您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
所谓的数据的完整性就是,数据的准确性和可靠性。可以通过添加完整性约束来提高数据的完整性:
主键约束
要求:要求主键列数唯一,并且不能为空,主键可以包含表的一列或多列(可以是一个列成为主键,也可以是几个列组合成为主键)。尽量不要选择业务数据为主键。
作用:主键是唯一能确定一行数据的字段。
创建主键的三种方式:
#例1:
#创建字段的时候添加约束
create table stu(
id int primary key ,
sname varchar(20));
#例2:
#最后添加约束
create table stu(
id int ,
sname varchar(20),
primary key(id));
#例3
#表已经创建,然后添加约束
create table stu(
id int ,
sname varchar(20));
alter table stu add constraint ky_id primary key(id);
ps:如果想加入主键自增,只需要在primary key 后面加入:auto_increment删除主键约束:
#删除主键约束,首先要删除他的主键自增,然后在删除:
alter table stu modify id int //删除主键自增
alter table stu drop primary key; //删除主键约束唯一约束
要求:要求该列唯一,允许为一个空。
#例:
alter table stu add constraint unique(sname) 删除唯一约束
#在删除唯一约束时,首先需要删除索引,因为在创建唯一约束时默认会创建一个索引
alter table stu drop index sname
alter table stu drop index 唯一约束名非空约束
要求:某类内容不允许为空
语法:name varchar(50) not null
默认值
要求:当字段没有给固定的值得时候,自动赋初值。
语法:name varchar(50) default ‘zs’;
外键约束
要求:一个表中的某个字段必须与另一张表中的某个字段相等,如果不相等,或者另一张表没有这个值,则存储失败。
语法:foreign key(表的字段) references 外表名(字段)
#例:添加外键约束
alter table table1 add constraint foreign key(需要设为外键的字段) references table2(父表的关联字段)CREATE TABLE `t_book` (
`bid` int(10) NOT NULL,
`bname` varchar(50) NOT NULL,
`price` double DEFAULT NULL,
`author` varchar(50) DEFAULT NULL,
`authorid` int(10) DEFAULT NULL,
PRIMARY KEY (`bid`),
UNIQUE KEY `author` (`author`)
) ; 描述:在数据库中用来加速对表的查询,通过使用快速路径访问的方法,快速定位数据,减少了磁盘的IO。
类型:B-Tree索引、位图索引、哈希索引。在不同的存储引擎中对索引的存储策略不同:
- Myisam引擎:叶子节点中保存记录的地址
- Innodb引擎:叶子节点中直接保存相应的数据。(B+树索引)
索引的优点:建立索引可以加快查询的速度,而降低增、删、改的效率。
索引的创建:索引的创建分为两种:自动创建和手动创建:
- 自动创建:当在表中定义了一个主键,或者唯一约束时,数据库会自动的创建一个对应的唯一索引。
- 手动创建:
#普通索引
create index index_name on t_name(field)
#唯一索引
create unique index index_name on t_name(field)
#复合索引
create index index_name on t_name(field1,field2) 索引的使用条件:当通过设置索引的字段作为过滤条件时查询的语句,才会用到索引。
索引的效率:
在查询时使用:explain select * from emp where ename='scott'; explain关键字用于查看索引的效率:
关于type的级别: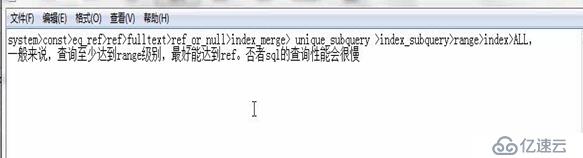
使用索引的注意点:
- 索引与表是分开保存的,会占用大量的磁盘空间
- 索引改善了检索数据的性能,但是降低了增、删、改数据的性能。
- 限制索引中索引数目。索引越多,数据库的工作量越大
- 索引用于数据过滤和数据排序(表的数据量比较大,经常使用某些字段做排序和查询,建立索引)
介绍:视图是从若干个表和其他视图中构造出来的虚表,并非是以物理文件保存数据,在执行过程中动态从基表中获取数据,以表为底层。
#例:创建视图
create view v_viem as select * from emp1 where deptno =20;
#修改视图:
update v_viem set deptno=10;
#查询视图
select * from v_viem;
注意:视图一般不建议进行删除、修改操作,因为他会影响到基表。以上的案例表示:如果修改了创建视图的条件字段,但是视图在查询时还按照原有的条件查询,会导致查询的数据不准确。# 控制视图 不能修改字段:
CREATE
OR REPLACE VIEW v_emp AS SELECT
*
FROM
emp
WHERE
deptno = 20 WITH CHECK OPTION;
注意:使用上面的方式,创建视图,如果想对视图的条件字段进行修改,就会出现:
1369 - CHECK OPTION failed 'db1807.v_emp',错误。对视图的操作
#查询视图
select * from v_emp;
#在视图中插入数据
insert into v_emp(field1,field2,field3) values(value1,value2,value3)
#重建视图
create or REPLACE view t_view as select * from emp where sal >2000
#销毁视图
drop view view_name 视图的优点:
- 安全性:bao保密敏感字段
- 提高查询效率
- 定制化SQL:可以将多张表中经常被使用的数据放置在视图中,快速查询。
本来以为这部分不重要,不,应该说不会是自己去操作MySQL的DCL,因为公司都有自己的数据库管理员,咱们使用MySQL都会有特殊的权限限制,能通过特定的用户,但是经过几次的安装集群后发现,最初hadoop平台搭建的时候,这个MySQL的授权操作还得自己来,每次都会因为hive初始化元数据库、Azkaban组件安装纠结半天。得嘞,自己总结下吧,以免下次在纠结。
语法:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';CREATE USER 'hadoop'@'localhost' IDENTIFIED BY '123456';
CREATE USER 'hive'@'192.168.1.101' IDENDIFIED BY '123456';
CREATE USER 'hadoop'@'%' IDENTIFIED BY '123456';
CREATE USER 'hive'@'%' IDENTIFIED BY '';
CREATE USER 'azkaban'@'%';创建用户成功后,就可以通过这个用户登录:
$mysql -hmysql_host -uhadoop -p123456删除用户:
DROP USER 'username'@'host'; 只有拥有特定权限的用户才能执行特定的操作。
语法:
GRANT privileges ON dbname.tableanme TO 'username'@'host';GRANT SELECT, INSERT ON test.user TO 'hadoop'@'%';
GRANT ALL ON *.* TO 'hadoop'@'%';
GRANT ALL ON maindataplus.* TO 'hadoop'@'%';授权之后一般都会刷新该操作:
mysql>flush privileges;撤销授权:
REVOKE privilege ON databasename.tablename FROM 'username'@'host';其中的内容与授权操作类似。
命令:
SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword');如果修改当前用户的密码则:
SET PASSWORD = PASSWORD("newpassword");举例:
SET PASSWORD FOR 'hadoop'@'%' = PASSWORD("123456");免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。