жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іSparkжҖҺж ·еә”з”ЁHanLPеҜ№дёӯж–ҮиҜӯж–ҷиҝӣиЎҢж–Үжң¬жҢ–жҺҳпјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
иҪҜ件пјҡIDEA2014гҖҒMavenгҖҒHanLPгҖҒJDKпјӣ
з”ЁеҲ°зҡ„зҹҘиҜҶпјҡHanLPгҖҒSpark TF-IDFгҖҒSpark kmeansгҖҒSpark mapPartition;
з”ЁеҲ°зҡ„ж•°жҚ®йӣҶпјҡhttp://www.threedweb.cn/thread-1288-1-1.htmlпјҲдёҚйңҖиҰҒдёӢиҪҪпјҢе·Із»ҸеҢ…еҗ«еңЁе·ҘзЁӢйҮҢйқўпјүпјӣ
е·ҘзЁӢдёӢиҪҪпјҡhttps://github.com/fansy1990/hanlp-test гҖӮ
1. й—®йўҳжҸҸиҝ°
зҺ°еңЁжңүдёҖдёӘдёӯж–Үж–Үжң¬ж•°жҚ®йӣҶпјҢиҝҷдёӘж•°жҚ®йӣҶе·Із»ҸеҜ№е…¶дёӯзҡ„ж–Үжң¬еҒҡдәҶеҲҶзұ»пјҢеҰӮдёӢпјҡ
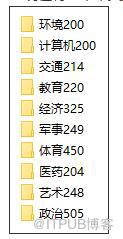
е…¶дёӯжҜҸдёӘж–Ү件еӨ№дёӯеҗ«жңүдёӘж•°дёҚзӯүзҡ„ж–Ү件пјҢжҜ”еҰӮзҺҜеўғжңү200дёӘпјҢиүәжңҜжңү248дёӘпјӣеҗҢж—¶пјҢжҜҸдёӘж–Ү件зҡ„еҶ…е®№еҹәжң¬дёҠе°ұжҳҜдёҖдәӣж–°й—»жҠҘйҒ“жҲ–иҖ…дёӯж–ҮжҸҸиҝ°пјҢеҰӮдёӢпјҡ
зҺ°еңЁйңҖиҰҒеҒҡзҡ„е°ұжҳҜпјҢжҠҠиҝҷдәӣж–ҮжЎЈиҝӣиЎҢиҒҡзұ»пјҢзңӢе…¶е’ҢеҺҹе§Ӣз»ҷе®ҡзҡ„зұ»еҲ«зҡ„йҮҚеҗҲеәҰжңүеӨҡе°‘пјҢиҝҷж ·д№ҹеҸҜд»ҘеҸҚиҝҮжқҘйӘҢиҜҒжҲ‘们иҒҡзұ»з®—жі•зҡ„жӯЈзЎ®еәҰгҖӮ
2. и§ЈеҶіжҖқи·Ҝпјҡ
2.1 ж–Үжң¬йў„еӨ„зҗҶпјҡ
1. з”ұдәҺж–Ү件зҡ„зј–з ҒжҳҜGBKзҡ„пјҢиҜ»еҸ–еҲ°Sparkдёӯе…ЁйғЁжҳҜд№ұз ҒпјҢжүҖд»Ҙе…ҲдҪҝз”ЁJavaжҠҠд»Јз ҒиҪ¬дёәUTF8зј–з Ғпјӣ
2. з”ұдәҺж–Үжң¬еӯҳеңЁеӨҡдёӘж–Ү件дёӯпјҲеӨ§жҰӮ2kеӨҡпјүпјҢдҪҝз”ЁSparkзҡ„wholeTextFileиҜ»еҸ–йҖҹеәҰеӨӘж…ўпјҢжүҖд»ҘиҖғиҷ‘жҠҠиҝҷдәӣж–Ү件全йғЁеҗҲ并дёәдёҖдёӘж–Ү件пјҢиҝҷж—¶еҸҲз»“еҗҲ1.зҡ„иҪ¬еҸҳзј–з ҒпјҢжүҖд»ҘеңЁиҪ¬еҸҳзј–з Ғзҡ„ж—¶еҖҷе°ұзӣҙжҺҘжҠҠжүҖжңүзҡ„ж•°жҚ®еӯҳе…ҘеҗҢдёҖдёӘж–Ү件дёӯпјӣ
е…¶еӯҳеӮЁзҡ„ж јејҸдёәпјҡ жҜҸиЎҢпјҡ ж–Ү件еҗҚ.txt\tж–Ү件еҶ…е®№
еҰӮпјҡ 41.txtгҖҗ ж—Ҙ жңҹ гҖ‘199601....
иҝҷж ·еӯҗзҡ„иҜқпјҢе°ұеҸҜд»ҘйҖҡиҝҮ.txt\t жқҘеҜ№жҜҸиЎҢж–Үжң¬иҝӣиЎҢеҲҶеүІпјҢеҫ—еҲ°е…¶ж–Ү件еҗҚд»ҘеҸҠж–Ү件еҶ…е®№пјҢиҝҷйҮҢжҜҸиЎҢе…¶е®һе°ұжҳҜдёҖдёӘж–Ү件дәҶгҖӮ
2.2 еҲҶиҜҚ
еҲҶиҜҚзӣҙжҺҘйҮҮз”ЁHanLPзҡ„еҲҶиҜҚжқҘеҒҡпјҢHanLPиҝҷйҮҢйҖүжӢ©дёӨз§ҚпјҡStandardе’ҢNLP(иҝҳжңүдёҖз§Қе°ұжҳҜHighSpeedпјҢдҪҶжҳҜиҝҷдёӘжңЁжңүз”ЁжҲ·иҮӘе®ҡд№үиҜҚе…ёпјҢжүҖд»ҘеүҚжңҹиҖғиҷ‘е…Ҳз”ЁдёӨз§Қ)пјҢе…·дҪ“еҸӮиҖғпјҡhttps://github.com/hankcs/HanLP ;
2.3 иҜҚиҪ¬жҚўдёәиҜҚеҗ‘йҮҸ
еңЁKmeansз®—жі•дёӯпјҢдёҖдёӘж ·жң¬йңҖиҰҒдҪҝз”Ёж•°еҖјзұ»еһӢпјҢжүҖд»ҘйңҖиҰҒжҠҠж–Үжң¬иҪ¬дёәж•°еҖјеҗ‘йҮҸеҪўејҸпјҢиҝҷйҮҢеңЁSparkдёӯжңүдёӨз§Қж–№ејҸгҖӮе…¶дёҖпјҢжҳҜдҪҝз”ЁTF-IDFпјӣе…¶дәҢпјҢдҪҝз”ЁWord2VecгҖӮиҝҷйҮҢжҡӮж—¶дҪҝз”ЁдәҶTF-IDFз®—жі•жқҘиҝӣиЎҢпјҢиҝҷдёӘз®—жі•йңҖиҰҒжҸҗдҫӣдёҖдёӘnumFeaturesпјҢиҝҷдёӘеҖји¶ҠеӨ§е…¶ж•Ҳжһңд№ҹи¶ҠеҘҪпјҢдҪҶжҳҜзӣёеә”зҡ„и®Ўз®—ж—¶й—ҙд№ҹи¶Ҡй•ҝпјҢеҗҺйқўд№ҹеҸҜд»ҘйҖҡиҝҮе®һйӘҢйӘҢиҜҒгҖӮ
2.4 дҪҝз”ЁжҜҸдёӘж–ҮжЎЈзҡ„иҜҚеҗ‘йҮҸиҝӣиЎҢиҒҡзұ»е»әжЁЎ
еңЁиҝӣиЎҢиҒҡзұ»е»әжЁЎзҡ„ж—¶еҖҷпјҢйңҖиҰҒжҸҗдҫӣдёҖдёӘеҲқе§Ӣзҡ„иҒҡзұ»дёӘж•°пјҢиҝҷйҮҢйқўи®ҫзҪ®дёә10пјҢеӣ дёәжҲ‘们зҡ„ж•°жҚ®жҳҜжңү10дёӘеҲҶз»„зҡ„гҖӮдҪҶжҳҜеңЁе®һйҷ…зҡ„жғ…еҶөдёӢпјҢдёҖиҲ¬иҝҷдёӘеҖјжҳҜйңҖиҰҒйҖҡиҝҮе®һйӘҢжқҘйӘҢиҜҒеҫ—еҲ°зҡ„гҖӮ
2.5 еҜ№иҒҡзұ»еҗҺзҡ„з»“жһңиҝӣиЎҢиҜ„дј°
иҝҷйҮҢйқўйҮҮз”Ёзҡ„жҖқи·ҜжҳҜпјҡ
1. еҫ—еҲ°иҒҡзұ»жЁЎеһӢеҗҺпјҢеҜ№еҺҹе§Ӣж•°жҚ®иҝӣиЎҢеҲҶзұ»пјҢеҫ—еҲ°еҺҹе§Ӣж–Ү件еҗҚе’Ңйў„жөӢзҡ„еҲҶзұ»idзҡ„дәҢе…ғз»„(fileName,predictId)пјӣ
2. й’ҲеҜ№пјҲfileNameпјҢpredictIdпјүпјҢеҫ—еҲ°пјҲfileNameFirstChar ,fileNameFirstChar.toInt - predictIdпјүзҡ„еҖјпјҢиҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜfileNameFirstCharе…¶е®һе°ұжҳҜд»ЈиЎЁиҝҷдёӘж–Ү件зҡ„еҺҹе§ӢжүҖеұһзұ»еҲ«дәҶгҖӮ
3. иҝҷйҮҢжңүдёҖдёӘдёҖиҲ¬еҒҮи®ҫпјҢе°ұжҳҜдҪҝз”ЁkmeansжЁЎеһӢйў„жөӢеҫ—еҲ°зҡ„з»“жһңеӨ§еӨҡж•°жҳҜжӯЈзЎ®зҡ„пјҢжүҖд»ҘfileNameFirstChar.toInt-predictIdеҫ—еҲ°зҡ„дј—ж•°е…¶е®һе°ұжҳҜеҲҶзұ»зҡ„жӯЈзЎ®зҡ„дёӘж•°дәҶпјҲиҝҷйҮҢеҸҜиғҪжҜ”иҫғйҡҫд»ҘзҗҶи§ЈпјҢеҗҺйқўдјҡжңүдёӘе°ҸжқҺеӯҗжқҘиҜҙжҳҺиҝҷдёӘй—®йўҳпјүпјӣ
4. еҫ—еҲ°жҜҸдёӘе®һйҷ…зұ»еҲ«зҡ„йў„жөӢзҡ„жӯЈзЎ®зҺҮеҗҺе°ұеҸҜд»ҘеҺ»е№іеқҮйў„жөӢзҺҮдәҶгҖӮ
5. ж”№еҸҳnumFeatuersзҡ„еҖјпјҢзңӢдёӢжҳҜеҗҰnumFeaturesи®ҫзҪ®зҡ„жҜ”иҫғеӨ§пјҢе…¶жӯЈзЎ®зҺҮд№ҹдјҡжҜ”иҫғеӨ§пјҹ
3. е…·дҪ“жӯҘйӘӨпјҡ
3.1 ејҖеҸ‘зҺҜеўғ--Maven
йҰ–е…Ҳ第дёҖжӯҘпјҢеҪ“然жҳҜејҖеҸ‘зҺҜеўғдәҶпјҢеӣ дёәз”ЁеҲ°дәҶSparkе’ҢHanLPпјҢжүҖд»ҘйңҖиҰҒеңЁpom.xmlдёӯеҠ е…ҘиҝҷдёӨдёӘдҫқиө–пјҡ
<!-- дёӯж–ҮеҲҶиҜҚжЎҶжһ¶ -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>${hanlp.version}</version>
</dependency>
<!-- Spark dependencies -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
е…¶зүҲжң¬дёәпјҡ<hanlp.version>portable-1.3.4</hanlp.version>гҖҒ <spark.version>1.6.0-cdh6.7.3</spark.version>гҖӮ
3.2 ж–Ү件иҪ¬дёәUTF-8зј–з ҒеҸҠеӯҳеӮЁеҲ°дёҖдёӘж–Ү件
иҝҷйғЁеҲҶеҶ…е®№еҸҜд»ҘзӣҙжҺҘеҸӮиҖғпјҡsrc/main/java/demo02_transform_encoding.TransformEncodingToOne иҝҷйҮҢзҡ„е®һзҺ°пјҢеӣ дёәжҳҜJavaеҹәжң¬зҡ„ж“ҚдҪңпјҢиҝҷйҮҢе°ұдёҚеҠ д»ҘеҲҶжһҗдәҶгҖӮ
3.3 Scalaи°ғз”ЁHanLPиҝӣиЎҢдёӯж–ҮеҲҶиҜҚ
Scalaи°ғз”ЁHanLPиҝӣиЎҢеҲҶиҜҚе’ҢJavaзҡ„жҳҜдёҖж ·зҡ„пјҢеҗҢж—¶пјҢеӣ дёәиҝҷйҮҢжңүдәӣиҜҚиҜӯж јејҸдёҚжӯЈеёёпјҢжүҖд»ҘжҠҠиҝҷдәӣзү№ж®Ҡзҡ„иҜҚиҜӯж·»еҠ еҲ°иҮӘе®ҡд№үиҜҚе…ёдёӯпјҢе…¶зӨәдҫӢеҰӮдёӢпјҡ
import com.hankcs.hanlp.dictionary.CustomDictionary
import com.hankcs.hanlp.dictionary.stopword.CoreStopWordDictionary
import com.hankcs.hanlp.tokenizer.StandardTokenizer
import scala.collection.JavaConversions._
/**
* Scala еҲҶиҜҚжөӢиҜ•
* Created by fansy on 2017/8/25.
*/
object SegmentDemo {
def main(args: Array[String]) {
val sentense = "41,гҖҗ ж—Ҙ жңҹ гҖ‘19960104 гҖҗ зүҲ еҸ· гҖ‘1 гҖҗ ж Ү йўҳ гҖ‘еҗҲе·ўиҠңй«ҳйҖҹе…¬и·Ҝе·ўиҠңж®өз«Је·Ҙ гҖҗ дҪң иҖ… гҖ‘еҪӯе»әдёӯ гҖҗ жӯЈ ж–Ү гҖ‘ е®үеҫҪеҗҲпјҲиӮҘпјүе·ўпјҲж№–пјүиҠңпјҲж№–пјүй«ҳйҖҹе…¬и·Ҝе·ўиҠңж®өж—ҘеүҚз«Је·ҘйҖҡиҪҰ并жҠ•е…ҘиҗҘиҝҗгҖӮеҗҲе·ўиҠң й«ҳйҖҹе…¬и·ҜжҳҜеӣҪ家规еҲ’зҡ„дә¬зҰҸз»јеҗҲиҝҗиҫ“зҪ‘зҡ„йҮҚиҰҒе№Ізәҝи·Ҝж®өпјҢжҳҜдәӨйҖҡйғЁзЎ®е®ҡпј‘пјҷпјҷпј•е№ҙе»әжҲҗ зҡ„е…ЁеӣҪпј‘пјҗжқЎйҮҚзӮ№е…¬и·Ҝд№ӢдёҖгҖӮиҜҘжқЎй«ҳйҖҹе…¬и·ҜжӯЈзәҝй•ҝпјҳпјҳе…¬йҮҢгҖӮпјҲеҪӯе»әдёӯпјү"
CustomDictionary.add("ж—Ҙ жңҹ")
CustomDictionary.add("зүҲ еҸ·")
CustomDictionary.add("ж Ү йўҳ")
CustomDictionary.add("дҪң иҖ…")
CustomDictionary.add("жӯЈ ж–Ү")
val list = StandardTokenizer.segment(sentense)
CoreStopWordDictionary.apply(list)
println(list.map(x => x.word.replaceAll(" ","")).mkString(","))
}
}
иҝҗиЎҢе®ҢжҲҗеҗҺпјҢеҚіеҸҜеҫ—еҲ°еҲҶиҜҚзҡ„з»“жһңпјҢеҰӮдёӢпјҡ

иҖғиҷ‘еҲ°дҪҝз”Ёж–№дҫҝпјҢиҝҷйҮҢжҠҠеҲҶиҜҚе°ҒиЈ…жҲҗдёҖдёӘеҮҪж•°пјҡ
/**
* String еҲҶиҜҚ
* @param sentense
* @return
*/
def transform(sentense:String):List[String] ={
val list = StandardTokenizer.segment(sentense)
CoreStopWordDictionary.apply(list)
list.map(x => x.word.replaceAll(" ","")).toList
}
}
иҫ“е…ҘеҚіжҳҜдёҖдёӘдёӯж–Үзҡ„ж–Үжң¬пјҢиҫ“еҮәе°ұжҳҜеҲҶиҜҚзҡ„з»“жһңпјҢеҗҢж—¶еҺ»жҺүдәҶдёҖдәӣеёёз”Ёзҡ„еҒңз”ЁиҜҚгҖӮ
3.4 жұӮTF-IDF
еңЁSparkйҮҢйқўжұӮTF-IDFпјҢеҸҜд»ҘзӣҙжҺҘи°ғз”ЁSparkеҶ…зҪ®зҡ„з®—жі•жЁЎеқ—еҚіеҸҜпјҢеҗҢж—¶еңЁSparkзҡ„иҜҘз®—жі•жЁЎеқ—дёӯиҝҳеҜ№жұӮеҫ—зҡ„з»“жһңиҝӣиЎҢдәҶз»ҙеәҰеҸҳжҚўпјҲеҸҜд»ҘзҗҶи§Јдёәзү№еҫҒйҖүжӢ©жҲ–вҖңйҷҚз»ҙвҖқпјҢеҪ“然иҝҷйҮҢзҡ„йҷҚз»ҙеҸҜиғҪжҳҜжҸҗеҚҮз»ҙеәҰпјүгҖӮд»Јз ҒеҰӮдёӢпјҡ
val docs = sc.textFile(input_data).map{x => val t = x.split(".txt\t");(t(0),transform(t(1)))}
.toDF("fileName", "sentence_words")
// 3. жұӮTF
println("calculating TF ...")
val hashingTF = new HashingTF()
.setInputCol("sentence_words").setOutputCol("rawFeatures").setNumFeatures(numFeatures)
val featurizedData = hashingTF.transform(docs)
// 4. жұӮIDF
println("calculating IDF ...")
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData).cache()
еҸҳйҮҸdocsжҳҜдёҖдёӘDataFrame[fileName, sentence_words] ,з»ҸиҝҮHashingTFеҗҺпјҢеҸҳжҲҗдәҶеҸҳйҮҸ featurizedData ,еҗҢж ·жҳҜдёҖдёӘDataFrame[fileName,sentence_words, rawFeatures]гҖӮиҝҷйҮҢйҖҡиҝҮsetInputColд»ҘеҸҠSetOutputColеҸҜд»Ҙи®ҫзҪ®иҫ“е…Ҙд»ҘеҸҠиҫ“еҮәеҲ—еҗҚпјҲеҲ—еҗҚжҳҜй’ҲеҜ№DataFrameжқҘиҜҙзҡ„пјҢдёҚзҹҘйҒ“зҡ„еҸҜд»ҘзңӢдёӢDataFrameзҡ„APIпјүгҖӮ
жҺҘзқҖпјҢз»ҸиҝҮIDFжЁЎеһӢпјҢеҫ—еҲ°еҸҳйҮҸ rescaledData пјҢе…¶DataFrame[fileName,sentence_words, rawFeatures, features] гҖӮ
жү§иЎҢз»“жһңдёәпјҡ

3.5 е»әз«ӢKMeansжЁЎеһӢ
зӣҙжҺҘеҸӮиҖғе®ҳзҪ‘з»ҷе®ҡдҫӢеӯҗеҚіеҸҜпјҡ
println("creating kmeans model ...")
val kmeans = new KMeans().setK(k).setSeed(1L)
val model = kmeans.fit(rescaledData)
// Evaluate clustering by computing Within Set Sum of Squared Errors.
println("calculating wssse ...")
val WSSSE = model.computeCost(rescaledData)
println(s"Within Set Sum of Squared Errors = $WSSSE")
иҝҷйҮҢжңүи®Ўз®—costеҖјзҡ„пјҢдҪҶжҳҜиҝҷдёӘеҖјиҜ„дј°дёҚжҳҜеҫҲеҮҶзЎ®пјҢжҜ”еҰӮжҲ‘numFeatureи®ҫзҪ®дёә2000зҡ„иҜқпјҢйӮЈд№ҲиҝҷдёӘеҖје°ұеҫҲеӨ§пјҢдҪҶжҳҜе…¶е®һе…¶жӯЈзЎ®зҺҮдјҡжҜ”иҫғеӨ§зҡ„гҖӮ
3.6 жЁЎеһӢиҜ„дј°
иҝҷйҮҢзҡ„жЁЎеһӢиҜ„дј°зӣҙжҺҘдҪҝз”ЁдёҖдёӘе°ҸжқҺеӯҗжқҘиҜҙжҳҺпјҡжҜ”еҰӮпјҢзҺ°еңЁжңүиҝҷж ·зҡ„ж•°жҚ®пјҡ

е…¶дёӯпјҢ1ејҖеӨҙпјҢ2ејҖеӨҙе’Ң4ејҖеӨҙзҡ„еұһдәҺеҗҢдёҖзұ»ж–ҮжЎЈпјҢеҗҺйқўзҡ„0,3,2,1зӯүпјҢд»ЈиЎЁиҝҷдёӘж–ҮжЎЈиў«жЁЎеһӢеҲҶзұ»зҡ„з»“жһңпјҢйӮЈд№ҲеҸҜд»ҘеҫҲе®№жҳ“зҡ„зңӢеҮәй’ҲеҜ№1ејҖеӨҙзҡ„ж–ҮжЎЈпјҢ
е…¶еҲҶзұ»жӯЈзЎ®зҡ„жңү4дёӘпјҢе…¶дёӯ("123.txt",3)д»ҘеҸҠпјҲвҖң126.txtвҖқ,1пјүжҳҜеҲҶзұ»й”ҷиҜҜзҡ„з»“жһңпјҢиҝҷжҳҜеӣ дёәпјҢеңЁиҝҷдёӘзұ»еҲ«дёӯйў„жөӢзҡ„з»“жһңдёӯ0жҳҜжңҖеӨҡзҡ„пјҢжүҖд»Ҙ0жҳҜе’Ң1ејҖеӨҙзҡ„ж–ҮжЎЈеҜ№еә”иө·жқҘзҡ„пјҢиҝҷд№ҹе°ұжҳҜеүҚйқўзҡ„еҒҮи®ҫгҖӮ
1. жҠҠеҗҢдёҖзұ»ж–ҮжЎЈеҲҶеҲ°еҗҢдёҖдёӘpartitionдёӯпјӣ
val data = sc.parallelize(t)
val file_index = data.map(_._1.charAt(0)).distinct.zipWithIndex().collect().toMap
println(file_index)
val partitionData = data.partitionBy(MyPartitioner(file_index))
иҝҷйҮҢзҡ„file_indexпјҢжҳҜеҜ№дёҚеҗҢзұ»зҡ„ж–ҮжЎЈиҝӣиЎҢзј–еҸ·пјҢиҝҷдёӘзј–еҸ·е°ұеҜ№еә”жҜҸдёӘpartitionпјҢзңӢMyPartitionerзҡ„е®һзҺ°пјҡ
case class MyPartitioner(file_index:Map[Char,Long]) extends Partitioner{
override def getPartition(key: Any): Int = key match {
case _ => file_index.getOrElse(key.toString.charAt(0),0L).toInt
}
override def numPartitions: Int = file_index.size
}
2. й’ҲеҜ№жҜҸдёӘpartitionиҝӣиЎҢж•ҙеҗҲж“ҚдҪңпјҡ
еңЁж•ҙеҗҲжҜҸдёӘpartitionд№ӢеүҚпјҢжҲ‘们е…ҲзңӢдёӢжҲ‘们иҮӘе®ҡд№үзҡ„MyPartitionerжҳҜеҗҰеңЁжӯЈеёёе·ҘдҪңпјҢеҸҜд»Ҙжү“еҚ°дёӢз»“жһңпјҡ
val tt = partitionData.mapPartitionsWithIndex((index: Int, it: Iterator[(String,Int)]) => it.toList.map(x => (index,x)).toIterator)
tt.collect().foreach(println(_))
иҝҗиЎҢеҰӮдёӢпјҡ

е…¶дёӯ第дёҖеҲ—д»ЈиЎЁжҜҸдёӘpartitionзҡ„idпјҢ第дәҢеҲ—жҳҜж•°жҚ®пјҢеҸ‘зҺ°е…¶ж•°жҚ®зЎ®е®һжҳҜжҢүз…§йў„жңҹиҝӣиЎҢеӨ„зҗҶзҡ„пјӣжҺҘзқҖеҸҜд»Ҙй’ҲеҜ№жҜҸдёӘpartitionиҝӣиЎҢж•°жҚ®ж•ҙеҗҲпјҡ
// firstCharInFileName , firstCharInFileName - predictType
val combined = partitionData.map(x =>( (x._1.charAt(0), Integer.parseInt(x._1.charAt(0)+"") - x._2),1) )
.mapPartitions{f => var aMap = Map[(Char,Int),Int]();
for(t <- f){
if (aMap.contains(t._1)){
aMap = aMap.updated(t._1,aMap.getOrElse(t._1,0)+1)
}else{
aMap = aMap + t
}
}
val aList = aMap.toList
val total= aList.map(_._2).sum
val total_right = aList.map(_._2).max
List((aList.head._1._1,total,total_right)).toIterator
// aMap.toIterator //жү“еҚ°еҗ„дёӘpartitionзҡ„жҖ»з»“
}
еңЁж•ҙеҗҲд№ӢеүҚе…Ҳжү§иЎҢдёҖдёӘmapж“ҚдҪңпјҢжҠҠж•°жҚ®еҸҳжҲҗпјҲ(fileNameFirstChar, fileNameFirstChar.toInt - predictId), 1пјүпјҢе…¶дёӯfileNameFirstCharд»ЈиЎЁж–Ү件зҡ„第дёҖдёӘеӯ—з¬ҰпјҢе…¶е®һд№ҹе°ұжҳҜж–Ү件зҡ„жүҖеұһе®һйҷ…зұ»еҲ«пјҢеҗҺйқўзҡ„fileNameFirstChar.toInt-predictId е…¶е®һе°ұжҳҜеҲӨж–ӯйў„жөӢзҡ„з»“жһңжҳҜеҗҰеҜ№дәҶпјҢиҝҷдёӘеҖјзҡ„дј—ж•°е°ұжҳҜйў„жөӢеҜ№зҡ„пјӣжңҖеҗҺдёҖдёӘеҖјд»Јз ҒеүҚйқўзҡ„иҝҷдёӘй”®еҖјеҜ№еҮәзҺ°зҡ„ж¬Ўж•°пјҢе…¶е®һе°ұжҳҜз»ҹи®ЎеұһдәҺжҹҗдёӘзұ»еҲ«зҡ„е®һйҷ…ж–Ү件дёӘж•°д»ҘеҸҠйў„жөӢеҜ№зҡ„ж–Ү件дёӘж•°пјҢеҲҶеҲ«еҜ№еә”дёҠйқўзҡ„totalе’Ңtotal_rightеҸҳйҮҸпјӣиҫ“еҮәз»“жһңдёәпјҡ
(4,6,3)
(1,6,4)
(2,6,4)
еҸ‘зҺ°е…¶жү“еҚ°зҡ„з»“жһңжҳҜжӯЈзЎ®зҡ„пјҢ第дёҖеҲ—д»ЈиЎЁж–Ү件еҗҚејҖеӨҙпјҢ第дәҢдёӘд»ЈиЎЁеұһдәҺиҝҷдёӘж–Ү件зҡ„дёӘж•°пјҢ第дёүеҲ—д»ЈиЎЁйў„жөӢжӯЈзЎ®зҡ„дёӘж•°
иҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢиҝҷйҮҢеӣ дёәж–Үжң¬зҡ„е®һйҷ…зұ»еҲ«е’Ңж–Ү件еҗҚжҳҜдёҖиҮҙзҡ„пјҢжүҖд»ҘжүҚеҸҜд»Ҙиҝҷж ·еӨ„зҗҶпјҢеҰӮжһңе®һйҷ…ж•°жҚ®зҡ„иҜқпјҢйӮЈд№ҲmapPartitionsеҮҪж•°йңҖиҰҒжӣҙж”№гҖӮ
3. й’ҲеҜ№ж•°жҚ®з»“жһңиҝӣиЎҢз»ҹи®Ўпјҡ
жңҖеҗҺеҸӘйңҖиҰҒиҝӣиЎҢз®ҖеҚ•зҡ„и®Ўз®—еҚіеҸҜпјҡ
for(re <- result ){
println("ж–ҮжЎЈ"+re._1+"ејҖеӨҙзҡ„ ж–ҮжЎЈжҖ»ж•°пјҡ"+ re._2+",еҲҶзұ»жӯЈзЎ®зҡ„жңүпјҡ"+re._3+",еҲҶзұ»жӯЈзЎ®зҺҮжҳҜпјҡ"+(re._3*100.0/re._2)+"%")
}
val averageRate = result.map(_._3).sum *100.0 / result.map(_._2).sum
println("е№іеқҮжӯЈзЎ®зҺҮдёәпјҡ"+averageRate+"%")
иҫ“еҮәз»“жһңдёәпјҡ

4. е®һйӘҢ
и®ҫзҪ®дёҚеҗҢзҡ„numFeatureпјҢжҜ”еҰӮдҪҝз”Ё200е’Ң2000пјҢе…¶еҜ№жҜ”з»“жһңдёәпјҡ
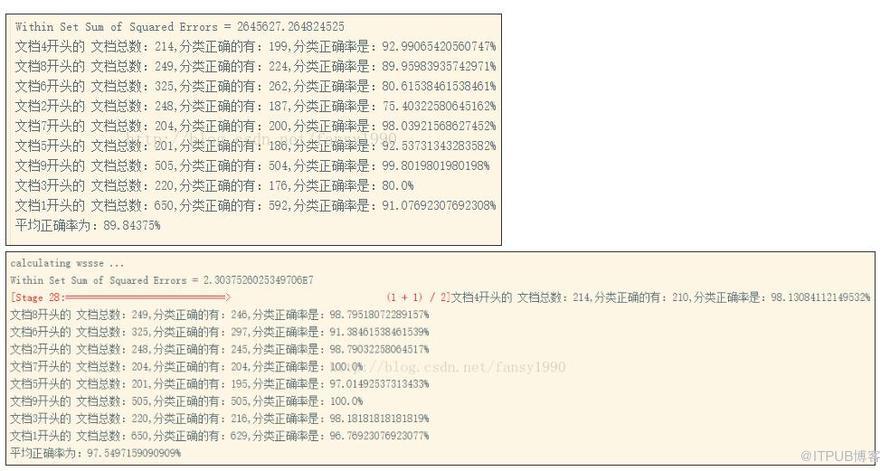
жүҖд»Ҙи®ҫзҪ®numFeaturesеҖји¶ҠеӨ§пјҢе…¶еҮҶзЎ®зҺҮд№ҹи¶Ҡй«ҳпјҢдёҚиҝҮи®Ўз®—д№ҹжҜ”иҫғеӨҚжқӮгҖӮ
жҖ»з»“
1. HanLPзҡ„дҪҝз”ЁзӣёеҜ№жҜ”иҫғз®ҖеҚ•пјҢиҝҷйҮҢеҸӘдҪҝз”ЁдәҶеҲҶиҜҚеҸҠеҒңз”ЁиҜҚпјҢж„ҹи°ўејҖжәҗпјӣ
2. SparkйҮҢйқўзҡ„TF-IDFд»ҘеҸҠWord2VectorдҪҝз”ЁжҜ”иҫғз®ҖеҚ•пјҢдёҚиҝҮдҪҝз”ЁиҝҷдёӘйңҖиҰҒе…ҲеҲҶиҜҚпјӣ
3. иҝҷйҮҢжҳҜеңЁIDEAйҮҢйқўиҝҗиЎҢзҡ„пјҢеҰӮжһңдҪҝз”ЁSpark-submitзҡ„жҸҗдәӨж–№ејҸпјҢйӮЈд№ҲйңҖиҰҒжҠҠhanplзҡ„jarеҢ…еҠ е…ҘпјҢиҝҷдёӘжңүеҫ…йӘҢиҜҒпјӣ
ж–Үз« жқҘжәҗдәҺfansy1990зҡ„еҚҡе®ў
дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„SparkжҖҺж ·еә”з”ЁHanLPеҜ№дёӯж–ҮиҜӯж–ҷиҝӣиЎҢж–Үжң¬жҢ–жҺҳдәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ