您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章给大家分享的是有关Spark工作流程是怎样的呢,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
一、Spark架构组成图:
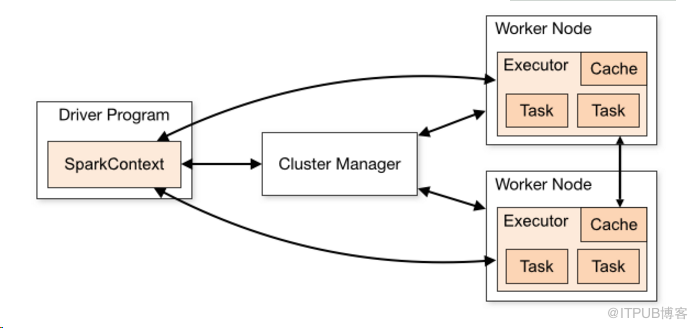
The following table summarizes terms you’ll see used to refer to cluster concepts:
| Term | Meaning |
|---|---|
| Application | 基于Spark的用户程序(创建了一个SparkContext).由一个driver 进程和N个executor 进程 on the cluster模式下. |
| Application jar | Spark包含的jar包 |
| Driver program | 一个Driver进程运行 main()方法,创建一个SparkContext |
| Cluster manager | 提交集群(--master local/standalone/on yarn)模式下的资源管理(提交设置code memory....) |
| Deploy mode | 区分Driver进程在什么地方cluster or client,主要区别是Driver在本地还是集群的Container里 |
| Worker node | 运行Spark代码的应用程序的节点(standalone模式概念),在(on yarn)模式下是NodeManager |
| Executor | 一个Executor进程,运行在Container里,能够运行我们Task,保存数据到内存里或者磁盘上,每一个应用程序有自己独立的Executor |
| Task | 最小的工作单元,Driver发送代码到Executor然后Task执行 |
| Job | 每一个Action就会产生job(map,conllect) |
| Stage | 每个Job被拆成Task集合,遇到shuffle会stage+1 |
以上就是Spark工作流程是怎样的呢,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。