жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дёҖгҖҒhiveдә§з”ҹиғҢжҷҜ
Apache Hiveж•°жҚ®д»“еә“иҪҜ件еҸҜд»ҘдҪҝз”ЁSQLж–№дҫҝең°йҳ…иҜ»гҖҒзј–еҶҷе’Ңз®ЎзҗҶеҲҶеёғеңЁеҲҶеёғејҸеӯҳеӮЁдёӯзҡ„еӨ§еһӢж•°жҚ®йӣҶгҖӮз»“жһ„еҸҜд»ҘжҠ•е°„еҲ°е·Із»ҸеӯҳеӮЁзҡ„ж•°жҚ®дёҠгҖӮжҸҗдҫӣдәҶдёҖдёӘе‘Ҫд»ӨиЎҢе·Ҙе…·е’ҢJDBCй©ұеҠЁзЁӢеәҸжқҘе°Ҷз”ЁжҲ·иҝһжҺҘеҲ°HiveгҖӮ
вҖў з”ұFacebookејҖжәҗпјҢжңҖеҲқз”ЁдәҺи§ЈеҶіжө·йҮҸз»“жһ„еҢ–зҡ„ж—Ҙеҝ—ж•°жҚ®з»ҹи®Ўй—®йўҳ
вҖў MapReduceзј–зЁӢзҡ„дёҚдҫҝжҖ§
вҖў HDFSдёҠзҡ„ж–Ү件зјәе°‘SchemaпјҲеӯ—ж®өеҗҚпјҢеӯ—ж®өзұ»еһӢзӯүпјү
дәҢгҖҒHiveжҳҜд»Җд№Ҳ
вҖў жһ„е»әеңЁHadoopд№ӢдёҠзҡ„ж•°жҚ®д»“еә“
вҖў Hiveе®ҡд№үдәҶдёҖз§Қзұ»SQLжҹҘиҜўиҜӯиЁҖпјҡHQLпјҲзұ»дјјSQLдҪҶдёҚе®Ңе…ЁзӣёеҗҢпјү
вҖў йҖҡеёёз”ЁдәҺиҝӣиЎҢзҰ»зәҝж•°жҚ®еӨ„зҗҶпјҲйҮҮз”ЁMapReduceпјү
вҖў еә•еұӮж”ҜжҢҒеӨҡз§ҚдёҚеҗҢзҡ„жү§иЎҢеј•ж“ҺпјҲHive on MapReduceгҖҒHive on TezгҖҒHive on Sparkпјү
вҖў ж”ҜжҢҒеӨҡз§ҚдёҚеҗҢзҡ„еҺӢзј©ж јејҸгҖҒеӯҳеӮЁж јејҸд»ҘеҸҠиҮӘе®ҡд№үеҮҪж•°пјҲеҺӢзј©пјҡGZIPгҖҒLZOгҖҒSnappyгҖҒBZIP2.. пјӣ еӯҳеӮЁпјҡTextFileгҖҒSequenceFileгҖҒRCFileгҖҒORCгҖҒParquet пјӣ UDFпјҡиҮӘе®ҡд№үеҮҪж•°пјү
еҲ°еә•д»Җд№ҲжҳҜHiveпјҢжҲ‘们е…ҲзңӢзңӢHiveе®ҳзҪ‘WikiжҳҜеҰӮдҪ•д»Ӣз»ҚHiveзҡ„(https://cwiki.apache.org/confluence/display/Hive/Home)пјҡ

Apache Hive Apache Hiveв„ў ж•°жҚ®д»“еә“иҪҜ件дёәеҲҶеёғејҸеӯҳеӮЁзҡ„еӨ§ж•°жҚ®йӣҶдёҠзҡ„иҜ»гҖҒеҶҷгҖҒз®ЎзҗҶжҸҗдҫӣеҫҲеӨ§ж–№дҫҝпјҢеҗҢж—¶иҝҳеҸҜд»Ҙз”ЁSQLиҜӯжі•еңЁеӨ§ж•°жҚ®йӣҶдёҠжҹҘиҜўгҖӮ
1гҖҒжҳҜдёҖз§Қжҳ“дәҺеҜ№ж•°жҚ®е®һзҺ°жҸҗеҸ–гҖҒиҪ¬жҚўгҖҒеҠ иҪҪзҡ„е·Ҙе…·(ETL)зҡ„е·Ҙе…·гҖӮеҸҜд»ҘзҗҶи§Јдёәж•°жҚ®жё…жҙ—еҲҶжһҗеұ•зҺ°гҖӮ 2гҖҒе®ғжңүдёҖз§Қе°ҶеӨ§йҮҸж јејҸеҢ–ж•°жҚ®ејәеҠ дёҠз»“жһ„зҡ„жңәеҲ¶гҖӮ 3гҖҒе®ғеҸҜд»ҘеҲҶжһҗеӨ„зҗҶзӣҙжҺҘеӯҳеӮЁеңЁhdfsдёӯзҡ„ж•°жҚ®жҲ–иҖ…жҳҜеҲ«зҡ„ж•°жҚ®еӯҳеӮЁзі»з»ҹдёӯзҡ„ж•°жҚ®пјҢеҰӮhbaseгҖӮ 4гҖҒжҹҘиҜўзҡ„жү§иЎҢз»Ҹз”ұmapreduceе®ҢжҲҗгҖӮ 5гҖҒhiveеҸҜд»ҘдҪҝз”ЁеӯҳеӮЁиҝҮзЁӢ 6гҖҒйҖҡиҝҮApache YARNе’ҢApache Sliderе®һзҺ°дәҡз§’зә§зҡ„жҹҘиҜўжЈҖзҙўгҖӮ
дёүгҖҒhiveзҡ„е®үиЈ…
1.hiveзҡ„еҚ•жңәе®үиЈ…пјҲдҪҝз”ЁderbyеҒҡе…ғж•°жҚ®еӯҳеӮЁпјү
вҖў е®үиЈ…еҢ…еҮҶеӨҮ
е°Ҷhiveе®үиЈ…еҢ… apache-hive-1.2.1-bin.tar.gz дёҠдј еҲ°иҷҡжӢҹжңә/bigdata/дёӢ
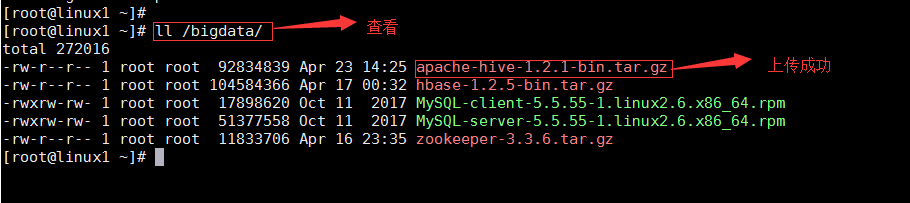
JDKе®үиЈ…еҢ… jdk-8u151-x64.gz
йӣҶзҫӨзҡ„еҮҶеӨҮпјҲlinux1,linux2,linux3пјү
вҖў hiveзҡ„и§ЈеҺӢе®үиЈ…
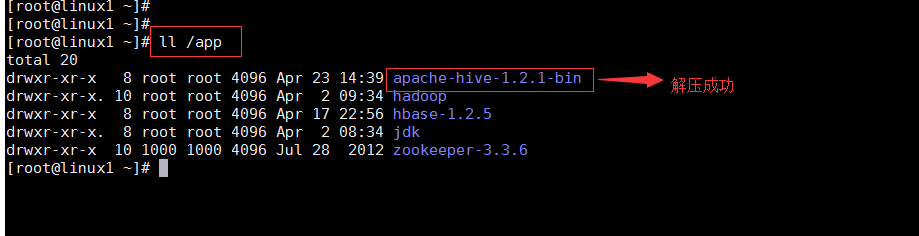
е°ҶдёҠдј зҡ„hiveи§ЈеҺӢзј©иҮіиҷҡжӢҹжңә/appзӣ®еҪ•дёӢ
tar -zxvf /app/apache-hive-1.2.1-bin.tar.gz -C /app
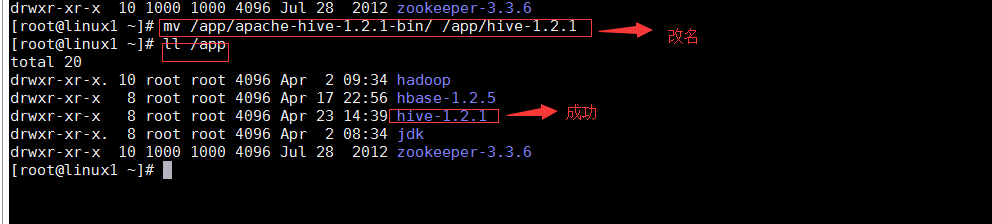
mv /app/apache-hive-1.2.1-bin/ /app/hive-1.2.1
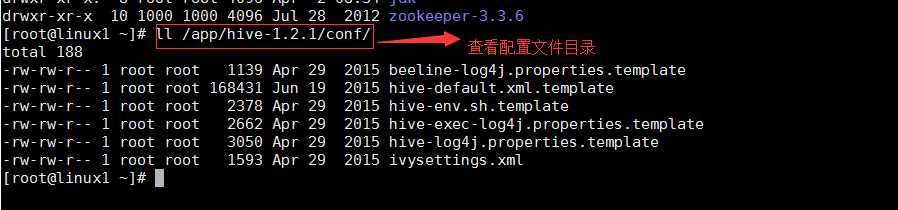
вҖў й…ҚзҪ®hiveзҡ„й…ҚзҪ®ж–Ү件
жҹҘзңӢй…ҚзҪ®ж–Ү件еҶ…е®№
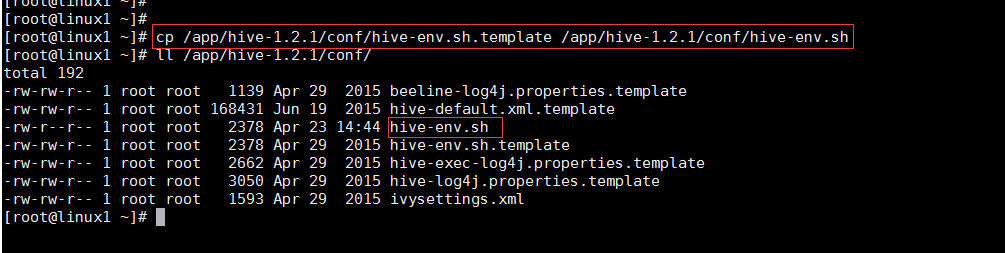
жӢ·иҙқй…ҚзҪ®ж–Ү件hive-env.sh.templateдёәhive-env.sh
cp /app/hive-1.2.1/conf/hive-env.sh.template /app/hive-1.2.1/conf/hive-env.sh
vim /app/hive-1.2.1/conf/hive-env.sh
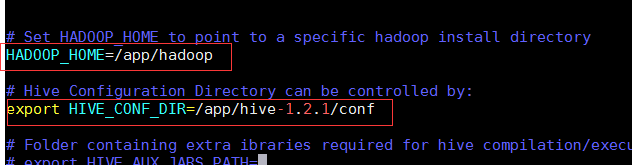
вҖў й…ҚзҪ®hiveзҡ„зҺҜеўғеҸҳйҮҸ
vim /etc/profile

source /etc/profile
which hive

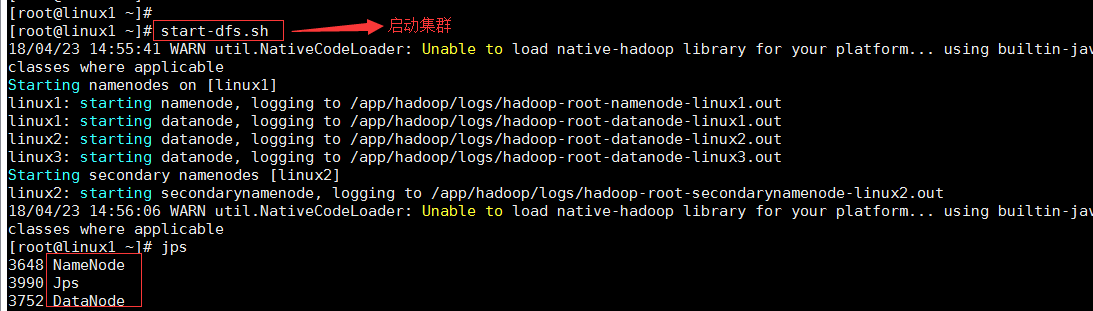
вҖў еҗҜеҠЁhadoopйӣҶзҫӨ
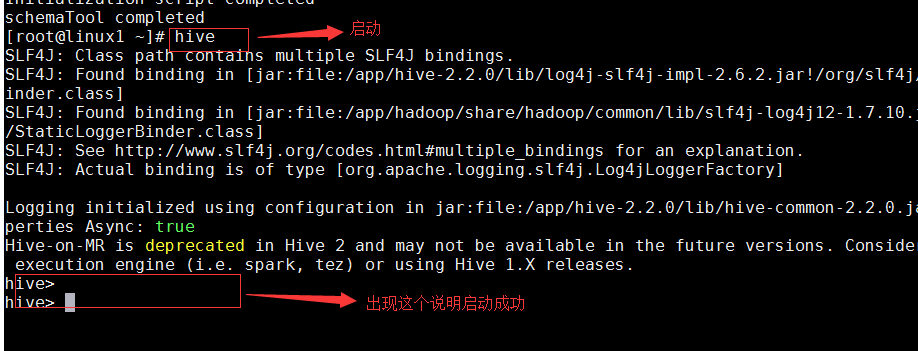
вҖў еҗҜеҠЁhiveжңҚеҠЎ
hive
вҖў жҹҘзңӢж•°жҚ®еә“
show databases;
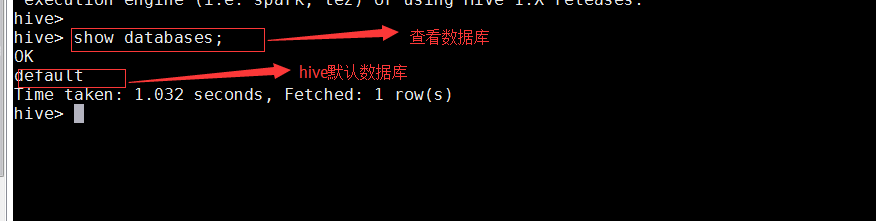
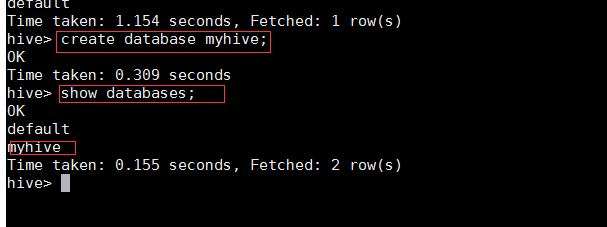
вҖў еҲӣе»әж•°жҚ®еә“
create database myhive;
show databases;
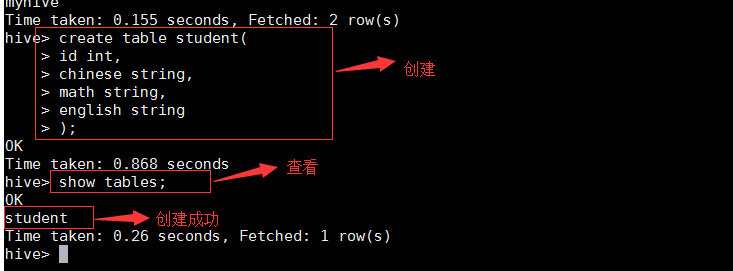
вҖў еҲӣе»әиЎЁ
create table studentпјҲid intпјҢchinese stringпјҢmath stringпјҢEnglish stringпјүпјӣ
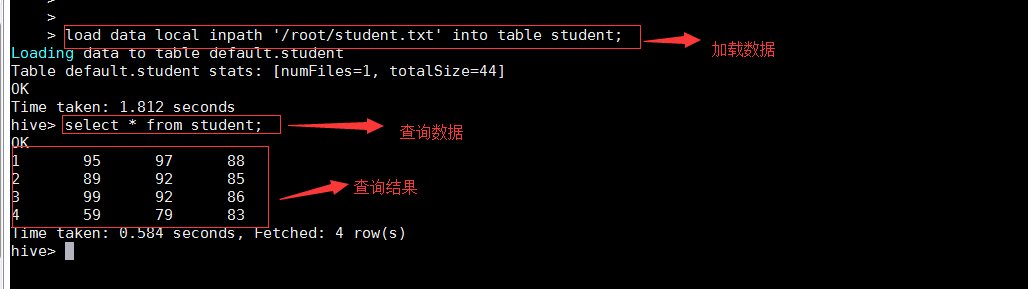
вҖў еҠ иҪҪж•°жҚ®е№¶жҹҘиҜў
load data local inpath '/root/student.txt' into table student;
select * from student;
2.hiveзҡ„зӢ¬з«Ӣе®үиЈ…жЁЎејҸпјҲдҪҝз”ЁmysqlеҒҡе…ғж•°жҚ®еӯҳеӮЁпјү
вҖў е®үиЈ…MySQLжңҚеҠЎеҷЁз«Ҝе’ҢMySQLе®ўжҲ·з«ҜпјҢ并еҗҜеҠЁmysqlжңҚеҠЎгҖӮ
вҖў еңЁlinux1дёҠдёәHiveе»әз«Ӣзӣёеә”зҡ„MySQLиҙҰжҲ·пјҢ并иөӢдәҲи¶іеӨҹзҡ„жқғйҷҗ
create user 'hive' identified by '123456';
GRANT ALL PRIVILEGES ON *.* TO hive@'%' IDENTIFIED BY '123456' with grant option;
GRANT ALL PRIVILEGES ON *.* TO hive@'localhost' IDENTIFIED BY '123456' with grant option;
flush privileges
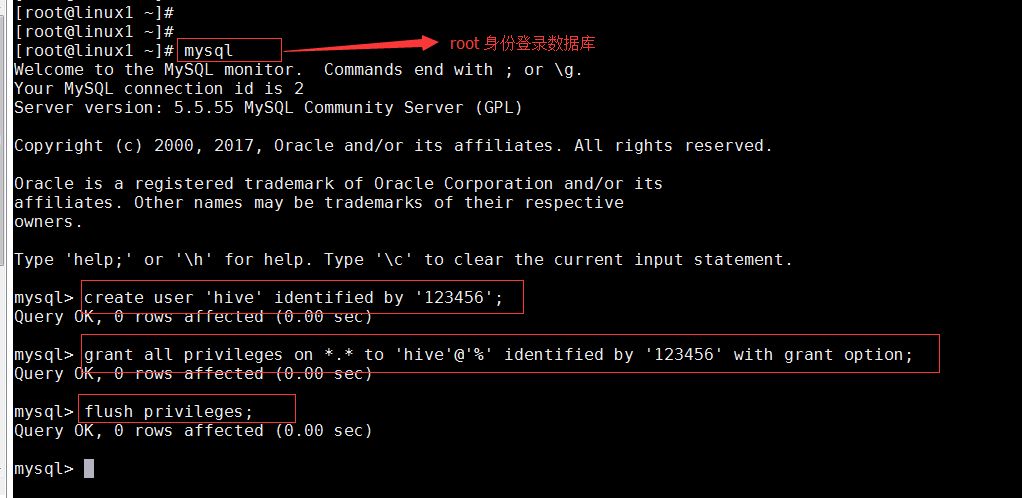
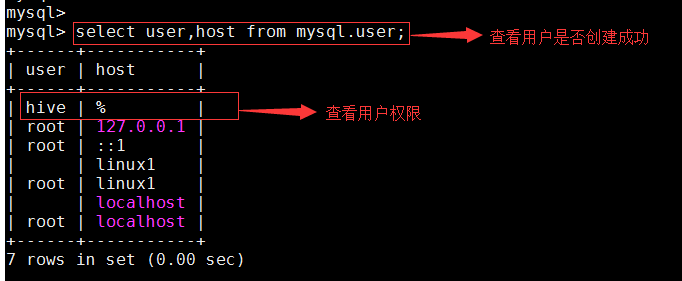
жҹҘзңӢжҳҜеҗҰжҲҗеҠҹ
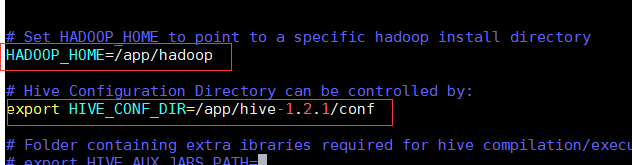
вҖў еңЁеҶ…еөҢжЁЎејҸдёӢ继з»ӯй…ҚзҪ®hiveпјҡhive-site.xml,hive-env.sh
й…ҚзҪ®hive-env.sh
й…ҚзҪ®hive-site.xml,жӢ·иҙқ/app/hive-1.2.1/confдёӢзҡ„hive-default.xmlж–Ү件дёәhive-site.xml
cp /app/hive-1.2.1/conf/hive-default.xml.template /app/hive-1.2.1/conf/hive-site.xml
vim /app/hive-1.2.1/conf/hive-site.xml
вҖў жӢ·иҙқж•°жҚ®й©ұеҠЁjarеҢ…еҲ°жҢҮе®ҡзӣ®еҪ•/app/hive-1.2.1/lib/дёӢгҖӮжІЎжңүй©ұеҠЁеҢ…дјҡжҠҘй”ҷ
вҖў дҪҝз”Ёе‘Ҫд»ӨиЎҢзҡ„ж–№ејҸеҗҜеҠЁhiveжңҚеҠЎпјҢ然еҗҺжҹҘзңӢж•°жҚ®еә“пјҢеҲӣе»әж•°жҚ®еә“еҗҚдёәheihei,жҹҘзңӢйӣҶзҫӨwebйЎөйқў
жҹҘзңӢйӣҶзҫӨwebйЎөйқўпјҢеҸҜд»ҘзңӢи§ҒеңЁhdfsдёҠз”ҹжҲҗдәҶеҜ№еә”heiheiж•°жҚ®еә“зҡ„ж–Ү件зӣ®еҪ•
вҖў дҪҝз”Ёbeelineи®ҝй—®hive
exitе‘Ҫд»ӨйҖҖеҮәеҲҡжүҚзҡ„hiveжңҚеҠЎпјҢеңЁlinux1дёҠдҝ®ж”№hadoop й…ҚзҪ®ж–Ү件 etc/hadoop/core-site.xml,еҠ е…ҘеҰӮдёӢй…ҚзҪ®йЎ№пјҢ йҖҡиҝҮhttpfsжҺҘеҸЈеҢҝеҗҚзҡ„ж–№ејҸзҷ»еҪ•еҲ°hdfsж–Ү件系з»ҹгҖӮ然еҗҺйҮҚж–°еҗҜеҠЁйӣҶзҫӨгҖӮ
<property>
<name> hadoop.proxyuser.root.hosts </name>
<value> * </value>
</property>
<property>
<name> hadoop.proxyuser.root.groups </name>
<value> * </value>
</property>
дҪҝз”Ёе‘Ҫд»Өhive --service hiveserver2 & еҗҺеҸ°еҗҜеҠЁhiveжңҚеҠЎ
hive --service hiveserver2 &
е…ӢйҡҶзӘ—еҸЈдҪңдёәе®ўжҲ·з«ҜиҝһжҺҘпјҢжү§иЎҢbeelineи„ҡжң¬
иҝһжҺҘжңҚеҠЎз«ҜпјҢиҝҷз§Қж–№ејҸдҪҝз”ЁдәҶthriftжңҚеҠЎпјҢ10000дёәй»ҳи®Өзҡ„иҝһжҺҘз«ҜеҸЈеҸ·
!connect jdbc:hive2://linux1:10000
йӘҢиҜҒиҝһжҺҘзҡ„жҳҜдёҚжҳҜжҲ‘们еҲҡжүҚз”Ёе‘Ҫд»ӨиЎҢж–№ејҸи®ҝй—®зҡ„hiveжңҚеҠЎ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ