҲҮжҚўйў‘з№Ғ
зәҝзЁӢеӨӘеӨҡ
й”Ғз«һдәүжҝҖзғҲ
еҰӮжһңIOзҡ„CPUеҚ з”ЁеҫҲй«ҳпјҢжҺ’жҹҘж¶үеҸҠеҲ°IOзҡ„зЁӢеәҸпјҢжҜ”еҰӮжҠҠOIOж”№йҖ жҲҗNIOгҖӮ
еҺҹеӣ пјҡеӯ—иҠӮз ҒиҪ¬дёәжңәеҷЁз ҒйңҖиҰҒеҚ з”ЁCPUж—¶й—ҙзүҮпјҢеӨ§йҮҸзҡ„CPUеңЁжү§иЎҢеӯ—иҠӮз Ғж—¶пјҢеҜјиҮҙCPUй•ҝжңҹеӨ„дәҺй«ҳдҪҚпјӣ
зҺ°иұЎпјҡвҖңC2 CompilerThread1вҖқ daemonпјҢвҖңC2 CompilerThread0вҖқ daemon CPUеҚ з”ЁзҺҮжңҖй«ҳпјӣ
и§ЈеҶіеҠһжі•пјҡдҝқиҜҒзј–иҜ‘зәҝзЁӢзҡ„CPUеҚ жҜ”гҖӮ
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңеҰӮдҪ•зј–еҶҷй«ҳжҖ§иғҪзҡ„Javaд»Јз ҒвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ