您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
选择CBO的优化方式
默认条件下,CBO将SQL语句的吞吐量作为优化目标
三种不同的优化方式
ALL_ROWS :该优化方式是Oracle的默认模式,优化目标是实现查询的最大吞吐量
FIRST_ROWS_n:该优化方式使用CBO的成本优化输出查询的前n行数据,目标是以满足快速相应的查询需求,
FIRST_ROWS :该方式是FIRST_ROWS_n优化方式的老版本,作用是使用CBO的成本优化尽快输出查询的前几行数据,满足最小相应时间的需求
查询当前数据库的CBO优化方式
show parameter optimizer_mode
在实例级设置优化方式
alter system set optimizer_mode = FIRST_ROWS_10 scope=spfile
在会话级设置优化方式
alter session set optimizer_mode=ALL_ROWS
会话级上设置优化方式必须使用hint提示
select /*+first_rows_10*/ ename,sal,mgr
from scott.emp
优化器工作过程
步骤
1.SQL转换
在CBO优化中,一个SQL语句往往被转换成另一种表达形式,这个转换的基础是CBO认为转换后的查询会更有效
2.确定访问路径
一个SQL查询中对数据的访问的路径要根据访问这些数据消耗的资源来判断,在多个查询路径中选择计算成本最小的一个。
3.确定联结方式
在SQL语句中涉及多个表时,CBO会根据统计数据以及表的键的信息来选择连接方式,在多个连接方法中选择计算成本最低的一个作为最佳连接方法
4.确定联结次序
CBO会对不同的连接次序中进行计算以选择最好的执行计划。
自动统计数据
查看GATHER_STATS_JOB状态
select job_name,state,owner
from dba_scheduler_jobs;
通过数据字典DBA_TABLES查询用户SCOTT拥有表的统计分析情况
select last_analyzed,table_name,owner,num_rows,sample_size
from dba_tables
where owner='SCOTT'
手动统计数据库数据
DBMS_STATS
存储过程
GATHER_DATABASE_STATS 为全库中的表统计数据
GATHER_SCHEMA_STATS 为某个模式统计数据
GATHER_TABLE_STATS 为某个特定的表统计数据
GATHER_INDEX_STATS 为某个索引表统计数据
上述统计数据保存在 DBA_TAB_STATISTICS 和 DBA_TAB_COL_STATISTICS
为模式SCOTT的所有表统计数据
execute DBMS_STATS.GATHER_SCHEMA_STATS(ownname=>'SCOTT');
验证模式SCOTT的数据统计成功
select last_analyzed,table_name,owner,num_rows,sample_size
from dba_tables
where owner='SCOTT'
为模式SCOTT用户的表EMP统计数据
execute DBMS_STATS.GATHER_TABLE_STATS('SCOTT','EMP');
为DEPT的索引统计数据
execute DBMS_STATS.GATHER_INDEX_STATS('SCOTT','PK_DEPT')
手工收集数据库级别的统计数据-----需要对初始化参数JOB_QUEUE_PROCESSES设置一个非0值
execute DBMS_STATS.GATHER_DATABASE_STATS(estimate_percent=>null)
查询表的统计数据 DBA_TAB_STATISTICS
查询表的列的统计数据 DBA_TAB_COL_STATISTICS
统计OS数据
DBMS_STATS.GATHER_SYSTEM_STATS SYS.AUX_STAST$
无负载方式下收集10分钟的系统统计数据
execute DBMS_STATS.GATHER_SYSTEM_STATS('NOWORKLOAD',10)
收集系统统计数据
execute DBMS_STATS.GATHER_SYSTEM_STATS('start')
execute DBMS_STATS.GATHER_SYSTEM_STATS('stop')
每三分钟执行一次
查询统计的系统数据
select * from SYS.AUX_STAST$;
手工统计字典数据---具备SYSDBA权限
收集固定字典表的统计数据
execute DBMS_STATS.GATHER_FIXED_OBJECTS_STATS;
收集数据字典表的统计数据
execute DBMS_STATS.GATHER_DIRECTORY_STATS;
/
使用过程GATHER_SCHEMA_STATS统计数据字典数据
execute DBMS_STATS.GATHER_SCHEMA_STATS('sys')
主动优化SQL语句
SQL语句优化工具
1.使用EXPLAN FOR 指令
utlxplan.sql
执行脚本---生成PLAN_TABLE表
@?/rdbms/admin/utlxplan.sql
通过EXPLAIN PLAN FOR 指令分析SQL语句的执行计划
explain plan for select count(*) from scott.emp;
查看表 PLAN_TABLE 中SQL语句执行计划信息
col if for 999
col operation for a20
col options for a20
col object_name for a20
select id,operation,options,object_name,position
from PLAN_TABLE
OPERATION :为TABLEACCESS说明该步骤的行为是访问表
OPTIONS :为FULL,说明全表扫描访问表
OBJECT_NAME :说明行为的对象为表EMP
使用AUTOTRACE指令------SQL_TRACE=TRUE
设置参数 SQL_TRACE 启动SQL语句追踪
alter system set SQL_TRACE = TRUE;
/* 选项 结果
SET AUTOTRACE ON 查询输出,解释计划,统计信息
SET AUTOTRACE OFF 关闭 AUTOTRACE
SET AUTOTRACE ON EXPLAIN 查询输出,解释计划,没有统计信息
SET AUTOTRACE ON EXPLAIN STAT 查询输出,解释计划,统计信息
SET AUTOTRACE ON STAT 查询输出,解释计划,统计信息
SET AUTOTRACE TRACE 解释计划,统计信息,生成结果但不显示
SET AUTOTRACE TRACE EXPLAIN 只有解释计划,不生成结果
SET AUTOTRACE TRACE STAT 只有统计,生成结果但不显示*/
使用AUTOTRACE追踪SQL语句执行计划
set autotrace traceonly
select count(*) from scott.emp 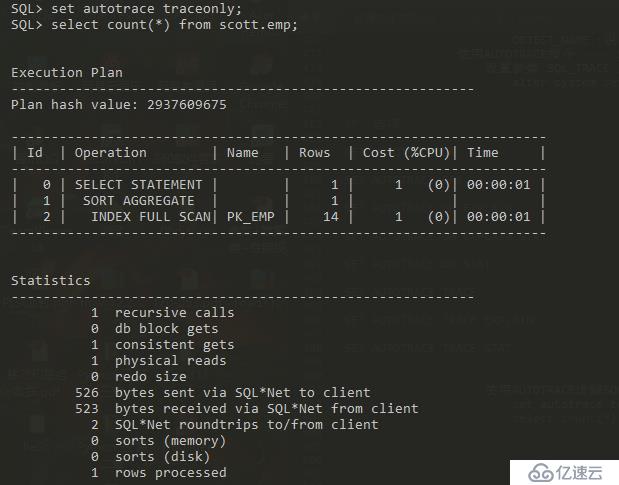
recursive calls 递归调用的次数 db block gets 读数据块的数量 consistent gets 总的逻辑I/O physical reads 物理I/O redo size 重做数量 bytes sent via SQL*Net to client SQL*Net通信 bytes received via SQL*Net from client SQL*Net roundtrips to/from client sorts (memory) 内存排序统计 sorts (disk) 磁盘排序统计 rows processed 被检索的行数 关闭AUTOTRACE set autotrace OFF 启动 SQL Trace的前提 1.statistics_level: TYPICAL / ALL BASE 2.timed_statistics: TRUE -----BASE False -----TYPICAL / ALL 3.user_dump_dest: 该参数存储SQL语句的追踪文件。 (max_dump_file_size) 启动SQL Trace追踪 实例级启动SQL Trace追踪 alter system set SQL_TRACE=TRUE 会话级启动SQL Trace追踪 alter session set SQL_TRACE=TRUE / begin sys.dbms_session.set_sql_trace(TRUE); end; 使用 TKPPOF 解释 SQL Trace文件 执行sql查询 使用TKPPOF工具格式化SQL追踪文件 TKPPOF xxxxxxxx.trc xxxx.txt sys=no 格式化参数的含义 count :不同执行阶段所读取的数据块数量 cpu :不同执行阶段锁消耗的CPU时间,单位是秒 elapsed :执行用掉的时间 disk :物理磁盘数据读操作数目 query :一致的缓冲区读取数量 current :数据库块读取的数量 call :该参数说明SQL语句的不同执行阶段
消除子查询优化SQL语句 对查询用户scott的emp表进行嵌套子查询 select * from scott.emp e1 where e1.sal> (select avg(sal) from scott.emp e2 where e2.deptno=e1.deptno) 开启AUTOTRACE功能 set autotrace traceonly 跟踪SQL语句的执行 select * from scott.emp e1 where e1.sal> (select avg(sal) from scott.emp e2 where e2.deptno=e1.deptno)
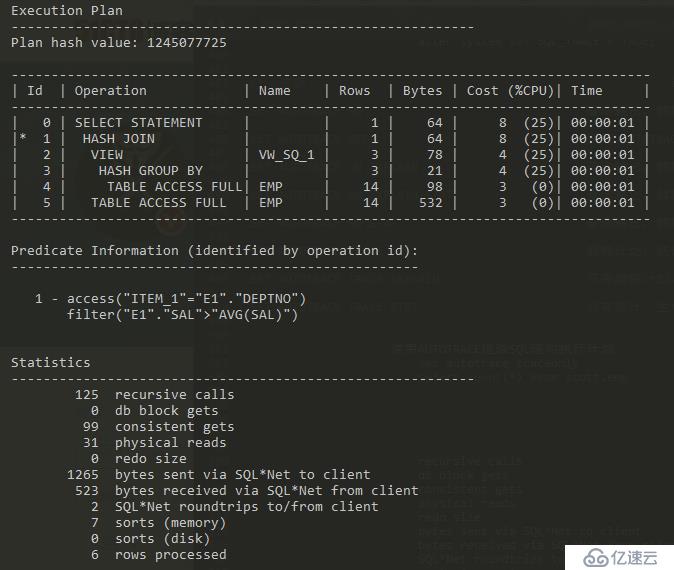
跟踪改写的SQL语句 使用联机视图改写子查询 select * from scott.emp e1,(select e2.deptno deptno ,avg(e2.sal) avg_sal from scott.emp e2 group by deptno ) dept_avg_sal where e1.deptno = dept_avg_sal.deptno and e1.sal > dept_avg_sal.avg_sal
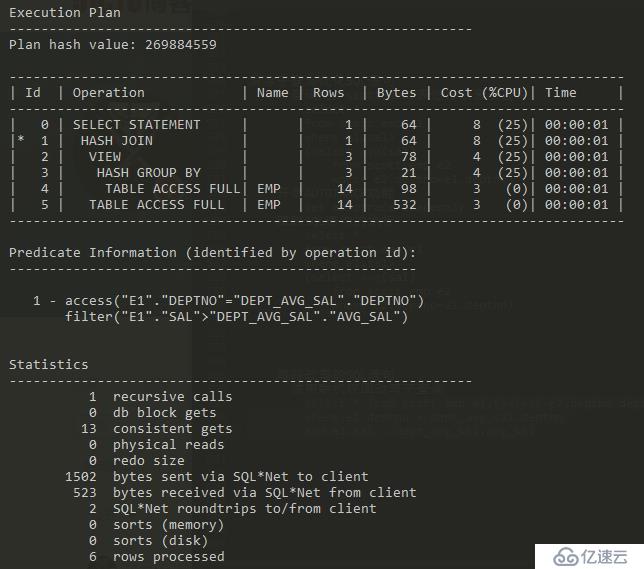
被动优化SQL语句 使用分区表 使用表和索引压缩 创建压缩表 create table compress_emp compress tablespace users as select * from scott.emp 查询是否成功创建压缩表 compress_emp select table_name,tablespace_name,compression from user_tables where table_name like 'COMPRESS%'; 创建压缩索引 create index compress_emp_ename_idx on compress_emp(ename) compress; 保持CBO的稳定性 1.创建存储大纲的前提 初始化参数 QUERY_REWRITE_ENABLED = TRUE STAR_TRANSFORMATION_ENABLED = TRUE 验证系统师傅具备创建存储大纲的前提 show paameter QUERY_REWRITE_ENABLED; show paramter STAR_TRANSFORMATION_ENABLED; show parameter optimizer_features_enable; 2.创建存储大纲 创建数据库级的存储大纲 alter system set create_stored_outlines = TRUE 创建会话级的存储大纲 alter session set create_stored_outlines = TRUE 为特定SQL语句创建存储大纲 create outline emp_outline on select * from scott.emp tablespace oltbs; 查询EMP_OUTLINE创建信息 select ol_name,sql_text,creator,timestamp from ol$ where ol_name like 'EMP%' 查询Oracle自动生产的存储大纲的名字 set lines 120 select ol_name,sql_text from ol$ 3.删除存储大纲 删除存储大纲-----sysdba drop outline emp_outline 4.启用存储大纲 修改参数 USE_STORED_OUTLINES 为TRUE alter system set USE_STORED_OUTLINES= TRUE
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。