您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何将kafka中的数据快速导入Hadoop,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
Kafka是一个分布式发布—订阅系统,由于其强大的分布式和性能特性,迅速成为数据管道的关键部分。它可完成许多工作,例如消息传递、指标收集、流处理和日志聚合。Kafka的另一个有效用途是将数据导入Hadoop。使用Kafka的关键原因是它将数据生产者和消费者分离,允许拥有多个独立的生产者(可能由不同的开发团队编写)。同样,还有多个独立的消费者(也可能由不同的团队编写)。此外,消费者可以是实时/同步或批量/离线/异步。当对比RabbitMQ等其他pub-sub工具时,后一个属性有很大区别。
要使用Kafka,有一些需要理解的概念:
topic—topic是相关消息的订阅源;
分区—每个topic由一个或多个分区组成,这些分区是由日志文件支持的有序消息队列;
生产者和消费者—生产者和消费者将消息写入分区并从分区读取。
Brokers—Brokers是管理topic和分区并为生产者和消费者请求提供服务的Kafka流程。
Kafka不保证对topic的“完全”排序,只保证组成topic的各个分区是有序的。消费者应用程序可以根据需要强制执行对“全局”topic排序。
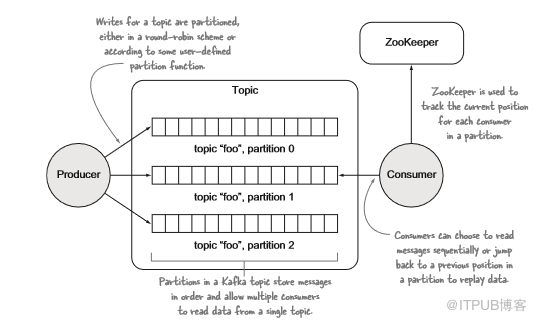
图5.14 显示了Kafka的概念模型
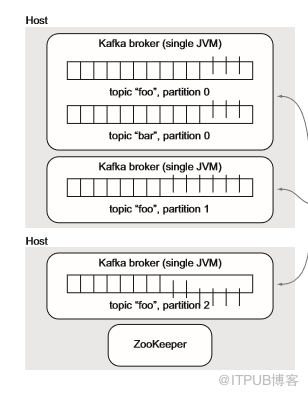
图5.15 显示了如何在Kafka部署分发分区的示例
为了支持容错,可以复制topic,这意味着每个分区可以在不同主机上具有可配置数量的副本。这提供了更高的容错能力,这意味着单个服务器死亡对数据或生产者和消费者的可用性来说不是灾难性的。
此处采用Kafka版本0.8和Camus的0.8.X。
实践:使用Camus将Avro数据从Kafka复制到HDFS
该技巧在已经将数据流入Kafka用于其他目的并且希望将数据置于HDFS中的情况下非常有用。
问题
希望使用Kafka作为数据传递机制来将数据导入HDFS。
解决方案
使用LinkedIn开发的解决方案Camus将Kafka中的数据复制到HDFS。
讨论
Camus是LinkedIn开发的一个开源项目。Kafka在LinkedIn大量部署,而Camus则用作将数据从Kafka复制到HDFS。
开箱即用,Camus支持Kafka中的两种数据格式:JSON和Avro。在这种技术中,我们将通过Camus使用Avro数据。Camus对Avro的内置支持要求Kafka发布者以专有方式编写Avro数据,因此对于这种技术,我们假设希望在Kafka中使用vanilla序列化数据。
让这项技术发挥作用需要完成三个部分的工作:首先要将一些Avro数据写入Kafka,然后编写一个简单的类来帮助Camus反序列化Avro数据,最后运行一个Camus作业来执行数据导入。
为了把Avro记录写入Kafka,在以下代码中,需要通过配置必需的Kafka属性来设置Kafka生成器,从文件加载一些Avro记录,并将它们写出到Kafka:

可以使用以下命令将样本数据加载到名为test的Kafka的topic中:
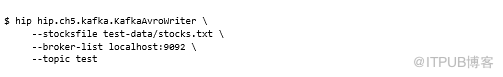
Kafka控制台使用者可用于验证数据是否已写入Kafka,这会将二进制Avro数据转储到控制台:

完成后,编写一些Camus代码,以便可以在Camus中阅读这些Avro记录。
实践:编写Camus和模式注册表
首先,需要了解三种Camus概念:
解码器—解码器的工作是将从Kafka提取的原始数据转换为Camus格式。
编码器—编码器将解码数据序列化为将存储在HDFS中的格式。
Schema注册表—提供有关正在编码的Avro数据的schema信息。
正如前面提到的,Camus支持Avro数据,但确实需要Kafka生产者使用Camus KafkaAvroMessageEncoder类来编写数据,该类为Avro序列化二进制数据添加了部分专有数据,可能是因为Camus中的解码器可以验证它是由该类编写的。
在此示例中,使用 Avro serialization进行序列化,因此需要编写自己的解码器。幸运的是,这很简单:


你可能已经注意到我们在Kafka中写了一个特定的Avro记录,但在Camus中我们将该记录读作通用的Avro记录,而不是特定的Avro记录,这是因为CamusWrapper类仅支持通用Avro记录。否则,特定的Avro记录可以更简单地使用,因为可以使用生成的代码并具有随之而来的所有安全特征。
CamusWrapper对象是从Kafka提取的数据。此类存在的原因是允许将元数据粘贴到envelope中,例如时间戳,服务器名称和服务详细信息。强烈建议使用的任何数据都有一些与每条记录相关的有意义的时间戳(通常这将是创建或生成记录的时间)。然后,可以使用接受时间戳作为参数的CamusWrapper构造函数:
public CamusWrapper(R record, long timestamp) { ... }如果未设置时间戳,则Camus将在创建包装器时创建新的时间戳。在确定输出记录的HDFS位置时,在Camus中使用此时间戳和其他元数据。
接下来,需要编写一个schema注册表,以便Camus Avro编码器知道正在写入HDFS的Avro记录的schema详细信息。注册架构时,还要指定从中拉出Avro记录的Kafka的topic名称:

运行Camus
Camus在Hadoop集群上作为MapReduce作业运行,希望在该集群中导入Kafka数据。需要向Camus提供一堆属性,可以使用命令行或者使用属性文件来执行此操作,我们将使用此技术的属性文件:
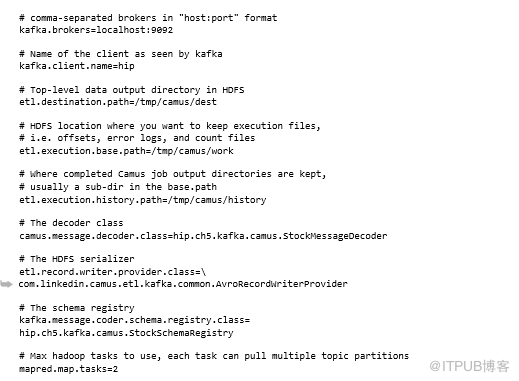
从属性中可以看出,无需明确告诉Camus要导入哪些topic。Camus自动与Kafka通信以发现topic(和分区)以及当前的开始和结束偏移。
如果想要精确控制导入的topic,可以分别使用kafka.whitelist.topics和kafka.blacklist.topics列举白名单(限制topic)和黑名单(排除topic),可以使用逗号作为分隔符指定多个topic,还支持正则表达式,如以下示例所示,其匹配topic的“topic1”或以“abc”开头,后跟一个或多个数字的任何topic,可以使用与value完全相同的语法指定黑名单:
kafka.whitelist.topics=topic1,abc[0-9]+
一旦属性全部设置完毕,就可以运行Camus作业了:

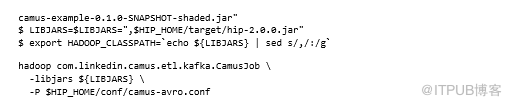
这将导致Avro数据在HDFS中着陆。我们来看看HDFS中的内容:
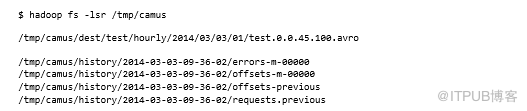
第一个文件包含已导入的数据,其他供Camus管理。
可以使用AvroDump实用程序查看HDFS中的数据文件:

那么,当Camus工作正在运行时究竟发生了什么? Camus导入过程作为MapReduce作业执行,如图5.16所示。
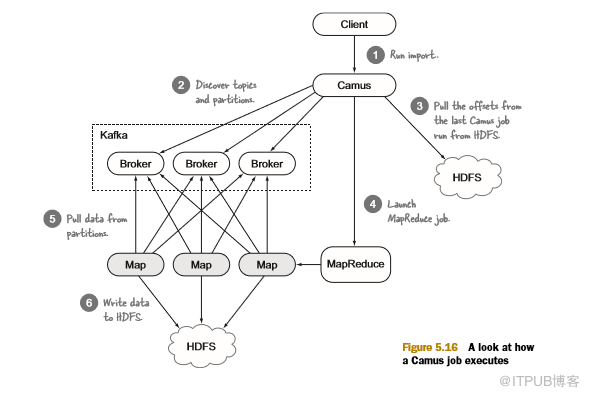
随着MapReduce中的Camus任务成功,Camus OutputCommitter(允许在任务完成时执行自定义工作的MapReduce构造)以原子方式将任务的数据文件移动到目标目录。OutputCommitter还为任务正在处理的所有分区创建偏移文件,同一作业中的其他任务可能会失败,但这不会影响成功任务的状态——成功任务的数据和偏移输出仍然存在,因此后续的Camus执行将从最后一个已知的成功状态恢复处理。
接下来,让我们看看Camus导入数据的位置以及如何控制行为。
数据分区
之前,我们看到了Camus导入位于Kafka的Avro数据,让我们仔细看看HDFS路径结构,如图5.17所示,看看可以做些什么来确定位置。
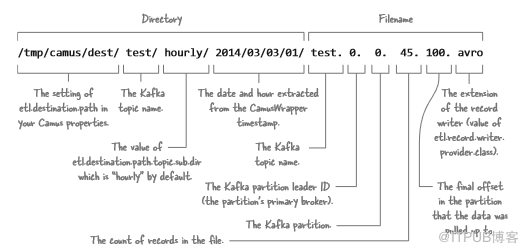
图5.17 在HDFS中解析导出数据的Camus输出路径
路径的日期/时间由从CamusWrapper中提取的时间戳确定,可以从MessageDecoder中的Kafka记录中提取时间戳,并将它们提供给CamusWrapper,这将允许按照有意义的日期对数据进行分区,而不是默认值,这只是在MapReduce中读取Kafka记录的时间。
Camus支持可插拔分区程序,允许控制图5.18所示路径的一部分。

图5.18 Camus分区路径
Camus Partitioner接口提供了两种必须实现的方法:

例如,自定义分区程序可创建用于Hive分区的路径。
Camus提供了一个完整的解决方案,可以在HDFS中从Kafka获取数据,并在出现问题时负责维护状态和进行错误处理。通过将其与Azkaban或Oozie集成,可以轻松实现自动化,并根据消息时间组织HDFS数据执行简单的数据管理。值得一提的是,当涉及到ETL时,与Flume相比,它的功能是无懈可击的。
Kafka捆绑了一种将数据导入HDFS的机制。它有一个KafkaETLInputFormat输入格式类,可用于在MapReduce作业中从Kafka提取数据。要求编写MapReduce作业以执行导入,但优点是可以直接在MapReduce流中使用数据,而不是将HDFS用作数据的中间存储。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。