жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іPythonдёӯжҖҺд№Ҳе®һзҺ°ж•°жҚ®жҢ–жҺҳпјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
第дёҖжӯҘпјҡеҠ иҪҪж•°жҚ®пјҢжөҸи§ҲдёҖдёӢ
и®©жҲ‘们跳иҝҮзңҹжӯЈзҡ„第дёҖжӯҘпјҲе®Ңе–„иө„ж–ҷпјҢдәҶи§ЈжҲ‘们иҰҒеҒҡзҡ„жҳҜд»Җд№ҲпјҢиҝҷеңЁе®һи·өиҝҮзЁӢдёӯжҳҜйқһеёёйҮҚиҰҒзҡ„пјүпјҢзӣҙжҺҘеҲ° https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection дёӢиҪҪ demo йҮҢйңҖиҰҒз”Ёзҡ„ zip ж–Ү件пјҢи§ЈеҺӢеҲ° data еӯҗзӣ®еҪ•дёӢгҖӮдҪ иғҪзңӢеҲ°дёҖдёӘеӨ§жҰӮ 0.5MB еӨ§е°ҸпјҢеҗҚдёә SMSSpamCollection зҡ„ж–Ү件пјҡ
Python
$ <span class="kw">ls</span> -l data <span class="kw">total</span> 1352 <span class="kw">-rw-r--r--@</span> 1 kofola staff 477907 Mar 15 2011 SMSSpamCollection <span class="kw">-rw-r--r--@</span> 1 kofola staff 5868 Apr 18 2011 readme <span class="kw">-rw-r-----@</span> 1 kofola staff 203415 Dec 1 15:30 smsspamcollection.zip |
з”өеҠЁchache
иҝҷд»Ҫж–Ү件еҢ…еҗ«дәҶ 5000 еӨҡд»Ҫ SMS жүӢжңәдҝЎжҒҜпјҲжҹҘзңӢ readme ж–Ү件д»ҘиҺ·еҫ—жӣҙеӨҡдҝЎжҒҜпјүпјҡ
In [2]:
messages = [line.rstrip() for line in open('./data/SMSSpamCollection')] print len(messages) |
5574
ж–Үжң¬йӣҶжңүж—¶еҖҷд№ҹз§°дёәвҖңиҜӯж–ҷеә“вҖқпјҢжҲ‘们жқҘжү“еҚ° SMS иҜӯж–ҷеә“дёӯзҡ„еүҚ 10 жқЎдҝЎжҒҜпјҡ
In [3]:
Python
for message_no, message in enumerate(messages[:10]): print message_no, message |
Python
0 ham Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat... 1 ham Ok lar... Joking wif u oni... 2 spam Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's 3 ham U dun say so early hor... U c already then say... 4 ham Nah I don't think he goes to usf, he lives around here though 5 spam FreeMsg Hey there darling it's been 3 week's now and no word back! I'd like some fun you up for it still? Tb ok! XxX std chgs to send, ?1.50 to rcv 6 ham Even my brother is not like to speak with me. They treat me like aids patent. 7 ham As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune 8 spam WINNER!! As a valued network customer you have been selected to receivea ?900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only. 9 spam Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030 |
жҲ‘们зңӢеҲ°дёҖдёӘ TSV ж–Ү件пјҲз”ЁеҲ¶иЎЁз¬Ұ tab еҲҶйҡ”пјүпјҢе®ғзҡ„第дёҖеҲ—жҳҜж Үи®°жӯЈеёёдҝЎжҒҜпјҲhamпјүжҲ–вҖңеһғеңҫж–Ү件вҖқпјҲspamпјүзҡ„ж ҮзӯҫпјҢ第дәҢеҲ—жҳҜдҝЎжҒҜжң¬иә«гҖӮ
иҝҷдёӘиҜӯж–ҷеә“е°ҶдҪңдёәеёҰж Үзӯҫзҡ„и®ӯз»ғйӣҶгҖӮйҖҡиҝҮдҪҝз”Ёиҝҷдәӣж Үи®°дәҶ ham/spam дҫӢеӯҗпјҢжҲ‘们е°Ҷи®ӯз»ғдёҖдёӘиҮӘеҠЁеҲҶиҫЁ ham/spam зҡ„жңәеҷЁеӯҰд№ жЁЎеһӢгҖӮ然еҗҺпјҢжҲ‘们еҸҜд»Ҙз”Ёи®ӯз»ғеҘҪзҡ„жЁЎеһӢе°Ҷд»»ж„ҸжңӘж Үи®°зҡ„дҝЎжҒҜж Үи®°дёә ham жҲ– spamгҖӮ
жҲ‘们еҸҜд»ҘдҪҝз”Ё Python зҡ„ Pandas еә“жӣҝжҲ‘们еӨ„зҗҶ TSV ж–Ү件пјҲжҲ– CSV ж–Ү件пјҢжҲ– Excel ж–Ү件пјүпјҡ
In [4]:
Python
messages = pandas.read_csv('./data/SMSSpamCollection', sep='t', quoting=csv.QUOTE_NONE, names=["label", "message"]) print messages |
Python
label message 0 ham Go until jurong point, crazy.. Available only ... 1 ham Ok lar... Joking wif u oni... 2 spam Free entry in 2 a wkly comp to win FA Cup fina... 3 ham U dun say so early hor... U c already then say... 4 ham Nah I don't think he goes to usf, he lives aro... 5 spam FreeMsg Hey there darling it's been 3 week's n... 6 ham Even my brother is not like to speak with me. ... 7 ham As per your request 'Melle Melle (Oru Minnamin... 8 spam WINNER!! As a valued network customer you have... 9 spam Had your mobile 11 months or more? U R entitle... 10 ham I'm gonna be home soon and i don't want to tal... 11 spam SIX chances to win CASH! From 100 to 20,000 po... 12 spam URGENT! You have won a 1 week FREE membership ... 13 ham I've been searching for the right words to tha... 14 ham I HAVE A DATE ON SUNDAY WITH WILL!! 15 spam XXXMobileMovieClub: To use your credit, click ... 16 ham Oh k...i'm watching here:) 17 ham Eh u remember how 2 spell his name... Yes i di... 18 ham Fine if that?s the way u feel. That?s the way ... 19 spam England v Macedonia - dont miss the goals/team... 20 ham Is that seriously how you spell his name? 21 ham IвҖҳm going to try for 2 months ha ha only joking 22 ham So Гј pay first lar... Then when is da stock co... 23 ham Aft i finish my lunch then i go str down lor. ... 24 ham Ffffffffff. Alright no way I can meet up with ... 25 ham Just forced myself to eat a slice. I'm really ... 26 ham Lol your always so convincing. 27 ham Did you catch the bus ? Are you frying an egg ... 28 ham I'm back &amp; we're packing the car now, I'll... 29 ham Ahhh. Work. I vaguely remember that! What does... ... ... ... 5544 ham Armand says get your ass over to epsilon 5545 ham U still havent got urself a jacket ah? 5546 ham I'm taking derek &amp; taylor to walmart, if I... 5547 ham Hi its in durban are you still on this number 5548 ham Ic. There are a lotta childporn cars then. 5549 spam Had your contract mobile 11 Mnths? Latest Moto... 5550 ham No, I was trying it all weekend ;V 5551 ham You know, wot people wear. T shirts, jumpers, ... 5552 ham Cool, what time you think you can get here? 5553 ham Wen did you get so spiritual and deep. That's ... 5554 ham Have a safe trip to Nigeria. Wish you happines... 5555 ham Hahaha..use your brain dear 5556 ham Well keep in mind I've only got enough gas for... 5557 ham Yeh. Indians was nice. Tho it did kane me off ... 5558 ham Yes i have. So that's why u texted. Pshew...mi... 5559 ham No. I meant the calculation is the same. That ... 5560 ham Sorry, I'll call later 5561 ham if you aren't here in the next &lt;#&gt; hou... 5562 ham Anything lor. Juz both of us lor. 5563 ham Get me out of this dump heap. My mom decided t... 5564 ham Ok lor... Sony ericsson salesman... I ask shuh... 5565 ham Ard 6 like dat lor. 5566 ham Why don't you wait 'til at least wednesday to ... 5567 ham Huh y lei... 5568 spam REMINDER FROM O2: To get 2.50 pounds free call... 5569 spam This is the 2nd time we have tried 2 contact u... 5570 ham Will Гј b going to esplanade fr home? 5571 ham Pity, * was in mood for that. So...any other s... 5572 ham The guy did some bitching but I acted like i'd... 5573 ham Rofl. Its true to its name
[5574 rows x 2 columns] |
жҲ‘们д№ҹеҸҜд»ҘдҪҝз”Ё pandas иҪ»жқҫжҹҘзңӢз»ҹи®ЎдҝЎжҒҜпјҡ
In [5]:
messages.groupby('label').describe() |
out[5]:
message | ||
| label | ||
| ham | count | 4827 |
| unique | 4518 | |
| top | Sorry, IвҖҷll call later | |
| freq | 30 | |
| spam | count | 747 |
| unique | 653 | |
| top | Please call our customer service representativвҖҰ | |
| freq | 4 |
иҝҷдәӣдҝЎжҒҜзҡ„й•ҝеәҰжҳҜеӨҡе°‘пјҡ
In [6]:
Python
messages['length'] = messages['message'].map(lambda text: len(text)) print messages.head() |
Python
label message length 0 ham Go until jurong point, crazy.. Available only ... 111 1 ham Ok lar... Joking wif u oni... 29 2 spam Free entry in 2 a wkly comp to win FA Cup fina... 155 3 ham U dun say so early hor... U c already then say... 49 4 ham Nah I don't think he goes to usf, he lives aro... 61 |
In [7]:
Python
messages.length.plot(bins=20, kind='hist') |
Out[7]:
Python
<matplotlib.axes._subplots.AxesSubplot at 0x10dd7a990> |
cdn2.b0.upaiyun.com/2015/02/7b930a617449365ee096983ea22bc78a.png">
In [8]:
Python
messages.length.describe() |
Out[8]:
Python
count 5574.000000 mean 80.604593 std 59.919970 min 2.000000 25% 36.000000 50% 62.000000 75% 122.000000 max 910.000000 Name: length, dtype: float64 |
е“ӘдәӣжҳҜи¶…й•ҝдҝЎжҒҜпјҹ
In [9]:
print list(messages.message[messages.length > 900]) |
["For me the love should start with attraction.i should feel that I need her every time around me.she should be the first thing which comes in my thoughts.I would start the day and end it with her.she should be there every time I dream.love will be then when my every breath has her name.my life should happen around her.my life will be named to her.I would cry for her.will give all my happiness and take all her sorrows.I will be ready to fight with anyone for her.I will be in love when I will be doing the craziest things for her.love will be when I don't have to proove anyone that my girl is the most beautiful lady on the whole planet.I will always be singing praises for her.love will be when I start up making chicken curry and end up makiing sambar.life will be the most beautiful then.will get every morning and thank god for the day because she is with me.I would like to say a lot..will tell later.."] |
spam дҝЎжҒҜдёҺ ham дҝЎжҒҜеңЁй•ҝеәҰдёҠжңүеҢәеҲ«еҗ—пјҹ
In [10]:
Python
messages.hist(column='length', by='label', bins=50) |
Out[10]:
Python
array([<matplotlib.axes._subplots.AxesSubplot object at 0x11270da50>, <matplotlib.axes._subplots.AxesSubplot object at 0x1126c7750>], dtype=object) |

еӨӘжЈ’дәҶпјҢдҪҶжҳҜжҲ‘们жҖҺд№ҲиғҪи®©з”өи„‘иҮӘе·ұиҜҶеҲ«ж–Үеӯ—дҝЎжҒҜпјҹе®ғеҸҜд»ҘзҗҶи§ЈиҝҷдәӣиғЎиЁҖд№ұиҜӯеҗ—пјҹ
иҝҷдёҖиҠӮжҲ‘们е°ҶеҺҹе§ӢдҝЎжҒҜпјҲеӯ—з¬ҰеәҸеҲ—пјүиҪ¬жҚўдёәеҗ‘йҮҸпјҲж•°еӯ—еәҸеҲ—пјүпјӣ
иҝҷйҮҢзҡ„жҳ 射并йқһдёҖеҜ№дёҖзҡ„пјҢжҲ‘们иҰҒз”ЁиҜҚиўӢжЁЎеһӢпјҲbag-of-wordsпјүжҠҠжҜҸдёӘдёҚйҮҚеӨҚзҡ„иҜҚз”ЁдёҖдёӘж•°еӯ—жқҘиЎЁзӨәгҖӮ
дёҺ第дёҖжӯҘзҡ„ж–№жі•дёҖж ·пјҢи®©жҲ‘们еҶҷдёҖдёӘе°ҶдҝЎжҒҜеҲҶеүІжҲҗеҚ•иҜҚзҡ„еҮҪж•°пјҡ
In [11]:
Python
def split_into_tokens(message): message = unicode(message, 'utf8') # convert bytes into proper unicode return TextBlob(message).words |
иҝҷиҝҳжҳҜеҺҹе§Ӣж–Үжң¬зҡ„дёҖйғЁеҲҶ:
In [12]:
Python
messages.message.head() |
Out[12]:
Python
0 Go until jurong point, crazy.. Available only ... 1 Ok lar... Joking wif u oni... 2 Free entry in 2 a wkly comp to win FA Cup fina... 3 U dun say so early hor... U c already then say... 4 Nah I don't think he goes to usf, he lives aro... Name: message, dtype: object |
иҝҷжҳҜеҺҹе§Ӣж–Үжң¬еӨ„зҗҶеҗҺзҡ„ж ·еӯҗпјҡ
In [13]:
Python
messages.message.head().apply(split_into_tokens) |
Out[13]:
Python
0 [Go, until, jurong, point, crazy, Available, o... 1 [Ok, lar, Joking, wif, u, oni] 2 [Free, entry, in, 2, a, wkly, comp, to, win, F... 3 [U, dun, say, so, early, hor, U, c, already, t... 4 [Nah, I, do, n't, think, he, goes, to, usf, he... Name: message, dtype: object |
иҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүзҡ„й—®йўҳпјҡ
еӨ§еҶҷеӯ—жҜҚжҳҜеҗҰжҗәеёҰдҝЎжҒҜпјҹ
еҚ•иҜҚзҡ„дёҚеҗҢеҪўејҸпјҲвҖңgoesвҖқе’ҢвҖңgoвҖқпјүжҳҜеҗҰжҗәеёҰдҝЎжҒҜпјҹ
еҸ№иҜҚе’Ңйҷҗе®ҡиҜҚжҳҜеҗҰжҗәеёҰдҝЎжҒҜпјҹ
жҚўеҸҘиҜқиҜҙпјҢжҲ‘们жғіеҜ№ж–Үжң¬иҝӣиЎҢжӣҙеҘҪзҡ„ж ҮеҮҶеҢ–гҖӮ
жҲ‘们дҪҝз”Ё textblob иҺ·еҸ– part-of-speech (POS) ж Үзӯҫпјҡ
In [14]:
Python
TextBlob("Hello world, how is it going?").tags # list of (word, POS) pairs |
Out[14]:
Python
[(u'Hello', u'UH'), (u'world', u'NN'), (u'how', u'WRB'), (u'is', u'VBZ'), (u'it', u'PRP'), (u'going', u'VBG')] |
并е°ҶеҚ•иҜҚж ҮеҮҶеҢ–дёәеҹәжң¬еҪўејҸ (lemmas)пјҡ
In [15]:
Python
def split_into_lemmas(message): message = unicode(message, 'utf8').lower() words = TextBlob(message).words # for each word, take its "base form" = lemma return [word.lemma for word in words]
messages.message.head().apply(split_into_lemmas) |
Out[15]:
0 [go, until, jurong, point, crazy, available, o... 1 [ok, lar, joking, wif, u, oni] 2 [free, entry, in, 2, a, wkly, comp, to, win, f... 3 [u, dun, say, so, early, hor, u, c, already, t... 4 [nah, i, do, n't, think, he, go, to, usf, he, ... Name: message, dtype: object |
иҝҷж ·е°ұеҘҪеӨҡдәҶгҖӮдҪ д№ҹи®ёиҝҳдјҡжғіеҲ°жӣҙеӨҡзҡ„ж–№жі•жқҘж”№иҝӣйў„еӨ„зҗҶпјҡи§Јз Ғ HTML е®һдҪ“пјҲжҲ‘们дёҠйқўзңӢеҲ°зҡ„ & е’Ң <пјүпјӣиҝҮж»ӨжҺүеҒңз”ЁиҜҚ (д»ЈиҜҚзӯү)пјӣж·»еҠ жӣҙеӨҡзү№еҫҒпјҢжҜ”еҰӮжүҖжңүеӯ—жҜҚеӨ§еҶҷж ҮиҜҶзӯүзӯүгҖӮ
зҺ°еңЁпјҢжҲ‘们е°ҶжҜҸжқЎж¶ҲжҒҜпјҲиҜҚе№ІеҲ—иЎЁпјүиҪ¬жҚўжҲҗжңәеҷЁеӯҰд№ жЁЎеһӢеҸҜд»ҘзҗҶи§Јзҡ„еҗ‘йҮҸгҖӮ
з”ЁиҜҚиўӢжЁЎеһӢе®ҢжҲҗиҝҷйЎ№е·ҘдҪңйңҖиҰҒдёүдёӘжӯҘйӘӨпјҡ
1. еҜ№жҜҸдёӘиҜҚеңЁжҜҸжқЎдҝЎжҒҜдёӯеҮәзҺ°зҡ„ж¬Ўж•°иҝӣиЎҢи®Ўж•°пјҲиҜҚйў‘пјүпјӣ
2. еҜ№и®Ўж•°иҝӣиЎҢеҠ жқғпјҢиҝҷж ·з»ҸеёёеҮәзҺ°зҡ„еҚ•иҜҚе°ҶдјҡиҺ·еҫ—иҫғдҪҺзҡ„жқғйҮҚпјҲйҖҶеҗ‘ж–Ү件频зҺҮпјүпјӣ
3. е°Ҷеҗ‘йҮҸз”ұеҺҹе§Ӣж–Үжң¬й•ҝеәҰеҪ’дёҖеҢ–еҲ°еҚ•дҪҚй•ҝеәҰпјҲL2 иҢғејҸпјүгҖӮ
жҜҸдёӘеҗ‘йҮҸзҡ„з»ҙеәҰзӯүдәҺ SMS иҜӯж–ҷеә“дёӯеҢ…еҗ«зҡ„зӢ¬з«ӢиҜҚзҡ„ж•°йҮҸгҖӮ
In [16]:
Python
bow_transformer = CountVectorizer(analyzer=split_into_lemmas).fit(messages['message']) print len(bow_transformer.vocabulary_) |
Python
8874 |
иҝҷйҮҢжҲ‘们дҪҝз”ЁејәеӨ§зҡ„ python жңәеҷЁеӯҰд№ и®ӯз»ғеә“ scikit-learn (sklearn)пјҢе®ғеҢ…еҗ«еӨ§йҮҸзҡ„ж–№жі•е’ҢйҖүйЎ№гҖӮ
жҲ‘们еҸ–дёҖдёӘдҝЎжҒҜ并дҪҝз”Ёж–°зҡ„ bow_tramsformer иҺ·еҸ–еҗ‘йҮҸеҪўејҸзҡ„иҜҚиўӢжЁЎеһӢи®Ўж•°:
In [17]:
Python
message4 = messages['message'][3] print message4 |
Python
U dun say so early hor... U c already then say... |
In [18]:
Python
bow4 = bow_transformer.transform([message4]) print bow4 print bow4.shape |
Python
(0, 1158) 1 (0, 1899) 1 (0, 2897) 1 (0, 2927) 1 (0, 4021) 1 (0, 6736) 2 (0, 7111) 1 (0, 7698) 1 (0, 8013) 2 (1, 8874) |
message 4 дёӯжңү 9 дёӘзӢ¬з«ӢиҜҚпјҢе®ғ们дёӯзҡ„дёӨдёӘеҮәзҺ°дәҶдёӨж¬ЎпјҢе…¶дҪҷзҡ„еҸӘеҮәзҺ°дәҶдёҖж¬ЎгҖӮеҸҜз”ЁжҖ§жЈҖжөӢпјҢе“ӘдәӣиҜҚеҮәзҺ°дәҶдёӨж¬Ўпјҹ
In [19]:
Python
print bow_transformer.get_feature_names()[6736] print bow_transformer.get_feature_names()[8013] |
Python
say u |
ж•ҙдёӘ SMS иҜӯж–ҷеә“зҡ„иҜҚиўӢи®Ўж•°жҳҜдёҖдёӘеәһеӨ§зҡ„зЁҖз–Ҹзҹ©йҳөпјҡ
In [20]:
Python
messages_bow = bow_transformer.transform(messages['message']) print 'sparse matrix shape:', messages_bow.shape print 'number of non-zeros:', messages_bow.nnz print 'sparsity: %.2f%%' % (100.0 * messages_bow.nnz / (messages_bow.shape[0] * messages_bow.shape[1])) |
Python
sparse matrix shape: (5574, 8874) number of non-zeros: 80272 sparsity: 0.16% |
жңҖз»ҲпјҢи®Ўж•°еҗҺпјҢдҪҝз”Ё scikit-learn зҡ„ TFidfTransformer е®һзҺ°зҡ„ TF-IDF е®ҢжҲҗиҜҚиҜӯеҠ жқғе’ҢеҪ’дёҖеҢ–гҖӮ
In [21]:
Python
tfidf_transformer = TfidfTransformer().fit(messages_bow) tfidf4 = tfidf_transformer.transform(bow4) print tfidf4 |
Python
(0, 8013) 0.305114653686 (0, 7698) 0.225299911221 (0, 7111) 0.191390347987 (0, 6736) 0.523371210191 (0, 4021) 0.456354991921 (0, 2927) 0.32967579251 (0, 2897) 0.303693312742 (0, 1899) 0.24664322833 (0, 1158) 0.274934159477 |
еҚ•иҜҚ вҖңuвҖқ зҡ„ IDFпјҲйҖҶеҗ‘ж–Ү件频зҺҮпјүжҳҜд»Җд№ҲпјҹеҚ•иҜҚвҖңuniversityвҖқзҡ„ IDF еҸҲжҳҜд»Җд№Ҳпјҹ
In [22]:
Python
print tfidf_transformer.idf_[bow_transformer.vocabulary_['u']] print tfidf_transformer.idf_[bow_transformer.vocabulary_['university']] |
Python
2.85068150539 8.23975323521 |
е°Ҷж•ҙдёӘ bag-of-words иҜӯж–ҷеә“иҪ¬еҢ–дёә TF-IDF иҜӯж–ҷеә“гҖӮ
In [23]:
Python
messages_tfidf = tfidf_transformer.transform(messages_bow) print messages_tfidf.shape |
Python
(5574, 8874) |
жңүи®ёеӨҡж–№жі•еҸҜд»ҘеҜ№ж•°жҚ®иҝӣиЎҢйў„еӨ„зҗҶе’Ңеҗ‘йҮҸеҢ–гҖӮиҝҷдёӨдёӘжӯҘйӘӨд№ҹеҸҜд»Ҙз§°дёәвҖңзү№еҫҒе·ҘзЁӢвҖқпјҢе®ғ们йҖҡеёёжҳҜйў„жөӢиҝҮзЁӢдёӯжңҖиҖ—ж—¶й—ҙе’ҢжңҖж— и¶Јзҡ„йғЁеҲҶпјҢдҪҶжҳҜе®ғ们йқһеёёйҮҚиҰҒ并且йңҖиҰҒз»ҸйӘҢгҖӮиҜҖзӘҚеңЁдәҺеҸҚеӨҚиҜ„дј°пјҡеҲҶжһҗжЁЎеһӢиҜҜе·®пјҢж”№иҝӣж•°жҚ®жё…жҙ—е’Ңйў„еӨ„зҗҶж–№жі•пјҢиҝӣиЎҢеӨҙи„‘йЈҺжҡҙи®Ёи®әж–°еҠҹиғҪпјҢиҜ„дј°зӯүзӯүгҖӮ
жҲ‘们дҪҝз”Ёеҗ‘йҮҸеҪўејҸзҡ„дҝЎжҒҜжқҘи®ӯз»ғ spam/ham еҲҶзұ»еҷЁгҖӮиҝҷйғЁеҲҶеҫҲз®ҖеҚ•пјҢжңүеҫҲеӨҡе®һзҺ°и®ӯз»ғз®—жі•зҡ„еә“ж–Ү件гҖӮ
иҝҷйҮҢжҲ‘们дҪҝз”Ё scikit-learnпјҢйҰ–е…ҲйҖүжӢ© Naive Bayes еҲҶзұ»еҷЁпјҡ
In [24]:
Python
%time spam_detector = MultinomialNB().fit(messages_tfidf, messages['label']) |
Python
CPU times: user 4.51 ms, sys: 987 ?s, total: 5.49 ms Wall time: 4.77 ms |
жҲ‘们жқҘиҜ•зқҖеҲҶзұ»дёҖдёӘйҡҸжңәдҝЎжҒҜпјҡ
In [25]:
Python
print 'predicted:', spam_detector.predict(tfidf4)[0] print 'expected:', messages.label[3] |
Python
predicted: ham expected: ham |
еӨӘжЈ’дәҶпјҒдҪ д№ҹеҸҜд»Ҙз”ЁиҮӘе·ұзҡ„ж–Үжң¬иҜ•иҜ•гҖӮ
жңүдёҖдёӘеҫҲиҮӘ然зҡ„й—®йўҳжҳҜпјҡжҲ‘们еҸҜд»ҘжӯЈзЎ®еҲҶиҫЁеӨҡе°‘дҝЎжҒҜпјҹ
In [26]:
Python
all_predictions = spam_detector.predict(messages_tfidf) print all_predictions |
Python
['ham' 'ham' 'spam' ..., 'ham' 'ham' 'ham'] |
In [27]:
Python
print 'accuracy', accuracy_score(messages['label'], all_predictions) print 'confusion matrixn', confusion_matrix(messages['label'], all_predictions) print '(row=expected, col=predicted)' |
Python
accuracy 0.969501255831 confusion matrix [[4827 0] [ 170 577]] (row=expected, col=predicted) |
In [28]:
Python
plt.matshow(confusion_matrix(messages['label'], all_predictions), cmap=plt.cm.binary, interpolation='nearest') plt.title('confusion matrix') plt.colorbar() plt.ylabel('expected label') plt.xlabel('predicted label') |
Out[28]:
Python
<matplotlib.text.Text at 0x11643f6d0> |

жҲ‘们еҸҜд»ҘйҖҡиҝҮиҝҷдёӘж··ж·Ҷзҹ©йҳөи®Ўз®—зІҫеәҰпјҲprecisionпјүе’ҢеҸ¬еӣһзҺҮпјҲrecallпјүпјҢжҲ–иҖ…е®ғ们зҡ„з»„еҗҲпјҲи°ғе’Ңе№іеқҮеҖјпјүF1пјҡ
In [29]:
Python
print classification_report(messages['label'], all_predictions) |
Python
precision recall f1-score support
ham 0.97 1.00 0.98 4827 spam 1.00 0.77 0.87 747
avg / total 0.97 0.97 0.97 5574 |
жңүзӣёеҪ“еӨҡзҡ„жҢҮж ҮйғҪеҸҜд»Ҙз”ЁжқҘиҜ„дј°жЁЎеһӢжҖ§иғҪпјҢиҮідәҺе“ӘдёӘжңҖеҗҲйҖӮжҳҜз”ұд»»еҠЎеҶіе®ҡзҡ„гҖӮжҜ”еҰӮпјҢе°ҶвҖңspamвҖқй”ҷиҜҜйў„жөӢдёәвҖңhamвҖқзҡ„жҲҗжң¬иҝңдҪҺдәҺе°ҶвҖңhamвҖқй”ҷиҜҜйў„жөӢдёәвҖңspamвҖқзҡ„жҲҗжң¬гҖӮ
еңЁдёҠиҝ°вҖңиҜ„д»·вҖқдёӯпјҢжҲ‘们зҠҜдәҶдёӘеӨ§еҝҢгҖӮдёәдәҶз®ҖеҚ•зҡ„жј”зӨәпјҢжҲ‘们дҪҝз”Ёи®ӯз»ғж•°жҚ®иҝӣиЎҢдәҶеҮҶзЎ®жҖ§иҜ„дј°гҖӮж°ёиҝңдёҚиҰҒиҜ„дј°дҪ зҡ„и®ӯз»ғж•°жҚ®гҖӮиҝҷжҳҜй”ҷиҜҜзҡ„гҖӮ
иҝҷж ·зҡ„иҜ„дј°ж–№жі•дёҚиғҪе‘ҠиҜүжҲ‘们模еһӢзҡ„е®һйҷ…йў„жөӢиғҪеҠӣпјҢеҰӮжһңжҲ‘们记дҪҸи®ӯз»ғжңҹй—ҙзҡ„жҜҸдёӘдҫӢеӯҗпјҢи®ӯз»ғзҡ„еҮҶзЎ®зҺҮе°ҶйқһеёёжҺҘиҝ‘ 100%пјҢдҪҶжҳҜжҲ‘们дёҚиғҪз”Ёе®ғжқҘеҲҶзұ»д»»дҪ•ж–°дҝЎжҒҜгҖӮ
дёҖдёӘжӯЈзЎ®зҡ„еҒҡжі•жҳҜе°Ҷж•°жҚ®еҲҶдёәи®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶпјҢеңЁжЁЎеһӢжӢҹеҗҲе’Ңи°ғеҸӮж—¶еҸӘиғҪдҪҝз”Ёи®ӯз»ғж•°жҚ®пјҢдёҚиғҪд»Ҙд»»дҪ•ж–№ејҸдҪҝз”ЁжөӢиҜ•ж•°жҚ®пјҢйҖҡиҝҮиҝҷдёӘж–№жі•зЎ®дҝқжЁЎеһӢжІЎжңүвҖңдҪңејҠвҖқпјҢжңҖз»ҲдҪҝз”ЁжөӢиҜ•ж•°жҚ®иҜ„д»·жЁЎеһӢеҸҜд»Ҙд»ЈиЎЁжЁЎеһӢзңҹжӯЈзҡ„йў„жөӢжҖ§иғҪгҖӮ
In [30]:
Python
msg_train, msg_test, label_train, label_test = train_test_split(messages['message'], messages['label'], test_size=0.2)
print len(msg_train), len(msg_test), len(msg_train) + len(msg_test) |
Python
4459 1115 5574 |
жҢүз…§иҰҒжұӮпјҢжөӢиҜ•ж•°жҚ®еҚ ж•ҙдёӘж•°жҚ®йӣҶзҡ„ 20%пјҲжҖ»е…ұ 5574 жқЎи®°еҪ•дёӯзҡ„ 1115 жқЎпјүпјҢе…¶дҪҷзҡ„жҳҜи®ӯз»ғж•°жҚ®пјҲ5574 жқЎдёӯзҡ„ 4459 жқЎпјүгҖӮ
и®©жҲ‘们еӣһйЎҫж•ҙдёӘжөҒзЁӢпјҢе°ҶжүҖжңүжӯҘйӘӨж”ҫе…Ҙ scikit-learn зҡ„ Pipeline дёӯ:
In [31]:
Python
def split_into_lemmas(message): message = unicode(message, 'utf8').lower() words = TextBlob(message).words # for each word, take its "base form" = lemma return [word.lemma for word in words]
pipeline = Pipeline([ ('bow', CountVectorizer(analyzer=split_into_lemmas)), # strings to token integer counts ('tfidf', TfidfTransformer()), # integer counts to weighted TF-IDF scores ('classifier', MultinomialNB()), # train on TF-IDF vectors w/ Naive Bayes classifier ]) |
е®һйҷ…еҪ“дёӯдёҖдёӘеёёи§Ғзҡ„еҒҡжі•жҳҜе°Ҷи®ӯз»ғйӣҶеҶҚж¬ЎеҲҶеүІжҲҗжӣҙе°Ҹзҡ„йӣҶеҗҲпјҢдҫӢеҰӮпјҢ5 дёӘеӨ§е°Ҹзӣёзӯүзҡ„еӯҗйӣҶгҖӮ然еҗҺжҲ‘们用 4 дёӘеӯҗйӣҶи®ӯз»ғж•°жҚ®пјҢз”ЁжңҖеҗҺ 1 дёӘеӯҗйӣҶи®Ўз®—зІҫеәҰпјҲз§°д№ӢдёәвҖңйӘҢиҜҒйӣҶвҖқпјүгҖӮйҮҚеӨҚ5ж¬ЎпјҲжҜҸж¬ЎдҪҝз”ЁдёҚеҗҢзҡ„еӯҗйӣҶиҝӣиЎҢйӘҢиҜҒпјүпјҢиҝҷж ·еҸҜд»Ҙеҫ—еҲ°жЁЎеһӢзҡ„вҖңзЁіе®ҡжҖ§вҖңгҖӮеҰӮжһңжЁЎеһӢдҪҝз”ЁдёҚеҗҢеӯҗйӣҶзҡ„еҫ—еҲҶе·®ејӮйқһеёёеӨ§пјҢйӮЈд№ҲеҫҲеҸҜиғҪе“ӘйҮҢеҮәй”ҷдәҶпјҲеқҸж•°жҚ®жҲ–иҖ…дёҚиүҜзҡ„жЁЎеһӢж–№е·®пјүгҖӮиҝ”еӣһпјҢеҲҶжһҗй”ҷиҜҜпјҢйҮҚж–°жЈҖжҹҘиҫ“е…Ҙж•°жҚ®жңүж•ҲжҖ§пјҢйҮҚж–°жЈҖжҹҘж•°жҚ®жё…жҙ—гҖӮ
еңЁиҝҷдёӘдҫӢеӯҗйҮҢпјҢдёҖеҲҮиҝӣеұ•йЎәеҲ©пјҡ
In [32]:
Python
scores = cross_val_score(pipeline, # steps to convert raw messages into models msg_train, # training data label_train, # training labels cv=10, # split data randomly into 10 parts: 9 for training, 1 for scoring scoring='accuracy', # which scoring metric? n_jobs=-1, # -1 = use all cores = faster ) print scores |
Python
[ 0.93736018 0.96420582 0.94854586 0.94183445 0.96412556 0.94382022 0.94606742 0.96404494 0.94831461 0.94606742] |
еҫ—еҲҶзЎ®е®һжҜ”и®ӯз»ғе…ЁйғЁж•°жҚ®ж—¶е·®дёҖзӮ№зӮ№пјҲ 5574 дёӘи®ӯз»ғдҫӢеӯҗдёӯпјҢеҮҶзЎ®жҖ§ 0.97пјүпјҢдҪҶжҳҜе®ғ们зӣёеҪ“зЁіе®ҡпјҡ
In [33]:
Python
print scores.mean(), scores.std() |
Python
0.9504386476 0.00947200821389 |
жҲ‘们иҮӘ然дјҡй—®пјҢеҰӮдҪ•ж”№иҝӣиҝҷдёӘжЁЎеһӢпјҹиҝҷдёӘеҫ—еҲҶе·Із»ҸеҫҲй«ҳдәҶпјҢдҪҶжҳҜжҲ‘们йҖҡеёёеҰӮдҪ•ж”№иҝӣжЁЎеһӢе‘ўпјҹ
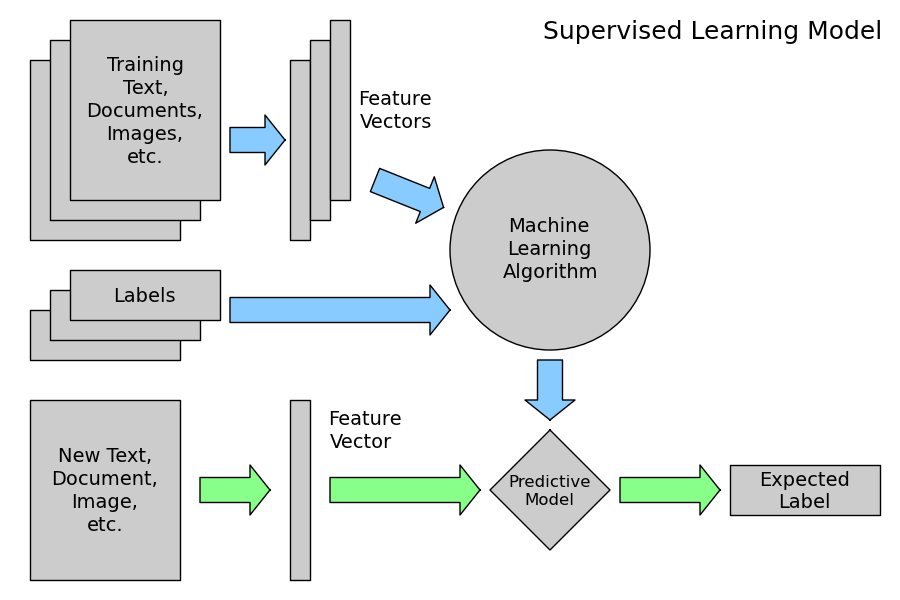
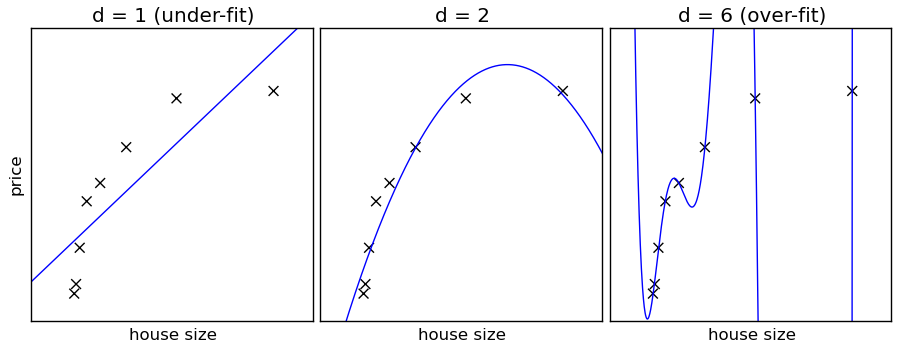
Naive Bayes жҳҜдёҖдёӘй«ҳеҒҸе·®-дҪҺж–№е·®зҡ„еҲҶзұ»еҷЁпјҲз®ҖеҚ•дё”зЁіе®ҡпјҢдёҚжҳ“иҝҮеәҰжӢҹеҗҲпјүгҖӮдёҺе…¶зӣёеҸҚзҡ„дҫӢеӯҗжҳҜдҪҺеҒҸе·®-й«ҳж–№е·®пјҲе®№жҳ“иҝҮеәҰжӢҹеҗҲпјүзҡ„ k жңҖдёҙиҝ‘пјҲkNNпјүеҲҶзұ»еҷЁе’ҢеҶізӯ–ж ‘гҖӮBaggingпјҲйҡҸжңәжЈ®жһ—пјүжҳҜдёҖз§ҚйҖҡиҝҮи®ӯз»ғи®ёеӨҡпјҲй«ҳж–№е·®пјүжЁЎеһӢе’ҢжұӮеқҮеҖјжқҘйҷҚдҪҺж–№е·®зҡ„ж–№жі•гҖӮ
жҚўеҸҘиҜқиҜҙпјҡ
й«ҳеҒҸе·® = еҲҶзұ»еҷЁжҜ”иҫғеӣәжү§гҖӮе®ғжңүиҮӘе·ұзҡ„жғіжі•пјҢж•°жҚ®иғҪеӨҹж”№еҸҳзҡ„з©әй—ҙжңүйҷҗгҖӮеҸҰдёҖж–№йқўпјҢд№ҹжІЎжңүеӨҡе°‘иҝҮеәҰжӢҹеҗҲзҡ„з©әй—ҙпјҲе·ҰеӣҫпјүгҖӮ
дҪҺеҒҸе·® = еҲҶзұ»еҷЁжӣҙеҗ¬иҜқпјҢдҪҶд№ҹжӣҙзҘһз»ҸиҙЁгҖӮеӨ§е®¶йғҪзҹҘйҒ“пјҢи®©е®ғеҒҡд»Җд№Ҳе°ұеҒҡд»Җд№ҲеҸҜиғҪйҖ жҲҗйә»зғҰпјҲеҸіеӣҫпјүгҖӮ
In [34]:
Python
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=-1, train_sizes=np.linspace(.1, 1.0, 5)): """ Generate a simple plot of the test and traning learning curve.
Parameters ---------- estimator : object type that implements the "fit" and "predict" methods An object of that type which is cloned for each validation.
title : string Title for the chart.
X : array-like, shape (n_samples, n_features) Training vector, where n_samples is the number of samples and n_features is the number of features.
y : array-like, shape (n_samples) or (n_samples, n_features), optional Target relative to X for classification or regression; None for unsupervised learning.
ylim : tuple, shape (ymin, ymax), optional Defines minimum and maximum yvalues plotted.
cv : integer, cross-validation generator, optional If an integer is passed, it is the number of folds (defaults to 3). Specific cross-validation objects can be passed, see sklearn.cross_validation module for the list of possible objects
n_jobs : integer, optional Number of jobs to run in parallel (default 1). """ plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Training examples") plt.ylabel("Score") train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")
plt.legend(loc="best") return plt |
In [35]:
Python
%time plot_learning_curve(pipeline, "accuracy vs. training set size", msg_train, label_train, cv=5) |
Python
CPU times: user 382 ms, sys: 83.1 ms, total: 465 ms Wall time: 28.5 s |
Out[35]:
Python
<module 'matplotlib.pyplot' from '/Volumes/work/workspace/vew/sklearn_intro/lib/python2.7/site-packages/matplotlib/pyplot.pyc'> |

пјҲжҲ‘们еҜ№ж•°жҚ®зҡ„ 64% иҝӣиЎҢдәҶжңүж•Ҳи®ӯз»ғпјҡдҝқз•ҷ 20% зҡ„ж•°жҚ®дҪңдёәжөӢиҜ•йӣҶпјҢдҝқз•ҷеү©дҪҷзҡ„ 20% еҒҡ 5 жҠҳдәӨеҸүйӘҢиҜҒ = > 0.8*0.8*5574 = 3567дёӘи®ӯз»ғж•°жҚ®гҖӮпјү
йҡҸзқҖжҖ§иғҪзҡ„жҸҗеҚҮпјҢи®ӯз»ғе’ҢдәӨеҸүйӘҢиҜҒйғҪиЎЁзҺ°иүҜеҘҪпјҢжҲ‘们еҸ‘зҺ°з”ұдәҺж•°жҚ®йҮҸиҫғе°‘пјҢиҝҷдёӘжЁЎеһӢйҡҫд»Ҙи¶іеӨҹеӨҚжқӮ/зҒөжҙ»ең°жҚ•иҺ·жүҖжңүзҡ„з»Ҷеҫ®е·®еҲ«гҖӮеңЁиҝҷз§Қзү№ж®ҠжЎҲдҫӢдёӯпјҢдёҚз®ЎжҖҺж ·еҒҡзІҫеәҰйғҪеҫҲй«ҳпјҢиҝҷдёӘй—®йўҳзңӢиө·жқҘдёҚжҳҜеҫҲжҳҺжҳҫгҖӮ
е…ідәҺиҝҷдёҖзӮ№пјҢжҲ‘们жңүдёӨдёӘйҖүжӢ©пјҡ
дҪҝз”ЁжӣҙеӨҡзҡ„и®ӯз»ғж•°жҚ®пјҢеўһеҠ жЁЎеһӢзҡ„еӨҚжқӮжҖ§пјӣ
дҪҝз”ЁжӣҙеӨҚжқӮпјҲжӣҙдҪҺеҒҸе·®пјүзҡ„жЁЎеһӢпјҢд»ҺзҺ°жңүж•°жҚ®дёӯиҺ·еҸ–жӣҙеӨҡдҝЎжҒҜгҖӮ
еңЁиҝҮеҺ»зҡ„еҮ е№ҙйҮҢпјҢйҡҸзқҖ收йӣҶеӨ§и§„жЁЎи®ӯз»ғж•°жҚ®и¶ҠжқҘи¶Ҡе®№жҳ“пјҢжңәеҷЁи¶ҠжқҘи¶Ҡеҝ«гҖӮж–№жі• 1 еҸҳеҫ—и¶ҠжқҘи¶ҠжөҒиЎҢпјҲжӣҙз®ҖеҚ•зҡ„з®—жі•пјҢжӣҙеӨҡзҡ„ж•°жҚ®пјүгҖӮз®ҖеҚ•зҡ„з®—жі•пјҲеҰӮ Naive Bayesпјүд№ҹжңүжӣҙе®№жҳ“и§ЈйҮҠзҡ„йўқеӨ–дјҳеҠҝпјҲзӣёеҜ№дёҖдәӣжӣҙеӨҚжқӮзҡ„й»‘з®ұжЁЎеһӢпјҢеҰӮзҘһз»ҸзҪ‘з»ңпјүгҖӮ
дәҶи§ЈдәҶеҰӮдҪ•жӯЈзЎ®ең°иҜ„дј°жЁЎеһӢпјҢжҲ‘们зҺ°еңЁеҸҜд»ҘејҖе§Ӣз ”з©¶еҸӮж•°еҜ№жҖ§иғҪжңүе“ӘдәӣеҪұе“ҚгҖӮ
еҲ°зӣ®еүҚдёәжӯўпјҢжҲ‘们зңӢеҲ°зҡ„еҸӘжҳҜеҶ°еұұдёҖи§’пјҢиҝҳжңүи®ёеӨҡе…¶е®ғеҸӮж•°йңҖиҰҒи°ғж•ҙгҖӮжҜ”еҰӮдҪҝз”Ёд»Җд№Ҳз®—жі•иҝӣиЎҢи®ӯз»ғгҖӮ
дёҠйқўжҲ‘们已з»ҸдҪҝз”ЁдәҶ Navie BayesпјҢдҪҶжҳҜ scikit-learn ж”ҜжҢҒи®ёеӨҡеҲҶзұ»еҷЁпјҡж”ҜжҢҒеҗ‘йҮҸжңәгҖҒжңҖйӮ»иҝ‘з®—жі•гҖҒеҶізӯ–ж ‘гҖҒEnsamble ж–№жі•зӯүвҖҰ

жҲ‘们дјҡй—®пјҡIDF еҠ жқғеҜ№еҮҶзЎ®жҖ§жңүд»Җд№ҲеҪұе“Қпјҹж¶ҲиҖ—йўқеӨ–жҲҗжң¬иҝӣиЎҢиҜҚеҪўиҝҳеҺҹпјҲдёҺеҸӘз”ЁзәҜж–Үеӯ—зӣёжҜ”пјүзңҹзҡ„дјҡжңүж•Ҳжһңеҗ—пјҹ
и®©жҲ‘们жқҘзңӢзңӢпјҡ
In [37]:
Python
params = { 'tfidf__use_idf': (True, False), 'bow__analyzer': (split_into_lemmas, split_into_tokens), }
grid = GridSearchCV( pipeline, # pipeline from above params, # parameters to tune via cross validation refit=True, # fit using all available data at the end, on the best found param combination n_jobs=-1, # number of cores to use for parallelization; -1 for "all cores" scoring='accuracy', # what score are we optimizing? cv=StratifiedKFold(label_train, n_folds=5), # what type of cross validation to use ) |
In [38]:
Python
%time nb_detector = grid.fit(msg_train, label_train)
print nb_detector.grid_scores_ |
Python
CPU times: user 4.09 s, sys: 291 ms, total: 4.38 s Wall time: 20.2 s [mean: 0.94752, std: 0.00357, params: {'tfidf__use_idf': True, 'bow__analyzer': <function split_into_lemmas at 0x1131e8668>}, mean: 0.92958, std: 0.00390, params: {'tfidf__use_idf': False, 'bow__analyzer': <function split_into_lemmas at 0x1131e8668>}, mean: 0.94528, std: 0.00259, params: {'tfidf__use_idf': True, 'bow__analyzer': <function split_into_tokens at 0x11270b7d0>}, mean: 0.92868, std: 0.00240, params: {'tfidf__use_idf': False, 'bow__analyzer': <function split_into_tokens at 0x11270b7d0>}] |
пјҲйҰ–е…ҲжҳҫзӨәжңҖдҪіеҸӮж•°з»„еҗҲпјҡеңЁиҝҷдёӘжЎҲдҫӢдёӯжҳҜдҪҝз”Ё idf=True е’Ң analyzer=split_into_lemmas зҡ„еҸӮж•°з»„еҗҲпјү
еҝ«йҖҹеҗҲзҗҶжҖ§жЈҖжҹҘ
In [39]:
Python
print nb_detector.predict_proba(["Hi mom, how are you?"])[0] print nb_detector.predict_proba(["WINNER! Credit for free!"])[0] |
Python
[ 0.99383955 0.00616045] [ 0.29663109 0.70336891] |
predict_proba иҝ”еӣһжҜҸзұ»пјҲhamпјҢspamпјүзҡ„йў„жөӢжҰӮзҺҮгҖӮеңЁз¬¬дёҖдёӘдҫӢеӯҗдёӯпјҢж¶ҲжҒҜиў«йў„жөӢдёә ham зҡ„жҰӮзҺҮ >99%пјҢиў«йў„жөӢдёә spam зҡ„жҰӮзҺҮ <1%гҖӮеҰӮжһңиҝӣиЎҢйҖүжӢ©жЁЎеһӢдјҡи®ӨдёәдҝЎжҒҜжҳҜ вҖқhamвҖңпјҡ
In [40]:
Python
print nb_detector.predict(["Hi mom, how are you?"])[0] print nb_detector.predict(["WINNER! Credit for free!"])[0] |
Python
ham spam |
еңЁи®ӯз»ғжңҹй—ҙжІЎжңүз”ЁеҲ°зҡ„жөӢиҜ•йӣҶзҡ„ж•ҙдҪ“еҫ—еҲҶпјҡ
In [41]:
Python
predictions = nb_detector.predict(msg_test) print confusion_matrix(label_test, predictions) print classification_report(label_test, predictions) |
Python
[[973 0] [ 46 96]] precision recall f1-score support
ham 0.95 1.00 0.98 973 spam 1.00 0.68 0.81 142
avg / total 0.96 0.96 0.96 1115 |
иҝҷжҳҜжҲ‘们дҪҝз”ЁиҜҚеҪўиҝҳеҺҹгҖҒTF-IDF е’Ң Navie Bayes еҲҶзұ»еҷЁзҡ„ ham жЈҖжөӢ pipeline иҺ·еҫ—зҡ„е®һйҷ…йў„жөӢжҖ§иғҪгҖӮ
и®©жҲ‘们е°қиҜ•еҸҰдёҖдёӘеҲҶзұ»еҷЁпјҡж”ҜжҢҒеҗ‘йҮҸжңәпјҲSVMпјүгҖӮSVM еҸҜд»Ҙйқһеёёиҝ…йҖҹзҡ„еҫ—еҲ°з»“жһңпјҢе®ғжүҖйңҖиҰҒзҡ„еҸӮж•°и°ғж•ҙд№ҹеҫҲе°‘пјҲиҷҪ然жҜ” Navie Bayes зЁҚеӨҡдёҖзӮ№пјүпјҢеңЁеӨ„зҗҶж–Үжң¬ж•°жҚ®ж–№йқўе®ғжҳҜдёӘеҘҪзҡ„иө·зӮ№гҖӮ
In [42]:
Python
pipeline_svm = Pipeline([ ('bow', CountVectorizer(analyzer=split_into_lemmas)), ('tfidf', TfidfTransformer()), ('classifier', SVC()), # <== change here ])
# pipeline parameters to automatically explore and tune param_svm = [ {'classifier__C': [1, 10, 100, 1000], 'classifier__kernel': ['linear']}, {'classifier__C': [1, 10, 100, 1000], 'classifier__gamma': [0.001, 0.0001], 'classifier__kernel': ['rbf']}, ]
grid_svm = GridSearchCV( pipeline_svm, # pipeline from above param_grid=param_svm, # parameters to tune via cross validation refit=True, # fit using all data, on the best detected classifier n_jobs=-1, # number of cores to use for parallelization; -1 for "all cores" scoring='accuracy', # what score are we optimizing? cv=StratifiedKFold(label_train, n_folds=5), # what type of cross validation to use ) |
In [43]:
Python
%time svm_detector = grid_svm.fit(msg_train, label_train) # find the best combination from param_svm
print svm_detector.grid_scores_ |
Python
CPU times: user 5.24 s, sys: 170 ms, total: 5.41 s Wall time: 1min 8s [mean: 0.98677, std: 0.00259, params: {'classifier__kernel': 'linear', 'classifier__C': 1}, mean: 0.98654, std: 0.00100, params: {'classifier__kernel': 'linear', 'classifier__C': 10}, mean: 0.98654, std: 0.00100, params: {'classifier__kernel': 'linear', 'classifier__C': 100}, mean: 0.98654, std: 0.00100, params: {'classifier__kernel': 'linear', 'classifier__C': 1000}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.001, 'classifier__kernel': 'rbf', 'classifier__C': 1}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.0001, 'classifier__kernel': 'rbf', 'classifier__C': 1}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.001, 'classifier__kernel': 'rbf', 'classifier__C': 10}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.0001, 'classifier__kernel': 'rbf', 'classifier__C': 10}, mean: 0.97040, std: 0.00587, params: {'classifier__gamma': 0.001, 'classifier__kernel': 'rbf', 'classifier__C': 100}, mean: 0.86432, std: 0.00006, params: {'classifier__gamma': 0.0001, 'classifier__kernel': 'rbf', 'classifier__C': 100}, mean: 0.98722, std: 0.00280, params: {'classifier__gamma': 0.001, 'classifier__kernel': 'rbf', 'classifier__C': 1000}, mean: 0.97040, std: 0.00587, params: {'classifier__gamma': 0.0001, 'classifier__kernel': 'rbf', 'classifier__C': 1000}] |
еӣ жӯӨпјҢеҫҲжҳҺжҳҫзҡ„пјҢе…·жңү C=1 зҡ„зәҝжҖ§ж ёеҮҪж•°жҳҜжңҖеҘҪзҡ„еҸӮж•°з»„еҗҲгҖӮ
еҶҚдёҖж¬ЎеҗҲзҗҶжҖ§жЈҖжҹҘпјҡ
In [44]:
Python
print svm_detector.predict(["Hi mom, how are you?"])[0] print svm_detector.predict(["WINNER! Credit for free!"])[0] |
Python
ham spam |
In [45]:
Python
print confusion_matrix(label_test, svm_detector.predict(msg_test)) print classification_report(label_test, svm_detector.predict(msg_test)) |
Python
[[965 8] [ 13 129]] precision recall f1-score support
ham 0.99 0.99 0.99 973 spam 0.94 0.91 0.92 142
avg / total 0.98 0.98 0.98 1115 |
иҝҷжҳҜжҲ‘们дҪҝз”Ё SVM ж—¶еҸҜд»Ҙд»Һ spam йӮ®д»¶жЈҖжөӢжөҒзЁӢдёӯиҺ·еҫ—зҡ„е®һйҷ…йў„жөӢжҖ§иғҪгҖӮ
з»ҸиҝҮеҹәжң¬еҲҶжһҗе’Ңи°ғдјҳпјҢзңҹжӯЈзҡ„е·ҘдҪңпјҲе·ҘзЁӢпјүејҖе§ӢдәҶгҖӮ
з”ҹжҲҗйў„жөӢеҷЁзҡ„жңҖеҗҺдёҖжӯҘжҳҜеҶҚж¬ЎеҜ№ж•ҙдёӘж•°жҚ®йӣҶеҗҲиҝӣиЎҢи®ӯз»ғпјҢд»Ҙе……еҲҶеҲ©з”ЁжүҖжңүеҸҜз”Ёж•°жҚ®гҖӮеҪ“然пјҢжҲ‘们е°ҶдҪҝз”ЁдёҠйқўдәӨеҸүйӘҢиҜҒжүҫеҲ°зҡ„жңҖеҘҪзҡ„еҸӮж•°гҖӮиҝҷдёҺжҲ‘们ејҖе§ӢеҒҡзҡ„йқһеёёзӣёдјјпјҢдҪҶиҝҷж¬Ўж·ұе…ҘдәҶи§Је®ғзҡ„иЎҢдёәе’ҢзЁіе®ҡжҖ§гҖӮеңЁдёҚеҗҢзҡ„и®ӯз»ғ/жөӢиҜ•еӯҗйӣҶиҝӣиЎҢиҜ„д»·гҖӮ
жңҖз»Ҳзҡ„йў„жөӢеҷЁеҸҜд»ҘеәҸеҲ—еҢ–еҲ°зЈҒзӣҳпјҢд»ҘдҫҝжҲ‘们дёӢж¬ЎжғідҪҝз”Ёе®ғж—¶пјҢеҸҜд»Ҙи·іиҝҮжүҖжңүи®ӯз»ғзӣҙжҺҘдҪҝз”Ёи®ӯз»ғеҘҪзҡ„жЁЎеһӢпјҡ
In [46]:
Python
# store the spam detector to disk after training with open('sms_spam_detector.pkl', 'wb') as fout: cPickle.dump(svm_detector, fout)
# ...and load it back, whenever needed, possibly on a different machine svm_detector_reloaded = cPickle.load(open('sms_spam_detector.pkl')) |
еҠ иҪҪзҡ„з»“жһңжҳҜдёҖдёӘдёҺеҺҹе§ӢеҜ№иұЎиЎЁзҺ°зӣёеҗҢзҡ„еҜ№иұЎпјҡ
In [47]:
Python
print 'before:', svm_detector.predict([message4])[0] print 'after:', svm_detector_reloaded.predict([message4])[0] |
Python
before: ham after: ham |
з”ҹдә§жү§иЎҢзҡ„еҸҰдёҖдёӘйҮҚиҰҒйғЁеҲҶжҳҜжҖ§иғҪгҖӮз»ҸиҝҮеҝ«йҖҹгҖҒиҝӯд»ЈжЁЎеһӢи°ғж•ҙе’ҢеҸӮж•°жҗңзҙўд№ӢеҗҺпјҢжҖ§иғҪиүҜеҘҪзҡ„жЁЎеһӢеҸҜд»Ҙиў«зҝ»иҜ‘жҲҗдёҚеҗҢзҡ„иҜӯиЁҖ并дјҳеҢ–гҖӮеҸҜд»ҘзүәзүІеҮ дёӘзӮ№зҡ„еҮҶзЎ®жҖ§жҚўеҸ–дёҖдёӘжӣҙе°ҸгҖҒжӣҙеҝ«зҡ„жЁЎеһӢеҗ—пјҹжҳҜеҗҰеҖјеҫ—дјҳеҢ–еҶ…еӯҳдҪҝз”Ёжғ…еҶөпјҢжҲ–иҖ…дҪҝз”Ё mmap и·ЁиҝӣзЁӢе…ұдә«еҶ…еӯҳпјҹ
иҜ·жіЁж„ҸпјҢдјҳеҢ–并дёҚжҖ»жҳҜеҝ…иҰҒзҡ„пјҢиҰҒд»Һе®һйҷ…жғ…еҶөеҮәеҸ‘гҖӮ
иҝҳжңүдёҖдәӣйңҖиҰҒиҖғиҷ‘зҡ„й—®йўҳпјҢжҜ”еҰӮпјҢз”ҹдә§жөҒж°ҙзәҝиҝҳйңҖиҰҒиҖғиҷ‘йІҒжЈ’жҖ§пјҲжңҚеҠЎж•…йҡңиҪ¬з§»гҖҒеҶ—дҪҷгҖҒиҙҹиҪҪе№іиЎЎпјүгҖҒзӣ‘жөӢпјҲеҢ…жӢ¬ејӮеёёиҮӘеҠЁжҠҘиӯҰпјүгҖҒHR еҸҜжӣҝд»ЈжҖ§пјҲйҒҝе…Қе…ідәҺе·ҘдҪңеҰӮдҪ•е®ҢжҲҗзҡ„вҖңзҹҘиҜҶеӯӨеІӣвҖқгҖҒжҷҰ涩/й”Ғе®ҡзҡ„жҠҖжңҜгҖҒи°ғж•ҙз»“жһңзҡ„й»‘иүәжңҜпјүгҖӮзҺ°еңЁпјҢејҖжәҗдё–з•ҢйғҪеҸҜд»ҘдёәжүҖжңүиҝҷдәӣйўҶеҹҹжҸҗдҫӣеҸҜиЎҢзҡ„и§ЈеҶіж–№жі•пјҢз”ұдәҺ OSI жү№еҮҶзҡ„ејҖжәҗи®ёеҸҜиҜҒпјҢд»ҠеӨ©еұ•зӨәзҡ„жүҖжңүе·Ҙе…·йғҪеҸҜд»Ҙе…Қиҙ№з”ЁдәҺе•Ҷдёҡз”ЁйҖ”гҖӮ
дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„PythonдёӯжҖҺд№Ҳе®һзҺ°ж•°жҚ®жҢ–жҺҳдәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ