您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家介绍用Python代码实现5种最好的、简单的数据可视化分别是怎样的,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
数据可视化是数据科学家工作的重要组成部分。在项目的早期阶段,您通常会进行探索性数据分析(EDA)以获得对数据的一些见解。创建可视化确实有助于使事情更清晰、更容易理解,尤其是对于更大、更高维度的数据集。在项目即将结束时,能够以清晰、简洁和引人注目的方式呈现您的最终结果非常重要,以便您的受众(通常是非技术客户)能够理解。
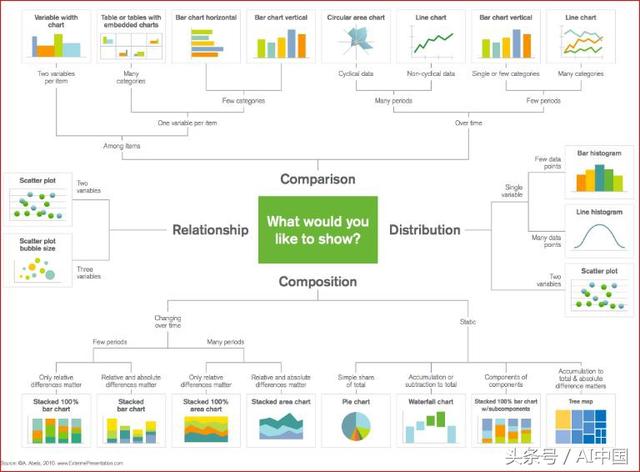
Matplotlib是一个流行的Python库,可用于轻松创建数据可视化。但是,每次执行新项目时,设置数据、参数、数字和绘图都会变得相当混乱和乏味。在这篇博文中,我们将看看6个数据可视化,并使用Python的Matplotlib为它们编写一些快速简便的函数。与此同时,这是一个很好的图表,可以为工作选择正确的可视化!
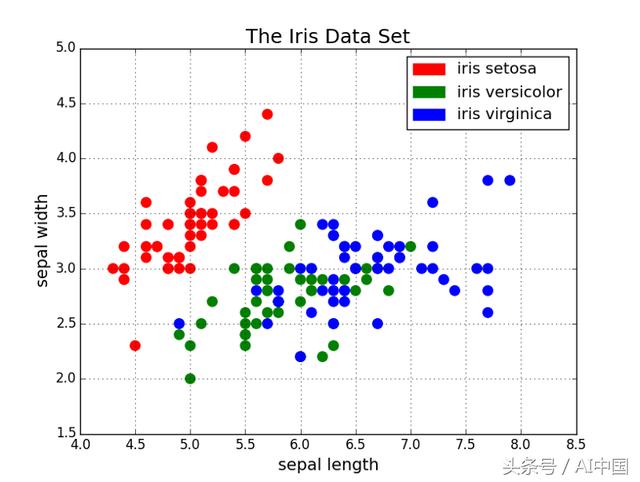
散点图
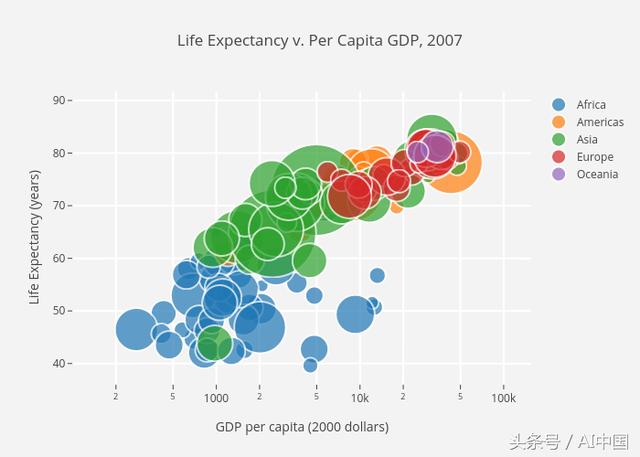
散点图非常适合显示两个变量之间的关系,因为您可以直接查看数据的原始分布。您还可以通过对组进行颜色编码来简单地查看不同数据组的这种关系,如下图所示。想要想象三个变量之间的关系?没问题!只需使用另一个参数(如点大小)来编码第三个变量,我们可以在下面的第二个图中看到。
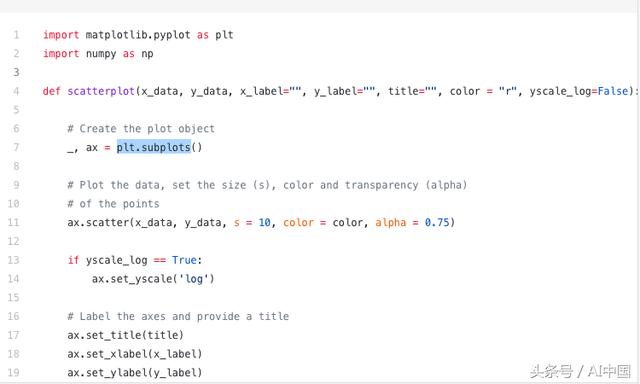
现在来看代码。我们首先使用别名“plt”导入Matplotlib的pyplot。为了创建一个新的情节图,我们调用plt.subplots()。将x轴和y轴数据传递给函数,然后将它们传递给ax.scatter()以绘制散点图。我们还可以设置磅值、点颜色和Alpha透明度。您甚至可以将y轴设置为对数刻度。然后专门为图形设置标题和轴标签。这很容易使用一个端到端创建散点图的函数!
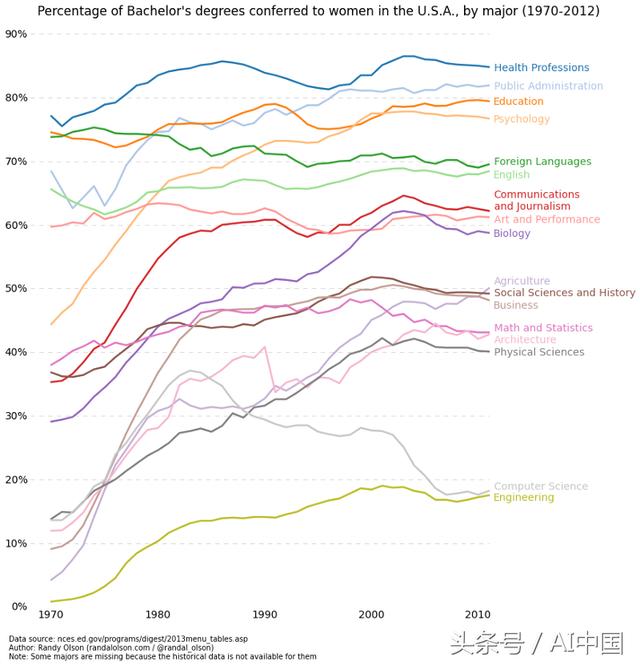
线形图
当您可以清楚地看到一个变量与另一个变量差异很大,即它们具有高协方差时,最好使用线图。我们来看看下图来说明,可以清楚地看到,所有专业的百分比随时间变化很大。使用散点图绘制这些图形会非常混乱,这使得我们很难真正理解并看到发生了什么。线图非常适合这种情况,因为它们基本上可以快速总结两个变量的协方差(百分比和时间)。同样,我们也可以通过颜色编码进行分组。
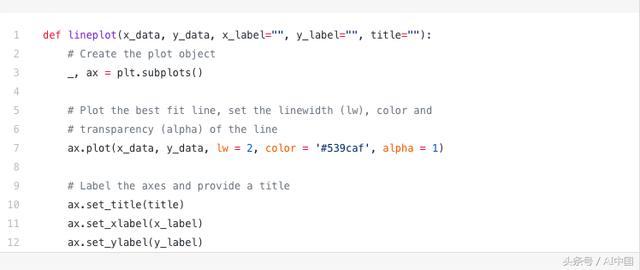
这是线形图的代码。它与上面的散点非常相似。只有一些变量的微小变化。
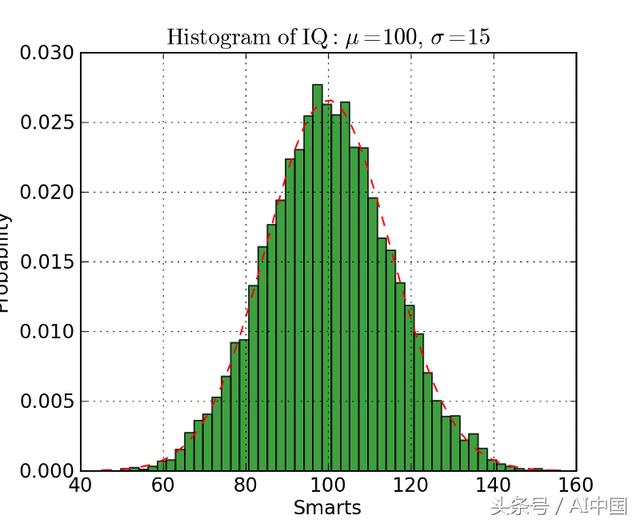
直方图
直方图可用于查看(或实际发现)数据点的分布。查看下面的直方图,我们绘制频率与IQ直方图。我们可以清楚地看到中心的浓度和中位数。我们还可以看到它遵循高斯分布。使用条(而不是散点)确实可以清楚地看到每个箱的频率之间的相对差异。使用分档(离散化)确实有助于我们看到“更大的图像”,而如果我们使用所有数据点而没有离散分档,可视化中可能会有很多噪声,这使得很难看到真正发生了什么。
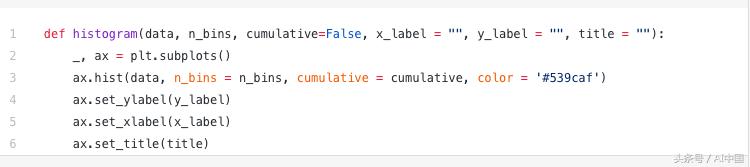
Matplotlib中直方图的代码如下所示。有两个参数需要注意。首先,n_bins参数控制我们的直方图所需的离散区数。更多的bins会给我们更好的信息,但也可能会引入噪音;另一方面,较少的bins给我们提供了更多的“鸟瞰图”,并且没有更精细的细节,更能了解正在发生的事情。其次,累积参数是一个布尔值,它允许我们选择我们的直方图是否累积。这基本上是选择概率密度函数(PDF)或累积密度函数(CDF)。
想象一下,我们想要比较数据中两个变量的分布。有人可能会认为你必须制作两个单独的直方图并将它们并排放置以进行比较。但是,实际上有更好的方法:我们可以用不同的透明度覆盖直方图。看看下图,统一分布设置为透明度为0.5,以便我们可以看到它背后的内容。这允许用户直接在同一图上查看两个分布。
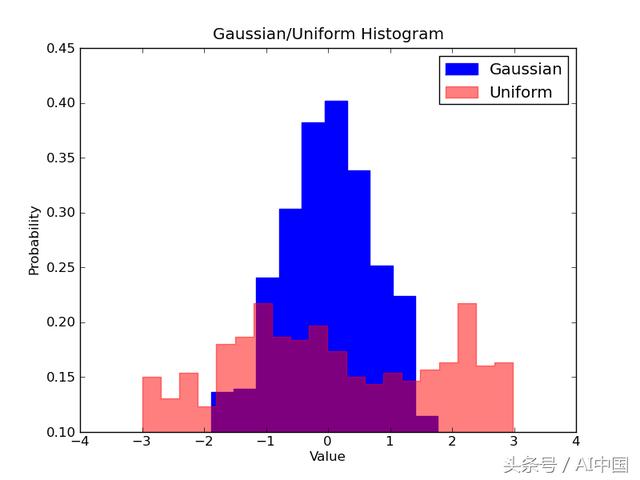
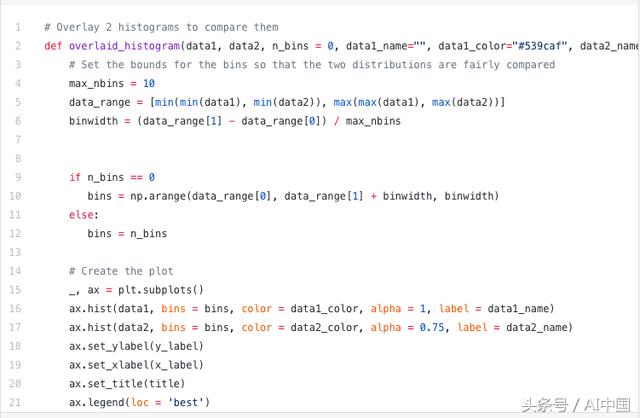
在代码中为叠加的直方图设置了一些东西。首先,我们设置水平范围以适应两个变量分布。根据这个范围和所需的箱数,我们实际上可以计算每个箱的宽度。最后,我们在同一个图上绘制两个直方图,其中一个直方图略微透明。
条形图
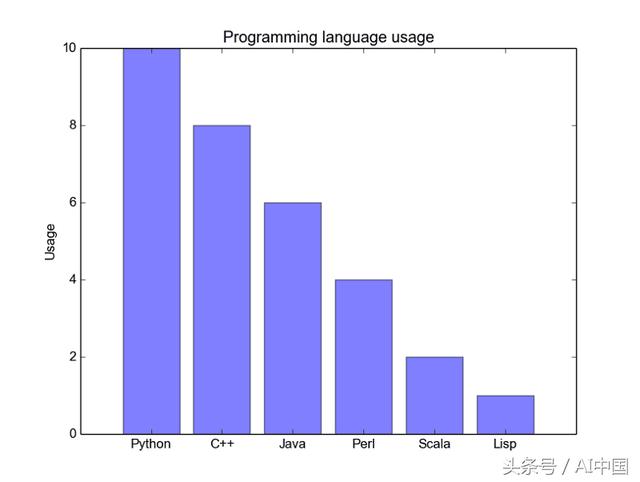
当您尝试可视化具有少量(可能<10个)类别的分类数据时,条形图最有效。如果我们的类别太多,那么图中的条形图将非常混乱并且难以理解。它们适用于分类数据,因为您可以根据条形图的大小(即幅度)轻松查看类别之间的差异;类别也很容易划分颜色编码。我们将看到3种不同类型的条形图:常规、分组和堆叠。随着我们的进展,请查看下图中的代码。
常规的条形图在下面的第一个图中。在barplot()函数中,x_data表示x轴上的代码,y_data表示y轴上的条形高度。误差条是以每个条形为中心的额外线条,可以绘制以显示标准偏差。
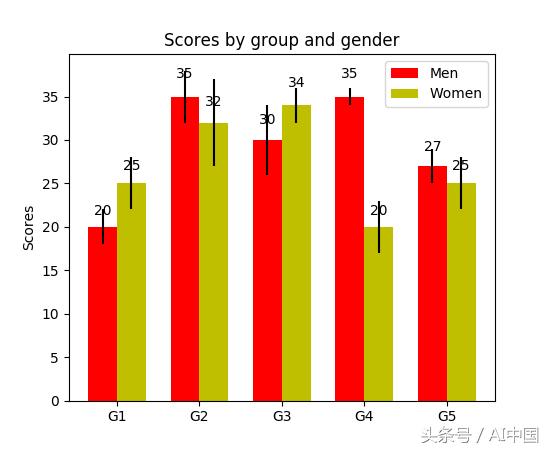
分组条形图允许我们比较多个分类变量。看看下面的第二个条形图。我们比较的第一个变量是分数如何按组(G1,G2,......等组)变化。我们还将性别本身与颜色代码进行比较。看一下代码,y_data_list变量现在实际上是一个列表,其中每个子列表代表一个不同的组。然后我们遍历每个组,对于每个组,我们在x轴上绘制每个刻度线的条形图;每组也有颜色编码。
堆积条形图非常适合可视化不同变量的分类构成。在下面的堆积条形图中,我们将比较日常的服务器负载。通过颜色编码堆栈,我们可以轻松查看和了解哪些服务器每天工作最多,以及负载如何与所有日期的其他服务器进行比较。此代码遵循与分组条形图相同的样式。我们遍历每个组,除了这次我们在旧组之上而不是在它们旁边绘制新条。
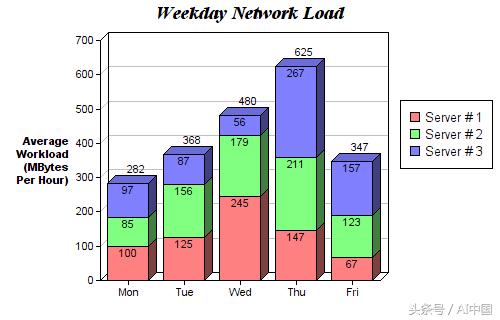

直方图
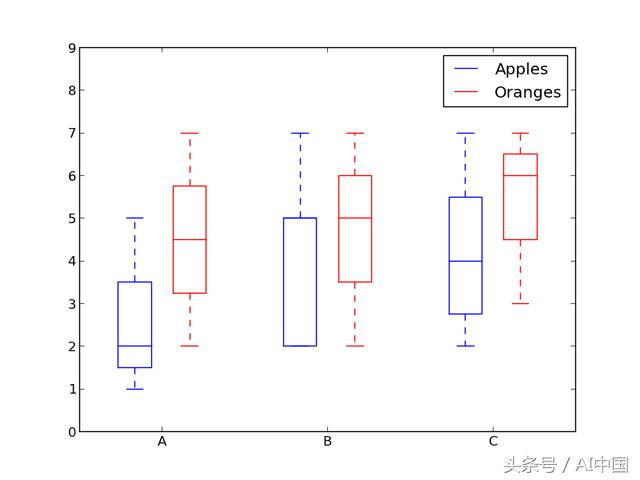
我们之前查看过直方图,这些直方图非常适合可视化变量的分布。但是如果我们需要更多信息呢?也许我们想要更清晰地看待标准偏差?也许中位数与均值有很大不同,因此我们有很多异常值?如果存在这样的偏差并且许多值集中在一边怎么办?
这就是箱形图出现的原因。箱形图给出了上述所有信息。实线框的底部和顶部始终是第一和第三四分位数(即数据的25%和75%),框内的频带始终是第二个四分位数(中位数)。晶须(即带有条形末端的虚线)从盒子中伸出,以显示数据的范围。
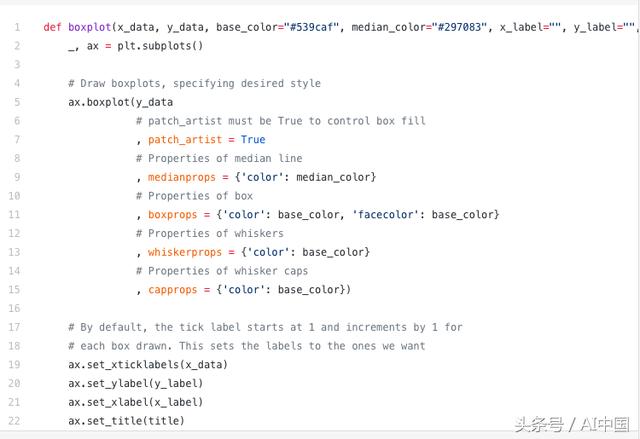
由于为每个组/变量绘制了框图,因此很容易设置。x_data是组/变量的列表。Matplotlib函数boxplot()为y_data的每一列或序列y_data中的每个向量创建一个盒子图;因此,x_data中的每个值对应于y_data中的列/向量。我们所要设定的只是情节的美学。
关于用Python代码实现5种最好的、简单的数据可视化分别是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。