您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关基于Spark Streaming+Saprk SQL怎么开发OnLineLogAanlysis2,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
1.influxdb创建database
[root@sht-sgmhadoopdn-04 app]# influx -precision rfc3339
Connected to http://localhost:8086 version 1.2.0
InfluxDB shell version: 1.2.0
>create database online_log_analysis
2.项目中原本想将 influxdb-java https://github.com/influxdata/influxdb-java的InfluxDBTest.java 文件的加到项目中,所以必须要引入 influxdb-java 的包;
但是由于GitHub的上的class文件的某些方法,是版本是2.6,而maven中的最高也就2.5版本,所以将Github的源代码下载导入到idea中,编译导出2.6.jar包;
可是 引入2.6jar包,其在InfluxDBTest.class文件的 无法import org.influxdb(百度谷歌很长时间,尝试很多方法不行)。
最后索性将 influx-java的源代码全部添加到项目中即可,如下图所示。
3.运行OnLineLogAanlysis2.java
https://github.com/Hackeruncle/OnlineLogAnalysis/blob/master/online_log_analysis/src/main/java/com/learn/java/main/OnLineLogAnalysis2.java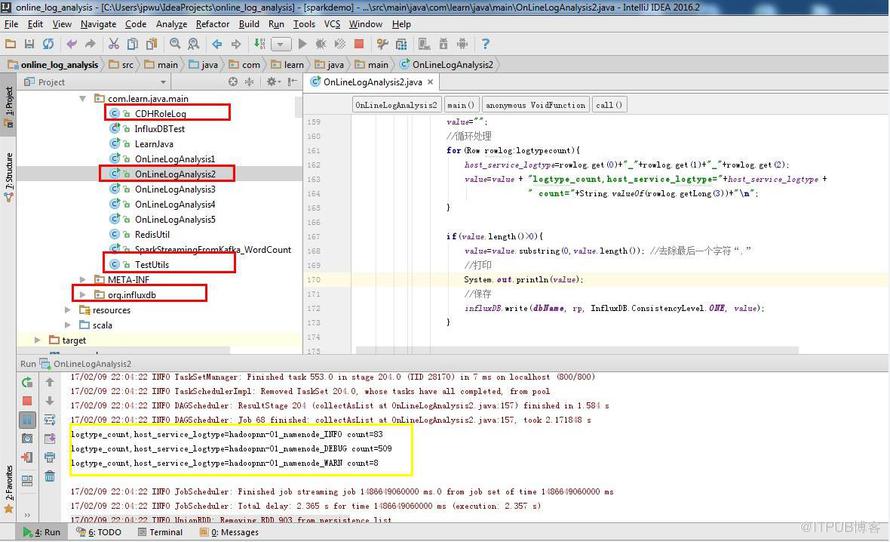
比如 logtype_count,host_service_logtype=hadoopnn-01_namenode_WARN count=12
logtype_count 是表
host_service_logtype=hadoopnn-01_namenode_WARN 是 tag--标签,在InfluxDB中,tag是一个非常重要的部分,表名+tag一起作为数据库的索引,是“key-value”的形式。
count=12 是 field--数据,field主要是用来存放数据的部分,也是“key-value”的形式。
tag、field 中间是要有空格的
4.influxdb查询数据

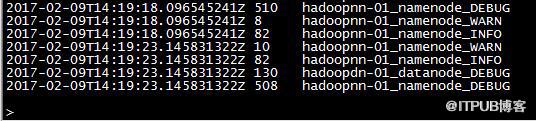
关于基于Spark Streaming+Saprk SQL怎么开发OnLineLogAanlysis2就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。