



您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
LVS实现负载均衡的原理与实践是怎样的,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
这是1998年一个普通的上午。
一上班,老板就把张大胖叫进了办公室,一边舒服地喝茶一边发难:“大胖啊,我们公司开发的这个网站,现在怎么越来越慢了? ”
还好张大胖也注意到了这个问题,他早有准备,一脸无奈地说: “唉,我昨天检查了一下系统,现在的访问量已经越来越大了,无论是CPU,还是硬盘、内存都不堪重负了,高峰期的响应速度越来越慢。”
顿了一下,他试探地问道:“老板,能不能买个好机器? 把现在的‘老破小’服务器给替换掉。我听说IBM的服务器挺好的,性能强劲,要不来一台?”
“好你个头,你知道那机器得多贵吗?! 我们小公司,用不起啊!” 抠门的老板立刻否决。 “这……” 大胖表示黔驴技穷了。 “你去和CTO Bill 商量下, 明天给我弄个方案出来。”
老板不管过程,只要结果。
大胖悻悻地去找Bill。 他将老板的指示声情并茂地做了传达。
Bill笑了:“我最近也在思考这件事,想和你商量一下,看看能不能买几台便宜的服务器,把系统多部署几份,横向扩展(Scale Out)一下。 ”
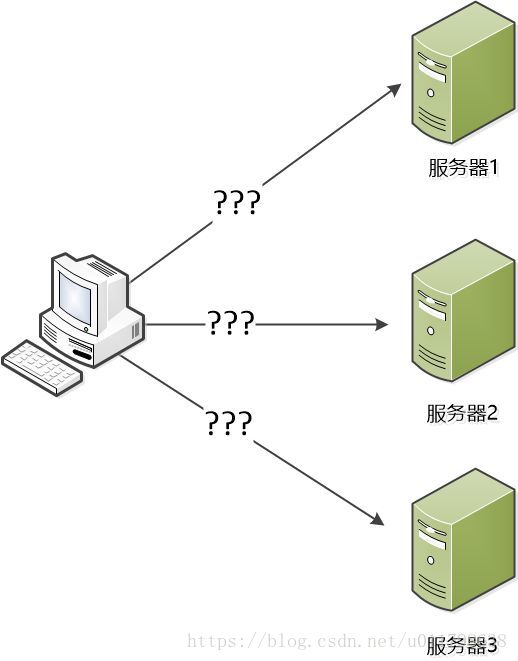
横向扩展? 张大胖心中寻思着,如果把系统部署到几个服务器上,用户的访问请求就可以分散到各个服务器,那单台服务器的压力就小得多了。
“可是,” 张大胖问道 ,“机器多了,每个机器一个IP, 用户可能就迷糊了,到底访问哪一个?”
“肯定不能把这些服务器暴露出去,从客户角度看来,最好是只有一个服务器。” Bill 说道。
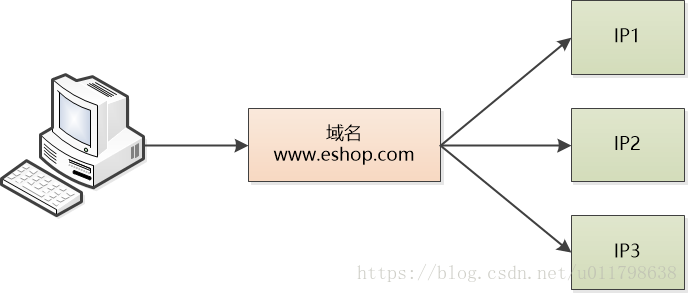
张大胖眼前一亮, 突然有了主意:“有了!我们有个中间层啊,对,就是DNS,我们可以设置一下,让我们网站的域名映射到多个服务器的IP,用户面对的是我们系统的域名,然后我们可以采用一种轮询的方式, 用户1的机器做域名解析的时候,DNS返回IP1, 用户2的机器做域名解析的时候,DNS返回IP2…… 这样不就可以实现各个机器的负载相对均衡了吗?”
Bill 思考片刻,发现了漏洞:“这样做有个很要命的问题,由于DNS这个分层的系统中有缓存,用户端的机器也有缓存,如果某个机器出故障,域名解析仍然会返回那个出问题机器的IP,那所有访问该机器的用户都会出问题, 即使我们把这个机器的IP从DNS中删除也不行, 这就麻烦了。”
张大胖确实是没想到这个缓存带来的问题, 他挠挠头:“那就不好办了。”
“要不我们自己开发一个软件实现负载均衡怎么样?” Bill另辟蹊径。
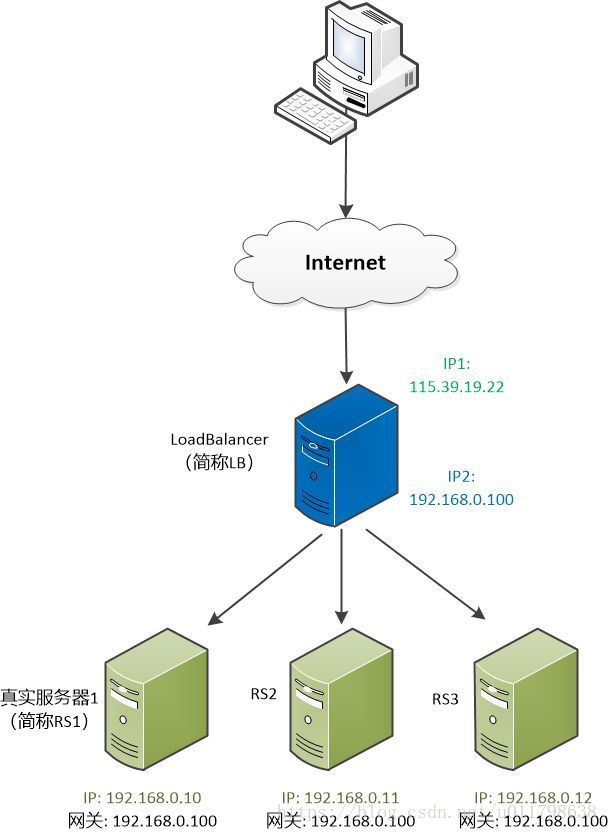
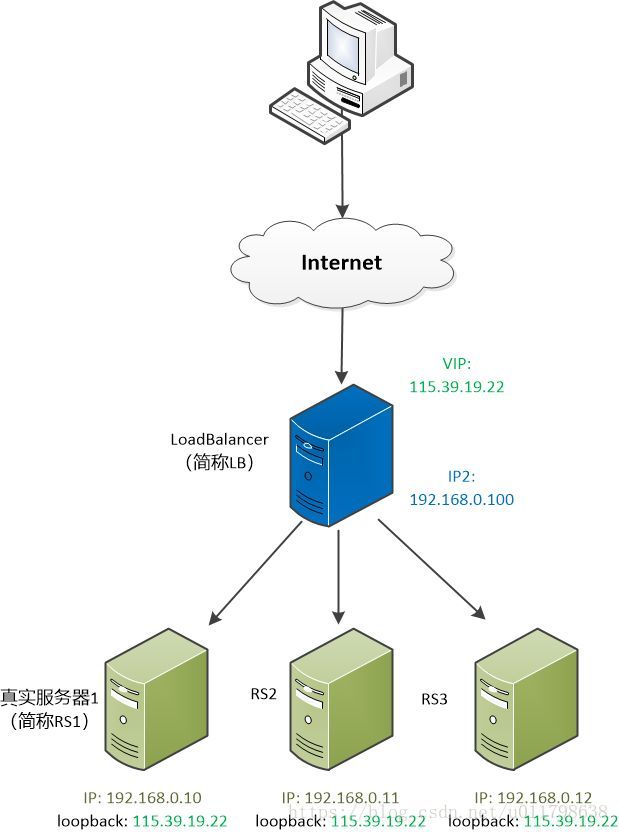
为了展示自己的想法, 他在白板上画了一张图, “看到中间那个蓝色服务器没有,我们可以把它称为Load Balancer (简称LB), 用户的请求都发给他,然后它再发给各个服务器。”
张大胖仔细审视这个图。
Load Balancer 简称LB , 有两个IP,一个对外(115.39.19.22),一个对内(192.168.0.100)。用户看到的是那个对外的IP。 后面的真正提供服务的服务器有三个,称为RS1, RS2,RS3, 他们的网关都指向LB。
“但是怎么转发请求呢?嗯, 用户的请求到底是什么东西?” 张大胖迷糊了。
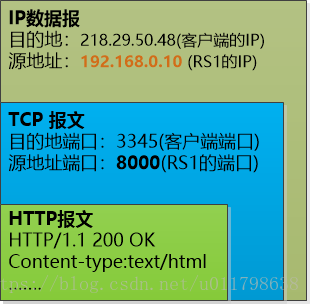
“你把计算机网络都忘了吧? 就是用户发过来的数据包嘛! 你看这个层层封装的数据包,用户发了一个HTTP的请求,想要访问我们网站的首页,这个HTTP请求被放到一个TCP报文中,再被放到一个IP数据报中, 最终的目的地就是我们的Load Balancer(115.39.19.22)。”
(注: 客户发给LB的数据包, 没有画出数据链路层的帧)
“但是这个数据包一看就是发给Load Balancer的, 怎么发给后面的服务器?”
Bill 说: “可以偷天换日,比如Load Balancer想把这个数据包发给RS1(192.168.0.10), 就可以做点手脚,把这个数据包改成这样, 然后这个IP数据包就可以转发给RS1去处理了。”
(LB动了手脚,把目的地IP和端口改为RS1的)
“RS1处理完了,要返回首页的HTML,还要把HTTP报文层层封装:” 张大胖明白怎么回事了:
(RS1处理完了,要发送结果给客户端)
“由于LB是网关,它还会收到这个数据包,它就可以再次施展手段,把源地址和源端口都替换为自己的,然后发给客户就可以了。”
(LB再次动手脚,把源地址和端口改成自己的, 让客户端毫无察觉)
张大胖总结了一下数据的流向: 客户端 –> Load Balancer –> RS –> Load Balancer –> 客户端
他兴奋地说:“这招瞒天过海真是妙啊,客户端根本就感受不到后面有好几台服务器在工作,它一直以为只有Load Balancer在干活。”
Bill此刻在思考Load Balancer 怎么样才能选取后面的各个真实的服务器, 可以有很多种策略,他在白板上写到:
轮询: 这个最简单,就是一个挨一个轮换。
加权轮询: 为了应对某些服务器性能好,可以让他们的权重高一点,被选中的几率大一点。
最少连接: 哪个服务器处理的连接少,就发给谁。
加权最少连接:在最少连接的基础上,也加上权重 …… 还有些其他的算法和策略,以后慢慢想。
张大胖却想到了另外一个问题: 对于用户的一个请求来说,可能会被分成多个数据包来发送, 如果这些数据包被我们的Load Balancer发到了不同的机器上,那就完全乱套了啊! 他把自己的想法告诉了Bill。
Bill说:“这个问题很好啊,我们的Load Balancer必须得维护一个表,这个表需要记录下客户端的数据包被我们转发到了哪个真实的服务器上, 这样当下一个数据包到来时,我们就可以把它转发到同一个服务器上去。”
“看来这个负载均衡软件需要是面向连接的,也就是OSI网络体系的第4层, 可以称为四层负载均衡”Bill做了一个总结。
“既然有四层负载均衡,那是不是也可以搞个七层的负载均衡啊?” 张大胖突发奇想。
“那是肯定的,如果我们的Load Balancer把HTTP层的报文数据取出来,根据其中的URL,浏览器,语言等信息,把请求分发到后面真实的服务器去,那就是七层的负载均衡了。不过我们现阶段先实现一个四层的吧,七层的以后再说。”
Bill 吩咐张大胖组织人力把这个负载均衡软件给开发出来。
张大胖不敢怠慢,由于涉及到协议的细节问题,张大胖还买了几本书:《TCP/IP详解》 卷一,卷二,卷三, 带着人快速复习了C语言, 然后开始疯狂开发。
三个月后,Load Balancer的第一版开发出来了,这是运行在Linux上的一个软件, 公司试用了一下,感觉还真是不错,仅仅用几台便宜的服务器就可以实现负载均衡了。
老板看到没花多少钱就解决了问题,非常满意,给张大胖所在的开发组发了1000块钱奖金,组织大家出去搓了一顿。
张大胖他们看到老板很抠门,虽略有不满,但是想到通过这个软件的开发,学到了很多底层的知识,尤其是TCP协议,也就忍了。
可是好景不长,张大胖发现这个Load Balancer存在这瓶颈:所有的流量都要通过它,它要修改客户发来的数据包, 还要修改发给客户的数据包。
网络访问还有个极大的特点,那就是请求报文较短而响应报文往往包含大量的数据。这是很容易理解的,一个HTTP GET请求短得可怜,可是返回的HTML却是极长 – 这就进一步加剧了Load Balancer修改数据包的工作。
张大胖赶紧去找Bill ,Bill说:“这确实是个问题,我们把请求和响应分开处理吧,让Load Balancer只处理请求,让各个服务器把响应直接发给客户端,这样瓶颈不就消除了吗?”
“怎么分开处理?”
“首先让所有的服务器都有同一个IP, 我们把他称为VIP吧(如图中115.39.19.22)。”
张大胖通过第一版Load Balancer的开发,积累了丰富的经验。
他问道:“你这是把每个实际服务器的loopback都绑定了那个VIP, 不过有问题啊,这么多服务器都有同样的IP , 当IP数据包来的时候,到底应该由哪个服务器来处理?”
“注意,IP数据包其实是通过数据链路层发过来的,你看看这个图。”
张大胖看到了客户端的HTTP报文再次被封装储层TCP报文,端口号是80, 然后IP数据报中的目的地是115.39.19.22(VIP)。
图中的问号是目的地的MAC地址, 该怎么得到呢?
对, 是使用ARP协议,把一个IP地址(115.39.19.22)给广播出去,然后具有此IP机器就会回复自己的MAC地址。 但是现在有好几台机器都有同一个IP(115.39.19.22), 怎么办?
Bill 说道:“我们只让Load Balancer 响应这个VIP地址(115.39.19.22)的ARP请求,对于RS1,RS2,RS3, 抑制住对这个VIP地址的ARP响应,不就可以唯一地确定Load Balancer了? ”
原来如此!张大胖恍然大悟。
既然Load Balancer得到了这个IP数据包, 它就可以用某个策略从RS1, RS2,RS3中选取一个服务器,例如RS1(192.168.0.10),把IP数据报原封不动, 封装成数据链路层的包(目的地是RS1的MAC地址),直接转发就可以了。
RS1(192.168.0.10)这个服务器收到了数据包,拆开一看,目的地IP是115.39.19.22,是自己的IP, 那就可以处理了。
处理完了以后,RS1可以直接响应发回给客户端,完全不用再通过Load Balancer。因为自己的地址就是115.39.19.22。
对于客户端来说,它看到的还是那个唯一的地址115.39.19.22, 并不知道后台发生了什么事情。
Bill补充到:“由于Load Balancer 根本不会修改IP数据报,其中的TCP的端口号自然也不会修改,这就要求RS1, RS2,RS3上的端口号必须得和Load Balancer一致才行。”
像之前一样,张大胖总结了一下数据的流向:
客户端 –> Load Balancer –> RS –> 客户端
Bill 说道:“怎么样? 这个办法还可以吧?”
张大胖又想了想,这种方式似乎没有漏洞,并且效率很高,Load Balancer只负责把用户请求发给特定的服务器就万事大吉了, 剩下的事由具体的服务器来处理,和它没有关系了。
他高兴地说:“不错,我着手带人去实现了。”
后记: 本文所描述的,其实就是著名开源软件LVS的原理,上面讲的两种负载均衡的方式,就是LVS的NAT和DR。 LVS是章文嵩博士在1998年5月成立的自由软件项目,现在已经是Linux内核的一部分。想想那时候我还在不亦乐乎地折腾个人网页,学会安装和使用Linux 没多久 , 服务器端开发也仅限于ASP,像LVS这种负载均衡的概念压根就没有听说过。 编程语言可以学,差距也能弥补,但是这种境界和眼光的差距,简直就是巨大的鸿沟,难以跨越啊! 读故事笔记:关于LVS的文章也读过几篇,往往只是记住了概念,不能设身处地的思考为何而来,刘欣老师每每都能以人物设定的场景,让我再次回到那个年代去思考、推演,还原当时如何一步步的演进成后来的LVS。
本人也混迹软件开发十几年,多数时间都是做着行业领域的软件开发,自我安慰是做着xx行业与计算机行业的交叉领域,实则一直未能深入计算机系统领域。行业应用软件开发,行业知识本身就牵扯了太多了精力,软件开发更多选择一种合适的架构来完成系统的设计、开发和维护。如你要成为一个计算机高手,有机会还是应当就计算机某一个领域深入研究,如Linux内核、搜索、图形图像、数据库、分布式存储,当然还有人工智能等等。
分布式架构实践——负载均衡
也许当我老了,也一样写代码;不为别的,只为了爱好。
在网站创立初期,我们一般都使用单台机器对台提供集中式服务,但是随着业务量越来越大,无论是性能上还是稳定性上都有了更大的挑战。这时候我们就会想到通过扩容的方式来提供更好的服务。我们一般会把多台机器组成一个集群对外提供服务。然而,我们的网站对外提供的访问入口都是一个的,比如 www.taobao.com。那么当用户在浏览器输入 www.taobao.com的时候如何将用户的请求分发到集群中不同的机器上呢,这就是负载均衡在做的事情。
当前大多数的互联网系统都使用了服务器集群技术,集群即将相同服务部署在多台服务器上构成一个集群整体对外提供服务,这些集群可以是Web应用服务器集群,也可以是数据库服务器集群,还可以是分布式缓存服务器集群等等。
在实际应用中,在Web服务器集群之前总会有一台负载均衡服务器,负载均衡设备的任务就是作为Web服务器流量的入口,挑选最合适的一台Web服务器,将客户端的请求转发给它处理,实现客户端到真实服务端的透明转发。最近几年很火的「云计算」以及分布式架构,本质上也是将后端服务器作为计算资源、存储资源,由某台管理服务器封装成一个服务对外提供,客户端不需要关心真正提供服务的是哪台机器,在它看来,就好像它面对的是一台拥有近乎无限能力的服务器,而本质上,真正提供服务的,是后端的集群。 软件负载解决的两个核心问题是:选谁、转发,其中最著名的是LVS(Linux Virtual Server)。

一个典型的互联网应用的拓扑结构是这样的:

现在我们知道,负载均衡就是一种计算机网络技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁碟驱动器或其他资源中分配负载,以达到最佳化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。那么,这种计算机技术的实现方式有多种。大致可以分为以下几种,其中最常用的是四层和七层负载均衡:
二层负载均衡 负载均衡服务器对外依然提供一个VIP(虚IP),集群中不同的机器采用相同IP地址,但是机器的MAC地址不一样。当负载均衡服务器接受到请求之后,通过改写报文的目标MAC地址的方式将请求转发到目标机器实现负载均衡。
三层负载均衡 和二层负载均衡类似,负载均衡服务器对外依然提供一个VIP(虚IP),但是集群中不同的机器采用不同的IP地址。当负载均衡服务器接受到请求之后,根据不同的负载均衡算法,通过IP将请求转发至不同的真实服务器。
四层负载均衡 四层负载均衡工作在OSI模型的传输层,由于在传输层,只有TCP/UDP协议,这两种协议中除了包含源IP、目标IP以外,还包含源端口号及目的端口号。四层负载均衡服务器在接受到客户端请求后,以后通过修改数据包的地址信息(IP+端口号)将流量转发到应用服务器。
七层负载均衡 七层负载均衡工作在OSI模型的应用层,应用层协议较多,常用http、radius、dns等。七层负载就可以基于这些协议来负载。这些应用层协议中会包含很多有意义的内容。比如同一个Web服务器的负载均衡,除了根据IP加端口进行负载外,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。

对于一般的应用来说,有了Nginx就够了。Nginx可以用于七层负载均衡。但是对于一些大的网站,一般会采用DNS+四层负载+七层负载的方式进行多层次负载均衡。

硬件负载均衡性能优越,功能全面,但是价格昂贵,一般适合初期或者土豪级公司长期使用。因此软件负载均衡在互联网领域大量使用。常用的软件负载均衡软件有Nginx,Lvs,HaProxy等。 Nginx/LVS/HAProxy是目前使用最广泛的三种负载均衡软件。
LVS(Linux Virtual Server),也就是Linux虚拟服务器, 是一个由章文嵩博士发起的自由软件项目。使用LVS技术要达到的目标是:通过LVS提供的负载均衡技术和Linux操作系统实现一个高性能、高可用的服务器群集,它具有良好可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。 LVS主要用来做四层负载均衡。
LVS架构 LVS架设的服务器集群系统有三个部分组成:最前端的负载均衡层(Loader Balancer),中间的服务器群组层,用Server Array表示,最底层的数据共享存储层,用Shared Storage表示。在用户看来所有的应用都是透明的,用户只是在使用一个虚拟服务器提供的高性能服务。

LVS的体系架构.png
LVS的各个层次的详细介绍:
Load Balancer层:位于整个集群系统的最前端,由一台或者多台负载调度器(Director Server)组成,LVS模块就安装在Director Server上,而Director的主要作用类似于一个路由器,它含有完成LVS功能所设定的路由表,通过这些路由表把用户的请求分发给Server Array层的应用服务器(Real Server)上。同时,在Director Server上还要安装对Real Server服务的监控模块Ldirectord,此模块用于监测各个Real Server服务的健康状况。在Real Server不可用时把它从LVS路由表中剔除,恢复时重新加入。
Server Array层:由一组实际运行应用服务的机器组成,Real Server可以是WEB服务器、MAIL服务器、FTP服务器、DNS服务器、视频服务器中的一个或者多个,每个Real Server之间通过高速的LAN或分布在各地的WAN相连接。在实际的应用中,Director Server也可以同时兼任Real Server的角色。
Shared Storage层:是为所有Real Server提供共享存储空间和内容一致性的存储区域,在物理上,一般有磁盘阵列设备组成,为了提供内容的一致性,一般可以通过NFS网络文件系统共享数 据,但是NFS在繁忙的业务系统中,性能并不是很好,此时可以采用集群文件系统,例如Red hat的GFS文件系统,oracle提供的OCFS2文件系统等。
从整个LVS结构可以看出,Director Server是整个LVS的核心,目前,用于Director Server的操作系统只能是Linux和FreeBSD,linux2.6内核不用任何设置就可以支持LVS功能,而FreeBSD作为 Director Server的应用还不是很多,性能也不是很好。对于Real Server,几乎可以是所有的系统平台,Linux、windows、Solaris、AIX、BSD系列都能很好的支持。
Nginx(发音同engine x)是一个网页服务器,它能反向代理HTTP, HTTPS, SMTP, POP3, IMAP的协议链接,以及一个负载均衡器和一个HTTP缓存。 Nginx主要用来做七层负载均衡。 并发性能:官方支持每秒5万并发,实际国内一般到每秒2万并发,有优化到每秒10万并发的。具体性能看应用场景。
特点
模块化设计:良好的扩展性,可以通过模块方式进行功能扩展。 高可靠性:主控进程和worker是同步实现的,一个worker出现问题,会立刻启动另一个worker。 内存消耗低:一万个长连接(keep-alive),仅消耗2.5MB内存。 支持热部署:不用停止服务器,实现更新配置文件,更换日志文件、更新服务器程序版本。 并发能力强:官方数据每秒支持5万并发; 功能丰富:优秀的反向代理功能和灵活的负载均衡策略 Nginx的基本工作模式

Nginx的基本工作模式.jpg
一个master进程,生成一个或者多个worker进程。但是这里master是使用root身份启动的,因为nginx要工作在80端口。而只有管理员才有权限启动小于低于1023的端口。master主要是负责的作用只是启动worker,加载配置文件,负责系统的平滑升级。其它的工作是交给worker。那么当worker被启动之后,也只是负责一些web最简单的工作,而其他的工作都是由worker中调用的模块来实现的。 模块之间是以流水线的方式实现功能的。流水线,指的是一个用户请求,由多个模块组合各自的功能依次实现完成的。比如:第一个模块只负责分析请求首部,第二个模块只负责查找数据,第三个模块只负责压缩数据,依次完成各自工作。来实现整个工作的完成。 他们是如何实现热部署的呢?其实是这样的,我们前面说master不负责具体的工作,而是调用worker工作,他只是负责读取配置文件,因此当一个模块修改或者配置文件发生变化,是由master进行读取,因此此时不会影响到worker工作。在master进行读取配置文件之后,不会立即把修改的配置文件告知worker。而是让被修改的worker继续使用老的配置文件工作,当worker工作完毕之后,直接杀死这个子进程,更换新的子进程,使用新的规则。
HAProxy也是使用较多的一款负载均衡软件。HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,是免费、快速并且可靠的一种解决方案。特别适用于那些负载特大的web站点。运行模式使得它可以很简单安全的整合到当前的架构中,同时可以保护你的web服务器不被暴露到网络上。 HAProxy是一个使用C语言编写的自由及开放源代码软件,其提供高可用性、负载均衡,以及基于TCP和HTTP的应用程序代理。 Haproxy主要用来做七层负载均衡。
上面介绍负载均衡技术的时候提到过,负载均衡服务器在决定将请求转发到具体哪台真实服务器的时候,是通过负载均衡算法来实现的。负载均衡算法可以分为两类:静态负载均衡算法和动态负载均衡算法。
静态负载均衡算法包括:轮询,比率,优先权
动态负载均衡算法包括: 最少连接数,最快响应速度,观察方法,预测法,动态性能分配,动态服务器补充,服务质量,服务类型,规则模式。
轮询(Round Robin):顺序循环将请求一次顺序循环地连接每个服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从顺序循环队列中拿出,不参加下一次的轮询,直到其恢复正常。 以轮询的方式依次请求调度不同的服务器; 实现时,一般为服务器带上权重;这样有两个好处: 针对服务器的性能差异可分配不同的负载; 当需要将某个结点剔除时,只需要将其权重设置为0即可; 优点:实现简单、高效;易水平扩展; 缺点:请求到目的结点的不确定,造成其无法适用于有写的场景(缓存,数据库写) 应用场景:数据库或应用服务层中只有读的场景; 随机方式:请求随机分布到各个结点;在数据足够大的场景能达到一个均衡分布; 优点:实现简单、易水平扩展; 缺点:同Round Robin,无法用于有写的场景; 应用场景:数据库负载均衡,也是只有读的场景;
哈希方式:根据key来计算需要落在的结点上,可以保证一个同一个键一定落在相同的服务器上; 优点:相同key一定落在同一个结点上,这样就可用于有写有读的缓存场景; 缺点:在某个结点故障后,会导致哈希键重新分布,造成命中率大幅度下降; 解决:一致性哈希 or 使用keepalived保证任何一个结点的高可用性,故障后会有其它结点顶上来; 应用场景:缓存,有读有写;
一致性哈希:在服务器一个结点出现故障时,受影响的只有这个结点上的key,最大程度的保证命中率; 如twemproxy中的ketama方案; 生产实现中还可以规划指定子key哈希,从而保证局部相似特征的键能分布在同一个服务器上; 优点:结点故障后命中率下降有限; 应用场景:缓存;
根据键的范围来负载:根据键的范围来负载,前1亿个键都存放到第一个服务器,1~2亿在第二个结点; 优点:水平扩展容易,存储不够用时,加服务器存放后续新增数据; 缺点:负载不均;数据库的分布不均衡;(数据有冷热区分,一般最近注册的用户更加活跃,这样造成后续的服务器非常繁忙,而前期的结点空闲很多) 适用场景:数据库分片负载均衡;
根据键对服务器结点数取模来负载:根据键对服务器结点数取模来负载;比如有4台服务器,key取模为0的落在第一个结点,1落在第二个结点上。 优点:数据冷热分布均衡,数据库结点负载均衡分布; 缺点:水平扩展较难; 适用场景:数据库分片负载均衡;
纯动态结点负载均衡:根据CPU、IO、网络的处理能力来决策接下来的请求如何调度; 优点:充分利用服务器的资源,保证个结点上负载处理均衡; 缺点:实现起来复杂,真实使用较少;
不用主动负载均衡:使用消息队列转为异步模型,将负载均衡的问题消灭;负载均衡是一种推模型,一直向你发数据,那么,将所有的用户请求发到消息队列中,所有的下游结点谁空闲,谁上来取数据处理;转为拉模型之后,消除了对下行结点负载的问题; 优点:通过消息队列的缓冲,保护后端系统,请求剧增时不会冲垮后端服务器; 水平扩展容易,加入新结点后,直接取queue即可; 缺点:不具有实时性; 应用场景:不需要实时返回的场景; 比如,12036下订单后,立刻返回提示信息:您的订单进去排队了…等处理完毕后,再异步通知;
比率(Ratio):给每个服务器分配一个加权值为比例,根椐这个比例,把用户的请求分配到每个服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配, 直到其恢复正常。
优先权(Priority):给所有服务器分组,给每个组定义优先权,BIG-IP 用户的请求,分配给优先级最高的服务器组(在同一组内,采用轮询或比率算法,分配用户的请求);当最高优先级中所有服务器出现故障,BIG-IP 才将请求送给次优先级的服务器组。这种方式,实际为用户提供一种热备份的方式。
最少的连接方式(Least Connection):传递新的连接给那些进行最少连接处理的服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配, 直到其恢复正常。
最快模式(Fastest):传递连接给那些响应最快的服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。
观察模式(Observed):连接数目和响应时间以这两项的最佳平衡为依据为新的请求选择服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。
预测模式(Predictive):BIG-IP利用收集到的服务器当前的性能指标,进行预测分析,选择一台服务器在下一个时间片内,其性能将达到最佳的服务器相应用户的请求。(被BIG-IP 进行检测)
动态性能分配(Dynamic Ratio-APM):BIG-IP 收集到的应用程序和应用服务器的各项性能参数,动态调整流量分配。
动态服务器补充(Dynamic Server Act.):当主服务器群中因故障导致数量减少时,动态地将备份服务器补充至主服务器群。
服务质量(QoS):按不同的优先级对数据流进行分配。
服务类型(ToS): 按不同的服务类型(在Type of Field中标识)负载均衡对数据流进行分配。
规则模式:针对不同的数据流设置导向规则,用户可自行。
package com.boer.tdf.act.test;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 負載均衡算法,輪詢法.
*/
public class TestRoundRobin {
static MapserverWeigthMap = new HashMap();
static {
serverWeigthMap.put("192.168.1.12", 1);
serverWeigthMap.put("192.168.1.13", 1);
serverWeigthMap.put("192.168.1.14", 2);
serverWeigthMap.put("192.168.1.15", 2);
serverWeigthMap.put("192.168.1.16", 3);
serverWeigthMap.put("192.168.1.17", 3);
serverWeigthMap.put("192.168.1.18", 1);
serverWeigthMap.put("192.168.1.19", 2);
}
Integer pos = 0;
public String roundRobin() {
// 重新建立一個map,避免出現由於服務器上線和下線導致的並發問題
MapserverMap = new HashMap();
serverMap.putAll(serverWeigthMap);
// 獲取ip列表list
SetkeySet = serverMap.keySet();
ArrayListkeyList = new ArrayList();
keyList.addAll(keySet);
String server = null;
synchronized (pos) {
if(pos >=keySet.size()){
pos = 0;
}
server = keyList.get(pos);
pos ++;
}
return server;
}
public static void main(String[] args) {
TestRoundRobin robin = new TestRoundRobin();
for (int i = 0; i < 20; i++) {
String serverIp = robin.roundRobin();
System.out.println(serverIp);
}
}
/**
* 运行结果:
* 192.168.1.12
192.168.1.14
192.168.1.13
192.168.1.16
192.168.1.15
192.168.1.18
192.168.1.17
192.168.1.19
192.168.1.12
192.168.1.14
192.168.1.13
192.168.1.16
192.168.1.15
192.168.1.18
192.168.1.17
192.168.1.19
192.168.1.12
192.168.1.14
192.168.1.13
192.168.1.16
*/
} package com.boer.tdf.act.test;
import java.util.*;
/**
* 加权随机负载均衡算法.
*/
public class TestWeightRandom {
static MapserverWeigthMap = new HashMap();
static {
serverWeigthMap.put("192.168.1.12", 1);
serverWeigthMap.put("192.168.1.13", 1);
serverWeigthMap.put("192.168.1.14", 2);
serverWeigthMap.put("192.168.1.15", 2);
serverWeigthMap.put("192.168.1.16", 3);
serverWeigthMap.put("192.168.1.17", 3);
serverWeigthMap.put("192.168.1.18", 1);
serverWeigthMap.put("192.168.1.19", 2);
}
public static String weightRandom()
{
// 重新建立一個map,避免出現由於服務器上線和下線導致的並發問題
MapserverMap = new HashMap();
serverMap.putAll(serverWeigthMap);
// 獲取ip列表list
SetkeySet = serverMap.keySet();
Iteratorit = keySet.iterator();
ListserverList = new ArrayList();
while (it.hasNext()) {
String server = it.next();
Integer weight = serverMap.get(server);
for (int i = 0; i < weight; i++) {
serverList.add(server);
}
}
Random random = new Random();
int randomPos = random.nextInt(serverList.size());
String server = serverList.get(randomPos);
return server;
}
public static void main(String[] args) {
String serverIp = weightRandom();
System.out.println(serverIp);
/**
* 运行结果:
* 192.168.1.16
*/
}
}随机负载均衡算法 package com.boer.tdf.act.test;
import java.util.*;
/**
* 随机负载均衡算法.
*/
public class TestRandom {
static MapserverWeigthMap = new HashMap();
static {
serverWeigthMap.put("192.168.1.12", 1);
serverWeigthMap.put("192.168.1.13", 1);
serverWeigthMap.put("192.168.1.14", 2);
serverWeigthMap.put("192.168.1.15", 2);
serverWeigthMap.put("192.168.1.16", 3);
serverWeigthMap.put("192.168.1.17", 3);
serverWeigthMap.put("192.168.1.18", 1);
serverWeigthMap.put("192.168.1.19", 2);
}
public static String random() {
// 重新建立一個map,避免出現由於服務器上線和下線導致的並發問題
MapserverMap = new HashMap();
serverMap.putAll(serverWeigthMap);
// 獲取ip列表list
SetkeySet = serverMap.keySet();
ArrayListkeyList = new ArrayList();
keyList.addAll(keySet);
Random random = new Random();
int randomPos = random.nextInt(keyList.size());
String server = keyList.get(randomPos);
return server;
}
public static void main(String[] args) {
String serverIp = random();
System.out.println(serverIp);
}
/**
* 运行结果:
* 192.168.1.16
*/
}负载均衡 ip_hash算法 package com.boer.tdf.act.test;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 负载均衡 ip_hash算法.
*/
public class TestIpHash {
static MapserverWeigthMap = new HashMap();
static {
serverWeigthMap.put("192.168.1.12", 1);
serverWeigthMap.put("192.168.1.13", 1);
serverWeigthMap.put("192.168.1.14", 2);
serverWeigthMap.put("192.168.1.15", 2);
serverWeigthMap.put("192.168.1.16", 3);
serverWeigthMap.put("192.168.1.17", 3);
serverWeigthMap.put("192.168.1.18", 1);
serverWeigthMap.put("192.168.1.19", 2);
}
/**
* 获取请求服务器地址
* @param remoteIp 负载均衡服务器ip
* @return
*/
public static String ipHash(String remoteIp) {
// 重新建立一個map,避免出現由於服務器上線和下線導致的並發問題
MapserverMap = new HashMap();
serverMap.putAll(serverWeigthMap);
// 獲取ip列表list
SetkeySet = serverMap.keySet();
ArrayListkeyList = new ArrayList();
keyList.addAll(keySet);
int hashCode =remoteIp.hashCode();
int serverListSize = keyList.size();
int serverPos = hashCode % serverListSize;
return keyList.get(serverPos);
}
public static void main(String[] args) {
String serverIp = ipHash("192.168.1.12");
System.out.println(serverIp);
/**
* 运行结果:
* 192.168.1.18
*/
}
}看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。