жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
Kafka ConnectеҰӮдҪ•е®һзҺ°еҗҢжӯҘRDS binlogж•°жҚ®пјҢеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
дёӢйқўд»Ӣз»ҚеҰӮдҪ•еңЁE-MapReduceдёҠдҪҝз”ЁKafka Connectе®һзҺ°еҗҢжӯҘRDS binlogж•°жҚ®
гҖҖгҖҖ1. иғҢжҷҜ
гҖҖгҖҖеңЁжҲ‘们зҡ„дёҡеҠЎејҖеҸ‘дёӯпјҢеҫҖеҫҖдјҡзў°еҲ°дёӢйқўиҝҷдёӘеңәжҷҜпјҡ
гҖҖгҖҖдёҡеҠЎжӣҙж–°ж•°жҚ®еҶҷеҲ°ж•°жҚ®еә“дёӯ
гҖҖгҖҖдёҡеҠЎжӣҙж–°ж•°жҚ®йңҖиҰҒе®һж—¶дј йҖ’з»ҷдёӢжёёдҫқиө–еӨ„зҗҶ
гҖҖгҖҖжүҖд»Ҙдј з»ҹзҡ„еӨ„зҗҶжһ¶жһ„еҸҜиғҪдјҡиҝҷж ·пјҡ
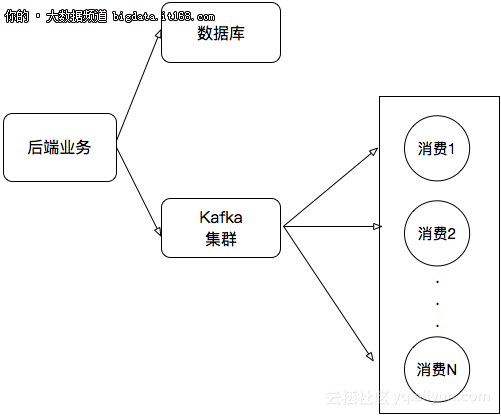
гҖҖгҖҖжң¬ж–Үе°Ҷжј”зӨәеҰӮдҪ•еңЁE-MapReduceдёҠе®һзҺ°е°ҶRDS binlogе®һж—¶еҗҢжӯҘеҲ°KafkaйӣҶзҫӨдёӯгҖӮ
гҖҖгҖҖ2. зҺҜеўғеҮҶеӨҮ
гҖҖгҖҖе®һйӘҢдёӯдҪҝз”ЁVPCзҪ‘з»ңзҺҜеўғпјҢд»ҘдёӢе®һдҫӢеҲӣе»әж—¶й»ҳи®ӨйғҪжҳҜеңЁVPCзҺҜеўғдёӢгҖӮ
гҖҖгҖҖ2.1 еҮҶеӨҮдёҖдёӘжөӢиҜ•RDSж•°жҚ®еә“
гҖҖгҖҖеҲӣе»әдёҖдёӘRDSе®һдҫӢпјҢзүҲжң¬йҖүжӢ©5.7гҖӮиҝҷйҮҢдёҚиөҳиҝ°еҰӮдҪ•еҲӣе»әRDSпјҢиҜҰз»ҶжөҒзЁӢиҜ·еҸӮиҖғRDSж–ҮжЎЈгҖӮеҲӣе»әе®ҢеҰӮеӣҫпјҡ
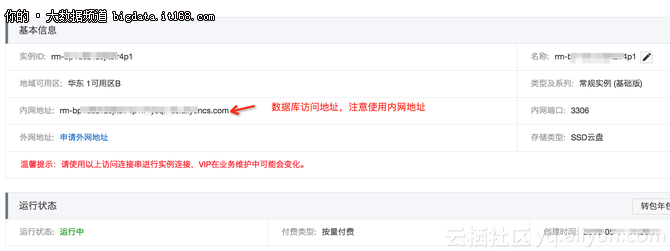
гҖҖгҖҖжіЁж„ҸпјҡRDSе®һдҫӢе’ҢE-MapReduce KafkaйӣҶзҫӨжңҖеҘҪеңЁеҗҢдёҖдёӘVPCдёӯпјҢеҗҰеҲҷйңҖиҰҒжү“йҖҡдёӨдёӘVPCд№Ӣй—ҙзҡ„зҪ‘з»ңгҖӮ
гҖҖгҖҖ3. Kafka Connect
гҖҖгҖҖ3.1 Connector
гҖҖгҖҖKafka ConnectжҳҜдёҖдёӘз”ЁдәҺKafkaе’Ңе…¶д»–ж•°жҚ®зі»з»ҹд№Ӣй—ҙиҝӣиЎҢж•°жҚ®дј иҫ“зҡ„е·Ҙе…·пјҢе®ғеҸҜд»Ҙе®һзҺ°еҹәдәҺKafkaзҡ„ж•°жҚ®з®ЎйҒ“пјҢжү“йҖҡдёҠдёӢжёёж•°жҚ®жәҗгҖӮжҲ‘们йңҖиҰҒеҒҡзҡ„е°ұжҳҜеңЁKafka ConnectжңҚеҠЎдёҠиҝҗиЎҢдёҖдёӘConnectorпјҢиҝҷдёӘConnectorжҳҜе…·дҪ“е®һзҺ°еҰӮдҪ•д»Һ/еҗ‘ж•°жҚ®жәҗдёӯиҜ»/еҶҷж•°жҚ®гҖӮConfluentжҸҗдҫӣдәҶеҫҲеӨҡConnectorе®һзҺ°пјҢдҪ еҸҜд»ҘеңЁиҝҷйҮҢдёӢиҪҪгҖӮдёҚиҝҮд»ҠеӨ©жҲ‘们дҪҝз”ЁDebeziumжҸҗдҫӣзҡ„дёҖдёӘMySQL ConnectorжҸ’件пјҢдёӢиҪҪең°еқҖгҖӮ
гҖҖгҖҖдёӢиҪҪиҝҷдёӘжҸ’件пјҢ并е°Ҷи§ЈеҺӢеҮәжқҘзҡ„jarеҢ…е…ЁйғЁжӢ·иҙқеҲ°kafka libзӣ®еҪ•дёӢгҖӮжіЁж„ҸпјҡйңҖиҰҒе°ҶиҝҷдәӣjarеҢ…жӢ·иҙқеҲ°KafkaйӣҶзҫӨжүҖжңүжңәеҷЁдёҠгҖӮ
гҖҖгҖҖеңЁKafkaйӣҶзҫӨзҡ„жңҚеҠЎеҲ—иЎЁдёӯйҮҚеҗҜKafka Connect组件гҖӮ
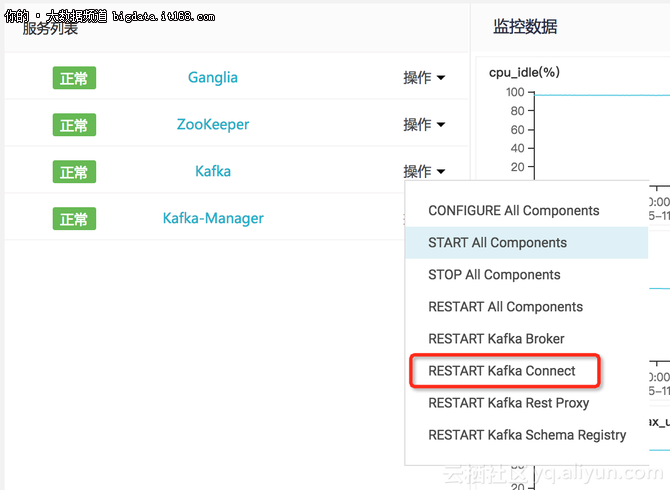
гҖҖгҖҖзҷ»еҪ•еҲ°KafkaйӣҶзҫӨпјҢй…ҚзҪ®е№¶еҲӣе»әдёҖдёӘconnectorпјҢе‘Ҫд»ӨеҰӮдёӢпјҡ
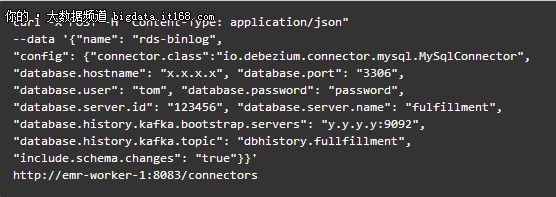
гҖҖгҖҖ3.3 жіЁж„ҸдәӢйЎ№
гҖҖгҖҖserver_idжҳҜеӨҡе°‘?пјҡдҪ еҸҜд»ҘеңЁRDSжү§иЎҢ"SELECT @@server_id;"жҹҘеҲ°гҖӮ
гҖҖгҖҖеҲӣе»әconnectorж—¶еҸҜиғҪдјҡеҮәзҺ°иҝһжҺҘеӨұиҙҘпјҢиҜ·зЎ®дҝқRDSзҡ„зҷҪеҗҚеҚ•е·Із»ҸжҺҲжқғдәҶKafkaйӣҶзҫӨжңәеҷЁи®ҝй—®гҖӮ
гҖҖгҖҖ4 жөӢиҜ•
гҖҖгҖҖ4.1 еҲӣе»әдёҖеј иЎЁ
гҖҖгҖҖжҸ’е…ҘеҮ жқЎж•°жҚ®

гҖҖгҖҖз»“жһңеҰӮеӣҫжүҖзӨәпјҡ

гҖҖ
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ