жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іJavaеҶ…еӯҳжі„жјҸжҺ’жҹҘиҝҮзЁӢзҡ„зӨәдҫӢеҲҶжһҗзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
еҚҲеӨңеҲҡиҝҮпјҢжҲ‘е°ұиў«дёҖжқЎжқҘиҮӘзӣ‘жҺ§зі»з»ҹзҡ„иӯҰжҠҘеҗөйҶ’дәҶгҖӮAdventoryпјҢжҲ‘们зҡ„ PPC пјҲд»ҘзӮ№еҮ»ж¬Ўж•°ж”¶иҙ№пјүе№ҝе‘Ҡзі»з»ҹдёӯдёҖдёӘиҙҹиҙЈзҙўеј•е№ҝе‘Ҡзҡ„еә”з”ЁпјҢеҫҲжҳҺжҳҫиҝһз»ӯйҮҚеҗҜдәҶеҘҪеҮ ж¬ЎгҖӮеңЁдә‘з«Ҝзҡ„зҺҜеўғйҮҢпјҢе®һдҫӢзҡ„йҮҚеҗҜжҳҜеҫҲжӯЈеёёзҡ„пјҢд№ҹдёҚдјҡи§ҰеҸ‘жҠҘиӯҰпјҢдҪҶиҝҷж¬Ўе®һдҫӢйҮҚеҗҜзҡ„ж¬Ўж•°еңЁзҹӯж—¶й—ҙеҶ…и¶…иҝҮдәҶйҳҲеҖјгҖӮжҲ‘жү“ејҖдәҶ笔记жң¬з”өи„‘пјҢдёҖеӨҙжүҺиҝӣйЎ№зӣ®зҡ„ж—Ҙеҝ—йҮҢгҖӮ
жҲ‘зңӢеҲ°жңҚеҠЎеңЁиҝһжҺҘ ZooKeeper ж—¶еҸ‘з”ҹдәҶж•°ж¬Ўи¶…ж—¶гҖӮжҲ‘们дҪҝз”Ё ZooKeeperпјҲZKпјүеҚҸи°ғеӨҡдёӘе®һдҫӢй—ҙзҡ„зҙўеј•ж“ҚдҪңпјҢ并дҫқиө–е®ғе®һзҺ°йІҒжЈ’жҖ§гҖӮеҫҲжҳҫ然пјҢдёҖж¬Ў Zookeeper еӨұиҙҘдјҡйҳ»жӯўзҙўеј•ж“ҚдҪңзҡ„继з»ӯиҝҗиЎҢпјҢдёҚиҝҮе®ғеә”иҜҘдёҚдјҡеҜјиҮҙж•ҙдёӘзі»з»ҹжҢӮжҺүгҖӮиҖҢдё”пјҢиҝҷз§Қжғ…еҶөйқһеёёзҪ•и§ҒпјҲиҝҷжҳҜжҲ‘第дёҖж¬ЎйҒҮеҲ° ZK еңЁз”ҹдә§зҺҜеўғжҢӮжҺүпјүпјҢжҲ‘и§үеҫ—иҝҷдёӘй—®йўҳеҸҜиғҪдёҚеӨӘе®№жҳ“жҗһе®ҡгҖӮдәҺжҳҜжҲ‘жҠҠ ZooKeeper зҡ„еҖјзҸӯдәәе‘ҳе–ҠйҶ’дәҶпјҢ让他们зңӢзңӢеҸ‘з”ҹдәҶд»Җд№ҲгҖӮ
еҗҢж—¶пјҢжҲ‘жЈҖжҹҘдәҶжҲ‘们зҡ„й…ҚзҪ®пјҢеҸ‘зҺ° ZooKeeper иҝһжҺҘзҡ„и¶…ж—¶ж—¶й—ҙжҳҜз§’зә§зҡ„гҖӮеҫҲжҳҺжҳҫпјҢZooKeeper е…ЁжҢӮдәҶпјҢз”ұдәҺе…¶д»–жңҚеҠЎд№ҹеңЁдҪҝз”Ёе®ғпјҢиҝҷж„Ҹе‘ізқҖй—®йўҳйқһеёёдёҘйҮҚгҖӮжҲ‘з»ҷе…¶д»–еҮ дёӘеӣўйҳҹеҸ‘дәҶж¶ҲжҒҜпјҢ他们жҳҫ然иҝҳдёҚзҹҘйҒ“иҝҷдәӢе„ҝгҖӮ
ZooKeeper еӣўйҳҹзҡ„еҗҢдәӢеӣһеӨҚжҲ‘дәҶпјҢеңЁд»–зңӢжқҘпјҢзі»з»ҹиҝҗиЎҢдёҖеҲҮжӯЈеёёгҖӮз”ұдәҺе…¶д»–з”ЁжҲ·зңӢиө·жқҘжІЎжңүеҸ—еҲ°еҪұе“ҚпјҢжҲ‘ж…ўж…ўж„ҸиҜҶеҲ°дёҚжҳҜ ZooKeeper зҡ„й—®йўҳгҖӮж—Ҙеҝ—йҮҢжҳҺжҳҫжҳҜзҪ‘з»ңи¶…ж—¶пјҢдәҺжҳҜжҲ‘жҠҠиҙҹиҙЈзҪ‘з»ңзҡ„еҗҢдәӢеҸ«йҶ’дәҶгҖӮ
иҙҹиҙЈзҪ‘з»ңзҡ„еӣўйҳҹжЈҖжҹҘдәҶ他们зҡ„зӣ‘жҺ§пјҢжІЎжңүеҸ‘зҺ°д»»дҪ•ејӮеёёгҖӮз”ұдәҺеҚ•дёӘзҪ‘ж®өпјҢз”ҡиҮіеҚ•дёӘиҠӮзӮ№пјҢйғҪжңүеҸҜиғҪе’Ңеү©дҪҷзҡ„е…¶д»–иҠӮзӮ№ж–ӯејҖиҝһжҺҘпјҢ他们жЈҖжҹҘдәҶжҲ‘们系з»ҹе®һдҫӢжүҖеңЁзҡ„еҮ еҸ°жңәеҷЁпјҢжІЎжңүеҸ‘зҺ°ејӮеёёгҖӮе…¶й—ҙпјҢжҲ‘е°қиҜ•дәҶе…¶д»–еҮ з§ҚжҖқи·ҜпјҢдёҚиҝҮйғҪиЎҢдёҚйҖҡпјҢжҲ‘д№ҹеҲ°дәҶиҮӘе·ұжҷәеҠӣзҡ„жһҒйҷҗгҖӮж—¶й—ҙе·Із»ҸеҫҲжҷҡдәҶпјҲжҲ–иҖ…иҜҙеҫҲж—©дәҶпјүпјҢеҗҢж—¶пјҢи·ҹжҲ‘зҡ„е°қиҜ•жІЎжңүд»»дҪ•е…ізі»пјҢйҮҚеҗҜеҸҳеҫ—дёҚйӮЈд№Ҳйў‘з№ҒдәҶгҖӮз”ұдәҺиҝҷдёӘжңҚеҠЎд»…д»…иҙҹиҙЈж•°жҚ®зҡ„еҲ·ж–°пјҢ并дёҚдјҡеҪұе“ҚеҲ°ж•°жҚ®зҡ„еҸҜз”ЁжҖ§пјҢжҲ‘们еҶіе®ҡжҠҠй—®йўҳж”ҫеҲ°дёҠеҚҲеҶҚиҜҙгҖӮ
жңүж—¶еҖҷжҠҠйҡҫйўҳж”ҫдёҖж”ҫпјҢзқЎдёҖи§үпјҢзӯүи„‘еӯҗжё…йҶ’дәҶеҶҚеҺ»и§ЈеҶіжҳҜдёҖдёӘеҘҪдё»ж„ҸгҖӮжІЎдәәзҹҘйҒ“еҪ“ж—¶еҸ‘з”ҹдәҶд»Җд№ҲпјҢжңҚеҠЎиЎЁзҺ°зҡ„йқһеёёжҖӘејӮгҖӮзӘҒ然й—ҙпјҢжҲ‘жғіеҲ°дәҶд»Җд№ҲгҖӮJava жңҚеҠЎиЎЁзҺ°жҖӘејӮзҡ„дё»иҰҒж №жәҗжҳҜд»Җд№ҲпјҹеҪ“然жҳҜеһғеңҫеӣһ收гҖӮ
дёәдәҶеә”еҜ№зӣ®еүҚиҝҷз§Қжғ…еҶөзҡ„еҸ‘з”ҹпјҢжҲ‘们дёҖзӣҙжү“еҚ°зқҖ GC зҡ„ж—Ҙеҝ—гҖӮжҲ‘马дёҠжҠҠ GC ж—Ҙеҝ—дёӢиҪҪдәҶдёӢжқҘпјҢ然еҗҺжү“ејҖ CensumејҖе§ӢеҲҶжһҗж—Ҙеҝ—гҖӮжҲ‘иҝҳжІЎд»”з»ҶзңӢпјҢе°ұеҸ‘зҺ°дәҶдёҖдёӘжҒҗжҖ–зҡ„жғ…еҶөпјҡжҜҸ15еҲҶй’ҹеҸ‘з”ҹдёҖж¬Ў full GCпјҢжҜҸж¬Ў GC еј•еҸ‘й•ҝиҫҫ 20 з§’зҡ„жңҚеҠЎеҒңйЎҝгҖӮжҖӘдёҚеҫ—иҝһжҺҘ ZooKeeper и¶…ж—¶дәҶпјҢеҚідҪҝ ZooKeeper е’ҢзҪ‘з»ңйғҪжІЎжңүй—®йўҳгҖӮ
иҝҷдәӣеҒңйЎҝд№ҹи§ЈйҮҠдәҶдёәд»Җд№Ҳж•ҙдёӘжңҚеҠЎдёҖзӣҙжҳҜжӯ»жҺүзҡ„пјҢиҖҢдёҚжҳҜи¶…ж—¶д№ӢеҗҺеҸӘжү“дёҖжқЎй”ҷиҜҜж—Ҙеҝ—гҖӮжҲ‘们зҡ„жңҚеҠЎиҝҗиЎҢеңЁ Marathon дёҠпјҢе®ғе®ҡж—¶жЈҖжҹҘжҜҸдёӘе®һдҫӢзҡ„еҒҘеә·зҠ¶жҖҒпјҢеҰӮжһңжҹҗдёӘз«ҜзӮ№еңЁдёҖж®өж—¶й—ҙеҶ…жІЎжңүе“Қеә”пјҢMarathon е°ұйҮҚеҗҜйӮЈдёӘжңҚеҠЎгҖӮ

зҹҘйҒ“еҺҹеӣ д№ӢеҗҺпјҢй—®йўҳе°ұи§ЈеҶідёҖеҚҠдәҶпјҢеӣ жӯӨжҲ‘зӣёдҝЎиҝҷдёӘй—®йўҳеҫҲеҝ«е°ұиғҪи§ЈеҶігҖӮдёәдәҶи§ЈйҮҠеҗҺйқўзҡ„жҺЁзҗҶпјҢжҲ‘йңҖиҰҒиҜҙжҳҺдёҖдёӢ Adventory жҳҜеҰӮдҪ•е·ҘдҪңзҡ„пјҢе®ғдёҚеғҸдҪ 们йӮЈз§Қж ҮеҮҶзҡ„еҫ®жңҚеҠЎгҖӮ
Adventory жҳҜз”ЁжқҘжҠҠжҲ‘们зҡ„е№ҝе‘Ҡзҙўеј•еҲ° ElasticSearch (ES) зҡ„гҖӮиҝҷйңҖиҰҒдёӨдёӘжӯҘйӘӨгҖӮ第дёҖжӯҘжҳҜиҺ·еҸ–жүҖйңҖзҡ„ж•°жҚ®гҖӮеҲ°зӣ®еүҚдёәжӯўпјҢиҝҷдёӘжңҚеҠЎд»Һе…¶д»–еҮ дёӘзі»з»ҹдёӯжҺҘ收йҖҡиҝҮ Hermes еҸ‘жқҘзҡ„дәӢ件гҖӮж•°жҚ®дҝқеӯҳеҲ° MongoDB йӣҶзҫӨдёӯгҖӮж•°жҚ®йҮҸжңҖеӨҡжҜҸз§’еҮ зҷҫдёӘиҜ·жұӮпјҢжҜҸдёӘж“ҚдҪңйғҪзү№еҲ«иҪ»йҮҸпјҢеӣ жӯӨеҚідҫҝи§ҰеҸ‘дёҖдәӣеҶ…еӯҳзҡ„еӣһ收пјҢд№ҹиҖ—иҙ№дёҚдәҶеӨҡе°‘иө„жәҗгҖӮ第дәҢжӯҘе°ұжҳҜж•°жҚ®зҡ„зҙўеј•гҖӮиҝҷдёӘж“ҚдҪңе®ҡж—¶жү§иЎҢпјҲеӨ§жҰӮдёӨеҲҶй’ҹжү§иЎҢдёҖж¬ЎпјүпјҢжҠҠжүҖжңү MongoDB йӣҶзҫӨеӯҳеӮЁзҡ„ж•°жҚ®йҖҡиҝҮ RxJava 收йӣҶеҲ°дёҖдёӘжөҒдёӯпјҢз»„еҗҲдёәйқһиҢғејҸзҡ„и®°еҪ•пјҢеҸ‘йҖҒз»ҷ ElasticSearchгҖӮиҝҷйғЁеҲҶж“ҚдҪңзұ»дјјзҰ»зәҝзҡ„жү№еӨ„зҗҶд»»еҠЎпјҢиҖҢдёҚжҳҜдёҖдёӘжңҚеҠЎгҖӮ
з”ұдәҺз»ҸеёёйңҖиҰҒеҜ№ж•°жҚ®еҒҡеӨ§йҮҸзҡ„жӣҙж–°пјҢз»ҙжҠӨзҙўеј•е°ұдёҚеӨӘеҖјеҫ—пјҢжүҖд»ҘжҜҸжү§иЎҢдёҖж¬Ўе®ҡж—¶д»»еҠЎпјҢж•ҙдёӘзҙўеј•йғҪдјҡйҮҚе»әдёҖж¬ЎгҖӮиҝҷж„Ҹе‘ізқҖдёҖж•ҙеқ—ж•°жҚ®йғҪиҰҒз»ҸиҝҮиҝҷдёӘзі»з»ҹпјҢд»ҺиҖҢеј•еҸ‘еӨ§йҮҸзҡ„еҶ…еӯҳеӣһ收гҖӮе°Ҫз®ЎдҪҝз”ЁдәҶжөҒзҡ„ж–№ејҸпјҢжҲ‘们д№ҹиў«иҝ«жҠҠе ҶеҠ еҲ°дәҶ 12 GB иҝҷд№ҲеӨ§гҖӮз”ұдәҺе ҶжҳҜеҰӮжӯӨе·ЁеӨ§пјҲиҖҢдё”зӣ®еүҚиў«е…ЁеҠӣж”ҜжҢҒпјүпјҢжҲ‘们зҡ„ GC йҖүжӢ©дәҶ G1гҖӮ
жҲ‘д»ҘеүҚеӨ„зҗҶиҝҮзҡ„жңҚеҠЎдёӯпјҢд№ҹдјҡеӣһ收еӨ§йҮҸз”ҹе‘Ҫе‘ЁжңҹеҫҲзҹӯзҡ„еҜ№иұЎгҖӮжңүдәҶйӮЈдәӣз»ҸйӘҢпјҢжҲ‘еҗҢж—¶еўһеҠ дәҶ -XX:G1NewSizePercent е’Ң -XX:G1MaxNewSizePercent зҡ„й»ҳи®ӨеҖјпјҢиҝҷж ·ж–°з”ҹд»ЈдјҡеҸҳеҫ—жӣҙеӨ§пјҢyoung GC е°ұеҸҜд»ҘеӨ„зҗҶжӣҙеӨҡзҡ„ж•°жҚ®пјҢиҖҢдёҚз”ЁжҠҠе®ғ们йҖҒеҲ°иҖҒе№ҙд»ЈгҖӮCensum д№ҹжҳҫзӨәжңүеҫҲеӨҡиҝҮж—©жҸҗеҚҮгҖӮиҝҷе’ҢдёҖж®өж—¶й—ҙд№ӢеҗҺеҸ‘з”ҹзҡ„ full GC д№ҹжҳҜдёҖиҮҙзҡ„гҖӮдёҚе№ёзҡ„жҳҜпјҢиҝҷдәӣи®ҫзҪ®жІЎжңүиө·еҲ°д»»дҪ•дҪңз”ЁгҖӮ
жҺҘдёӢжқҘжҲ‘жғіпјҢжҲ–и®ёз”ҹдә§иҖ…еҲ¶йҖ ж•°жҚ®еӨӘеҝ«дәҶпјҢж¶Ҳиҙ№иҖ…жқҘдёҚеҸҠж¶Ҳиҙ№пјҢеҜјиҮҙиҝҷдәӣи®°еҪ•еңЁе®ғ们被еӨ„зҗҶеүҚе°ұиў«еӣһ收дәҶгҖӮжҲ‘е°қиҜ•еҮҸе°Ҹз”ҹдә§ж•°жҚ®зҡ„зәҝзЁӢж•°йҮҸпјҢйҷҚдҪҺж•°жҚ®дә§з”ҹзҡ„йҖҹеәҰпјҢеҗҢж—¶дҝқжҢҒж¶Ҳиҙ№иҖ…еҸ‘йҖҒз»ҷ ES зҡ„ж•°жҚ®жұ еӨ§е°ҸдёҚеҸҳгҖӮиҝҷдё»иҰҒжҳҜдҪҝз”ЁиғҢеҺӢпјҲbackpressureпјүжңәеҲ¶пјҢдёҚиҝҮе®ғд№ҹжІЎжңүиө·еҲ°дҪңз”ЁгҖӮ
иҝҷж—¶пјҢдёҖдёӘеҪ“ж—¶еӨҙи„‘иҝҳдҝқжҢҒеҶ·йқҷзҡ„еҗҢдәӢпјҢе»әи®®жҲ‘们еә”иҜҘеҒҡдёҖејҖе§Ӣе°ұеҒҡзҡ„дәӢжғ…пјҡжЈҖжҹҘе Ҷдёӯзҡ„ж•°жҚ®гҖӮжҲ‘们еҮҶеӨҮдәҶдёҖдёӘејҖеҸ‘зҺҜеўғзҡ„е®һдҫӢпјҢжӢҘжңүе’ҢзәҝдёҠе®һдҫӢзӣёеҗҢзҡ„ж•°жҚ®йҮҸпјҢе Ҷзҡ„еӨ§е°Ҹд№ҹеӨ§иҮҙзӣёеҗҢгҖӮжҠҠе®ғиҝһжҺҘеҲ° jnisualvm пјҢеҲҶжһҗеҶ…еӯҳзҡ„ж ·жң¬пјҢжҲ‘们еҸҜд»ҘзңӢеҲ°е ҶдёӯеҜ№иұЎзҡ„еӨ§иҮҙж•°йҮҸе’ҢеӨ§е°ҸгҖӮеӨ§зңјдёҖзңӢпјҢеҸҜд»ҘеҸ‘зҺ°жҲ‘们еҹҹдёӯAdеҜ№иұЎзҡ„ж•°йҮҸй«ҳзҡ„дёҚжӯЈеёёпјҢ并且еңЁзҙўеј•зҡ„иҝҮзЁӢдёӯдёҖзӣҙеңЁеўһй•ҝпјҢдёҖзӣҙеўһй•ҝеҲ°жҲ‘们еӨ„зҗҶзҡ„е№ҝе‘Ҡзҡ„ж•°йҮҸзә§еҲ«гҖӮдҪҶжҳҜвҖҰвҖҰиҝҷдёҚеә”иҜҘе•ҠгҖӮжҜ•з«ҹпјҢжҲ‘们йҖҡиҝҮ RX жҠҠиҝҷдәӣж•°жҚ®ж•ҙзҗҶжҲҗжөҒпјҢе°ұжҳҜдёәдәҶйҳІжӯўжҠҠжүҖжңүзҡ„ж•°жҚ®йғҪеҠ иҪҪеҲ°еҶ…еӯҳйҮҢгҖӮ
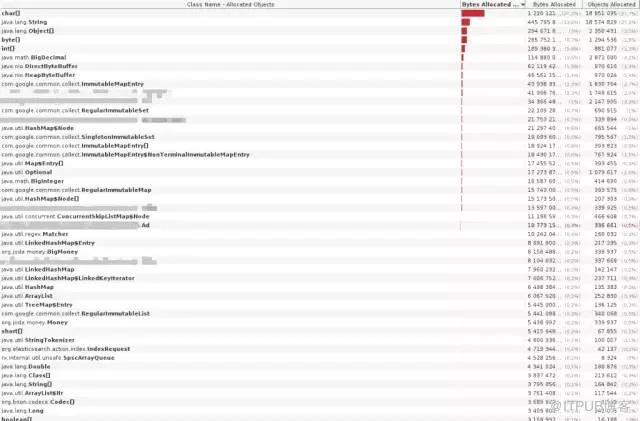
йҡҸзқҖжҖҖз–‘и¶ҠжқҘи¶ҠејәпјҢжҲ‘жЈҖжҹҘдәҶиҝҷйғЁеҲҶд»Јз ҒгҖӮе®ғ们жҳҜдёӨе№ҙеүҚеҶҷзҡ„пјҢд№ӢеҗҺе°ұжІЎжңүеҶҚиў«д»”з»Ҷзҡ„жЈҖжҹҘиҝҮгҖӮжһңдёҚ其然пјҢжҲ‘们е®һйҷ…дёҠжҠҠжүҖжңүзҡ„ж•°жҚ®йғҪеҠ иҪҪеҲ°дәҶеҶ…еӯҳйҮҢгҖӮиҝҷеҪ“然дёҚжҳҜж•…ж„Ҹзҡ„гҖӮз”ұдәҺеҪ“ж—¶еҜ№ RxJava зҡ„зҗҶи§ЈдёҚеӨҹе…ЁйқўпјҢжҲ‘们жғіи®©д»Јз Ғд»ҘдёҖз§Қзү№ж®Ҡзҡ„ж–№ејҸ并иЎҢиҝҗиЎҢгҖӮдёәдәҶд»Һ RX зҡ„дё»е·ҘдҪңжөҒдёӯеүҘзҰ»еҮәжқҘдёҖдәӣе·ҘдҪңпјҢжҲ‘们еҶіе®ҡз”ЁдёҖдёӘеҚ•зӢ¬зҡ„ executor и·‘ CompetableFutureгҖӮдҪҶжҳҜпјҢжҲ‘们еӣ жӯӨе°ұйңҖиҰҒзӯүеҫ…жүҖжңүзҡ„ CompetableFuture йғҪе·ҘдҪңе®ҢвҖҰвҖҰйҖҡиҝҮеӯҳеӮЁд»–们зҡ„еј•з”ЁпјҢ然еҗҺи°ғз”Ё join()гҖӮиҝҷеҜјиҮҙдёҖзӣҙеҲ°зҙўеј•е®ҢжҲҗпјҢжүҖжңүзҡ„ future зҡ„еј•з”ЁпјҢд»ҘеҸҠе®ғ们引用еҲ°зҡ„ж•°жҚ®пјҢйғҪдҝқжҢҒзқҖз”ҹеӯҳзҡ„зҠ¶жҖҒгҖӮиҝҷйҳ»жӯўдәҶеһғеңҫ收йӣҶеҷЁеҸҠж—¶зҡ„жҠҠе®ғ们清зҗҶжҺүгҖӮ
еҪ“然иҝҷжҳҜдёҖдёӘеҫҲж„ҡи ўзҡ„й”ҷиҜҜпјҢеҜ№дәҺеҸ‘зҺ°еҫ—иҝҷд№ҲжҷҡпјҢжҲ‘们д№ҹеҫҲжҒ¶еҝғгҖӮжҲ‘з”ҡиҮіжғіиө·еҫҲд№…д№ӢеүҚпјҢе…ідәҺиҝҷдёӘеә”з”ЁйңҖиҰҒ 12 GB зҡ„е Ҷзҡ„й—®йўҳпјҢжӣҫжңүдёӘз®Җзҹӯзҡ„и®Ёи®әгҖӮ12 GB зҡ„е ҶпјҢзЎ®е®һжңүзӮ№еӨ§дәҶгҖӮдҪҶжҳҜеҸҰдёҖж–№йқўпјҢиҝҷдәӣд»Јз Ғе·Із»ҸиҝҗиЎҢдәҶе°Ҷиҝ‘дёӨе№ҙдәҶпјҢжІЎжңүеҸ‘з”ҹиҝҮд»»дҪ•й—®йўҳгҖӮжҲ‘们еҸҜд»ҘеңЁеҪ“ж—¶зӣёеҜ№е®№жҳ“зҡ„дҝ®еӨҚе®ғпјҢ然иҖҢеҰӮжһңжҳҜдёӨе№ҙеүҚпјҢиҝҷеҸҜиғҪйңҖиҰҒжҲ‘们иҠұиҙ№жӣҙеӨҡзҡ„ж—¶й—ҙпјҢиҖҢдё”зӣёеҜ№дәҺиҠӮзңҒеҮ дёӘ G зҡ„еҶ…еӯҳпјҢеҪ“ж—¶жҲ‘们жңүеҫҲеӨҡжӣҙйҮҚиҰҒзҡ„е·ҘдҪңгҖӮ
еӣ жӯӨпјҢиҷҪ然д»ҺзәҜжҠҖжңҜзҡ„и§’еәҰжқҘиҜҙпјҢиҝҷдёӘй—®йўҳеҰӮжӯӨй•ҝж—¶й—ҙжІЎи§ЈеҶізЎ®е®һеҫҲдёўдәәпјҢ然иҖҢд»ҺжҲҳз•ҘжҖ§зҡ„и§’еәҰжқҘзңӢпјҢжҲ–и®ёз•ҷзқҖиҝҷдёӘжөӘиҙ№еҶ…еӯҳзҡ„й—®йўҳдёҚз®ЎпјҢжҳҜжӣҙеҠЎе®һзҡ„йҖүжӢ©гҖӮеҪ“然пјҢеҸҰдёҖдёӘиҖғиҷ‘е°ұжҳҜиҝҷдёӘй—®йўҳдёҖж—ҰеҸ‘з”ҹпјҢдјҡйҖ жҲҗд»Җд№ҲеҪұе“ҚгҖӮжҲ‘们еҮ д№ҺжІЎжңүеҜ№з”ЁжҲ·йҖ жҲҗд»»дҪ•еҪұе“ҚпјҢдёҚиҝҮз»“жһңжңүеҸҜиғҪжӣҙзіҹзі•гҖӮиҪҜ件е·ҘзЁӢе°ұжҳҜжқғиЎЎеҲ©ејҠпјҢеҶіе®ҡдёҚеҗҢд»»еҠЎзҡ„дјҳе…Ҳзә§д№ҹдёҚдҫӢеӨ–гҖӮ
жңүдәҶжӣҙеӨҡдҪҝз”Ё RX зҡ„з»ҸйӘҢд№ӢеҗҺпјҢжҲ‘们еҸҜд»ҘеҫҲз®ҖеҚ•зҡ„и§ЈеҶі ComplerableFurue зҡ„й—®йўҳгҖӮйҮҚеҶҷд»Јз ҒпјҢеҸӘдҪҝз”Ё RXпјӣеңЁйҮҚеҶҷзҡ„иҝҮзЁӢдёӯпјҢеҚҮзә§еҲ° RX2пјӣзңҹжӯЈзҡ„жөҒејҸеӨ„зҗҶж•°жҚ®пјҢиҖҢдёҚжҳҜеңЁеҶ…еӯҳйҮҢ收йӣҶе®ғ们гҖӮиҝҷдәӣж”№еҠЁйҖҡиҝҮ code review д№ӢеҗҺпјҢйғЁзҪІеҲ°ејҖеҸ‘зҺҜеўғиҝӣиЎҢжөӢиҜ•гҖӮи®©жҲ‘们еҗғжғҠзҡ„жҳҜпјҢеә”з”ЁжүҖйңҖзҡ„еҶ…еӯҳдёқжҜ«жІЎжңүеҮҸе°‘гҖӮеҶ…еӯҳжҠҪж ·жҳҫзӨәпјҢзӣёиҫғд№ӢеүҚпјҢеҶ…еӯҳдёӯе№ҝе‘ҠеҜ№иұЎзҡ„ж•°йҮҸжңүжүҖеҮҸе°‘гҖӮиҖҢдё”еҜ№иұЎзҡ„ж•°йҮҸзҺ°еңЁдёҚдјҡдёҖзӣҙеўһй•ҝпјҢжңүж—¶д№ҹдјҡдёӢйҷҚпјҢеӣ жӯӨ他们дёҚжҳҜе…ЁйғЁеңЁеҶ…еӯҳйҮҢ收йӣҶзҡ„гҖӮиҝҳжҳҜиҖҒй—®йўҳпјҢзңӢиө·жқҘиҝҷдәӣж•°жҚ®д»Қ然没жңүзңҹжӯЈзҡ„иў«еҪ’йӣҶжҲҗжөҒгҖӮ
зӣёе…ізҡ„е…ій”®иҜҚеҲҡжүҚе·Із»ҸжҸҗеҲ°дәҶпјҡиғҢеҺӢгҖӮеҪ“ж•°жҚ®иў«жөҒејҸеӨ„зҗҶпјҢз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…зҡ„йҖҹеәҰдёҚеҗҢжҳҜеҫҲжӯЈеёёзҡ„гҖӮеҰӮжһңз”ҹдә§иҖ…жҜ”ж¶Ҳиҙ№иҖ…еҝ«пјҢ并且дёҚиғҪжҠҠйҖҹеәҰйҷҚдёӢжқҘпјҢе®ғе°ұдјҡдёҖзӣҙз”ҹдә§и¶ҠжқҘи¶ҠеӨҡзҡ„ж•°жҚ®пјҢж¶Ҳиҙ№иҖ…ж— жі•д»ҘеҗҢж ·зҡ„йҖҹеәҰеӨ„зҗҶжҺү他们гҖӮзҺ°иұЎе°ұжҳҜжңӘеӨ„зҗҶж•°жҚ®зҡ„зј“еӯҳдёҚж–ӯеўһй•ҝпјҢиҖҢиҝҷе°ұжҳҜжҲ‘们еә”з”ЁдёӯзңҹжӯЈеҸ‘з”ҹзҡ„гҖӮиғҢеҺӢе°ұжҳҜдёҖеҘ—жңәеҲ¶пјҢе®ғе…Ғи®ёдёҖдёӘиҫғж…ўзҡ„ж¶Ҳиҙ№иҖ…е‘ҠиҜүиҫғеҝ«зҡ„з”ҹдә§иҖ…еҺ»йҷҚйҖҹгҖӮ
жҲ‘们зҡ„зҙўеј•зі»з»ҹжІЎжңүиғҢеҺӢзҡ„жҰӮеҝөпјҢиҝҷеңЁд№ӢеүҚжІЎд»Җд№Ҳй—®йўҳпјҢеҸҚжӯЈжҲ‘们жҠҠж•ҙдёӘзҙўеј•йғҪдҝқеӯҳеҲ°еҶ…еӯҳйҮҢдәҶгҖӮдёҖж—ҰжҲ‘们解еҶідәҶд№ӢеүҚзҡ„й—®йўҳпјҢејҖе§ӢзңҹжӯЈзҡ„жөҒејҸеӨ„зҗҶж•°жҚ®пјҢзјәе°‘иғҢеҺӢзҡ„й—®йўҳе°ұеҸҳеҫ—еҫҲжҳҺжҳҫдәҶгҖӮ
иҝҷдёӘжЁЎејҸжҲ‘еңЁи§ЈеҶіжҖ§иғҪй—®йўҳж—¶и§ҒиҝҮеҫҲеӨҡж¬ЎдәҶпјҡи§ЈеҶідёҖдёӘй—®йўҳж—¶дјҡжө®зҺ°еҸҰдёҖдёӘдҪ з”ҡиҮіжІЎжңүеҗ¬иҜҙиҝҮзҡ„й—®йўҳпјҢеӣ дёәе…¶д»–й—®йўҳжҠҠе®ғйҡҗи—Ҹиө·жқҘдәҶгҖӮеҰӮжһңдҪ зҡ„жҲҝеӯҗз»Ҹеёёиў«ж·№пјҢдҪ дёҚдјҡжіЁж„ҸеҲ°е®ғжңүзҒ«зҒҫйҡҗжӮЈгҖӮ
еңЁ RxJava 2 йҮҢпјҢеҺҹжқҘзҡ„ Observable зұ»иў«жӢҶжҲҗдәҶдёҚж”ҜжҢҒиғҢеҺӢзҡ„ Observable е’Ңж”ҜжҢҒиғҢеҺӢзҡ„ FlowableгҖӮе№ёиҝҗзҡ„жҳҜпјҢжңүдёҖдәӣз®ҖеҚ•зҡ„еҠһжі•пјҢеҸҜд»ҘејҖз®ұеҚіз”Ёзҡ„жҠҠдёҚж”ҜжҢҒиғҢеҺӢзҡ„ Observable ж”№йҖ жҲҗж”ҜжҢҒиғҢеҺӢзҡ„ FlowableгҖӮе…¶дёӯеҢ…еҗ«д»Һйқһе“Қеә”ејҸзҡ„иө„жәҗжҜ”еҰӮ Iterable еҲӣе»ә FlowableгҖӮжҠҠиҝҷдәӣ Flowable иһҚеҗҲиө·жқҘеҸҜд»Ҙз”ҹжҲҗеҗҢж ·ж”ҜжҢҒиғҢеҺӢзҡ„ FlowableпјҢеӣ жӯӨеҸӘиҰҒеҝ«йҖҹи§ЈеҶідёҖдёӘзӮ№пјҢж•ҙдёӘзі»з»ҹе°ұжңүдәҶиғҢеҺӢзҡ„ж”ҜжҢҒгҖӮ
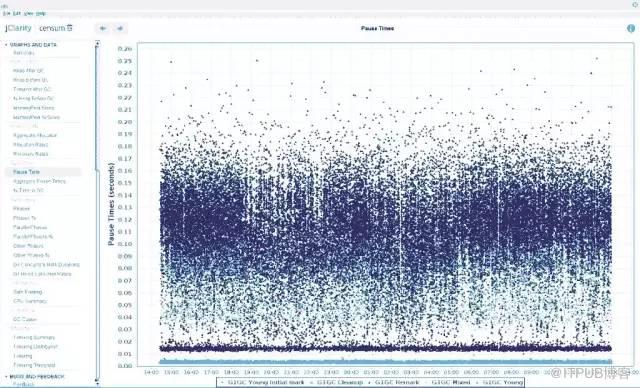
жңүдәҶиҝҷдёӘж”№еҠЁд№ӢеҗҺпјҢжҲ‘们жҠҠе Ҷд»Һ 12 GB еҮҸе°‘еҲ°дәҶ 3 GB пјҢеҗҢж—¶и®©зі»з»ҹдҝқжҢҒе’Ңд№ӢеүҚеҗҢж ·зҡ„йҖҹеәҰгҖӮжҲ‘们д»Қ然жҜҸйҡ”ж•°е°Ҹж—¶е°ұдјҡжңүдёҖж¬ЎжҡӮеҒңй•ҝиҫҫ 2 з§’зҡ„ full GCпјҢдёҚиҝҮиҝҷжҜ”жҲ‘们д№ӢеүҚи§ҒеҲ°зҡ„ 20 з§’зҡ„жҡӮеҒңпјҲиҝҳжңүзі»з»ҹеҙ©жәғпјүиҰҒеҘҪеӨҡдәҶгҖӮ
дҪҶжҳҜпјҢж•…дәӢеҲ°жӯӨиҝҳжІЎжңүз»“жқҹгҖӮжЈҖжҹҘ GC зҡ„ж—Ҙеҝ—пјҢжҲ‘们注ж„ҸеҲ°еӨ§йҮҸзҡ„иҝҮж—©жҸҗеҚҮпјҢеҚ еҲ° 70%гҖӮе°Ҫз®ЎжҖ§иғҪе·Із»ҸеҸҜд»ҘжҺҘеҸ—дәҶпјҢжҲ‘们д№ҹе°қиҜ•еҺ»и§ЈеҶіиҝҷдёӘй—®йўҳпјҢеёҢжңӣд№ҹи®ёеҸҜд»ҘеҗҢж—¶и§ЈеҶі full GC зҡ„й—®йўҳгҖӮ
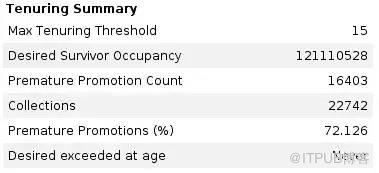
еҰӮжһңдёҖдёӘеҜ№иұЎзҡ„з”ҹе‘Ҫе‘ЁжңҹеҫҲзҹӯпјҢдҪҶжҳҜе®ғд»Қ然жҷӢеҚҮеҲ°дәҶиҖҒе№ҙд»ЈпјҢжҲ‘们е°ұжҠҠиҝҷз§ҚзҺ°иұЎеҸ«еҒҡиҝҮж—©жҸҗеҚҮпјҲpremature tenuringпјүпјҲжҲ–иҖ…еҸ«иҝҮж—©еҚҮзә§пјүгҖӮиҖҒе№ҙд»ЈйҮҢзҡ„еҜ№иұЎйҖҡеёёйғҪжҜ”иҫғеӨ§пјҢдҪҝз”ЁдёҺж–°з”ҹд»ЈдёҚеҗҢзҡ„ GC з®—жі•пјҢиҖҢиҝҷдәӣиҝҮж—©жҸҗеҚҮзҡ„еҜ№иұЎеҚ жҚ®дәҶиҖҒе№ҙд»Јзҡ„з©әй—ҙпјҢжүҖд»Ҙе®ғ们дјҡеҪұе“Қ GC зҡ„жҖ§иғҪгҖӮеӣ жӯӨпјҢжҲ‘们жғіз«ӯеҠӣйҒҝе…ҚиҝҮж—©жҸҗеҚҮгҖӮ
жҲ‘们зҡ„еә”з”ЁеңЁзҙўеј•зҡ„иҝҮзЁӢдёӯдјҡдә§з”ҹеӨ§йҮҸзҹӯз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎпјҢеӣ жӯӨдёҖдәӣиҝҮж—©жҸҗеҚҮжҳҜжӯЈеёёзҡ„пјҢдҪҶжҳҜдёҚеә”иҜҘеҰӮжӯӨдёҘйҮҚгҖӮеҪ“еә”з”Ёдә§з”ҹеӨ§йҮҸзҹӯз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎж—¶пјҢиғҪжғіеҲ°зҡ„第дёҖ件дәӢе°ұжҳҜз®ҖеҚ•зҡ„еўһеҠ ж–°з”ҹд»Јзҡ„з©әй—ҙгҖӮй»ҳи®Өжғ…еҶөдёӢпјҢG1 зҡ„ GC еҸҜд»ҘиҮӘеҠЁзҡ„и°ғж•ҙж–°з”ҹд»Јзҡ„з©әй—ҙпјҢе…Ғи®ёж–°з”ҹд»ЈдҪҝз”Ёе ҶеҶ…еӯҳзҡ„ 5% иҮі 60%гҖӮжҲ‘жіЁж„ҸеҲ°иҝҗиЎҢзҡ„еә”з”ЁйҮҢпјҢж–°з”ҹд»Је’ҢиҖҒе№ҙд»Јзҡ„жҜ”дҫӢдёҖзӣҙеңЁдёҖдёӘеҫҲе®Ҫзҡ„е№…еәҰйҮҢеҸҳеҢ–пјҢдёҚиҝҮжҲ‘дҫқ然еҠЁжүӢдҝ®ж”№дәҶдёӨдёӘеҸӮж•°пјҡ-XX:G1NewSizePercent=40 е’Ң -XX:G1MaxNewSizePercent=90зңӢзңӢдјҡеҸ‘з”ҹд»Җд№ҲгҖӮиҝҷжІЎиө·дҪңз”ЁпјҢз”ҡиҮіи®©дәӢжғ…еҸҳеҫ—жӣҙзіҹзі•дәҶпјҢеә”з”ЁдёҖеҗҜеҠЁе°ұи§ҰеҸ‘дәҶ full GCгҖӮжҲ‘д№ҹе°қиҜ•дәҶе…¶д»–зҡ„жҜ”дҫӢпјҢдёҚиҝҮжңҖеҘҪзҡ„жғ…еҶөе°ұжҳҜеҸӘеўһеҠ G1MaxNewSizePercentиҖҢдёҚдҝ®ж”№жңҖе°ҸеҖјгҖӮиҝҷиө·дәҶдҪңз”ЁпјҢеӨ§жҰӮе’Ңй»ҳи®ӨеҖјзҡ„иЎЁзҺ°е·®дёҚеӨҡпјҢд№ҹжІЎжңүеҸҳеҘҪгҖӮ
е°қиҜ•дәҶеҫҲеӨҡеҠһжі•еҗҺпјҢд№ҹжІЎжңүеҸ–еҫ—д»Җд№ҲжҲҗе°ұпјҢжҲ‘е°ұж”ҫејғдәҶпјҢ然еҗҺз»ҷ Kirk Pepperdine еҸ‘дәҶе°ҒйӮ®д»¶гҖӮд»–жҳҜдҪҚеҫҲзҹҘеҗҚзҡ„ Java жҖ§иғҪ专家пјҢжҲ‘зў°е·§еңЁ Allegro дёҫеҠһзҡ„ Devoxx дјҡи®®зҡ„и®ӯз»ғиҜҫзЁӢйҮҢи®ӨиҜҶдәҶд»–гҖӮйҖҡиҝҮжҹҘзңӢ GC зҡ„ж—Ҙеҝ—д»ҘеҸҠеҮ е°ҒйӮ®д»¶зҡ„дәӨжөҒпјҢKirk е»әи®®иҜ•иҜ•и®ҫзҪ® -XX:G1MixedGCLiveThresholdPercent=100гҖӮиҝҷдёӘи®ҫзҪ®еә”иҜҘдјҡејәеҲ¶ G1 GC еңЁ mixed GC ж—¶дёҚеҺ»иҖғиҷ‘е®ғ们被填充дәҶеӨҡе°‘пјҢиҖҢжҳҜејәеҲ¶жё…зҗҶжүҖжңүзҡ„иҖҒе№ҙд»ЈпјҢеӣ жӯӨд№ҹеҗҢж—¶жё…зҗҶдәҶд»Һж–°з”ҹд»ЈиҝҮж—©жҸҗеҚҮзҡ„еҜ№иұЎгҖӮиҝҷеә”иҜҘдјҡйҳ»жӯўиҖҒе№ҙд»Јиў«еЎ«ж»Ўд»ҺиҖҢдә§з”ҹдёҖж¬Ў full GCгҖӮ然иҖҢпјҢеңЁиҝҗиЎҢдёҖж®өж—¶й—ҙд»ҘеҗҺпјҢжҲ‘们еҶҚж¬ЎжғҠ讶зҡ„еҸ‘зҺ°дәҶдёҖж¬Ў full GCгҖӮKirk жҺЁж–ӯиҜҙд»–еңЁе…¶д»–еә”з”ЁйҮҢд№ҹи§ҒеҲ°иҝҮиҝҷз§Қжғ…еҶөпјҢе®ғжҳҜ G1 GC зҡ„дёҖдёӘ bugпјҡmixed GC жҳҫ然没жңүжё…зҗҶжүҖжңүзҡ„еһғеңҫпјҢи®©е®ғ们дёҖзӣҙе Ҷз§ҜзӣҙеҲ°дә§з”ҹ full GCгҖӮд»–иҜҙд»–е·Із»ҸжҠҠиҝҷдёӘй—®йўҳйҖҡзҹҘдәҶ OracleпјҢдёҚиҝҮ他们еқҡз§°жҲ‘们и§ӮеҜҹеҲ°зҡ„иҝҷдёӘзҺ°иұЎдёҚжҳҜдёҖдёӘ bugпјҢиҖҢжҳҜжӯЈеёёзҡ„гҖӮ
жҲ‘们жңҖеҗҺеҒҡзҡ„е°ұжҳҜжҠҠеә”з”Ёзҡ„еҶ…еӯҳи°ғеӨ§дәҶдёҖзӮ№зӮ№пјҲд»Һ 3 GB еҲ° 4 GBпјүпјҢ然еҗҺ full GC е°ұж¶ҲеӨұдәҶгҖӮжҲ‘们д»Қ然и§ӮеҜҹеҲ°еӨ§йҮҸзҡ„иҝҮж—©жҸҗеҚҮпјҢдёҚиҝҮ既然жҖ§иғҪжҳҜжІЎй—®йўҳзҡ„пјҢжҲ‘们е°ұдёҚеңЁд№ҺиҝҷдәӣдәҶгҖӮдёҖдёӘжҲ‘们еҸҜд»Ҙе°қиҜ•зҡ„йҖүйЎ№жҳҜиҪ¬жҚўеҲ° GMSпјҲConcurrent Mark SweepпјүGCпјҢдёҚиҝҮз”ұдәҺе®ғе·Із»Ҹиў«еәҹејғдәҶпјҢжҲ‘们иҝҳжҳҜе°ҪйҮҸдёҚеҺ»дҪҝз”Ёе®ғгҖӮ
йӮЈд№ҲиҝҷдёӘж•…дәӢзҡ„еҜ“ж„ҸжҳҜд»Җд№Ҳе‘ўпјҹйҰ–е…ҲпјҢжҖ§иғҪй—®йўҳеҫҲе®№жҳ“и®©дҪ иҜҜе…Ҙжӯ§йҖ”гҖӮдёҖејҖе§ӢзңӢиө·жқҘжҳҜ ZooKeeper жҲ–иҖ… зҪ‘з»ңзҡ„й—®йўҳпјҢжңҖеҗҺеҸ‘зҺ°жҳҜжҲ‘们代з Ғзҡ„й—®йўҳгҖӮеҚідҪҝж„ҸиҜҶеҲ°дәҶиҝҷдёҖзӮ№пјҢжҲ‘йҰ–е…ҲйҮҮеҸ–зҡ„жҺӘж–Ҫд№ҹжІЎжңүиҖғиҷ‘е‘Ёе…ЁгҖӮдёәдәҶйҳІжӯў full GCпјҢжҲ‘еңЁжЈҖжҹҘеҲ°еә•еҸ‘з”ҹдәҶд»Җд№Ҳд№ӢеүҚе°ұејҖе§Ӣи°ғдјҳ GCгҖӮиҝҷжҳҜдёҖдёӘеёёи§Ғзҡ„йҷ·йҳұпјҢеӣ жӯӨи®°дҪҸпјҡеҚідҪҝдҪ жңүдёҖдёӘзӣҙи§үеҺ»еҒҡд»Җд№ҲпјҢе…ҲжЈҖжҹҘдёҖдёӢеҲ°еә•еҸ‘з”ҹдәҶд»Җд№ҲпјҢеҶҚжЈҖжҹҘдёҖйҒҚпјҢйҳІжӯўжөӘиҙ№ж—¶й—ҙеҺ»й”ҷиҜҜзҡ„й—®йўҳгҖӮ
第дәҢжқЎпјҢжҖ§иғҪй—®йўҳеӨӘйҡҫи§ЈеҶідәҶгҖӮжҲ‘们зҡ„д»Јз ҒжңүиүҜеҘҪзҡ„жөӢиҜ•иҰҶзӣ–зҺҮпјҢиҖҢдё”иҝҗиЎҢзҡ„зү№еҲ«еҘҪпјҢдҪҶжҳҜе®ғд№ҹжІЎжңүж»Ўи¶іжҖ§иғҪзҡ„иҰҒжұӮпјҢе®ғеңЁејҖе§Ӣзҡ„ж—¶еҖҷе°ұжІЎжңүжё…жҷ°зҡ„е®ҡд№үеҘҪгҖӮжҖ§иғҪй—®йўҳзӣҙеҲ°йғЁзҪІд№ӢеҗҺеҫҲд№…жүҚжө®зҺ°еҮәжқҘгҖӮз”ұдәҺйҖҡеёёеҫҲйҡҫзңҹе®һзҡ„еҶҚзҺ°дҪ зҡ„з”ҹдә§зҺҜеўғпјҢдҪ з»Ҹеёёиў«иҝ«еңЁз”ҹдә§зҺҜеўғжөӢиҜ•жҖ§иғҪпјҢеҚідҪҝйӮЈеҗ¬иө·жқҘйқһеёёзіҹзі•гҖӮ
第дёүжқЎпјҢи§ЈеҶідёҖдёӘй—®йўҳжңүеҸҜиғҪеј•еҸ‘еҸҰдёҖдёӘжҪңеңЁй—®йўҳзҡ„жө®зҺ°пјҢејәиҝ«дҪ дёҚж–ӯжҢ–зҡ„жҜ”дҪ йў„жғізҡ„жӣҙж·ұгҖӮжҲ‘们没жңүиғҢеҺӢзҡ„дәӢе®һи¶ід»Ҙдёӯж–ӯиҝҷдёӘзі»з»ҹпјҢдҪҶжҳҜзӣҙеҲ°жҲ‘们解еҶідәҶеҶ…еӯҳжі„жјҸзҡ„й—®йўҳеҗҺпјҢе®ғжүҚжө®зҺ°гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңJavaеҶ…еӯҳжі„жјҸжҺ’жҹҘиҝҮзЁӢзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ