您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要为大家分析了BIRT异构跨库的动态关联查询该怎样做的相关知识点,内容详细易懂,操作细节合理,具有一定参考价值。如果感兴趣的话,不妨跟着跟随小编一起来看看,下面跟着小编一起深入学习“BIRT异构跨库的动态关联查询该怎样做”的知识吧。
BIRT自带的Data Sources Join以及用ETL转化为同库等方案都难以解决此类问题。具体可以通过如下示例讨论:
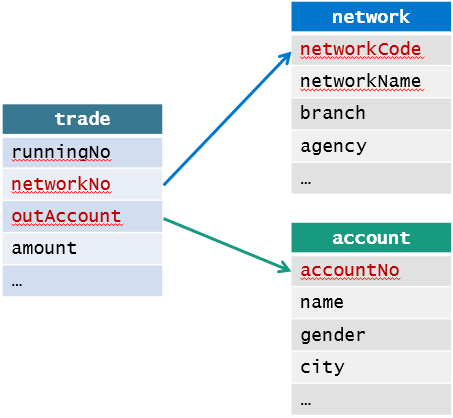
交易明细数据(trade表)存储于生产系统的数据库DB2中,另外一部分业务数据(network表、account表)存储于业务系统的Mysql中,它们其中的关联关系如下图所示:
所谓“动态关联”,是指用户在前台界面输入参数,报表通过参数来决定trade和哪张表做关联,并在报表中显示关联后的数据,实际运算中可能还要进行数据过滤和汇总。查询流程如下图所示:
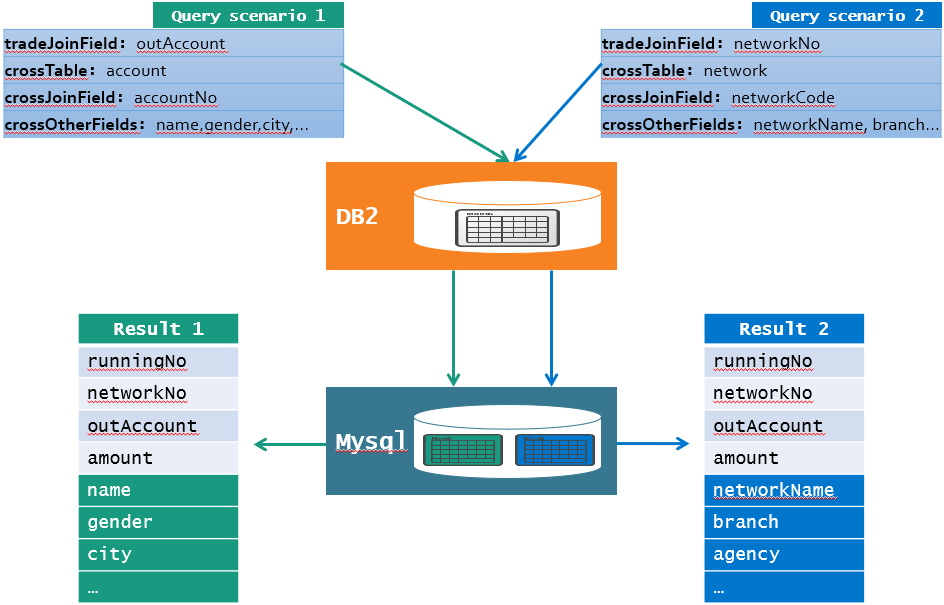
比如查询场景一:报表根据传入参数,能动态地将trade中的outAccount字段和account中的accountNo字段关联,最后查询结果显示trade中的所有字段以及account的name,gender,city等字段。
解决此类问题的常见方案与不足,分析如下:
1、BIRT Data Sources Join的问题在于要求表名和字段名是已知、确定的,但这类报表都是通过参数来动态关联的,因此无法实现。
2、可以用ETL把生产库的数据抽取到业务库,这样跨库的问题就转化为同库了。这个方案思路简单但实施起来细节上有很多难点。首先是实时查询:为了实时查询数据,需要在生产库使用触发器之类的功能来检测数据的实时变化,并将数据推送到业务库,但生产库不能轻易改动,因此实时查询就无法实现。非实时查询也难以办到,这是因为生产库的数据极其庞大,不可能每次都全部取过来,只有用增量抽取的办法,而判断增量就需要在trade表中加入时间戳字段。同样,生产库是不允许有这种改动的,因此也无法实现。
3、从能力上讲,BIRT JAVA bean data source是真正能解决报表问题,它比Data Sources Join更具灵活性,也不需要修改生产库。但这个方案只有一个缺陷:代码过于复杂,原因在于数据计算并非JAVA特长,若每次遇到跨库问题都用硬编码方式来实现,并不现实。
建议使用集算器,它是独立的数据计算引擎,拥有不依赖于数据库的计算能力,支持异构数据源的混合运算,比较适合进行动态关联再计算,事实上,可以把集算器看作是语法更简单的BIRT JAVA bean data source。比如实现上面的问题,集算器脚本只需6行:
A | |
1 | =DB2.query("select runningNo,networkNo,outAccount,amount from trade") |
2 | ="select"+crossJoinField+","+crossOtherFields+"from"+crossTable |
3 | =Mysql.query(A2) |
4 | =join(A1:trade,${tradeJoinField};A3:cross,${crossJoinField}) |
5 | =crossOtherFields.array().("cross."+~).string() |
6 | =A4.new(trade.runningNo,trade.networkNo,trade.outAccount,trade.amount,${A5}) |
其中 tradeJoinField,crossJoinField,crossOtherFields,crossTable 为输入参数。最后将计算结果返回给BIRT的DataSet进行报表展现。从此示例来看,集算器的参数用法很灵活,非常适合这类动态关联查询。由于它是专门的计算语言,所以较于常规办法,跨库计算的代码更加精炼易懂。
关于“BIRT异构跨库的动态关联查询该怎样做”就介绍到这了,更多相关内容可以搜索亿速云以前的文章,希望能够帮助大家答疑解惑,请多多支持亿速云网站!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。