您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍如何使用Hive中自定义UDAF函数实现统计区域产品用户访问排名,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
UDAF实现方法:
1,用户的UDAF必须继承了org.apache.hadoop.hive.ql.exec.UDAF;
2,用户的UDAF必须包含至少一个实现了org.apache.hadoop.hive.ql.exec的静态类,诸如实现了 UDAFEvaluator
3,一个计算函数必须实现的5个方法的具体含义如下:
init():主要是负责初始化计算函数并且重设其内部状态,一般就是重设其内部字段。一般在静态类中定义一个内部字段来存放最终的结果。
iterate():每一次对一个新值进行聚集计算时候都会调用该方法,计算函数会根据聚集计算结果更新内部状态。当输 入值合法或者正确计算了,则 就返回true。
terminatePartial():Hive需要部分聚集结果的时候会调用该方法,必须要返回一个封装了聚集计算当前状态的对象。
merge():Hive进行合并一个部分聚集和另一个部分聚集的时候会调用该方法。
terminate():Hive最终聚集结果的时候就会调用该方法。计算函数需要把状态作为一个值返回给用户。
mapreduce阶段调用函数
MAP
init()
iterate()
terminatePartial()
Combiner
merge()
terminatePartial()
REDUCE
init()
merge()
terminate()
一、自定义UDAF函数
点击(此处)折叠或打开
此处)折叠或打开
DROP TEMPORARY FUNCTION user_click;
add jar /data/hive_udf-1.0.jar;
CREATE TEMPORARY FUNCTION user_click AS 'hive.org.ruozedata.UserClickUDAF';
三、调用自定义UDAF函数处理数据
点击(此处)折叠或打开
insert overwrite directory '/works/tmp1' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select regexp_replace(substring(rs, instr(rs, '=')+1), '}', '') from (
select explode(split(user_click(pcid, pcname, type),',')) as rs from (
select * from (
select '-2' as type, product_id as pcid, product_name as pcname from product_info
union all
select '-1' as type, city_id as pcid,area as pcname from city_info
union all
select count(1) as type,
product_id as pcid,
city_id as pcname
from user_click
where action_time='2016-05-05'
group by product_id,city_id
) a
order by type) b
) c
四、创建Hive临时外部表
点击(此处)折叠或打开
create external table tmp1(
city_name string,
product_name string,
rn string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
location '/works/tmp1';
五、-统计最终区域前3产品排名
点击(此处)折叠或打开
select * from (
select city_name,
product_name,
floor(sum(rn)) visit_num,
row_number()over(partition by city_name order by sum(rn) desc) rn,
'2016-05-05' action_time
from tmp1
group by city_name,product_name
) a where rn <=3
六、统计结果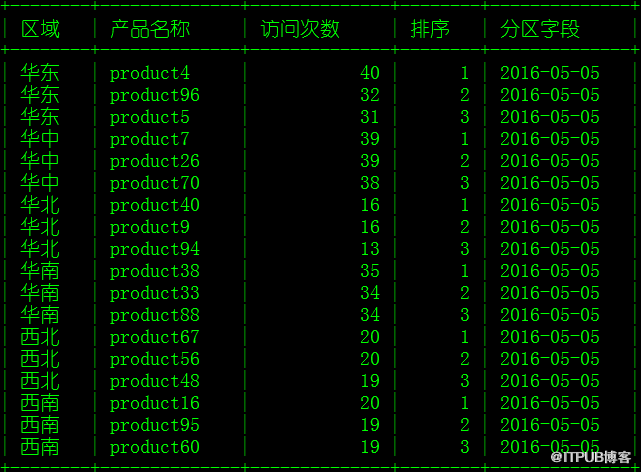
以上是“如何使用Hive中自定义UDAF函数实现统计区域产品用户访问排名”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。