您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要为大家展示了“Hive中Join方式有哪些”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Hive中Join方式有哪些”这篇文章吧。
Reduce Join在Hive中也叫Common Join或Shuffle Join
如果两边数据量都很大,它会进行把相同key的value合在一起,正好符合我们在sql中的join,然后再去组合,如图所示。
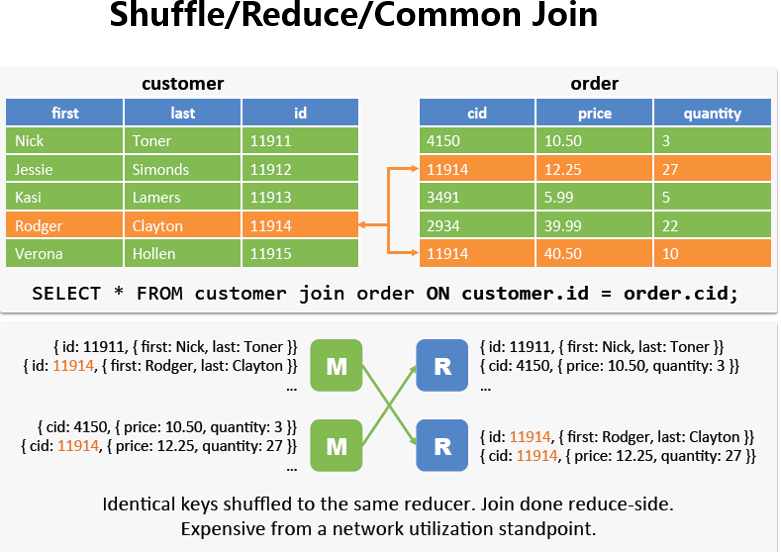
1) 大小表连接:
如果一张表的数据很大,另外一张表很少(<1000行),那么我们可以将数据量少的那张表放到内存里面,在map端做join。
Hive支持Map Join,用法如下
select /*+ MAPJOIN(time_dim) */ count(1) from store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
3) MAPJOIN 结合 UNIONALL
原始sql:
select a.*,coalesce(c.categoryid,’NA’) as app_category from (select * from t_aa_pvid_ctr_hour_js_mes1 ) a left outer join (select * fromt_qd_cmfu_book_info_mes ) c on a.app_id=c.book_id;
数据分布如下:
NA 617370129 2 118293314 1 40673814 d 20151236 b 1846306 s 1124246 5 675240 8 642231 6 611104 t 596973 4 579473 3 489516 7 475999 9 373395 107580 10508
设置:
当然也可以让hive自动识别,把join变成合适的Map Join如下所示
注:当设置为true的时候,hive会自动获取两张表的数据,判定哪个是小表,然后放在内存中
set hive.auto.convert.join=true; select count(*) from store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
场景:
大表对小表应该使用MapJoin,但是如果是大表对大表,如果进行shuffle,那就要人命了啊,第一个慢不用说,第二个容易出异常,既然是两个表进行join,肯定有相同的字段吧。
tb_a - 5亿(按排序分成五份,每份1亿放在指定的数值范围内,类似于分区表)
a_id
100001 ~ 110000 - bucket-01-a -1亿
110001 ~ 120000
120001 ~ 130000
130001 ~ 140000
140001 ~ 150000
tb_b - 5亿(同上,同一个桶只能和对应的桶内数据做join)
b_id
100001 ~ 110000 - bucket-01-b -1亿
110001 ~ 120000
120001 ~ 130000
130001 ~ 140000
140001 ~ 150000
注:实际生产环境中,一天的数据可能有50G(举例子可以把数据弄大点,比如说10亿分成1000个bucket)。
原理:
在运行SMB Join的时候会重新创建两张表,当然这是在后台默认做的,不需要用户主动去创建,如下所示:

设置(默认是false):
set hive.auto.convert.sortmerge.join=true set hive.optimize.bucketmapjoin=true; set hive.optimize.bucketmapjoin.sortedmerge=true;
以上是“Hive中Join方式有哪些”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。