您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“怎么在HDFS中进行数据压缩”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么在HDFS中进行数据压缩”吧!
通过数据压缩实现高效存储
数据压缩是文件处理的重要方面,在处理Hadoop支持的数据大小时,这一点变得更加重要。大部分企业在使用Hadoop时,目标都是尽可能高效得进行数据处理,选择合适的压缩编解码器将使作业运行更快,并允许在集群中存储更多数据。
为数据选择正确的压缩编解码器
在HDFS上使用压缩并不像在ZFS等文件系统上那样透明,特别是在处理可拆分的压缩文件时(本章稍后将详细介绍)。使用Avro和SequenceFile等文件格式的优点是内置压缩支持,使压缩几乎对用户完全透明。但是在使用文本等格式时,就会失去这种支持。
问题
评估并确定用于数据压缩的最佳编解码器。
解决方案
谷歌的压缩编解码器Snappy提供压缩大小和读/写执行时间的最佳组合。但是,当使用必须支持可拆分性的大型压缩文件时,LZOP是最好的编解码器。
讨论
首先,快速浏览可用于Hadoop的压缩编解码器,如表4.1所示。
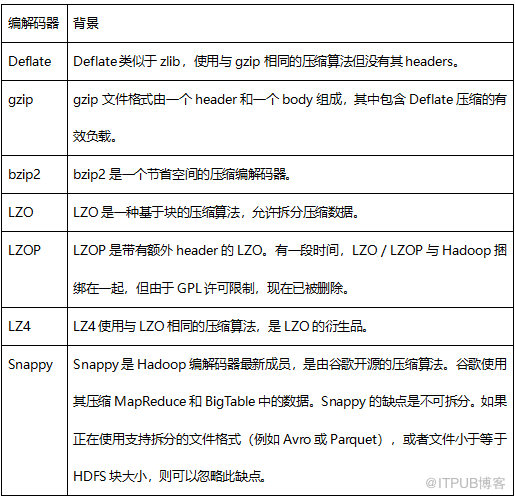
表4.1压缩编解码器
要正确评估编解码器,首先需要确定评估标准,该标准应基于功能和性能特征。对于压缩,你的标准可能包括以下内容:
空间/时间权衡——通常,计算成本越高的压缩编解码器可以产生更好的压缩比,从而产生更小的压缩输出。
可拆分性——可以拆分压缩文件以供多个mapper使用。如果无法拆分压缩文件,则只能使用一个mapper。如果该文件跨越多个块,则会丢失数据局部性,因为map可能必须从远程DataNode读取块,从而导致网络I/O开销。
本机压缩支持——是否存在执行压缩和解压缩的本地库?这通常胜过用Java编写的压缩编解码器,没有底层的本机库支持。
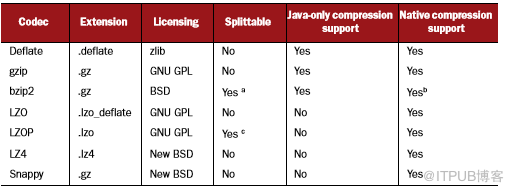
表4.2 压缩编解码器比较
Native vs Java bzip2
Hadoop添加了对bzip2的原生支持(从版本2.0和1.1.0开始)。本机bzip2支持是默认的,但不支持可拆分性。如果需要可拆分性,就需要启用Java bzip2,可以通过将io.compression .codec.bzip2.library设置为java-builtin来指定。
接下来,我们来了解编解码器在空间和时间上是如何平衡的。此处使用100 MB(10 ^ 8)的XML文件(来自http://mattmahoney.net/dc/textdata.html的enwik8.zip)来比较编解码器运行时间及其压缩大小,具体测试结果见表4.3。
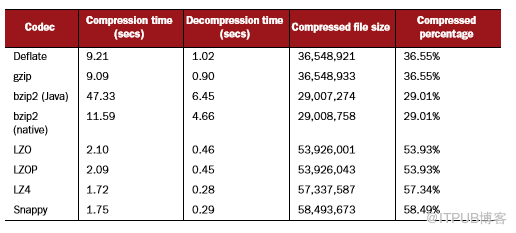
表4.3 100 MB文本文件上压缩编解码器的性能比较
运行测试
当进行评估时,我建议使用自己的数据进行测试,最好是在类似于生产节点的主机上执行测试,这样就可以很好地理解编解码器的预期压缩和运行时间。
要确保集群已启用本机编解码器,你可以通过运行以下命令来检查:
$ hadoop checknative -a
空间和时间的结果说明了什么?如果将尽可能多的数据压入集群是首要任务,并且允许较长的压缩时间,那么bzip2可能是适合的编解码器。如果要压缩数据但要求在读取和写入压缩文件时引入最少的CPU开销,则应该考虑LZ4。任何寻求压缩和执行时间之间平衡的企业都不会考虑bzip2的Java版本。
拆分压缩文件很重要,但必须在bzip2和LZOP之间进行选择。原生bzip2编解码器不支持拆分,Java bzip2 time可能会让大多数人放弃。bzip2优于LZOP的唯一优势是其Hadoop集成比LZOP更容易使用。
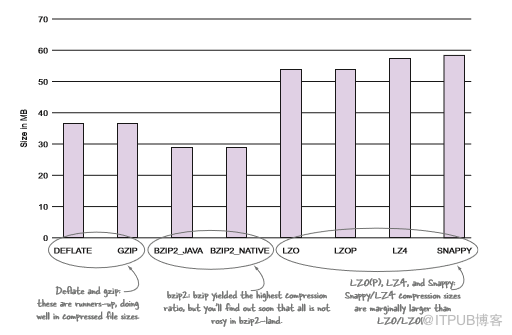
图4.4 单个100 MB文本文件的压缩大小(较小的值更好)
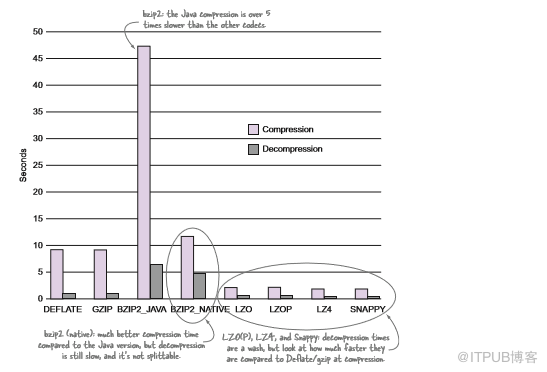
图4.5单个100 MB文本文件的压缩和解压缩时间(较小的值更好)
虽然LZOP似乎看起来是最优的选择,但还是需要做一些改进,正如下文所述。
总结
最适合的编解码器取决于你的需求和标准。如果不关心拆分文件,LZ4是最有前途的编解码器,如果想要拆分文件,LZOP就是最应该关注的。
此外,我们还需要考虑数据是否需要长期存储。如果长时间保存数据,你可能希望最大限度地压缩文件,我建议使用基于zlib的编解码器(例如gzip)。但是,由于gzip不可拆分,因此将它与基于块的文件格式(如Avro或Parquet)结合使用是明智的,这样数据仍然可以拆分,或者调整输出大小使其在HDFS中占用一个块,这样就不需要考虑是否可拆分。
请记住,压缩大小将根据文件是文本还是二进制而有所不同,具体取决于其内容。要获得准确的数字,需要针对自己的数据运行类似的测试。
对HDFS中的数据进行压缩有许多好处,包括减小文件大小和更快的MapReduce作业运行时。许多压缩编解码器可用于Hadoop,我根据功能和性能对它们进行了评估。接下来,让我们看看如何压缩文件并通过MapReduce,Pig和Hive等工具使用它们。
使用HDFS,MapReduce,Pig和Hive进行压缩
由于HDFS不提供内置的压缩支持,因此在Hadoop中使用压缩可能是一项挑战。此外,可拆分压缩不适合技术水平不高的初学者,因为它并不是Hadoop开箱即用的功能。如果正在处理压缩到接近HDFS块大小的中型文件,以下方法将是在Hadoop中压缩优势最明显和最简单的方法。
问题
希望在HDFS中读取和写入压缩文件,并将其与MapReduce,Pig和Hive一起使用。
解决方案
在MapReduce中使用压缩文件涉及更新MapReduce配置文件mapred-site.xml并注册正在使用的压缩编解码器。执行此操作后,在MapReduce中使用压缩输入文件不需要额外的步骤,并且生成压缩的MapReduce输出是设置mapred.output.compress和mapred.output.compression.codec MapReduce属性的问题。
讨论
第一步是弄清楚如何使用本章前面评估的编解码器来读取和写入文件。本章详细介绍的所有编解码器都与Hadoop捆绑在一起,但LZO / LZOP和Snappy除外,如果想使用这三种编解码器,需要自己下载并构建。
要使用压缩编解码器,首先需要知道它们的类名,如表4.4所示。
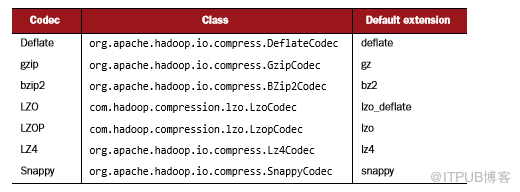
表4.4 编解码器类
在HDFS中使用压缩
如何使用上表中提到的任何一种编解码器压缩HDFS中的现有文件?以下代码支持这样做:

编解码器缓存使用压缩编解码器的一个开销是创建成本很高。当使用Hadoop ReflectionUtils类时,与创建实例相关的一些开销将缓存在ReflectionUtils中,这将加速后续创建编解码器。更好的选择是使用CompressionCodecFactory,它本身提供编解码器缓存。
读取此压缩文件就像编写一样简单:

超级简单。既然可以创建压缩文件,那么让我们看看如何在MapReduce中使用。
在MapReduce中使用压缩
要在MapReduce中使用压缩文件,需要为作业设置一些配置选项。为简洁起见,我们假设在此示例中使用了identity mapper和reducer:

使用未压缩I/O与压缩I/O的MapReduce作业之间的唯一区别是前面示例中的三个带注释的行。
不仅可以压缩作业的输入和输出,而且中间map输出也可以压缩,因为它首先输出到磁盘,最终通过网络输出到reducer。map输出的压缩有效性最终取决于发出的数据类型,但一般情况下,我们可以通过进行此更改来加速某些作业进程。
为什么不必在前面的代码中为输入文件指定压缩编解码器?默认情况下,FileInputFormat类使用CompressionCodecFactory来确定输入文件扩展名是否与已注册的编解码器匹配。如果找到与该文件扩展名相关联的编解码器,会自动使用该编解码器解压缩输入文件。
MapReduce如何知道要使用哪些编解码器?需要在mapred-site.xml中指定编解码器。 以下代码显示了如何注册上述提到的所有编解码器。请记住,除了gzip,Deflate和bzip2之外,所有压缩编解码器都需要构建并在集群上可用,然后才能注册:
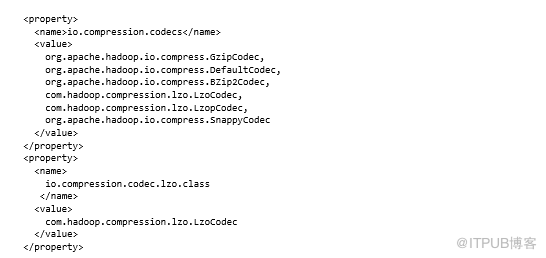
现在,你已经使用MapReduce掌握了压缩,是时候了解Hadoop堆栈信息了。因为压缩也可以与Pig和Hive一起使用,让我们看看如何使用Pig和Hive镜像完成MapReduce压缩。
在Pig中使用压缩
如果你正在使用Pig,那么使用压缩输入文件不需要额外的工作,需要做的就是确保文件扩展名map到相应的压缩编解码器(参见表4.4)。以下示例是gzips本地加密文件加载到Pig,并转储用户名的过程:
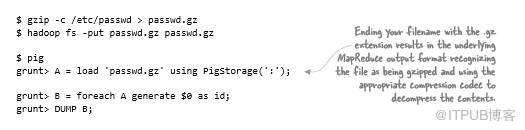

写gzip压缩文件是一样的,都要确保指定压缩编解码器的扩展名。以下示例将Pig关系B的结果存储在HDFS文件中,然后将它们复制到本地文件系统以检查内容:

在Hive中使用压缩
与Pig一样,我们需要做的就是在定义文件名时指定编解码器扩展:

前面的示例将一个gzip压缩文件加载到Hive中。在这种情况下,Hive将正在加载的文件移动到数据仓库目录,并继续使用原始文件作为表的存储。
如果要创建另一个表并指定需要被压缩该怎么办?下面的示例通过一些Hive配置来启用MapReduce压缩实现这一点(因为将执行MapReduce作业以在最后一个语句中加载新表):

我们可以通过在HDFS中查看来验证Hive是否确实压缩了新apachelog_backup表的存储:

应该注意的是,Hive建议使用SequenceFile作为表的输出格式,因为SequenceFile块可以单独压缩。
总结
此技术提供了一种在Hadoop中运行压缩的快速简便方法,这适用于不太大的文件,因为它提供了一种相对透明的压缩方式。如果压缩文件远大于HDFS块大小,请考虑以下方法。
可拆分LZOP,带有MapReduce,Hive和Pig
如果你正在使用大型文本文件,即使在压缩时,这也会比HDFS块大小大很多倍。为避免让一个map任务处理整个大型压缩文件,你需要选择一个可支持拆分该文件的压缩编解码器。
LZOP符合要求,但使用它比上文示例更复杂,因为LZOP本身不可拆分。因为LZOP是基于块的,不可能随机搜索LZOP文件并确定下一个块的起点,这是该方法面临的挑战。
问题
希望使用压缩编解码器,以允许MapReduce在单个压缩文件上并行工作。
解决方案
在MapReduce中,拆分大型LZOP压缩输入文件需要使用LZOP特定的输入格式类,例如LzoInputFormat。在Pig和Hive中使用LZOP压缩的输入文件时,同样的原则也适用。
讨论
LZOP压缩编解码器是仅有的允许拆分压缩文件的两个编解码器之一,因此多个Reducer可并行处理。另一个编解码器bzip2受到压缩时间的影响导致运行很慢,可能会导致编解码器无法使用,LZOP提供了压缩和速度之间的良好权衡。
LZO和LZOP有什么区别?LZO和LZOP编解码器都可用于Hadoop。LZO是一个基于流的压缩存储,没有块或头的概念。LZOP具有块(已校验和)的概念,因此是要使用的编解码器,尤其是在希望压缩输出可拆分的情况下。令人困惑的是,Hadoop编解码器默认情况下将以.lzo扩展名结尾的文件处理为LZOP编码,以.lzo_deflate扩展名结尾的文件处理为LZO编码。此外,许多文档似乎可以互换使用LZO和LZOP。
不幸的是,由于许可原因,Hadoop并未不捆绑LZOP。在集群上编译和安装LZOP非常费力,要编译本文代码,还请先行安装配置LZOP。
在HDFS中读写LZOP文件
如果要使用LZOP读写压缩文件,我们需要在代码中指定LZOP编解码器:

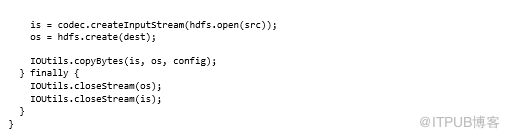
代码4.3在HDFS中读写LZOP文件的方法
让我们编写并读取LZOP文件,确保LZOP实用程序可以使用生成的文件(将$ HADOOP_CONF_HOME替换为Hadoop配置目录的位置):

以上代码将在HDFS中生成core-site.xml.lzo文件。
现在确保可以将此LZOP文件与lzop二进制文件一起使用。在主机上安装lzop二进制文件将LZOP文件从HDFS复制到本地磁盘,使用本机lzop二进制文件解压缩,并将其与原始文件进行比较:
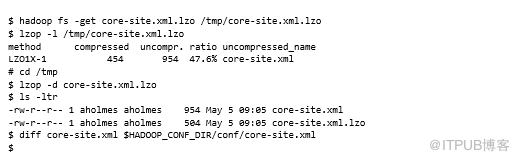
diff验证了使用LZOP编解码器压缩的文件可以使用lzop二进制文件解压缩。
既然已经拥有了LZOP文件,我们需要对其进行索引以便可以拆分。
为LZOP文件创建索引
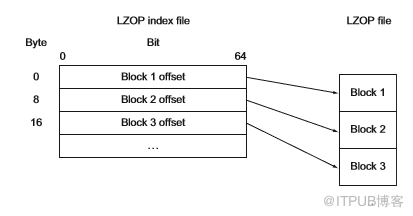
LZOP文件本身不可拆分,虽然其具有块的概念,但缺少块分隔同步标记意味着无法随机搜索LZOP文件并开始读取。但是因为在内部确实使用了块,所以只需要做一些预处理即可,它可以生成一个包含块偏移的索引文件。
完整读取LZOP文件,并在读取发生时将块偏移写入索引文件。索引文件格式(如图4.6所示)是一个二进制文件,包含一系列连续的64-bit数字,表示LZOP文件中每个块的字节偏移量。
你可以使用以下两种方式创建索引文件,如果要为单个LZOP文件创建索引文件,只需要进行一个简单的库调用即可,如下:
shell$ hadoop com.hadoop.compression.lzo.LzoIndexer core-site.xml.lzo
如果有大量LZOP文件并且需要更有效的方法来生成索引文件,索引器运行MapReduce作业以创建索引文件,支持文件和目录(以递归方式扫描LZOP文件):

图4.6中描述的两种方法都将在与LZOP文件相同的目录中生成索引文件。索引文件名是以.index为后缀的原始LZOP文件名。运行以前的命令将生成文件名core-site.xml.lzo.index。
接下来,我们来看看如何在Java代码中使用LzoIndexer。以下代码(来自LzoIndexer的主方法)将导致同步创建索引文件:
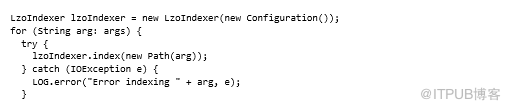
使用DistributedLzoIndexer,MapReduce作业将启动并运行N个mapper,每个.lzo文件一个。没有运行reducer,因此(identity)mapper通过自定义LzoSplitInputFormat和LzoIndexOutputFormat直接写入索引文件。
如果要从自己的Java代码运行MapReduce作业,可以使用DistributedLzoIndexer代码。
需要LZOP索引文件,以便可以在MapReduce,Pig和Hive作业中拆分LZOP文件。既然已经拥有了上述LZOP索引文件,让我们看一下如何将它们与MapReduce一起使用。
MapReduce和LZOP
在为LZOP文件创建索引文件之后,就可以开始将LZOP文件与MapReduce一起使用了。不幸的是,这给我们带来了下一个挑战:现有的基于Hadoop文件的内置输入格式都不适用于可拆分LZOP,因为它们需要专门的逻辑来处理使用LZOP索引文件的输入拆分。我们需要特定的输入格式类才能使用可拆分LZOP。
LZOP库为面向行的LZOP压缩文本文件提供了LzoTextInputFormat实现,并附带索引文件。
以下代码显示了配置MapReduce作业以使用LZOP所需的步骤。 我们将对具有文本LZOP输入和输出的MapReduce作业执行以下步骤:

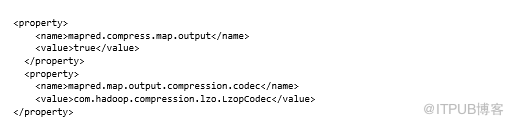
压缩中间map输出还将减少MapReduce作业的总体执行时间:

可以通过编辑hdfs-site.xml轻松配置集群以始终压缩map输出:
每个LZOP文件的拆分数量是文件占用的LZOP块数量的函数,而不是文件占用的HDFS块数量函数。
Pig和Hive
Elephant Bird,一个包含与LZOP一起工作的实用程序的Twitter项目,提供了许多有用的MapReduce和Pig类。Elephant Bird有一个LzoPigStorage类,可以在Pig中使用基于文本的LZOP压缩数据。
通过使用LZO库中的com.hadoop.mapred .DeprecatedLzoTextInputFormat输入格式类,Hive可以使用LZOP压缩的文本文件。
感谢各位的阅读,以上就是“怎么在HDFS中进行数据压缩”的内容了,经过本文的学习后,相信大家对怎么在HDFS中进行数据压缩这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。