您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍Tungsten Fabric安装的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
如果计划设置用于关键流量,则始终需要使用HA。
Tungsten Fabric拥有不错的HA实施,已经以下的文档中有相关信息。
http://www.opencontrail.org/opencontrail-architecture-documentation/#section2_7
这里我想多说的一件事,cassandra的keyspace在configdb和analyticsdb之间具有不同的replication-factor。
configdb:
https://github.com/Juniper/contrail-controller/blob/master/src/config/common/vnc_cassandra.py#L609
analytics:
https://github.com/Juniper/contrail-analytics/blob/master/contrail-collector/db_handler.cc#L524
由于configdb的数据已复制到所有的cassandras,因此即使某些节点的磁盘崩溃并需要抹掉,也不太可能丢失数据。另一方面,由于analyticsdb的replication-factor始终设置为2,因此如果两个节点同时丢失数据,那么数据就可能会丢失。
在安装Tungsten Fabric时,许多情况下都需要进行多NIC安装,例如用于管理平面和控制/数据平面的,都是单独的NIC。
绑定(bonding)不在此讨论中,因为bond0可以直接由VROUTER_GATEWAY参数指定
我需要明确一下在此设置中vRouter的有趣的行为。
对于controller/analytics来说,与典型的Linux安装并没有太大区别,这是因为Linux可以与多个NIC和其自己的路由表(包括使用静态路由)很好地协同工作。
另一方面,在vRouter节点中您需要注意的是,vRouter在发送报文时不会使用Linux路由表,而是始终将报文发送到网关IP。
这可以使用concert-vrouter-agent.conf中的网关参数和vrouter-agent容器的环境变量中的VROUTER_GATEWAY进行设置
因此,在设置多NIC安装时,如果需要指定VROUTER_GATEWAY,那么您需要小心一点。
如果没有指明,并且Internet访问的路由(0.0.0.0/0)是由管理NIC而不是数据平面NIC所覆盖,那么vrouter-agent容器将选择保存该节点默认路由的NIC,尽管那不会是正确的NIC。
在这种情况下,您需要显式指定VROUTER_GATEWAY参数。
由于这些行为的存在,当您要将报文从虚拟机或容器发送到NIC(除了vRouter使用的NIC之外的其它NIC)时,仍然需要谨慎一些,因为它同样不会检查Linux路由表,并且它始终使用与其它vRouter通信相同的NIC。
据我所知,来自本地链接服务或无网关的报文也显示出类似的行为
在这种情况下,您可能需要使用简单网关(simple-gateway)或SR-IOV。
https://github.com/Juniper/contrail-controller/wiki/Simple-Gateway
对于Tungsten Fabric集群的一般规格(sizing),您可以使用下面的表。
https://github.com/hartmutschroeder/contrailandrhosp10#21sizing-the-controller-nodes-and-vms
如果集群规模很大,则需要大量资源来保障控制平面的稳定。
请注意,从5.1版本开始,analytics数据库(以及analytics的某些组件)成为了可选项。因此,如果您只想使用Tungsten Fabric中的控制平面,我建议使用5.1版本。
https://github.com/Juniper/contrail-analytics/blob/master/specs/analytics_optional_components.md
尽管没有一个方便的答案,但集群的大小也是很重要的,因为它取决于很多因素。
我曾经尝试用一个K8s集群( https://kubernetes.io/docs/setup/cluster-large/)部署了近5,000个节点。在它与一个具有64个vCPU和58GB内存的控制器节点配合使用时效果很不错,尽管当时我并没有创建太多的端口、策略和逻辑路由器等。
这个Wiki也描述了一些有关海量规模集群的真实经验:
https://wiki.tungsten.io/display/TUN/KubeCon+NA+in+Seattle+2018
由于可以随时从云中获取大量资源,因此最好的选择应该是按照实际需求的大小和流量来模拟集群,并查看其是否正常运行,以及瓶颈是什么。
Tungsten Fabric在应对海量规模方面拥有一些很好的功能,例如,基于集群之间的MP-BGP的多集群设置,以及基于3层虚拟网络的BUM丢弃功能,这大概就是其具备可扩展性和稳定性虚拟网络的关键。
https://bugs.launchpad.net/juniperopenstack/+bug/1471637
为了说明控件的横向扩展行为,我在AWS中创建了一个包含980个vRouter和15个控件的集群。
所有控制节点均具有4个vCPU和16GB内存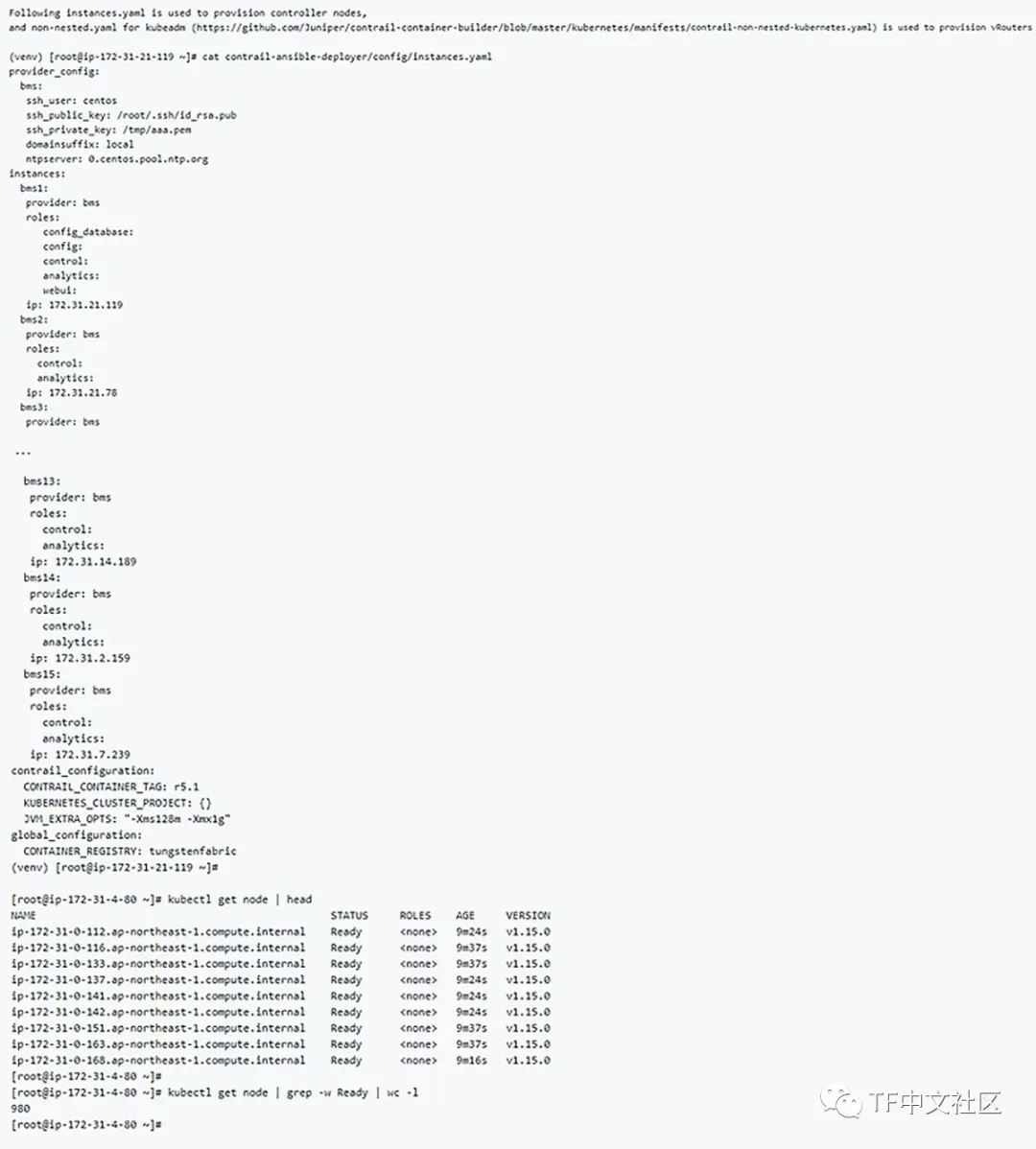
当控制节点的数量为15时,XMPP的连接数最多只有113,因此CPU使用率不是很高(最高只有5.4%)。
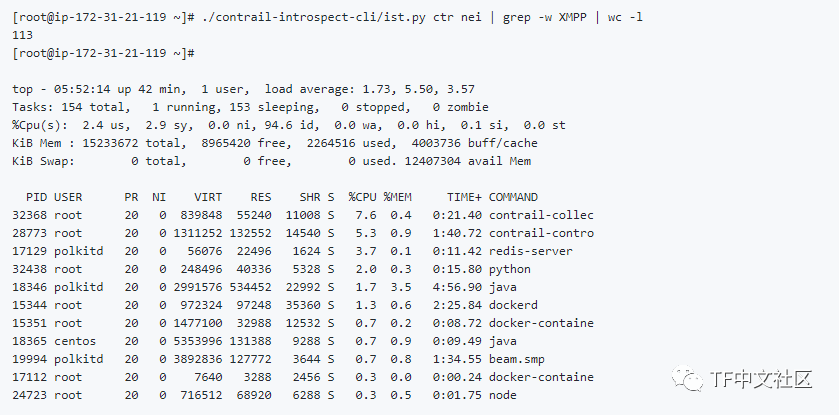
但是,当其中12个控制节点停止工作时,剩余的每个控制节点的XMPP连接数将高达708,因此CPU使用率变得很高(21.6%)。
因此,如果您需要部署大量的节点,那么可能需要仔细规划控制节点的数量。
在撰写本文档时,ansible-deployer尚未支持K8s master HA。
https://bugs.launchpad.net/juniperopenstack/+bug/1761137
由于kubeadm已经支持K8s master HA,因此我将介绍集成基于kubeadm的k8s安装和基于YAML的Tungsten Fabric安装的方法。
https://kubernetes.io/docs/setup/independent/high-availability/
https://github.com/Juniper/contrail-ansible-deployer/wiki/Provision-Contrail-Kubernetes-Cluster-in-Non-nested-Mode
与其它CNI一样,也可以通过“kubectl apply”命令直接安装Tungsten Fabric。但要实现此目的,需要手动配置一些参数,例如控制器节点的IP地址。
对于此示例的设置,我使用了5个EC2实例(AMI也一样,ami-3185744e),每个实例具有2个vCPU、8 GB内存、20 GB磁盘空间。VPC的CIDR为172.31.0.0/16。

我将附上一些原始和修改的yaml文件以供进一步参考。
https://github.com/tnaganawa/tungstenfabric-docs/blob/master/cni-tungsten-fabric.yaml.orig
https://github.com/tnaganawa/tungstenfabric-docs/blob/master/cni-tungsten-fabric.yaml
然后,您终于有了(多数情况下)已经启动了的具有Tungsten Fabric CNI的kubernetes HA环境。
注意:Coredns在此输出中未处于活动状态,我将在本节稍后的部分对此进行修复。
 在创建cirros部署后,就像“启动并运行”部分所描述的一样,两个vRouter节点之间已经可以ping通了。
在创建cirros部署后,就像“启动并运行”部分所描述的一样,两个vRouter节点之间已经可以ping通了。
输出是相同的,但现在在两个vRouter之间使用的是MPLS封装!

注意:要使coredns处于活动状态,需要进行两项更改。

终于,coredns也处于活动状态,集群已完全启动!

以上是“Tungsten Fabric安装的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。